Recognition: 2 theorem links
· Lean TheoremGuided Streaming Stochastic Interpolant Policy
Pith reviewed 2026-05-12 02:46 UTC · model grok-4.3
The pith
By deriving the optimal guidance term for Stochastic Interpolants through Backward Kolmogorov Equation analysis of the value function, the paper establishes a modified drift that guarantees sampling from target distributions in a streaming
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Analyzing the value function's time evolution via the Backward Kolmogorov Equation establishes a modified drift for Stochastic Interpolants that theoretically guarantees sampling from a target distribution, which is then unified with a streaming architecture to support fast and reactive robot control.
What carries the argument
The modified drift term derived from the Backward Kolmogorov Equation for guiding the Stochastic Interpolant process in a streaming policy framework.
Load-bearing premise
The analysis via the Backward Kolmogorov Equation provides a modified drift applicable to the streaming architecture without needing extra approximations.
What would settle it
Observing that the generated trajectories from the guided streaming policy do not converge to the target distribution or that the method shows no improvement in reactivity during physical robot experiments.
Figures





read the original abstract
Inference-time guidance is essential for steering generative robot policies toward dynamic objectives without retraining, yet existing methods are largely confined to chunk-based architectures that exhibit high latency and lack the reactivity needed for test-time preference alignment or obstacle avoidance. In this work, we formally derive the optimal guidance term for Stochastic Interpolants (SI) by analyzing the value function's time evolution via the Backward Kolmogorov Equation, establishing a modified drift that theoretically guarantees sampling from a target distribution. We apply this framework to real-time control through the Streaming Stochastic Interpolant Policy (SSIP), which generalizes the deterministic Streaming Flow Policy (SFP). Unifying this guidance law with the streaming architecture enables fast and reactive control. To support diverse deployment needs, we propose two complementary mechanisms: training-free Stochastic Trajectory Ensemble Guidance (STEG) that computes gradients on-the-fly for zero-shot adaptation, and training-based Conditional Critic Guidance (CCG) for amortized inference. Empirical evaluations demonstrate that our guided streaming approach significantly outperforms conventional chunk-based policies in reactivity and provides superior, physically valid guidance for dynamic, unstructured environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to formally derive an optimal guidance term for Stochastic Interpolants by analyzing the value function's time evolution via the Backward Kolmogorov Equation, yielding a modified drift that theoretically guarantees sampling from a target distribution. This is applied to real-time robot control via the Streaming Stochastic Interpolant Policy (SSIP), which generalizes the deterministic Streaming Flow Policy (SFP). Two mechanisms are introduced: training-free Stochastic Trajectory Ensemble Guidance (STEG) for zero-shot adaptation and training-based Conditional Critic Guidance (CCG) for amortized inference. Empirical evaluations are said to show superior reactivity and physically valid guidance over conventional chunk-based policies in dynamic environments.
Significance. If the continuous-time derivation extends rigorously to the discrete streaming setting without unaccounted distribution shift, the work would provide a principled unification of stochastic guidance with low-latency reactive policies, enabling test-time adaptation for obstacle avoidance and preference alignment in robotics without retraining. The formal BKE grounding and generalization from SFP are strengths if the discretization gap is closed.
major comments (2)
- [Abstract and BKE derivation section] Abstract and derivation (BKE analysis): The central claim that the modified drift 'theoretically guarantees sampling from a target distribution' rests on continuous-time Backward Kolmogorov Equation analysis of the value function. However, SSIP is a discrete-time streaming architecture for low-latency control; the manuscript does not show that the guidance term remains optimal or unbiased after discretization, nor does it quantify the resulting distribution shift or handle additional Itô terms explicitly.
- [SSIP architecture and unification section] § on SSIP architecture and unification with SFP: The generalization from deterministic SFP to stochastic SSIP is presented as enabling fast reactive control, but the paper provides no explicit proof or empirical verification that the stochastic guidance law preserves the target distribution under the streaming (non-chunked) discretization required for real-time deployment.
minor comments (2)
- [Empirical evaluations] The abstract mentions 'physically valid guidance' but does not define the metric or provide quantitative validation in the empirical section; clarify how physical validity is measured beyond qualitative description.
