Recognition: no theorem link
Beyond Self-Play and Scale: A Behavior Benchmark for Generalization in Autonomous Driving
Pith reviewed 2026-05-12 03:16 UTC · model grok-4.3
The pith
Reinforcement learning policies for autonomous driving trained through pure self-play overfit to their opponents and fail to generalize to other traffic behaviors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
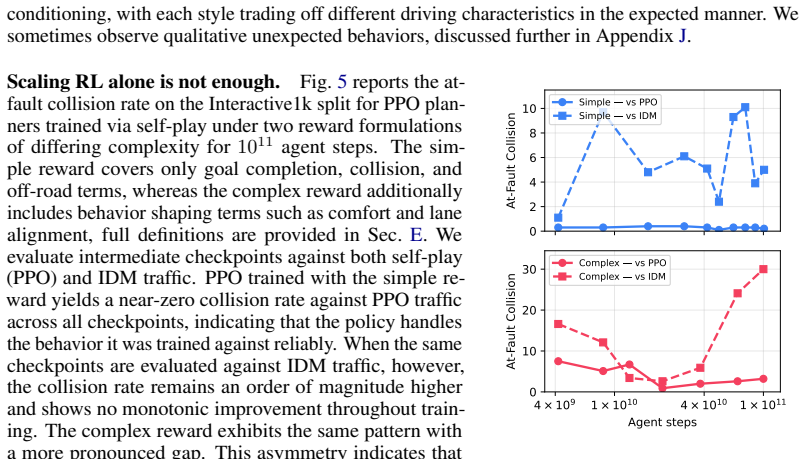
Policies trained via pure self-play under standard reward functions overfit to their training opponents and fail to generalize to other traffic agent behaviors, even though interactive behaviors emerge during training. BehaviorBench makes this visible by connecting PufferDrive to nuPlan, using complex splits from the Waymo Open Motion Dataset, and testing against heterogeneous traffic models instead of only the Intelligent Driver Model.
What carries the argument
BehaviorBench, a test suite that connects RL-trained policies to nuPlan, uses interaction-rich WOMD scenarios, and evaluates against a diverse suite of interactive traffic agents.
Load-bearing premise
The performance drop against diverse traffic agents is caused by overfitting to self-play opponents rather than differences in simulation fidelity, insufficient training scale, or other factors.
What would settle it
Retraining the same policy architecture inside self-play that includes the diverse traffic agents and then observing no performance drop on the benchmark would falsify the overfitting claim.
Figures
















read the original abstract
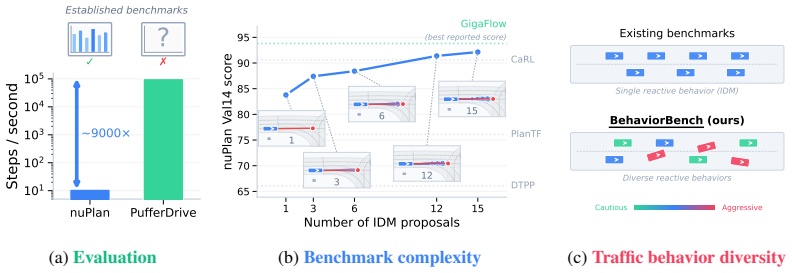
Recent Autonomous Driving (AD) works such as GigaFlow and PufferDrive have unlocked Reinforcement Learning (RL) at scale as a training strategy for driving policies. Yet such policies remain disconnected from established benchmarks, leaving the performance of large-scale RL for driving on standardized evaluations unknown. We present BehaviorBench -- a comprehensive test suite that closes this gap along three axes: Evaluation, Complexity, and Behavior Diversity. In terms of Evaluation, we provide an interface connecting PufferDrive to nuPlan, which, for the first time, enables policies trained via RL at scale to be evaluated on an established planning benchmark for autonomous driving. Complementarily, we offer an evaluation framework that allows planners to be benchmarked directly inside the PufferDrive simulation, at a fraction of the time. Regarding Complexity, we observe that today's standardized benchmarks are so simple that near-perfect scores are achievable by straight lane following with collision checking. We extract a meaningful, interaction-rich split from the Waymo Open Motion Dataset (WOMD) on which strong performance is impossible without multi-agent reasoning. Lastly, we address Behavior Diversity. Existing benchmarks commonly evaluate planners against a single rule-based traffic model, the Intelligent Driver Model (IDM). We provide a diverse suite of interactive traffic agents to stress-test policies under heterogeneous behaviors, beyond just using IDM. Overall, our benchmarking analysis uncovers the following insight: despite learning interactive behaviors in an emergent manner, policies trained via pure self-play under standard reward functions overfit to their training opponents and fail to generalize to other traffic agent behaviors. Building on this observation, we propose a hybrid planner that combines a PPO policy with a rule-based planner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BehaviorBench, a test suite for autonomous driving policies with three components: an interface linking PufferDrive-trained RL policies to the nuPlan benchmark for standardized evaluation, an interaction-rich scenario split extracted from the Waymo Open Motion Dataset (WOMD) where simple lane-following is insufficient, and a diverse suite of interactive traffic agents extending beyond the standard Intelligent Driver Model (IDM). The central empirical insight is that policies trained via pure self-play under standard reward functions overfit to their training opponents and fail to generalize to heterogeneous traffic behaviors, motivating a proposed hybrid planner that combines a PPO policy with a rule-based planner.
