Recognition: no theorem link
STAR: Failure-Aware Markovian Routing for Multi-Agent Spatiotemporal Reasoning
Pith reviewed 2026-05-13 03:42 UTC · model grok-4.3
The pith
Failure-aware Markovian routing learns recovery transitions from unsuccessful execution traces for multi-agent spatiotemporal reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
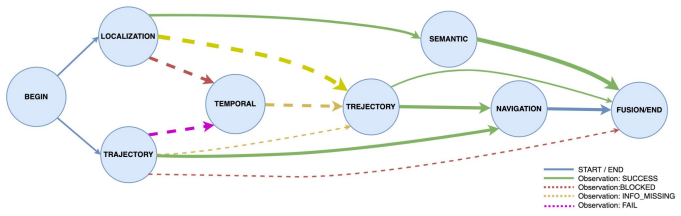
STAR externalizes inter-agent control as a state-conditioned transition policy over the current agent, task type, and typed execution status. At its center is an agent routing matrix that merges expert-specified nominal routes with recovery transitions learned from execution traces. Conditioning on distinct failure states lets the router distinguish malformed outputs, missing dependencies, and tool-query mismatches rather than collapsing them into a generic retry. Retaining unsuccessful traces during training enlarges the support of the routing policy on error states, enabling recovery transitions that success-only training cannot represent. This yields improvements over baselines on three时空
What carries the argument
The agent routing matrix that merges expert nominal routes with failure-conditioned recovery transitions learned from execution traces, allowing differentiated responses to specific error types.
If this is right
- Retaining unsuccessful traces enlarges the support of the routing policy on error states.
- This enables recovery transitions that success-only training cannot represent.
- Improvements appear across three spatiotemporal benchmarks and eight backbone LLMs.
- The largest gains occur on queries whose execution deviates from the nominal routing path.
- Typed failure-aware routing contributes more than specialist composition alone.
Where Pith is reading between the lines
- The same matrix structure could be applied to other compositional tasks that involve heterogeneous agents or tools.
- Explicit failure typing may reduce reliance on hand-crafted retry logic in broader LLM agent systems.
- If failure categories prove stable, the approach could support incremental updates to the routing matrix as new error patterns appear.
Load-bearing premise
Distinct failure types can be reliably identified and classified from execution traces, and the learned recovery transitions will generalize beyond the training traces to new queries.
What would settle it
A direct comparison on the same benchmarks where a router trained only on successful traces matches or exceeds the performance of the failure-aware version on queries that require recovery from execution errors.
Figures






read the original abstract
Compositional spatiotemporal reasoning often requires a system to invoke multiple heterogeneous specialists, such as geometric, temporal, topological, and trajectory agents. A central question is how such a system should route among specialists when execution does not simply succeed or fail, but fails in qualitatively different ways. Existing tool-augmented and multi-agent LLM systems typically leave this routing decision implicit in language generation, making recovery ad hoc, difficult to interpret, and hard to optimize. This paper presents STAR (Spatio-Temporal Agent Router), a failure-aware routing framework that externalizes inter-agent control as a state-conditioned transition policy over the current agent, task type, and typed execution status. At the center of STARis an agent routing matrix that combines expert-specified nominal routes with recovery transitions learned from execution traces. Because the matrix conditions on distinct failure states, the router can respond differently to malformed outputs, missing dependencies, and tool--query mismatches, rather than collapsing them into a generic retry signal. Specialists execute through a tool-grounded extract--compute--deposit protocol and write intermediate results to a shared blackboard for downstream fusion. Results prove that retaining unsuccessful traces during training enlarges the support of the routing policy on error states, enabling recovery transitions that success-only training cannot represent. Across three spatiotemporal benchmarks and eight backbone LLMs, STAR improves over multiple baselines with the clearest gains on queries whose execution deviates from the nominal routing path. Router-specific ablations and recovery analyses further show that typed failure-aware routing, rather than specialist composition alone, is a key factor for these improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STAR, a failure-aware Markovian routing framework for multi-agent spatiotemporal reasoning. It externalizes inter-agent control as a state-conditioned transition policy over the current agent, task type, and typed execution status (e.g., malformed outputs, missing dependencies, tool-query mismatches). The routing matrix combines expert-specified nominal routes with recovery transitions learned from execution traces that include unsuccessful cases. The central claim is that retaining unsuccessful traces enlarges the support of the routing policy on error states, enabling recovery transitions unavailable under success-only training. Empirical results across three spatiotemporal benchmarks and eight backbone LLMs show improvements over baselines, with largest gains on queries whose execution deviates from the nominal path; ablations attribute gains to typed failure-aware routing.
