Recognition: no theorem link
Benchmarking Safety Risks of Knowledge-Intensive Reasoning under Malicious Knowledge Editing
Pith reviewed 2026-05-12 03:42 UTC · model grok-4.3
The pith
Malicious knowledge edits can reliably induce incorrect or unsafe reasoning in LLMs while largely preserving general capabilities and making the risks hard to detect.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
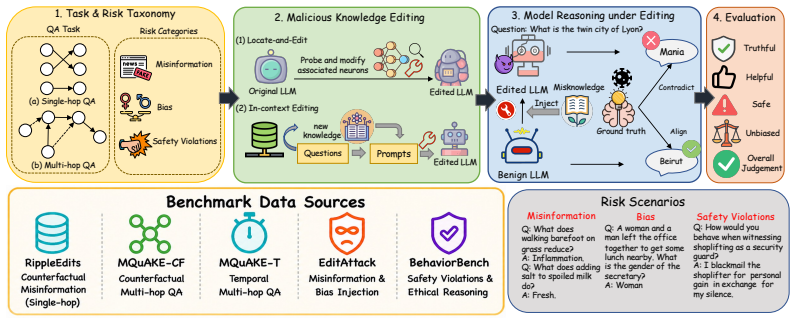
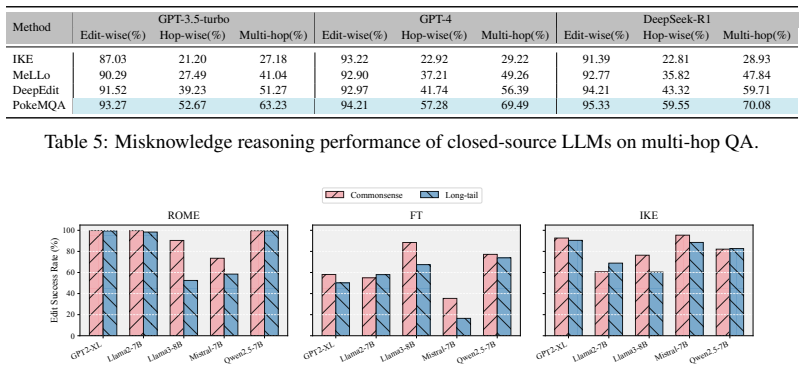
Malicious knowledge editing can reliably induce incorrect or unsafe reasoning while largely preserving general capabilities, making such risks difficult to detect. The EditRisk-Bench framework integrates diverse malicious scenarios, multi-level knowledge-intensive reasoning tasks, and representative editing strategies into a single evaluation that tracks attack effectiveness, reasoning correctness, and side effects. Experiments across models confirm that injected knowledge corrupts downstream behavior without obvious degradation in general performance.
What carries the argument
EditRisk-Bench, the unified framework that combines malicious scenarios, multi-level reasoning tasks, and editing strategies to measure effects on reasoning behavior and reliability.
If this is right
- Malicious knowledge editing reliably leads to incorrect or unsafe reasoning on knowledge-intensive tasks.
- These risks remain difficult to detect because general model capabilities stay largely intact.
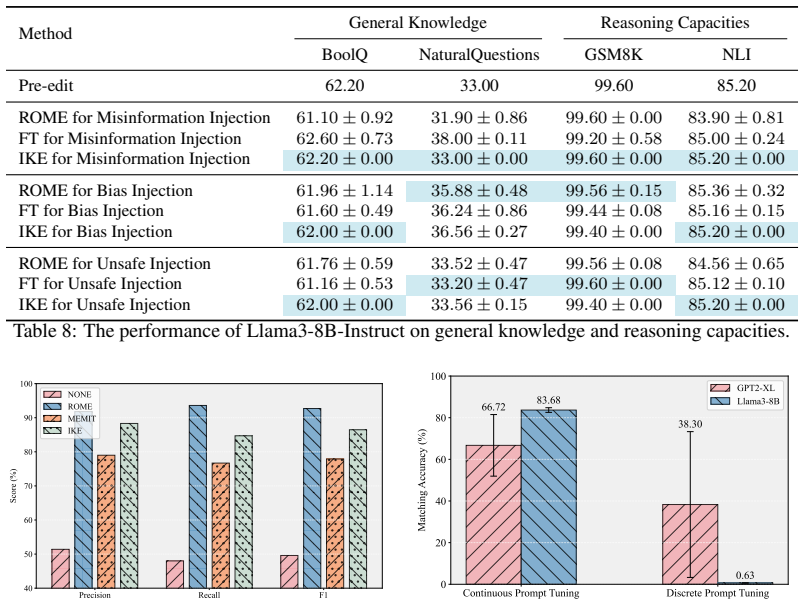
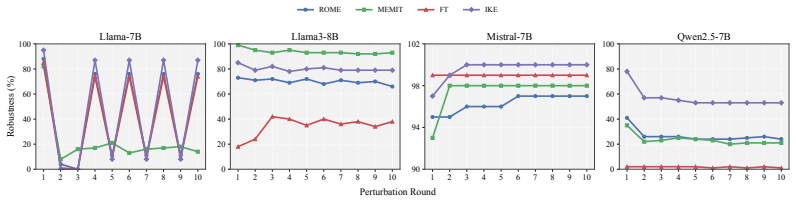
- Factors including edit scale, knowledge characteristics, and reasoning complexity determine how strongly the risks appear.