Significance. If the reported results and controls hold, the work would be significant for establishing the first direct connection between large-scale self-play RL training and established AD benchmarks like nuPlan, while providing evaluation tools that stress multi-agent complexity and behavior diversity. This could guide future research away from pure self-play toward more robust generalization strategies and offer a reproducible framework for testing interactive driving policies at lower computational cost than full nuPlan runs.
major comments (1)
- [Abstract] Abstract: The central claim that 'policies trained via pure self-play under standard reward functions overfit to their training opponents and fail to generalize to other traffic agent behaviors' is stated without any quantitative results, ablation studies, error bars, training details, reward specifications, or description of how the diverse traffic agents were constructed. This absence makes it impossible to assess whether the performance drop is caused by overfitting (as claimed) or by unmeasured factors such as simulation fidelity differences between PufferDrive and nuPlan, rendering the key insight unverifiable from the provided manuscript.
minor comments (1)
- The abstract asserts that the nuPlan interface is provided 'for the first time'; the full manuscript should include citations to any prior attempts at connecting RL policies to nuPlan to substantiate this novelty claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: The central claim that 'policies trained via pure self-play under standard reward functions overfit to their training opponents and fail to generalize to other traffic agent behaviors' is stated without any quantitative results, ablation studies, error bars, training details, reward specifications, or description of how the diverse traffic agents were constructed. This absence makes it impossible to assess whether the performance drop is caused by overfitting (as claimed) or by unmeasured factors such as simulation fidelity differences between PufferDrive and nuPlan, rendering the key insight unverifiable from the provided manuscript.
Authors: We agree that the abstract states the central claim without quantitative support, ablations, error bars, reward details, or agent construction information, which prevents readers from verifying the overfitting interpretation versus other factors such as simulator differences. Because only the abstract is available here, we cannot reference or quote specific results from the body. We will revise the abstract to include a brief quantitative summary of the observed performance degradation, high-level training and reward information, and a description of the diverse traffic agents, plus a short note on simulation fidelity controls. This will make the key insight verifiable at the abstract level while preserving brevity. revision: yes
- Specific quantitative results, ablation studies, error bars, reward specifications, and exact descriptions of traffic agent construction are absent from the provided abstract, so we cannot supply or cite them in this response.