- [Derivation] Notation for the modified drift term should be introduced with an explicit equation number in the derivation to improve traceability from BKE to the SSIP implementation.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our work. We appreciate the emphasis on rigorously bridging the continuous-time theoretical derivation with the discrete-time streaming implementation. Below, we provide point-by-point responses to the major comments and outline the revisions we will make to address them.
read point-by-point responses
-
Referee: [Abstract and BKE derivation section] Abstract and derivation (BKE analysis): The central claim that the modified drift 'theoretically guarantees sampling from a target distribution' rests on continuous-time Backward Kolmogorov Equation analysis of the value function. However, SSIP is a discrete-time streaming architecture for low-latency control; the manuscript does not show that the guidance term remains optimal or unbiased after discretization, nor does it quantify the resulting distribution shift or handle additional Itô terms explicitly.
Authors: We acknowledge that our derivation of the optimal guidance term is performed in the continuous-time limit using the Backward Kolmogorov Equation, as detailed in Section 3. The SSIP architecture discretizes this process using a first-order scheme with small time increments to enable real-time streaming control. The current version of the manuscript does not explicitly analyze the discretization error or the additional Itô terms arising from the stochastic differential equation. We agree this is an important point for rigor. In the revised manuscript, we will add a dedicated subsection in the methods or theory section that derives the discrete-time guidance law, accounts for Itô corrections where applicable, and provides a bound on the distribution shift under standard regularity assumptions (e.g., Lipschitz continuity of the drift and diffusion terms). We will also include numerical experiments quantifying the shift for the time steps used in our robotic evaluations. revision: yes
-
Referee: [SSIP architecture and unification section] § on SSIP architecture and unification with SFP: The generalization from deterministic SFP to stochastic SSIP is presented as enabling fast reactive control, but the paper provides no explicit proof or empirical verification that the stochastic guidance law preserves the target distribution under the streaming (non-chunked) discretization required for real-time deployment.
Authors: The unification with SFP is presented to highlight the generalization to stochastic policies while maintaining the low-latency streaming property. We recognize that the manuscript lacks both a formal proof of distribution preservation in the discrete streaming setting and direct empirical verification of this property. To address this, the revised version will include: (1) a theoretical remark noting that as the discretization step size approaches zero, the discrete process converges to the continuous guided process whose marginals match the target by construction of the BKE-derived drift; (2) new empirical results in the experiments section comparing the empirical distribution of generated trajectories under streaming SSIP to the target distribution, using appropriate distance metrics. This will provide both theoretical grounding and practical validation for the real-time deployment scenario. revision: yes
Circularity Check
BKE derivation provides independent grounding for guidance term
full rationale
The paper's central claim derives the optimal guidance term for Stochastic Interpolants by applying the Backward Kolmogorov Equation to the value function's time evolution, yielding a modified drift. This step uses a standard external mathematical tool from stochastic calculus and is not constructed from the paper's own fitted parameters, definitions, or prior results by construction. The subsequent application to the SSIP streaming architecture and generalization of deterministic SFP is framed as an implementation choice rather than a load-bearing premise that reduces the derivation to self-referential inputs. No self-definitional equivalences, renamed empirical patterns, or unverified self-citation chains appear in the derivation chain as described.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The Backward Kolmogorov Equation governs the time evolution of the value function in the stochastic interpolant setting
invented entities (1)
-
modified drift
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive the exact guidance law ... Δb(x,t,ξ)≜2ϵ(t)∇x log u(x,t,ξ) (Eq. 12); J(τ;ξ)=∫c ds + ϕ (Eq. 5)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Michael Albergo, Nicholas M Boffi, and Eric Vanden- Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209):1–80, 2025
work page 2025
-
[2]
Real-time execution of action chunking flow policies
Kevin Black, Manuel Y Galliker, and Sergey Levine. Real-time execution of action chunking flow policies. In The Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2025. URL https://openreview. net/forum?id=UkR2zO5uww
work page 2025
-
[3]
Don’t Start From Scratch: Behavioral Refinement via Interpolant-based Policy Diffusion
Kaiqi Chen, Eugene Lim, Kelvin Lin, Yiyang Chen, and Harold Soh. Don’t Start From Scratch: Behavioral Refinement via Interpolant-based Policy Diffusion. In Proceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024. doi: 10.15607/RSS.2024.XX. 122
-
[4]
Dif- fusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Dif- fusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[5]