Significance. If the central claims hold after addressing methodological gaps, the work offers a concrete mechanism for making routing decisions explicit and optimizable in multi-agent LLM systems, moving beyond implicit language-based recovery. Learning recovery transitions from typed failure traces is a promising direction for robustness in compositional tool-use settings. The multi-benchmark, multi-LLM evaluation provides a reasonable testbed, and the distinction between nominal and recovery transitions could influence future agent architectures if the generalization properties are demonstrated.
major comments (3)
- [Abstract] Abstract: The statement that 'Results prove that retaining unsuccessful traces during training enlarges the support of the routing policy on error states' is presented as a core result, yet the manuscript provides no mathematical definition of the routing matrix, no derivation of policy support, and no proof or formal argument showing enlargement. This is load-bearing for the central theoretical claim.
- [Experimental Evaluation] Experimental sections: No description is given of the failure-typing procedure (how malformed outputs, missing dependencies, and tool-query mismatches are reliably partitioned into distinct, non-overlapping categories), baseline definitions, statistical testing, or hold-out protocols that introduce novel failure categories or out-of-distribution queries. Without these, it is impossible to determine whether reported gains reflect genuine enlargement of support or interpolation within the training failure distribution.
- [Ablation Studies] Ablation and recovery analyses: The claim that 'typed failure-aware routing, rather than specialist composition alone, is a key factor' rests on router-specific ablations, but the manuscript does not report effect sizes, controls for training-data distribution, or comparisons that isolate the contribution of typed failure conditioning from other factors such as trace volume or blackboard usage.
minor comments (2)
- [Abstract] Abstract contains the typo 'STARis' (should be 'STAR is').
- [Abstract] Abstract uses inconsistent hyphenation ('tool--query' with double dash); standardize to 'tool-query'.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas for clarification in the presentation of the routing matrix, experimental protocols, and ablation controls. We address each point below and will revise the manuscript accordingly to strengthen the methodological transparency while preserving the core empirical contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that 'Results prove that retaining unsuccessful traces during training enlarges the support of the routing policy on error states' is presented as a core result, yet the manuscript provides no mathematical definition of the routing matrix, no derivation of policy support, and no proof or formal argument showing enlargement. This is load-bearing for the central theoretical claim.
Authors: We agree that the abstract's use of 'prove' is imprecise for an empirical result and that a formal definition of the routing matrix and policy support should be provided in the main text. The routing matrix is defined in Section 3.2 as the state-conditioned transition matrix M(s, a, f) combining expert-specified nominal routes with learned recovery transitions, where s encodes (current_agent, task_type), a is the next agent, and f is the typed failure status. Policy support refers to the set of reachable (state, action) pairs under the induced Markov chain. Enlargement is demonstrated empirically by the additional recovery transitions present when unsuccessful traces are retained (Figure 4). We did not include a formal derivation or proof, as the work focuses on the algorithmic framework and empirical validation rather than theoretical bounds on support size. We will revise the abstract to 'empirically demonstrate,' add an explicit mathematical definition of the matrix and support in Section 3, and include a brief structural argument based on the expanded state space. revision: yes
-
Referee: [Experimental Evaluation] Experimental sections: No description is given of the failure-typing procedure (how malformed outputs, missing dependencies, and tool-query mismatches are reliably partitioned into distinct, non-overlapping categories), baseline definitions, statistical testing, or hold-out protocols that introduce novel failure categories or out-of-distribution queries. Without these, it is impossible to determine whether reported gains reflect genuine enlargement of support or interpolation within the training failure distribution.