Circularity Check
No circularity: empirical benchmark evaluation
full rationale
The paper introduces BehaviorBench as an evaluation interface and test suite linking large-scale RL policies (from PufferDrive) to external benchmarks (nuPlan, WOMD) and a new suite of diverse traffic agents. The central insight—that pure self-play policies overfit to training opponents—is presented as an observed performance pattern from these comparisons, not as a derived result from any equations, fitted parameters, or self-referential definitions. No self-citations, uniqueness theorems, ansatzes, or renamings of known results appear in the provided abstract. The work is self-contained as a standard empirical benchmarking contribution with independent external validation points.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Valentin Charraut, Waël Doulazmi, Thomas Tournaire, and Thibault Buhet
doi: 10.1109/CVPR.2019.00895. Valentin Charraut, Waël Doulazmi, Thomas Tournaire, and Thibault Buhet. V-max: A reinforcement learning framework for autonomous driving.arXiv preprint arXiv:2503.08388,
-
[2]
doi: 10.1109/ICRA57147.2024.10611364. Daphne Cornelisse, Aarav Pandya, Kevin Joseph, Joseph Suárez, and Eugene Vinitsky. Building reliable sim driving agents by scaling self-play,
-
[3]
Radiance fields for robotic teleoperation,
doi: 10.1109/IROS58592.2024.10803052. Zhiyu Huang, Peter Karkus, Boris Ivanovic, Yuxiao Chen, Marco Pavone, and Chen Lv. Dtpp: Dif- ferentiable joint conditional prediction and cost evaluation for tree policy planning in autonomous driving. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6806–6812,
-
[4]
Carl: Learning scalable planning policies with simple rewards,
Bernhard Jaeger, Daniel Dauner, Jens Beißwenger, Simon Gerstenecker, Kashyap Chitta, and An- dreas Geiger. Carl: Learning scalable planning policies with simple rewards.arXiv preprint arXiv:2504.17838, 2025a. Bernhard Jaeger, Daniel Dauner, Jens Beißwenger, Simon Gerstenecker, Kashyap Chitta, and Andreas Geiger. Carl: Learning scalable planning policies w...
-
[5]
doi: 10.1109/ICRA57147.2024.10611484. Saman Kazemkhani, Aarav Pandya, Daphne Cornelisse, Brennan Shacklett, and Eugene Vinitsky. Gpudrive: Data-driven, multi-agent driving simulation at 1 million fps. InProceedings of the International Conference on Learning Representations (ICLR),
-
[6]
The waymo open sim agents challenge
Nico Montali, John Lambert, Paul Arber, Nick Bber, et al. The waymo open sim agents challenge. In NeurIPS 2023 Datasets and Benchmarks Track,
work page 2023
-
[7]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.ArXiv, abs/1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
ISSN 1095-3787. doi: 10.1103/physreve.62.1805. Wei Wu, Xiaoxin Feng, Ziyan Gao, and Yuheng Kan. Smart: Scalable multi-agent real-time motion generation via next-token prediction. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 114048–114071. C...
-
[9]
Yuan Yin, Pegah Khayatan, Éloi Zablocki, Alexandre Boulch, and Matthieu Cord
doi: 10.52202/079017-3622. Yuan Yin, Pegah Khayatan, Éloi Zablocki, Alexandre Boulch, and Matthieu Cord. Regents: Real- world safety-critical driving scenario generation made stable. InEuropean Conference on Computer Vision, pages 262–276. Springer,
-
[10]
11 A Related Work In this section, we review datasets and benchmarks that support closed-loop simulation, distinguishing our scope from perception-centric prediction benchmarks like nuScenes [Caesar et al., 2020] or Argoverse [Chang et al., 2019]. We include the Waymo Open Motion Dataset (WOMD) [Ettinger et al., 2021] due to its essential role in validati...
work page 2020
-
[11]
A.1 Datasets and Benchmarks nuPlan [Karnchanachari et al., 2024] serves as the primary large-scale dataset and benchmark for closed-loop planning, comprising 1,282 hours of driving data from four cities with high-fidelity object tracks, traffic lights, and over 70 scenario types. Several benchmarks have been proposed on top of nuPlan to evaluate closed-lo...
work page 2024
-
[12]
This comparison provides the necessary context to understand how BehaviorBench relates to existing tools in terms of functionality and performance across these core categories. Supported Datasets and BenchmarksThe field of autonomous driving simulation ranges from localized, synthetic environments to massive-scale, real-world data integration to enhance m...
work page 2023
-
[13]
instantiates the corresponding behavior. Unconditional Conditioned Encoder branches ego, road, partner + c_reward Shared embedding input[h ego;h road;h part] [h ego;h road;h part;h c] Recurrent core LSTM LSTM Actor / Critic discrete 91 / scalar discrete 91 / scalar #Parameters 614k 635k Table 7: Side-by-side summary. The conditioned variant differs only i...
