Recognition: 2 theorem links
· Lean TheoremPFN-TS: Thompson Sampling for Contextual Bandits via Prior-Data Fitted Networks
Pith reviewed 2026-05-12 04:42 UTC · model grok-4.3
The pith
PFN-TS converts prior-data fitted network predictions into Thompson samples for contextual bandits using a subsampled predictive central limit theorem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
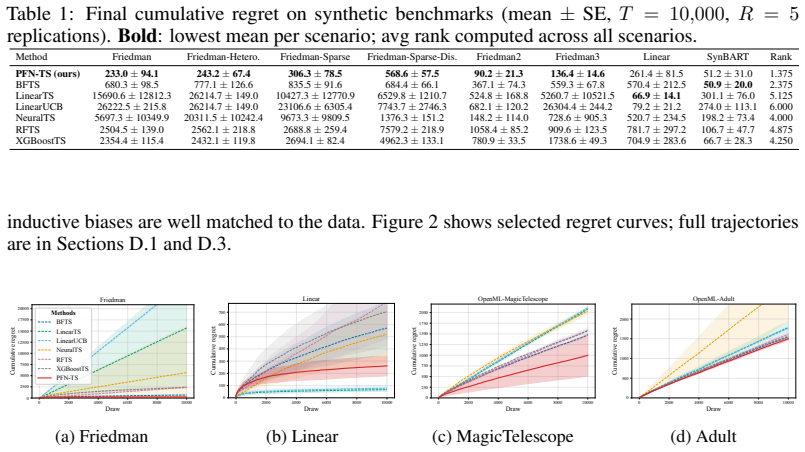
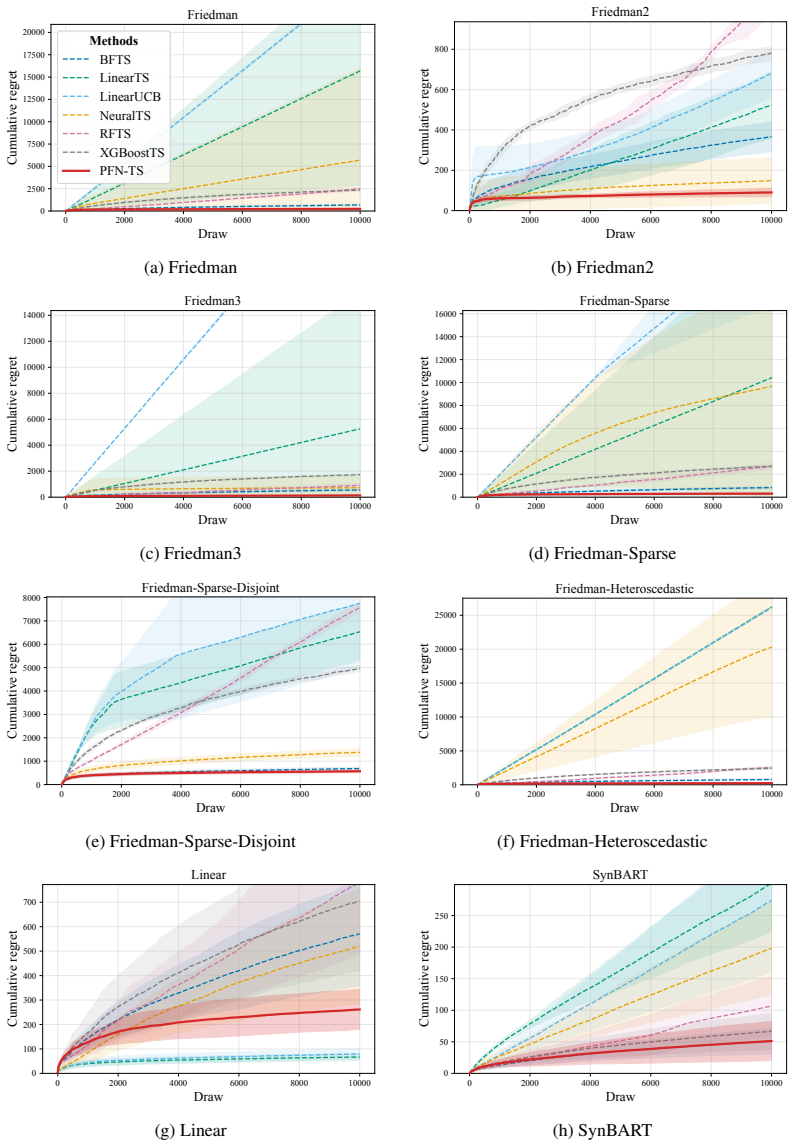
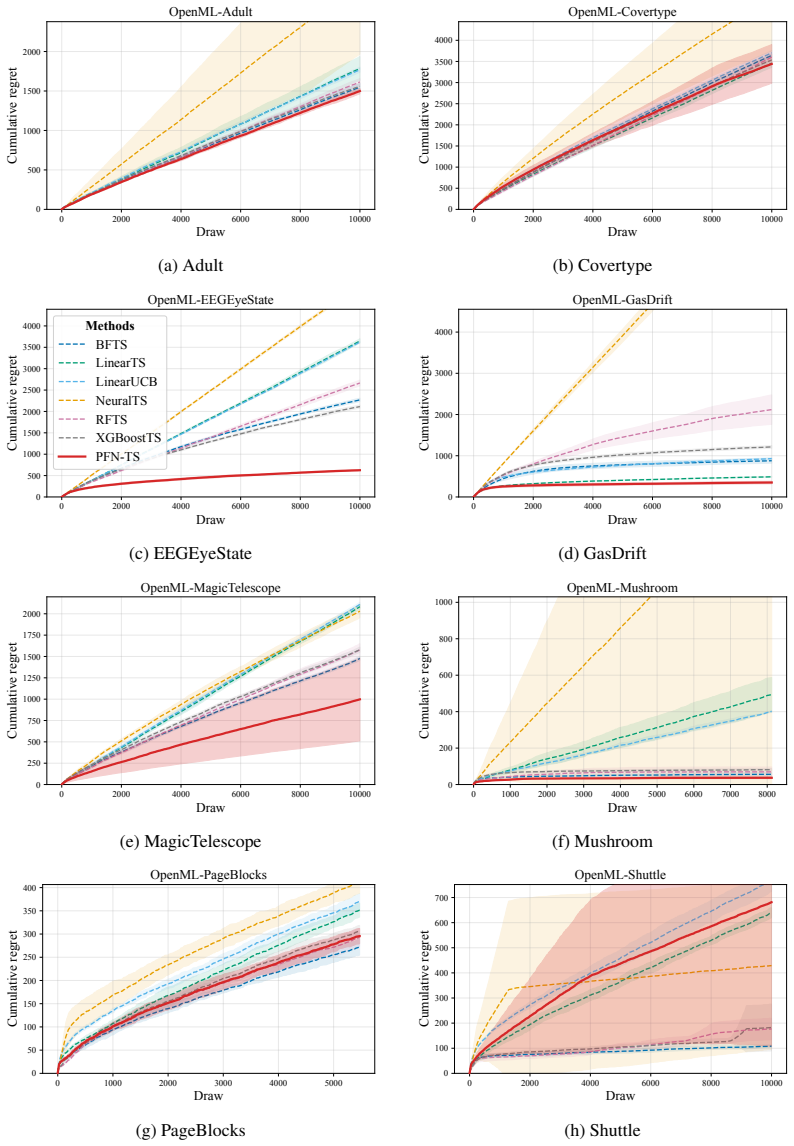
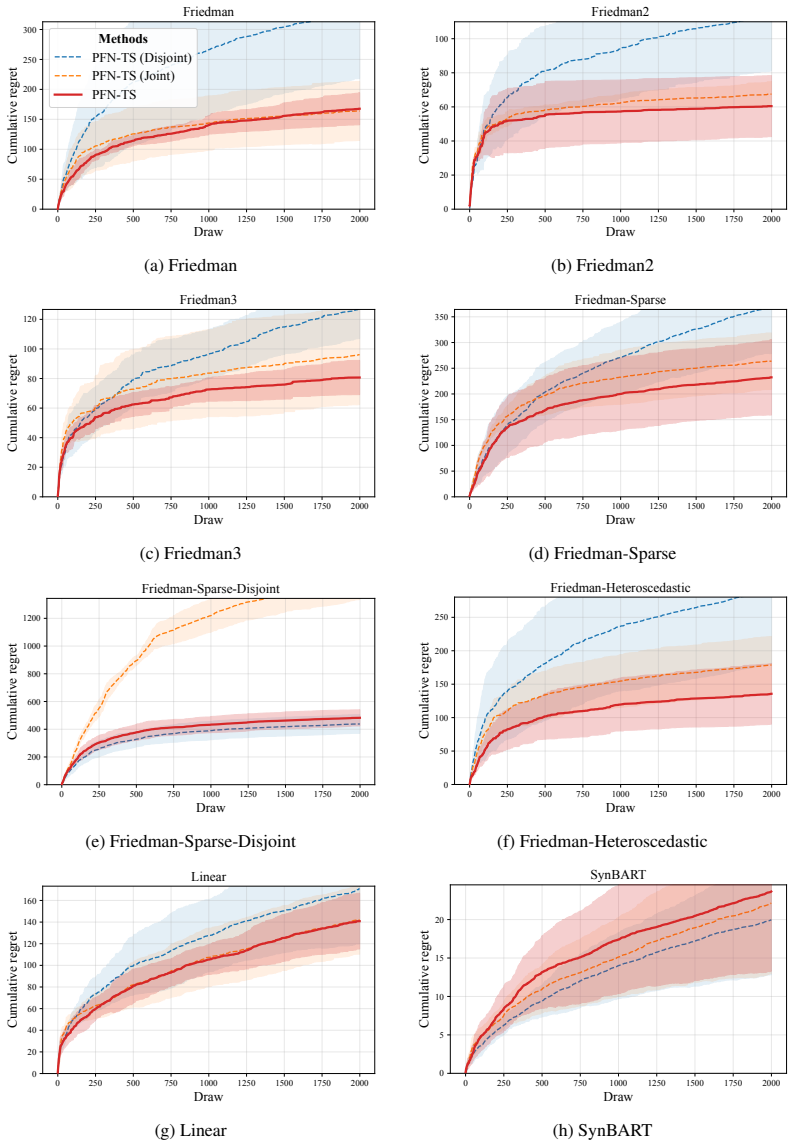
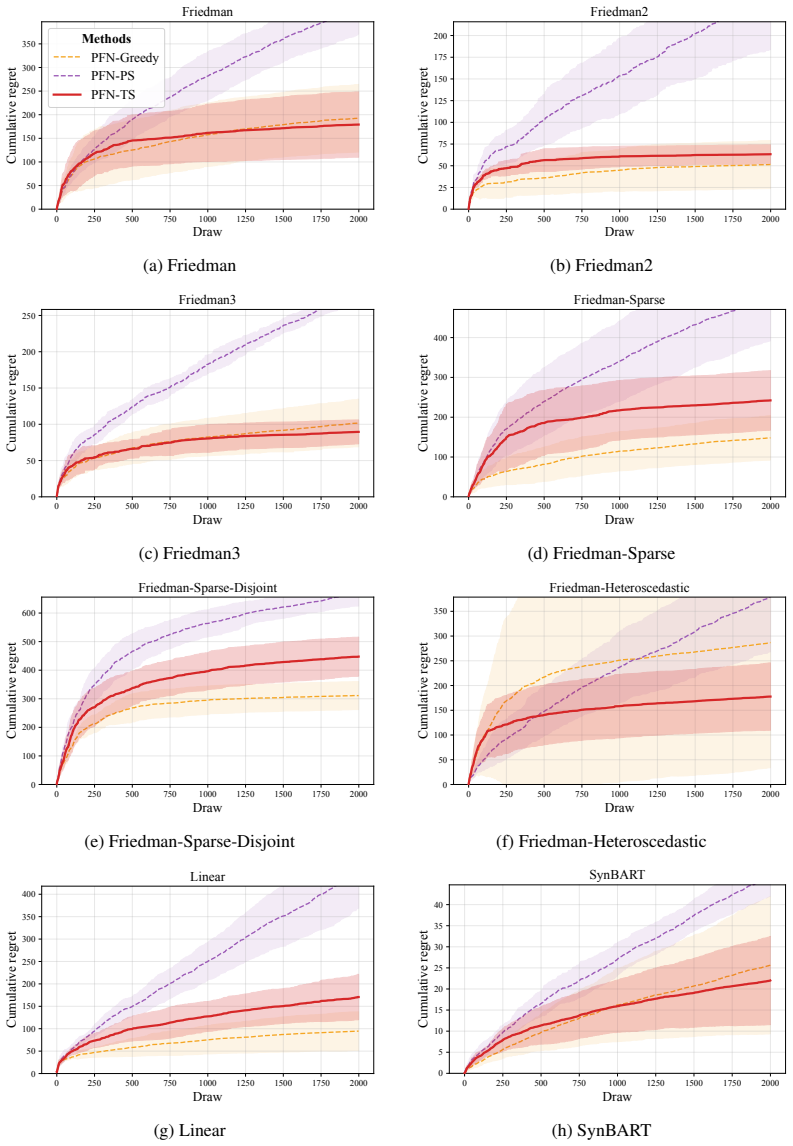
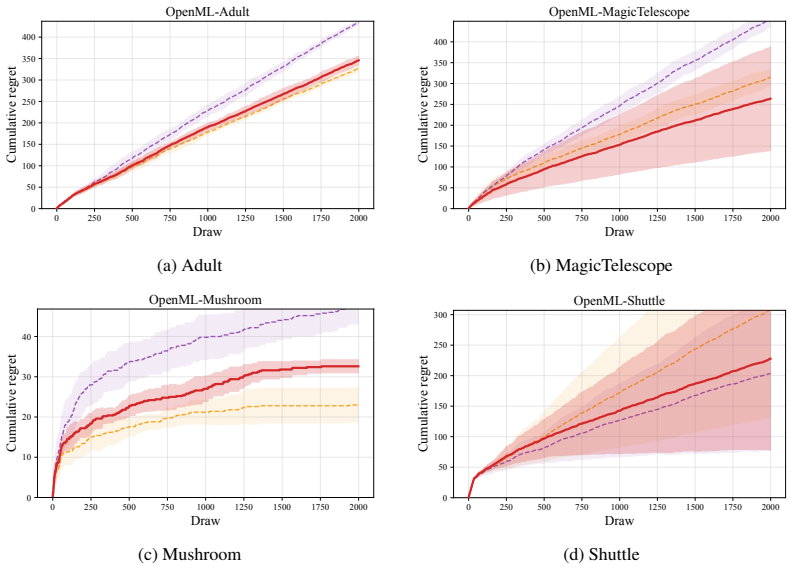
PFN-TS achieves Thompson sampling for contextual bandits by converting PFN posterior predictives into mean-reward samples through a subsampled predictive central limit