Diffusion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael Thompson Mc- Cann, Marc Louis Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[6]
Safebimanual: Diffusion-based trajectory optimization for safe bimanual manipulation
Haoyuan Deng, Wenkai Guo, Qianzhun Wang, Zhenyu Wu, and Ziwei Wang. Safebimanual: Diffusion-based trajectory optimization for safe bimanual manipulation. In9th Annual Conference on Robot Learning, 2025
work page 2025
-
[7]
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
work page 2021
-
[8]
On the guidance of flow matching
Ruiqi Feng, Chenglei Yu, Wenhao Deng, Peiyan Hu, and Tailin Wu. On the guidance of flow matching. InForty- second International Conference on Machine Learning, 2025
work page 2025
-
[9]
Zeyu Feng, Hao Luan, Pranav Goyal, and Harold Soh. LTLDoG: Satisfying temporally-extended symbolic con- straints for safe diffusion-based planning.IEEE Robotics and Automation Letters, 2024
work page 2024
-
[10]
Alexandros Graikos, Nikolay Malkin, Nebojsa Jojic, and Dimitris Samaras. Diffusion models as plug-and-play priors.Advances in Neural Information Processing Systems, 35:14715–14728, 2022
work page 2022
-
[11]
Ce Hao, Kelvin Lin, Zhiwei Xue, Siyuan Luo, and Harold Soh. Disco: Language-guided manipulation with diffusion policies and constrained inpainting.IEEE Robotics and Automation Letters, 2025
work page 2025
-
[12]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural infor- mation processing systems, 33:6840–6851, 2020
work page 2020
-
[13]
Planning with diffusion for flexible behavior synthesis
Michael Janner, Yilun Du, Joshua Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. InInternational Conference on Machine Learning, 2022
work page 2022
-
[14]
Sunshine Jiang, Xiaolin Fang, Nicholas Roy, Tom ´as Lozano-P´erez, Leslie Pack Kaelbling, and Siddharth An- cha. Streaming flow policy: Simplifying diffusion/ flow-matching policies by treating action trajectories as flow trajectories. In9th Annual Conference on Robot Learning, 2025
work page 2025
-
[15]
Flowdps: Flow-driven posterior sampling for inverse problems
Jeongsol Kim, Bryan Sangwoo Kim, and Jong Chul Ye. Flowdps: Flow-driven posterior sampling for inverse problems. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12328–12337, 2025
work page 2025
-
[16]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[17]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Con- ference on Learning Representations, 2023
work page 2023
-
[18]
Consistency policy: Accelerated visuo- motor policies via consistency distillation
Aaditya Prasad, Kevin Lin, Jimmy Wu, Linqi Zhou, and Jeannette Bohg. Consistency policy: Accelerated visuo- motor policies via consistency distillation. InRobotics: Science and Systems, 2024
work page 2024
-
[19]
Allen Z. Ren, Justin Lidard, Lars Lien Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Ben- jamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[20]
Score- based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score- based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2021
work page 2021
-
[21]
Training free guided flow-matching with optimal control
Luran Wang, Chaoran Cheng, Yizhen Liao, Yanru Qu, and Ge Liu. Training free guided flow-matching with optimal control. InThe Thirteenth International Confer- ence on Learning Representations, 2025
work page 2025
-
[22]
Inference-time policy steering through human interactions
Yanwei Wang, Lirui Wang, Yilun Du, Balakumar Sun- daralingam, Xuning Yang, Yu-Wei Chao, Claudia P ´erez- D’Arpino, Dieter Fox, and Julie Shah. Inference-time policy steering through human interactions. In2025 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 15626–15633. IEEE, 2025
work page 2025
-
[23]
One-step diffusion policy: Fast visuomotor policies via diffusion distillation
Zhendong Wang, Max Li, Ajay Mandlekar, Zhenjia Xu, Jiaojiao Fan, Yashraj Narang, Linxi Fan, Yuke Zhu, Yo- gesh Balaji, Mingyuan Zhou, Ming-Yu Liu, and Yu Zeng. One-step diffusion policy: Fast visuomotor policies via diffusion distillation. InForty-second International Con- ference on Machine Learning, 2025
work page 2025
-
[24]
Reactive dif- fusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation
Han Xue, Jieji Ren, Wendi Chen, Gu Zhang, Yuan Fang, Guoying Gu, Huazhe Xu, and Cewu Lu. Reactive dif- fusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation. InProceedings of Robotics: Science and Systems (RSS), 2025
work page 2025
-
[25]
Sixu Yan, Zeyu Zhang, Muzhi Han, Zaijin Wang, Qi Xie, Zhitian Li, Zhehan Li, Hangxin Liu, Xinggang Wang, and Song-Chun Zhu. M 2 diffuser: Diffusion-based trajectory optimization for mobile manipulation in 3d scenes.IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2025
work page 2025
-
[26]
Jiwen Yu, Yinhuai Wang, Chen Zhao, Bernard Ghanem, and Jian Zhang. Freedom: Training-free energy-guided conditional diffusion model. In2023 IEEE/CVF Inter- national Conference on Computer Vision (ICCV), pages 23117–23127, 2023. doi: 10.1109/ICCV51070.2023. 02118
-
[27]
Improving diffusion inverse problem solving with decoupled noise annealing
Bingliang Zhang, Wenda Chu, Julius Berner, Chenlin Meng, Anima Anandkumar, and Yang Song. Improving diffusion inverse problem solving with decoupled noise annealing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20895–20905, 2025
work page 2025
-
[28]
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InProceedings of Robotics: Science and Systems (RSS), 2023. APPENDIXA EXTENDEDFORMULATION OFSSIP In this section, we provide the rigorous mathematical deriva- tion of the Streaming Stochastic Interpolant Policy (SSIP), extending ...