work page 2025
-
[14]
0 1 5 10 20 40 Horizon 25 30 35 40 45 50 55Runtime [ms] Interactive1k 0 1 5 10 20 40 Horizon Random1k Figure 9: Per-step runtime of the PDM+PPO hybrid planner as a function of the planning horizon on Interactive1k (left) and Random1k (right). Each red marker reports the mean per-step runtime in ms over all scenarios for one traffic agent type, and the box...
work page 2024
-
[15]
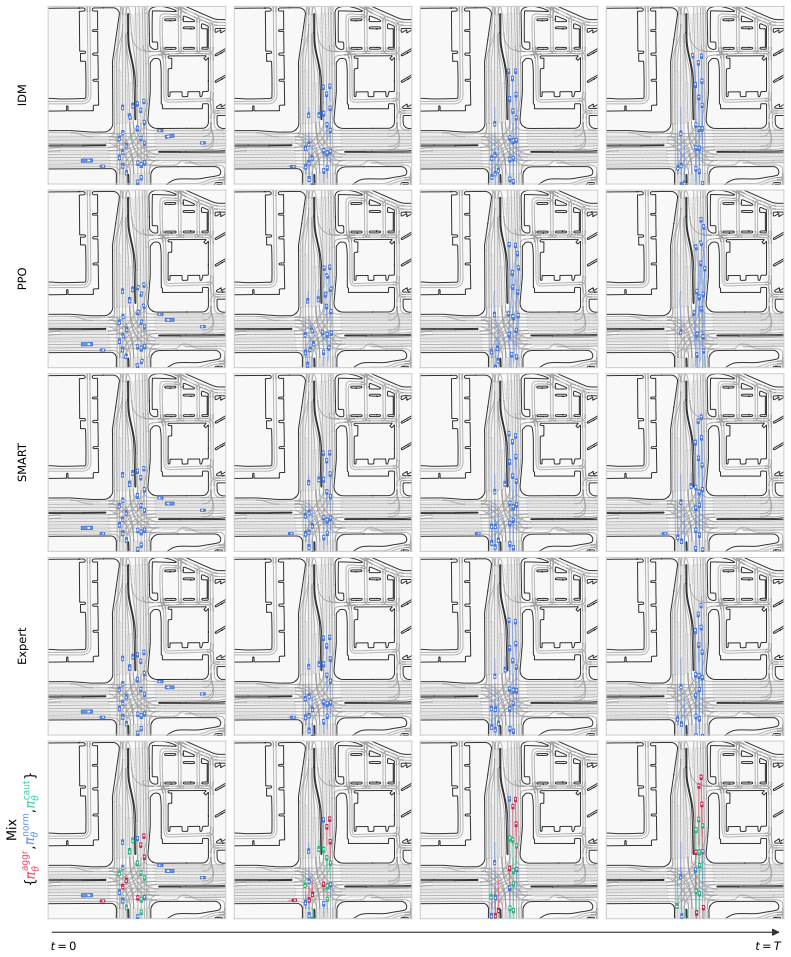
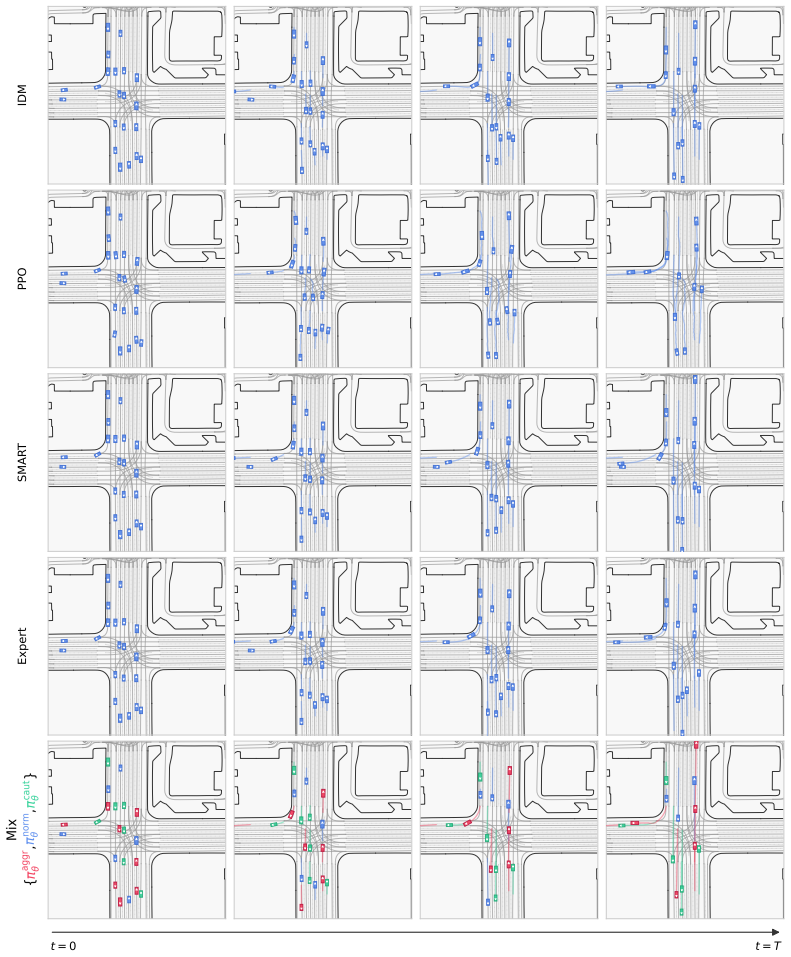