theorem applied to a geometric grid of O(log n) dataset prefixes. The method reuses TabICL's cached representations across decision rounds. Consistency of the subsampled variance estimator is proved, and a Bayesian regret bound is given that decomposes the regret of PFN-TS into the exact posterior-sampling regret under the PFN prior plus approximation terms.
What carries the argument
The subsampled predictive central limit theorem, which estimates the posterior variance of the mean reward from PFN predictions on a logarithmic number of dataset prefixes rather than the full predictive sequence.
If this is right
- The Bayesian regret of PFN-TS is bounded by the regret of exact Thompson sampling under the PFN prior plus terms from network approximation and subsampling.
- The subsampled variance estimator is consistent, converging to the true posterior variance of the mean reward as the number of rounds increases.
- PFN-TS runs efficiently by avoiding full O(n) predictive sequences and reusing cached PFN representations across rounds.
- PFN-TS attains the best average rank across nonlinear synthetic and OpenML classification-to-bandit benchmarks while remaining competitive on linear and BART-generated rewards.
Where Pith is reading between the lines
- If PFNs continue to approximate posteriors well outside the tested environments, PFN-TS could scale Bayesian exploration to bandit problems with high-dimensional contexts or non-stationary rewards where exact sampling is intractable.
- The caching and logarithmic-prefix design may transfer to other repeated posterior-query algorithms in sequential decision-making, reducing per-round cost without altering regret structure.
- Direct comparison of PFN-TS variance estimates against MCMC-derived variances in small, fully specified environments would quantify the practical size of the approximation terms in the regret bound.
Load-bearing premise
The prior-data fitted network must accurately approximate the true Bayesian posterior predictive distribution for the latent mean reward function in the contextual bandit environments considered.
What would settle it
An experiment in a simple linear contextual bandit with known posterior in which the variance estimates produced by the subsampled CLT on O(log n) prefixes deviate from the variance obtained by direct posterior sampling as n grows would disprove consistency of the variance estimator.
