HYPERPOSE: Hyperbolic Kinematic Phase-Space Attention for 3D Human Pose Estimation
Pith reviewed 2026-05-19 17:40 UTC · model grok-4.3
The pith
3D human pose estimation performed inside hyperbolic space preserves the skeleton's tree structure and avoids the volume distortion that Euclidean methods produce.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
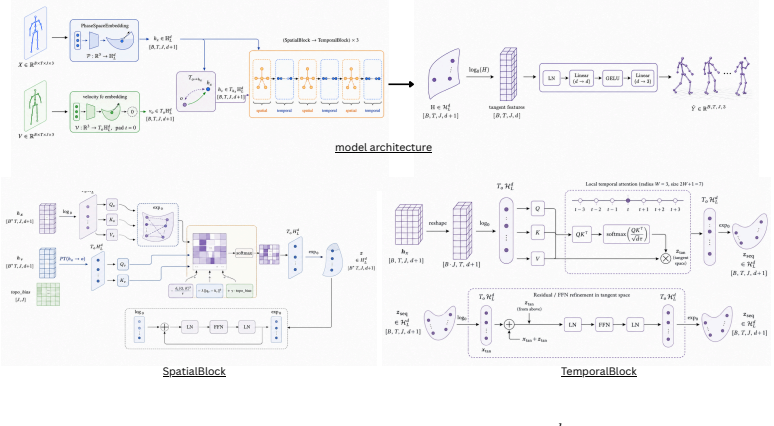
HYPERPOSE performs spatio-temporal reasoning entirely within the Lorentz model of hyperbolic space to natively preserve the hierarchical tree topology of the human skeleton, using Hyperbolic Kinematic Phase-Space Attention to embed joint relationships without distortion and a multi-scale windowed hyperbolic attention mechanism to model temporal dynamics efficiently.
What carries the argument
Hyperbolic Kinematic Phase-Space Attention (HKPSA) operating in the Lorentz model, which embeds complex joint relationships in a curved space that matches the skeleton's tree topology.
Load-bearing premise
That the Lorentz model of hyperbolic space will preserve the hierarchical tree topology of the human skeleton without the exponential volume distortion seen in Euclidean space.
What would settle it
A side-by-side measurement on Human3.6M showing that volume distortion or structural coherence error remains higher than the best Euclidean transformer or graph-convolution baselines under identical training conditions.
Figures


read the original abstract
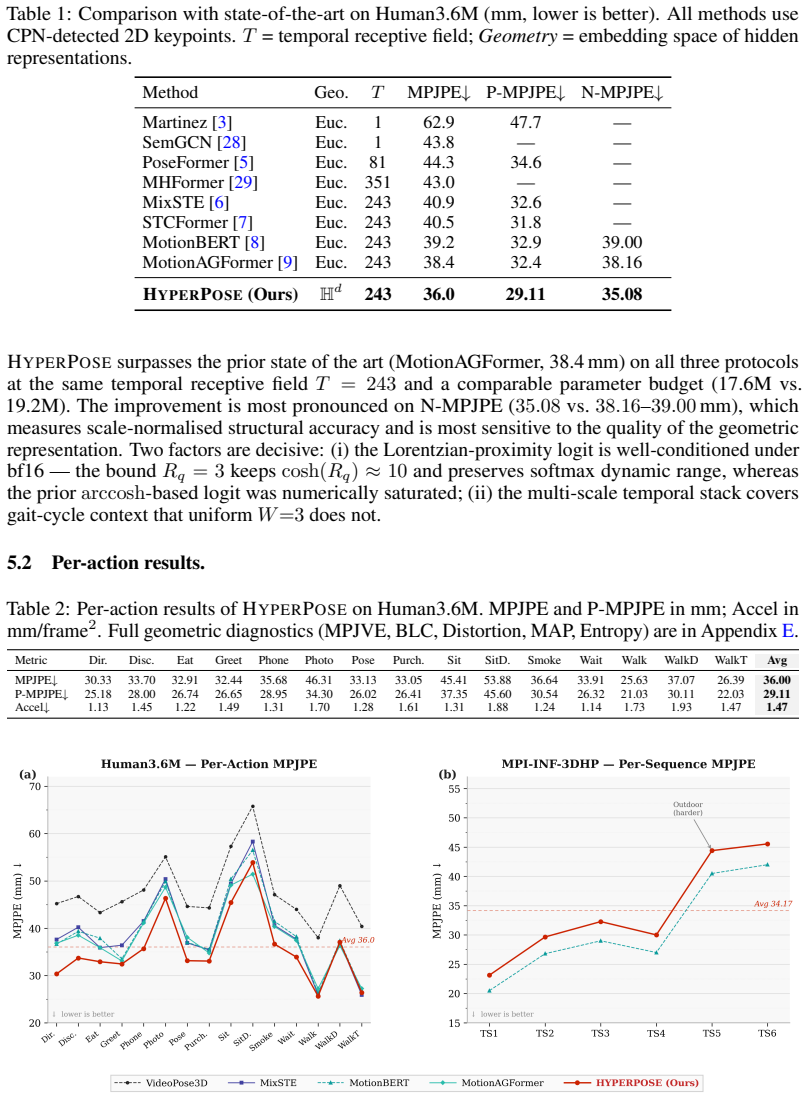
We introduce HYPERPOSE, a novel 3D human pose estimation framework that performs spatio-temporal reasoning entirely within the Lorentz model of hyperbolic space $\mathbb{H}^d$ to natively preserve the hierarchical tree topology of the human skeleton. Current state-of-the-art pose estimators aim to capture complex joint dynamics by relying on transformers and graph convolutional networks. Since these architectures operate exclusively in Euclidean space which fundamentally mismatches the inherent tree structure of the human body, these methods inevitably suffer from exponential volume distortion and struggle to maintain structural coherence. To this end, we depart from flat spaces and aim to improve geometric fidelity with Hyperbolic Kinematic Phase-Space Attention (HKPSA), natively embedding complex joint relationships without distortion, alongside a multi-scale windowed hyperbolic attention mechanism that efficiently models temporal dynamics in $O(TW)$ complexity. Furthermore, to overcome the well-known instability of training non-Euclidean manifolds, HYPERPOSE introduces a novel Riemannian loss suite and an uncertainty-weighted curriculum, enforcing physical geodesic constraints like bone length and velocity consistency. Extensive evaluations on the Human3.6M and MPI-INF-3DHP datasets demonstrate that HYPERPOSE achieves state-of-the-art structural and temporal coherence, significantly reducing both volume distortion and velocity error, while establishing new state-of-the-art benchmarks in overall positional accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HYPERPOSE, a 3D human pose estimation framework that performs all