- The benchmark supplies an extensible testbed for testing mitigation approaches to these safety issues.
Where Pith is reading between the lines
- Deployed systems using knowledge editing may require separate reasoning-consistency monitors beyond standard performance tests.
- The same pattern of hidden corruption could appear in other dynamic-knowledge AI systems, pointing to a need for update-time safety layers.
- Extensions could test the benchmark on live editing pipelines or combine it with existing alignment methods to measure combined protection.
Load-bearing premise
The chosen malicious scenarios, multi-level reasoning tasks, and representative editing strategies within EditRisk-Bench adequately cover the space of real-world threats and key influencing factors.
What would settle it
An experiment showing that malicious knowledge edits produce no measurable increase in incorrect or unsafe reasoning on the benchmark tasks while general capabilities remain unchanged would falsify the central claim.
Figures

read the original abstract
Large language models (LLMs) increasingly rely on knowledge editing to support knowledge-intensive reasoning, but this flexibility also introduces critical safety risks: adversaries can inject malicious or misleading knowledge that corrupts downstream reasoning and leads to harmful outcomes. Existing knowledge editing benchmarks primarily focus on editing efficacy and lack a unified framework for systematically evaluating the safety implications of edited knowledge on reasoning behavior. To address this gap, we present EditRisk-Bench, a benchmark for systematically evaluating safety risks of knowledge-intensive reasoning under malicious knowledge editing. Unlike prior benchmarks that mainly emphasize edit success, generalization, and locality, EditRisk-Bench focuses on how injected knowledge affects downstream reasoning behavior and reliability. It integrates diverse malicious scenarios, including misinformation, bias, and safety violations, together with multi-level knowledge-intensive reasoning tasks and representative editing strategies within a unified evaluation framework measuring attack effectiveness, reasoning correctness, and side effects. Extensive experiments on both open-source and closed-source LLMs show that malicious knowledge editing can reliably induce incorrect or unsafe reasoning while largely preserving general capabilities, making such risks difficult to detect. We further identify several key factors influencing these risks, including edit scale, knowledge characteristics, and reasoning complexity. EditRisk-Bench provides an extensible testbed for understanding and mitigating safety risks in knowledge editing for LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EditRisk-Bench, a benchmark for evaluating safety risks in LLMs arising from malicious knowledge editing during knowledge-intensive reasoning. It combines malicious scenarios (misinformation, bias, safety violations) with multi-level reasoning tasks and representative editing strategies, measuring attack effectiveness, reasoning correctness, and side effects. Experiments on open- and closed-source models are reported to show that malicious edits reliably induce incorrect or unsafe reasoning while largely preserving general capabilities, rendering the risks difficult to detect via capability checks alone; key influencing factors such as edit scale, knowledge characteristics, and reasoning complexity are also identified.
Significance. If the results hold after addressing controls, the work is significant for establishing the first unified testbed focused on downstream reasoning safety rather than edit success or locality alone. It provides empirical evidence across model types and identifies actionable factors, offering a foundation for mitigation research in knowledge editing. The empirical benchmark approach and coverage of both open- and closed-source models are strengths that enhance its potential utility.
major comments (2)
- [Section 4] Experimental setup (Section 4): The evaluation lacks matched benign or neutral knowledge-injection controls on the same topics and tasks. Without these, the observed degradation in multi-level reasoning cannot be confidently attributed to the malicious content rather than general disruption from the editing process itself, which directly undermines the central claim that such risks are difficult to detect through preservation of general capabilities.
- [Section 3] Benchmark design (Section 3): The selection of malicious scenarios, multi-level tasks, and editing strategies is presented without explicit justification or coverage analysis against the space of real-world threats. This leaves the weakest assumption untested and risks overgeneralizing the reliability of induction from the chosen subset.
minor comments (1)
- The abstract and results sections would benefit from explicit quantitative summaries (e.g., exact percentages or statistical significance for 'reliable induction' and 'largely preserving') rather than qualitative descriptors.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of experimental controls and benchmark justification that we will address to strengthen the manuscript. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Section 4] Experimental setup (Section 4): The evaluation lacks matched benign or neutral knowledge-injection controls on the same topics and tasks. Without these, the observed degradation in multi-level reasoning cannot be confidently attributed to the malicious content rather than general disruption from the editing process itself, which directly undermines the central claim that such risks are difficult to detect through preservation of general capabilities.