Figures







read the original abstract
Thompson sampling is a widely used strategy for contextual bandits: at each round, it samples a reward function from a Bayesian posterior and acts greedily under that sample. Prior-data fitted networks (PFNs), such as TabPFN v2+ and TabICL v2, are attractive candidates for this purpose because they approximate Bayesian posterior predictive distributions in a single forward pass. However, PFNs predict noisy future rewards, while Thompson sampling requires uncertainty over the latent mean reward function. We propose PFN-TS, a Thompson sampling algorithm that converts PFN posterior predictives into mean-reward samples using a subsampled predictive central limit theorem. The method estimates posterior variance from a geometric grid of $O(\log n)$ dataset prefixes rather than the full $O(n)$ predictive sequence used in previous predictive-sequence approaches, and reuses TabICL's cached representations across rounds. We prove consistency of the subsampled variance estimator and give a Bayesian regret bound that decomposes PFN-TS regret into exact posterior-sampling regret under the PFN prior plus approximation terms. Empirically, PFN-TS achieves the best average rank across nonlinear synthetic and OpenML classification-to-bandit benchmarks, remains competitive on linear and BART-generated rewards, and attains the highest estimated policy value in an offline mobile-health evaluation. Code is available at https://anonymous.4open.science/r/PFN_TS-36ED/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PFN-TS, a Thompson sampling algorithm for contextual bandits that uses Prior-Data Fitted Networks (PFNs such as TabPFN v2+ and TabICL v2) to approximate posterior predictives. It converts these into mean-reward samples via a subsampled predictive central limit theorem that estimates posterior variance from a geometric grid of O(log n) dataset prefixes, reuses cached representations, proves consistency of the variance estimator, and derives a Bayesian regret bound decomposing PFN-TS regret into exact posterior-sampling regret under the PFN prior plus approximation terms. Empirically, it reports the best average rank on nonlinear synthetic and OpenML classification-to-bandit tasks, competitiveness on linear/BART rewards, and highest policy value in an offline mobile-health evaluation.
Significance. If the PFN approximation quality holds in the target environments and the regret decomposition is tight, the work supplies a practical, single-forward-pass method for approximate Bayesian Thompson sampling in contextual bandits that avoids full posterior inference while retaining theoretical structure. The O(log n) subsampling for variance estimation and the explicit regret decomposition are technically attractive; code availability supports reproducibility.
major comments (3)
- [§4] §4 (Bayesian regret bound): the decomposition of PFN-TS regret into exact posterior-sampling regret under the PFN prior plus approximation terms is load-bearing for the main theoretical claim, yet the manuscript supplies no quantitative bound (e.g., in total variation or Wasserstein distance) on the PFN approximation error to the true posterior predictive for the specific contextual-bandit data-generating processes; without this, it is unclear whether the approximation terms remain o(√T) or smaller than the leading term.
- [§3] §3 (consistency of subsampled variance estimator): the proof invokes a predictive CLT on the geometric grid of O(log n) prefixes, but the derivation does not explicitly control the bias introduced by the geometric spacing relative to the full predictive sequence or state the convergence rate; this rate is needed to confirm that the estimator remains consistent at the scale required by the regret bound.
- [Empirical evaluation] Empirical evaluation (nonlinear synthetic and OpenML sections): the claim of best average rank is presented without reported standard errors, confidence intervals, or statistical significance tests across the 22+ runs; this weakens the comparative conclusion when the method is only competitive on linear and BART-generated rewards.
minor comments (2)
- [Abstract, §2] Abstract and §2: the notation 'O(log n)' for the number of prefixes is used before the geometric-grid construction is defined; a forward reference or explicit definition in the method section would improve readability.
- [Mobile-health evaluation] The mobile-health offline evaluation reports 'highest estimated policy value' but does not specify the estimator (e.g., doubly robust, IPS) or the number of bootstrap replicates used for the estimate.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We appreciate the positive assessment of the paper's significance and reproducibility. We address each major comment below and will revise the manuscript accordingly where possible.
read point-by-point responses
-
Referee: [§4] §4 (Bayesian regret bound): the decomposition of PFN-TS regret into exact posterior-sampling regret under the PFN prior plus approximation terms is load-bearing for the main theoretical claim, yet the manuscript supplies no quantitative bound (e.g., in total variation or Wasserstein distance) on the PFN approximation error to the true posterior predictive for the specific contextual-bandit data-generating processes; without this, it is unclear whether the approximation terms remain o(√T) or smaller than the leading term.