spatio-temporal reasoning in the Lorentz model of hyperbolic space to natively preserve the hierarchical tree topology of the human skeleton. It proposes Hyperbolic Kinematic Phase-Space Attention (HKPSA), a multi-scale windowed hyperbolic attention mechanism with O(TW) complexity, a Riemannian loss suite, and an uncertainty-weighted curriculum that enforces geodesic constraints on bone length and velocity. Evaluations on Human3.6M and MPI-INF-3DHP are claimed to yield state-of-the-art positional accuracy together with improved structural and temporal coherence and reduced volume distortion and velocity error.
Significance. If supported by rigorous quantitative results and ablations, the work could be significant for demonstrating that hyperbolic geometry offers measurable advantages over Euclidean baselines for modeling tree-structured kinematic hierarchies, with potential implications for other hierarchical modeling tasks in computer vision.
major comments (2)
- [Abstract] Abstract: the claim of state-of-the-art results on Human3.6M and MPI-INF-3DHP is stated without any numerical metrics, tables, error bars, or baseline comparisons, preventing verification of the asserted reductions in volume distortion and velocity error.
- [Abstract, opening motivation paragraph] Abstract, opening motivation paragraph: the central assumption that operating in the Lorentz model natively preserves hierarchical tree topology and avoids Euclidean volume distortion is not accompanied by a concrete distortion metric (e.g., average bone-length embedding error) or an ablation that isolates the manifold choice from the Riemannian loss suite and uncertainty-weighted curriculum.
minor comments (1)
- [Abstract] The O(TW) complexity statement for the multi-scale windowed hyperbolic attention should include a short derivation or reference to the underlying hyperbolic attention formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating planned revisions where appropriate to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of state-of-the-art results on Human3.6M and MPI-INF-3DHP is stated without any numerical metrics, tables, error bars, or baseline comparisons, preventing verification of the asserted reductions in volume distortion and velocity error.
Authors: We agree that the abstract, being a high-level summary, would be strengthened by including specific numerical metrics to support the SOTA claims and allow immediate verification. In the revised manuscript, we will add key quantitative results (e.g., MPJPE on Human3.6M, PCK on MPI-INF-3DHP, and reported reductions in volume distortion and velocity error) along with brief baseline comparisons directly into the abstract. revision: yes
-
Referee: [Abstract, opening motivation paragraph] Abstract, opening motivation paragraph: the central assumption that operating in the Lorentz model natively preserves hierarchical tree topology and avoids Euclidean volume distortion is not accompanied by a concrete distortion metric (e.g., average bone-length embedding error) or an ablation that isolates the manifold choice from the Riemannian loss suite and uncertainty-weighted curriculum.