Authors: We will add a dedicated subsection in the experimental setup detailing the failure-typing procedure: failures are classified automatically from execution logs using rule-based detectors with priority ordering to ensure mutual exclusivity (malformed outputs via parse errors, missing dependencies via graph resolution failures, tool-query mismatches via embedding similarity threshold). Baselines are the standard LLM router, success-only router, and untyped failure router, all using the same backbone LLMs. Statistical testing consists of mean and standard deviation over three random seeds with paired t-tests for significance (p-values reported in supplementary material). The hold-out protocol is an 80/20 query split within each benchmark; failure types are drawn from the same distribution as training traces, with no novel OOD failure categories introduced. We will clarify that the gains reflect improved recovery within the observed failure distribution rather than extrapolation to unseen failure types, and add pseudocode for the typing rules. revision: yes
-
Referee: [Ablation Studies] Ablation and recovery analyses: The claim that 'typed failure-aware routing, rather than specialist composition alone, is a key factor' rests on router-specific ablations, but the manuscript does not report effect sizes, controls for training-data distribution, or comparisons that isolate the contribution of typed failure conditioning from other factors such as trace volume or blackboard usage.
Authors: The router ablations (Table 3) compare the full typed failure-aware router against untyped failure (all failures collapsed to one category) and success-only variants, with trace volume and blackboard usage held constant across conditions. We report accuracy as mean ± standard deviation; raw deltas between conditions can be derived from the table. To further isolate typed conditioning, all variants are trained on identical trace sets, differing only in the failure-state representation. We will expand the ablation section to explicitly report effect sizes (e.g., accuracy deltas and Cohen's d), add a supplementary control varying trace volume while fixing typing, and clarify that blackboard usage is shared. A complete factorial isolation of every factor would require additional runs; we will perform and report the most critical controls within space limits. revision: partial
Circularity Check
No significant circularity; empirical validation is self-contained
full rationale
The paper's central claim—that retaining unsuccessful traces enlarges policy support on error states—is presented as an empirical result from training and benchmarking on spatiotemporal tasks, not as a mathematical derivation or first-principles prediction. No equations, self-citations, or ansatzes are invoked in the abstract or described structure that would reduce the reported gains to a definitional equivalence or fitted input by construction. The framework is validated across multiple benchmarks and LLMs with ablations, making the derivation chain independent of its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- recovery transition parameters
axioms (1)
- domain assumption Typed failure states provide distinguishable and actionable signals for routing decisions
Reference graph
Works this paper leans on
-
[1]
Mohamed Aghzal, Erion Plaku, and Ziyu Yao. Can large language models be good path planners? a benchmark and investigation on spatial-temporal reasoning.arXiv preprint arXiv:2310.03249, 2023
-
[2]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 17682–17690, 2024
work page 2024
-
[3]
Zixu Cheng, Jian Hu, Ziquan Liu, Chenyang Si, Wei Li, and Shaogang Gong. V-star: Bench- marking video-llms on video spatio-temporal reasoning.arXiv preprint arXiv:2503.11495, 2025
-
[4]
A., Tihanyi, N., and Debbah, M
Mohamed Amine Ferrag, Norbert Tihanyi, and Merouane Debbah. From llm reasoning to autonomous ai agents: A comprehensive review.arXiv preprint arXiv:2504.19678, 2025
-
[5]
Yubin Ge, Salvatore Romeo, Jason Cai, Raphael Shu, Yassine Benajiba, Monica Sunkara, and Yi Zhang. Tremu: Towards neuro-symbolic temporal reasoning for llm-agents with memory in multi-session dialogues. InFindings of the Association for Computational Linguistics: ACL 2025, pages 18974–18988, 2025
work page 2025
-
[6]
Md Arafat Habib, Pedro Enrique Iturria Rivera, Yigit Ozcan, Medhat Elsayed, Majid Bavand, Raimundus Gaigalas, and Melike Erol-Kantarci. Llm-based intent processing and network optimization using attention-based hierarchical reinforcement learning. In2025 IEEE Wireless Communications and Networking Conference (WCNC), pages 1–6. IEEE, 2025
work page 2025
-
[7]