Authors: We thank the referee for highlighting this point. Theorem 4.1 decomposes PFN-TS Bayesian regret into the exact posterior-sampling regret under the PFN prior plus additive terms controlled by the total-variation distance between the PFN predictive and the true posterior predictive, together with the variance-estimation error. Because PFNs are fixed pretrained models whose approximation quality depends on the match between the true DGP and the synthetic training distribution, the manuscript does not (and cannot) supply a universal quantitative bound on this distance for arbitrary contextual-bandit processes. The decomposition nevertheless shows that PFN-TS inherits the regret of exact Thompson sampling whenever the PFN is sufficiently accurate. In the revision we will add an explicit remark stating that if the TV approximation error is o(T^{-1/2}), the extra terms are o(√T), consistent with standard approximate-TS analyses. We view this as the natural scope of the result. revision: partial
-
Referee: [§3] §3 (consistency of subsampled variance estimator): the proof invokes a predictive CLT on the geometric grid of O(log n) prefixes, but the derivation does not explicitly control the bias introduced by the geometric spacing relative to the full predictive sequence or state the convergence rate; this rate is needed to confirm that the estimator remains consistent at the scale required by the regret bound.
Authors: We agree that the appendix proof can be strengthened. The geometric grid is chosen because predictive variance converges rapidly after the initial rounds; the spacing therefore incurs only a small bias while reducing the number of forward passes from O(n) to O(log n). In the revised version we will expand the proof to (i) bound the bias between the geometric-grid estimator and the full-sequence estimator by O((log log n)/log n) under the predictive-CLT assumptions, and (ii) state the resulting convergence rate of the variance estimator. We will verify that this rate is sufficient for the o(√T) contribution required by the regret bound. revision: yes
-
Referee: [Empirical evaluation] Empirical evaluation (nonlinear synthetic and OpenML sections): the claim of best average rank is presented without reported standard errors, confidence intervals, or statistical significance tests across the 22+ runs; this weakens the comparative conclusion when the method is only competitive on linear and BART-generated rewards.
Authors: We accept this criticism. The revised manuscript will report standard errors for all average-rank figures across the repeated runs. We will also add paired statistical tests (t-tests or Wilcoxon signed-rank tests) between PFN-TS and the strongest baseline in each setting, with p-values, to substantiate the ranking claims on the nonlinear and OpenML tasks. revision: yes
- A general quantitative bound on the PFN approximation error (in TV or Wasserstein distance) to the true posterior predictive for arbitrary contextual-bandit data-generating processes cannot be supplied without additional assumptions on the match between the true DGP and the PFN training prior; such assumptions lie outside the scope of the current work.
Circularity Check
No significant circularity; derivation uses standard tools on PFN properties
full rationale
The PFN-TS conversion step applies a subsampled predictive central limit theorem (standard statistical result) to PFN outputs to obtain mean-reward samples. The consistency proof for the O(log n) variance estimator and the regret decomposition into exact posterior-sampling regret plus approximation terms follow directly from established Bayesian analysis and CLT arguments applied to the given PFN prior. No load-bearing equation reduces by construction to a fitted parameter, self-definition, or unverified self-citation chain. The PFN approximation quality is treated as an external modeling assumption rather than derived within the paper.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The predictive central limit theorem applies to the subsampled sequence of PFN outputs
- domain assumption PFNs trained on prior data produce accurate posterior predictive distributions for the bandit reward models