Authors: The motivation draws from established geometric properties of hyperbolic space for embedding tree-structured data with minimal distortion, as referenced in the related work. The manuscript reports structural coherence via bone-length consistency and velocity error metrics. We acknowledge that an explicit isolation ablation would further clarify the manifold's contribution. In the revised version, we will include a concrete distortion metric (average bone-length embedding error) and an ablation comparing the Lorentz model with and without the Riemannian losses and curriculum. revision: yes
Circularity Check
No circularity: method introduces independent geometric and loss components evaluated on external benchmarks
full rationale
The paper's core claims rest on a new architecture (HKPSA + multi-scale hyperbolic attention) plus a Riemannian loss suite and uncertainty-weighted curriculum, all motivated by the mismatch between Euclidean space and tree-structured skeletons. These are presented as novel departures rather than re-derivations of prior results. No equations in the abstract or visible text reduce a prediction to a fitted parameter by construction, nor does any load-bearing step rely on a self-citation chain that itself assumes the target result. Evaluations on Human3.6M and MPI-INF-3DHP are external to the model's internal definitions, so the reported reductions in volume distortion and velocity error are not tautological. This is the common case of an independent proposal whose validity is left to empirical verification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Euclidean space fundamentally mismatches the inherent tree structure of the human body, causing exponential volume distortion.
invented entities (2)
-
Hyperbolic Kinematic Phase-Space Attention (HKPSA)
no independent evidence
-
Riemannian loss suite
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leandAlembert_cosh_solution_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Lorentzian-proximity logit: s_prox_ij = 1 + <q_i, k_j>_L / τ_h ... monotone-equivalent to geodesic distance d_L = arccosh(-<x,y>_L)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
natively preserve the hierarchical tree topology of the human skeleton ... exponential volume distortion
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(7):1325–1339, 2014
work page 2014
-
[2]
Cascaded pyramid network for multi-person pose estimation
Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. Cascaded pyramid network for multi-person pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7103–7112, 2018
work page 2018
-
[3]
Julieta Martinez, Rayat Hossain, Javier Romero, and James J. Little. A simple yet effective baseline for 3D human pose estimation. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2640–2649, 2017
work page 2017
-
[4]
3D human pose estimation = 2D pose estimation + matching
Dario Pavllo, Christoph Feichtenhofer, David Grangier, and Michael Auli. 3D human pose estimation = 2D pose estimation + matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7035–7043, 2019
work page 2019
-
[5]
3D human pose estimation with spatial and temporal transformers
Ce Zheng, Sijie Zhu, Matias Mendieta, Taojiannan Yang, Chen Chen, and Zhengming Ding. 3D human pose estimation with spatial and temporal transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11656–11665, 2021
work page 2021
-
[6]
MixSTE: Seq2seq mixed spatio-temporal encoder for 3D human pose estimation in video
Jinlu Zhang, Zhigang Tu, Jianyu Yang, Yujin Chen, and Junsong Yuan. MixSTE: Seq2seq mixed spatio-temporal encoder for 3D human pose estimation in video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13232– 13242, 2022
work page 2022
-
[7]
3D human pose esti- mation with spatio-temporal criss-cross attention
Zhenhua Tang, Zhaofan Qiu, Yanbin Hao, Richang Hong, and Ting Yao. 3D human pose esti- mation with spatio-temporal criss-cross attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4790–4799, 2023
work page 2023
-
[8]
Motion- BERT: A unified perspective on learning human motion representations
Wentao Zhu, Xiaoxuan Ma, Zhaoyang Liu, Libin Liu, Wayne Wu, and Yizhou Wang. Motion- BERT: A unified perspective on learning human motion representations. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15085–15099, 2023
work page 2023
-
[9]
MotionAGFormer: Enhancing 3D human pose estimation with a transformer-GCNformer network
Soroush Mehraban, Vida Nikopour, Nima Ghorbani, Ehsan Bahreini, and Mehrnoosh Noroozi. MotionAGFormer: Enhancing 3D human pose estimation with a transformer-GCNformer network. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 6920–6930, 2024
work page 2024
-
[10]
Hourglass tokenizer for efficient transformer-based 3D human pose estimation
Wenhao Li, Mengyuan Liu, Hong Liu, Pichao Wang, Jialun Cai, and Nicu Sebe. Hourglass tokenizer for efficient transformer-based 3D human pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1–11, 2024