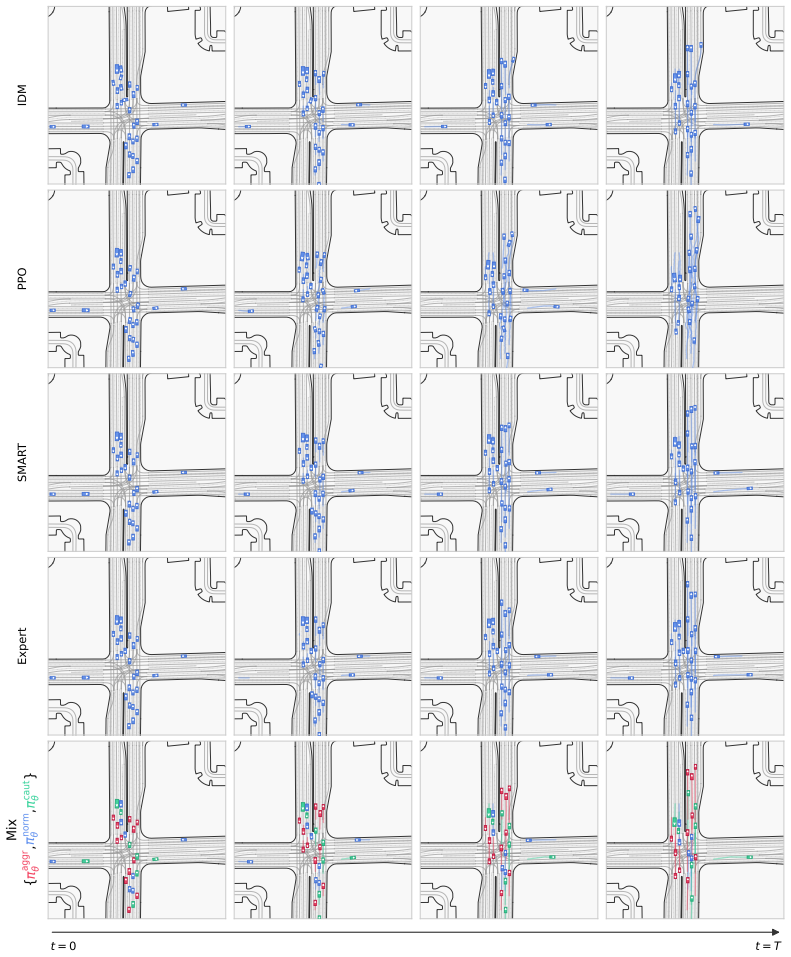
We observe that the conditioned traffic agents exhibit behavior consistent with the intended conditioning. Positive examples are shown in Fig.12, Fig.13, and Fig.19. In particular, the aggressive agents in red tend to drive faster and overtake other vehicles more frequently than the other agent types. Such an overtaking maneuver is shown in Fig.13, where ...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.