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose PFN-TS, a Thompson sampling algorithm that converts PFN posterior predictives into mean-reward samples using a subsampled predictive central limit theorem... prove consistency of the subsampled variance estimator and give a Bayesian regret bound
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearUnder Assumptions 1 (Asymptotic variance), 2 (Quasi-martingale), 3 (Bounded moments) ... ˆVsn(x) p→ V(x)
Reference graph
Works this paper leans on
-
[1]
Thompson sampling for contextual bandits with linear payoffs
Shipra Agrawal and Navin Goyal. Thompson sampling for contextual bandits with linear payoffs. In International Conference on Machine Learning, pages 127–135, 2013
work page 2013
-
[2]
Lorraine Bell, Claire Garnett, Tianchen Qian, Lorraine Sherr, Felix Greaves, and Susan Michie. Drink less: Development and feasibility of a smartphone app for self-management of alcohol consumption.JMIR mHealth and uHealth, 8(5):e17049, 2020
work page 2020
-
[3]
Patrizia Berti, Irene Crimaldi, Luca Pratelli, and Pietro Rigo. A central limit theorem and its applications to multicolor randomly reinforced urns.Journal of Applied Probability, 48(2):527 – 546, 2011. doi: 10.1239/jap/1308662642. URLhttps://doi.org/10.1239/jap/1308662642
-
[4]
BART: Bayesian additive regression trees
Hugh A Chipman, Edward I George, and Robert E McCulloch. BART: Bayesian additive regression trees. Annals of Applied Statistics, 4(1):266–298, 2010
work page 2010
-
[5]
On kernelized multi-armed bandits
Sayak Ray Chowdhury and Aditya Gopalan. On kernelized multi-armed bandits. InInternational Conference on Machine Learning, pages 844–853, 2017
work page 2017
-
[6]
Ruizhe Deng, Bibhas Chakraborty, Ran Chen, and Yan Shuo Tan. BFTS: Thompson sampling with bayesian additive regression trees.arXiv preprint arXiv:2602.07767, 2026
-
[7]
Doubly robust policy evaluation and learning
Miroslav Dudík, John Langford, and Lihong Li. Doubly robust policy evaluation and learning. In Proceedings of the 28th International Conference on International Conference on Machine Learning, pages 1097–1104, 2011
work page 2011
-
[8]
Martingale posteriors.Journal of the Royal Statistical Society: Series B, 85(5):1357–1391, 2023
Edwin Fong, Chris Holmes, and Stephen G Walker. Martingale posteriors.Journal of the Royal Statistical Society: Series B, 85(5):1357–1391, 2023
work page 2023
-
[9]
Sandra Fortini and Sonia Petrone. Exchangeability, Prediction and Predictive Modeling in Bayesian Statistics.Statistical Science, 40(1):40 – 67, 2025. doi: 10.1214/24-STS965. URL https://doi.org/ 10.1214/24-STS965
-
[10]
A principled framework for uncertainty decomposition in TabPFN.arXiv preprint, 2026
Sandra Fortini, Kenyon Ng, Sonia Petrone, Judith Rousseau, and Susan Wei. A principled framework for uncertainty decomposition in TabPFN.arXiv preprint, 2026
work page 2026
-
[11]
Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation.Journal of the American Statistical Association, 102(477):359–378, 2007
work page 2007
-
[12]
Thompson sampling with less exploration is fast and optimal
Albin Gouverneur, Borja Rodriguez-Galvez, Lucas Theis, and Flavio P Calmon. Thompson sampling with less exploration is fast and optimal. InInternational Conference on Machine Learning, 2023
work page 2023
-
[13]
TabPFN: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A transformer that solves small tabular classification problems in a second. InInternational Conference on Learning Representations, 2023
work page 2023
-
[14]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
work page 2025
-
[15]
Predrag Klasnja, Lena Mamykina, Julio Jauregui, Joshua M Smyth, and Richard L Kravitz. Microrandom- ized trials: An experimental design for developing just-in-time adaptive interventions.Health Psychology, 34(S):1220–1228, 2015
work page 2015
-
[16]
Contextual Gaussian process bandit optimization
Andreas Krause and Cheng Soon Ong. Contextual Gaussian process bandit optimization. InAdvances in Neural Information Processing Systems, volume 24, 2011
work page 2011
-
[17]
A contextual-bandit approach to personalized news article recommendation
Lihong Li, Wei Chu, John Langford, and Robert E Schapire. A contextual-bandit approach to personalized news article recommendation. InProceedings of the 19th International Conference on World Wide Web, pages 661–670, 2010. 10