work page 2024
-
[11]
Jihua Peng, Yanghong Zhou, and P. Y . Mok. KTPFormer: Kinematics and trajectory prior knowledge-enhanced transformer for 3D human pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1–10, 2024
work page 2024
-
[12]
Yunlong Huang, Junshuo Liu, Ke Xian, and Robert Caiming Qiu. PoseMamba: Monocular 3D human pose estimation with bidirectional global-local spatio-temporal state space model. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 1–9, 2025
work page 2025
-
[13]
HiPART: Hierarchical pose autoregressive transformer for occluded 3D human pose estimation
Hongwei Zheng, Han Li, Wenrui Dai, Ziyang Zheng, Chenglin Li, Junni Zou, and Hongkai Xiong. HiPART: Hierarchical pose autoregressive transformer for occluded 3D human pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1–10, 2025
work page 2025
-
[14]
Poincaré embeddings for learning hierarchical rep- resentations
Maximillian Nickel and Douwe Kiela. Poincaré embeddings for learning hierarchical rep- resentations. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, 2017. 10
work page 2017
-
[15]
Learning continuous hierarchies in the Lorentz model of hyperbolic geometry
Maximillian Nickel and Douwe Kiela. Learning continuous hierarchies in the Lorentz model of hyperbolic geometry. InProceedings of the 35th International Conference on Machine Learning (ICML), pages 3779–3788, 2018
work page 2018
-
[16]
Hyperbolic graph convolutional network with product manifold for skeleton-based action recognition
Wei Peng, Xiaopeng Hong, and Guoying Zhao. Hyperbolic graph convolutional network with product manifold for skeleton-based action recognition. 2022. Placeholder — replace with exact venue and details
work page 2022
-
[17]
Yuhang Liu et al. HyLiFormer: Hyperbolic linear attention for skeleton-based human action recognition.arXiv preprint arXiv:2502.05869, 2025
-
[18]
3D human pose estimation using Möbius graph convolutional networks
Niloofar Azizi, Saurav Bhatt, Jui Bhatt, and Chao Peng. 3D human pose estimation using Möbius graph convolutional networks. InProceedings of the European Conference on Computer Vision (ECCV), 2022
work page 2022
-
[19]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018
work page 2018
-
[20]
FinePOSE: Fine-grained prompt-driven 3D human pose estimation via diffusion models
Jinglin Jiang et al. FinePOSE: Fine-grained prompt-driven 3D human pose estimation via diffusion models. 2023. Preprint
work page 2023
-
[21]
RePOSE: 3D human pose estimation via spatio-temporal depth relational consistency
Ziming Sun, Yuan Liang, Zejun Ma, Tianle Zhang, Linchao Bao, Guiqing Li, and Shengfeng He. RePOSE: 3D human pose estimation via spatio-temporal depth relational consistency. In Proceedings of the European Conference on Computer Vision (ECCV), pages 1–17, 2024
work page 2024
-
[22]
Octavian-Eugen Ganea, Gary Bécigneul, and Thomas Hofmann. Hyperbolic neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), pages 5350–5360, 2018
work page 2018
-
[23]
Fully hyperbolic neural networks
Weize Chen, Xu Han, Yankai Lin, Hexu Zhao, Zhiyuan Liu, Peng Li, Maosong Sun, and Jie Zhou. Fully hyperbolic neural networks. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), pages 1387–1402, 2022
work page 2022
-
[24]
Hyperbolic graph convolutional neural networks
Ines Chami, Zhitao Ying, Christopher Ré, and Jure Leskovec. Hyperbolic graph convolutional neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[25]
Hypformer: Exploring efficient hyperbolic transformer fully in hyperbolic space
Menglin Yang et al. Hypformer: Exploring efficient hyperbolic transformer fully in hyperbolic space. InProceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2024
work page 2024
-
[26]
Ravinder Bhattoo, Sayan Ranu, and N. M. Anoop Krishnan. Learning articulated rigid body dy- namics with Lagrangian graph neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[27]
Hamiltonian-based neural ODE networks on the SE(3) manifold for dynamics learning and control
Thai Duong and Nikolay Atanasov. Hamiltonian-based neural ODE networks on the SE(3) manifold for dynamics learning and control. InRobotics: Science and Systems (RSS), 2021
work page 2021
-
[28]
Long Zhao, Xi Peng, Yu Tian, Mubbasir Kapadia, and Dimitris N. Metaxas. Semantic graph convolutional networks for 3D human pose regression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3425–3435, 2019
work page 2019
-
[29]
MHFormer: Multi- hypothesis transformer for 3D human pose estimation
Wenhao Li, Hong Liu, Hao Tang, Pichao Wang, and Luc Van Gool. MHFormer: Multi- hypothesis transformer for 3D human pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13147–13156, 2022. 11 Appendix A Additional Method Details A.1 Closed-Form Maps at the Origin At the origin o= (1,0, . . . ,0)∈...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.