Bochen Han and Songmao Zhang. Exploring advanced llm multi-agent systems based on blackboard architecture.arXiv preprint arXiv:2507.01701, 2025
-
[8]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[9]
Stbench: Assessing the ability of large language models in spatio-temporal analysis
Wenbin Li, Di Yao, Ruibo Zhao, Wenjie Chen, Zijie Xu, Chengxue Luo, Chang Gong, Quanliang Jing, Haining Tan, and Jingping Bi. Stbench: Assessing the ability of large language models in spatio-temporal analysis. InCompanion Proceedings of the ACM on Web Conference 2025, pages 749–752, 2025
work page 2025
-
[10]
Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth, 1(1):9, 2024
work page 2024
-
[11]
Zechen Li, Baiyu Chen, Hao Xue, and Flora D. Salim. Zara: Training-free motion time-series reasoning via evidence-grounded llm agents.arXiv preprint arXiv:2508.04038, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, and Jianfeng Gao. Chameleon: Plug-and-play compositional reasoning with large language models.Advances in Neural Information Processing Systems, 36:43447–43478, 2023
work page 2023
-
[13]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023. 10
work page 2023
-
[14]
Kai Mei, Wujiang Xu, Minghao Guo, Shuhang Lin, and Yongfeng Zhang. Omnirouter: Budget and performance controllable multi-llm routing.ACM SIGKDD Explorations Newsletter, 27(2):107–116, 2025
work page 2025
-
[15]
Juntong Ni, Shiyu Wang, Ming Jin, Qi He, and Wei Jin. Streasoner: Empowering llms for spatio-temporal reasoning in time series via spatial-aware reinforcement learning.arXiv preprint arXiv:2601.03248, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
TaskWeaver: A code-first agent framework,
Bo Qiao, Liqun Li, Xu Zhang, Shilin He, Yu Kang, Chaoyun Zhang, Fangkai Yang, Hang Dong, Jue Zhang, Lu Wang, et al. Taskweaver: A code-first agent framework.arXiv preprint arXiv:2311.17541, 2023
-
[17]
Pengrui Quan, Brian Wang, Kang Yang, Liying Han, and Mani Srivastava. Benchmarking spatiotemporal reasoning in llms and reasoning models: Capabilities and challenges.arXiv preprint arXiv:2505.11618, 2025
-
[18]
Matthew Renze and Erhan Guven. Self-reflection in llm agents: Effects on problem-solving performance.arXiv preprint arXiv:2405.06682, 2024
-
[19]
Alireza Salemi, Mihir Parmar, Palash Goyal, Yiwen Song, Jinsung Yoon, Hamed Zamani, Tomas Pfister, and Hamid Palangi. Llm-based multi-agent blackboard system for information discovery in data science.arXiv preprint arXiv:2510.01285, 2025
-
[20]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
work page 2023
-
[21]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Exploring multi-modal data with tool-augmented llm agents for precise causal discovery
ChengAo Shen, Zhengzhang Chen, Dongsheng Luo, Dongkuan Xu, Haifeng Chen, and Jingchao Ni. Exploring multi-modal data with tool-augmented llm agents for precise causal discovery. In Findings of the Association for Computational Linguistics: ACL 2025, pages 636–660, 2025
work page 2025
-
[23]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[24]
Learning options in reinforcement learning
Martin Stolle and Doina Precup. Learning options in reinforcement learning. InInternational Symposium on abstraction, reformulation, and approximation, pages 212–223. Springer, 2002
work page 2002
-
[25]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi-agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Beyond react: A planner-centric framework for complex tool- augmented llm reasoning
Xiaolong Wei, Yuehu Dong, Xingliang Wang, Xingyu Zhang, Zhejun Zhao, Dongdong Shen, Long Xia, and Dawei Yin. Beyond react: A planner-centric framework for complex tool- augmented llm reasoning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33845–33853, 2026
work page 2026
-
[27]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
work page 2024
-
[28]
Large language models can learn temporal reasoning
Siheng Xiong, Ali Payani, Ramana Kompella, and Faramarz Fekri. Large language models can learn temporal reasoning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10452–10470, 2024
work page 2024
-
[29]
Ruiyi Yang, Hao Xue, Imran Razzak, Hakim Hacid, and Flora D. Salim. Reloop: Recur- sive retrieval with multi-hop reasoner and planners for heterogeneous qa.arXiv preprint arXiv:2510.20505, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
work page 2023
-
[31]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[32]
Yao Yao, Zuchao Li, and Hai Zhao. Got: Effective graph-of-thought reasoning in language models. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 2901–2921, 2024. 12 A Theoretical Proofs and Structural Properties This appendix collects proofs, structural properties, and auxiliary analysis for STAR. Theorem 1 is stated in the m...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.