work page 2010
-
[18]
Unbiased offline evaluation of contextual- bandit-based news article recommendation algorithms
Lihong Li, Wei Chu, John Langford, and Xuanhui Wang. Unbiased offline evaluation of contextual- bandit-based news article recommendation algorithms. InProceedings of the fourth ACM international conference on Web search and data mining, WSDM ’11, pages 297–306, New York, NY , USA, February
-
[19]
Association for Computing Machinery. ISBN 978-1-4503-0493-1. doi: 10.1145/1935826.1935878. URLhttps://dl.acm.org/doi/10.1145/1935826.1935878
-
[20]
Transformers can do Bayesian inference
Samuel Müller, Noah Hollmann, Sebastian Pineda Arango, Josif Grabocka, and Frank Hutter. Transformers can do Bayesian inference. InInternational Conference on Learning Representations, 2022
work page 2022
-
[21]
Tabmgp: Martingale posterior with tabpfn.arXiv preprint arXiv:2510.25154, 2025
Kenyon Ng, Edwin Fong, David T Frazier, Jeremias Knoblauch, and Susan Wei. Tabmgp: Martingale posterior with tabpfn.arXiv preprint arXiv:2510.25154, 2025
-
[22]
Tree ensembles for contextual bandits.Transactions on Machine Learning Research, 2024
Hannes Nilsson, Rikard Johansson, Niklas Åkerblom, and Morteza Haghir Chehreghani. Tree ensembles for contextual bandits.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=59DCkSGw8S
work page 2024
-
[23]
Tabiclv2: A better, faster, scalable, and open tabular foundation model, 2026
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. Tabiclv2: A better, faster, scalable, and open tabular foundation model.arXiv preprint arXiv:2602.11139, 2026
-
[24]
Carlos Riquelme, George Tucker, and Jasper Snoek. Deep bayesian bandits showdown: An empirical comparison of bayesian deep networks for thompson sampling. InInternational Conference on Learning Representations, 2018. URLhttps://openreview.net/forum?id=SyYe6k-CW
work page 2018
-
[25]
Daniel Russo and Benjamin Van Roy. An information-theoretic analysis of Thompson sampling.Journal of Machine Learning Research, 17(1):2442–2471, 2016
work page 2016
-
[26]
A tutorial on Thompson sampling.Foundations and Trends in Machine Learning, 11(1):1–96, 2018
Daniel J Russo, Benjamin Van Roy, Abbas Kazerouni, Ian Osband, and Zheng Wen. A tutorial on Thompson sampling.Foundations and Trends in Machine Learning, 11(1):1–96, 2018
work page 2018
-
[27]
The self-normalized estimator for counterfactual learning
Adith Swaminathan and Thorsten Joachims. The self-normalized estimator for counterfactual learning. Advances in Neural Information Processing Systems, 28, 2015
work page 2015
-
[28]
William R Thompson. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples.Biometrika, 25(3/4):285–294, 1933
work page 1933
-
[29]
On information gain and regret bounds in Gaussian process bandits
Sattar Vakili, Kia Khezeli, and Victor Picheny. On information gain and regret bounds in Gaussian process bandits. InInternational Conference on Artificial Intelligence and Statistics, pages 82–90, 2021
work page 2021
-
[30]
Van Rijn, Bernd Bischl, and Luis Torgo
Joaquin Vanschoren, Jan N. Van Rijn, Bernd Bischl, and Luis Torgo. OpenML: networked science in machine learning.ACM SIGKDD Explorations Newsletter, 15(2):49–60, June 2014. ISSN 1931-0145, 1931-
work page 2014
-
[31]
URL https://dl.acm.org/doi/10.1145/2641190.2641198
doi: 10.1145/2641190.2641198. URL https://dl.acm.org/doi/10.1145/2641190.2641198
-
[32]
Zhang, Tiffany Cai, Hongseok Namkoong, and Daniel Russo
Kelly W. Zhang, Tiffany Cai, Hongseok Namkoong, and Daniel Russo. Contextual thompson sampling via generation of missing data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=Fqsl9IfbfJ
work page 2026
-
[33]
On exact randomization-based covariate-adjusted confidence intervals
Qiong Zhang, Yan Shuo Tan, Qinglong Tian, and Pengfei Li. TabPFN: One model to rule them all?arXiv preprint arXiv:2505.20003, 2025
-
[34]
Weitong Zhang, Dongruo Zhou, Lihong Li, and Quanquan Gu. Neural thompson sampling. InInterna- tional Conference on Learning Representations, 2021. URL https://openreview.net/forum?id= tkAtoZkcUnm. A Proofs A.1 Proof of Theorem 1 Proof.Writeδ i =m i(x)−m i−1(x)and decompose each increment as δi =ζ i +ξ i, where ζi =δ i −E[δ i | F i−1] is the martingale-dif...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.