work page 2023
-
[29]
Velocity Matching:The velocity networkv θ(at, t)learns the stabilizing vector field of the underlying flow. It is trained to regress the SFP drift even when the input state is perturbed by the additional SI noise: Lvel(θ) =E t,ξ,ϵ,z ∥vθ(at, t)−v SF P (aSF P t |ξ)∥2 (33) wherea SF P t =ξ t +σ(t)ϵis the unperturbed SFP state
-
[30]
Score Matching:The denoiser networkη θ(at, t)esti- mates the added SI noisez. This is trained via standard denoising score matching: Lscore(θ) =E t,at,z ∥ηθ(at, t)−z∥ 2 (34) The analytical score of the conditional distribution is then given bys θ(at, t)≈ − ηθ(at,t) γ(t) . We avoid directly regressing the score function because it scales with1/γ(t), which ...
-
[31]
The Physical Oracle (S ∗):We define the optimal guid- ance scoreS ∗(a)as the gradient of the log-expected utility under the true physics. This formulation aligns with the derivation in Section III-D, omitting the scaling factor for simplicity: S∗(a) =∇ a logE ϵ h e−J(Φ phy(a,ϵ)) i (37) By applying thereparameterization trick, the expectation is taken over...
-
[32]
The Estimator Gradient ( ˆS):Since the ground truth physical oracle is inaccessible, STEG approximates future trajectories. We define an estimator distributionq(τ|a)via the learned differentiable surrogateτ= Φ est(a,z), wherezis the noise injected during the SDE rollout. Analogous to the physical derivation, the STEG gradient (computed via Log- SumExp in ...
-
[33]
Term I: Distributional Shift (Coverage Error):Term I measures the support mismatch between the estimatorqand the physicsp. •Problem:If the physical safety landscape is multi-modal (e.g., passing an obstacle on the left or right) but the estimatorqis too narrow or uses a single deterministic rollout,q saf e may collapse to a single mode or miss the safe re...
-
[34]
Term II: Dynamics Mismatch (Jacobian Error):Term II measures the alignment error between the modeled and physical dynamics, weighted by the safety of the trajectory. •Problem:Even if the trajectories are kinematically sim- ilar, if the Jacobians diverge (J est ̸=J phy), the guidance force will point in a physically invalid direction (e.g., commanding inst...
-
[35]
Network Architecture:We employ a ResNet-based critic with 6 hidden layers of size 1024. The networkV ψ(at, t,h, ϕ) conditions on the current actiona t, diffusion timet, the history embeddingh(extracted from the frozen policy encoder), and obstacle parametersϕ
-
[36]
Training Objective:We train the critic using a regression approach anchored by Monte Carlo rollouts collected from the frozen base policy. For a sampled tuple(a t,h, ϕ), we simulate Kparallel future trajectories{τ (k)}K k=1 using the base SSIP dynamics and compute an empirical target valuey target. The network minimizes theL 2 regression loss: L=E ∥Vψ(at,...
-
[37]
The trajectory cost is defined as the cumulative distance potential:J(τ) = P exp − ∥x−xobs∥2 2σ2
Cost Variants:We instantiate two variants of CCG by defining different regression targetsy target based on the rollout outcomes: •CCG-D (Distance Potential):The target approximates the log-expected future utility,y target ≈logE[e −J(τ) ]. The trajectory cost is defined as the cumulative distance potential:J(τ) = P exp − ∥x−xobs∥2 2σ2 . •CCG-P (Collision P...
-
[38]
Push-T Task:The goal is to push a T-shaped block to a target pose. The state space consists of the robot end-effector position and the block pose (position and angle). •Observation Space:Low-dimensional state vector, in- cluding agent position(x, y)and block pose(x, y, θ). •Action Space:Continuous control space (2D position for Push-T; End-effector pose f...
-
[39]
Robomimic Tasks:We use the standard Lift, Can, and Square tasks from the Robomimic suite. •Observation Space:Low-dimensional state vector con- sisting of the object state and proprioceptive states (e.g., end-effector pose and gripper joint positions). •Action Space:Continuous control space (End-effector pose for Robomimic). •Simulation Horizon:T= 400steps...
-
[40]
Diffusion Policy with Reconstruction Guidance [13]: This method follows the classifier-guidance paradigm, utiliz- ing the intermediate diffusion statex t to estimate the clean trajectoryx 0 for gradient calculation. a) Reconstruction & Gradient Injection.:At each reverse diffusion stept, we estimate the clean dataˆx 0 from the current noisy samplex t and ...
-
[41]
Flow Policy Guidance [8]:For the flow matching policy, we employ a lookahead mechanism that linearly extrapolates the future state using the current velocity field. a) Lookahead Extrapolation.:During the ODE integra- tion stept∈[0,1], we predict the terminal stateˆx 1 using the current velocityv θ(xt, t): ˆx1 =x t +v θ(xt, t)·(1−t)(50) TABLE V: Hyperparam...
-
[42]
We apply this to the drift term of the SSIP
Naive Repulsive Guidance (SSIP):As a non-learning baseline, this method applies an analytical repulsive potential field directly to the action space without backpropagation. We apply this to the drift term of the SSIP. a) Repulsive Force:We define a repulsive vector based solely on the geometric distancedbetween the current trajec- tory pointx t and the o...
-
[43]
•Inference Latency:Measured as the average wall-clock time per control step
Metrics Definition: •Task Success:A trajectory is considered successful if no collision and the final reward exceeds 85% (Push-T) or if the object is successfully placed/lifted (Robomimic). •Inference Latency:Measured as the average wall-clock time per control step. Note that for chunk-based baselines (DP, FP), the generation time is amortized over the ex...
-
[44]
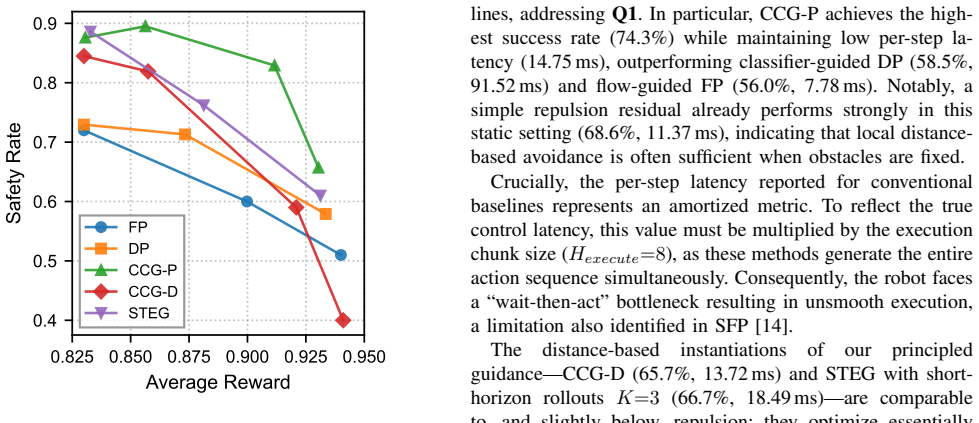
Compute Hardware:All experiments and latency mea- surements were conducted on a workstation with the following specifications: •CPU:AMD EPYC 7543 Processor. •GPU:Single NVIDIA RTX A5000. •Framework:PyTorch with CUDA acceleration. E. Complete Trade-off Plot Figure 6 presents the complete Pareto frontier of safety versus task performance. We observe several...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.