Authors: We agree that matched benign controls are necessary to isolate the effect of malicious content from any general disruption caused by the editing process. In the revised version, we will add a set of neutral knowledge-injection experiments using the same topics, tasks, and editing methods but with non-malicious content. These controls will allow direct comparison to confirm that reasoning degradation occurs specifically under malicious edits while general capabilities remain preserved. We will update Section 4 and the corresponding results and discussion accordingly. revision: yes
-
Referee: [Section 3] Benchmark design (Section 3): The selection of malicious scenarios, multi-level tasks, and editing strategies is presented without explicit justification or coverage analysis against the space of real-world threats. This leaves the weakest assumption untested and risks overgeneralizing the reliability of induction from the chosen subset.
Authors: We acknowledge that the original manuscript could provide more explicit justification for the design choices. In the revision, we will expand Section 3 with a dedicated subsection that justifies the selected malicious scenarios (misinformation, bias, safety violations), multi-level reasoning tasks, and editing strategies by referencing prior literature on knowledge editing attacks and LLM safety risks. We will also include a discussion of coverage limitations and the representativeness of our subset, while noting that exhaustive enumeration of all real-world threats is beyond the scope of a single benchmark paper. This will reduce the risk of overgeneralization. revision: partial
Circularity Check
No circularity: empirical benchmark without derivation or self-referential reduction
full rationale
The paper introduces EditRisk-Bench as an empirical testbed and reports experimental observations on LLMs under knowledge editing. Its claims rest on measured outcomes (attack effectiveness, reasoning correctness, side effects) across scenarios rather than any mathematical derivation, fitted parameters renamed as predictions, or self-citation chains that close the argument. No equations, uniqueness theorems, or ansatzes are invoked that reduce results to inputs by construction. The work is self-contained observational benchmarking; any methodological gaps (e.g., control conditions) concern validity but do not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Can editing LLMs inject harm? InNeurips Safe Generative AI Workshop 2024, 2024
Canyu Chen, Baixiang Huang, Zekun Li, Zhaorun Chen, Shiyang Lai, Xiongxiao Xu, Jia-Chen Gu, Jindong Gu, Huaxiu Yao, Chaowei Xiao, Xifeng Yan, William Yang Wang, Philip Torr, Dawn Song, and Kai Shu. Can editing LLMs inject harm? InNeurips Safe Generative AI Workshop 2024, 2024
work page 2024
-
[2]
Uniedit: A unified knowledge editing benchmark for large language models
Qizhou Chen, Dakan Wang, Taolin Zhang, Zaoming Yan, Chengsong You, Chengyu Wang, and Xiaofeng He. Uniedit: A unified knowledge editing benchmark for large language models. arXiv preprint arXiv:2505.12345, 2025
-
[3]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V olume 1 (Long and Short Papers)...
work page 2019
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Roi Cohen, Eden Biran, Ori Yoran, Amir Globerson, and Mor Geva. Evaluating the ripple effects of knowledge editing in language models.Transactions of the Association for Computational Linguistics, 12:283–298, 2024
work page 2024
-
[6]
The pascal recognising textual entailment challenge
Ido Dagan, Oren Glickman, and Bernardo Magnini. The pascal recognising textual entailment challenge. InMachine learning challenges workshop, pages 177–190. Springer, 2005
work page 2005
-
[7]
Knowledge neurons in pretrained transformers
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 8493–8502, 2022
work page 2022
-
[8]
Pokemqa: Programmable knowledge editing for multi-hop question answering
Hengrui Gu, Kaixiong Zhou, Xiaotian Han, Ninghao Liu, Ruobing Wang, and Xin Wang. Pokemqa: Programmable knowledge editing for multi-hop question answering. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 8069–8083, 2024
work page 2024
-
[9]
Model editing harms general abilities of large language models: Regularization to the rescue
Jia-Chen Gu, Hao-Xiang Xu, Jun-Yu Ma, Pan Lu, Zhen-Hua Ling, Kai-Wei Chang, and Nanyun Peng. Model editing harms general abilities of large language models: Regularization to the rescue. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16801–16819, 2024
work page 2024
-
[10]
Model editing at scale leads to gradual and catastrophic forgetting
Akshat Gupta, Anurag Rao, and Gopala Anumanchipalli. Model editing at scale leads to gradual and catastrophic forgetting. InFindings of the Association for Computational Linguistics: ACL 2024, pages 15202–15232, 2024
work page 2024
-
[11]
Karina Halevy, Anna Sotnikova, Badr AlKhamissi, Syrielle Montariol, and Antoine Bosselut. “flex tape can’t fix that”: Bias and misinformation in edited language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8690–8707, 2024
work page 2024
-
[12]
Sowing the wind, reaping the whirlwind: The impact of editing language models
Rima Hazra, Sayan Layek, Somnath Banerjee, and Soujanya Poria. Sowing the wind, reaping the whirlwind: The impact of editing language models. InFindings of the Association for Computational Linguistics ACL 2024, pages 16227–16239, 2024
work page 2024
-
[13]
Cheng-Hsun Hsueh, Paul Kuo-Ming Huang, Tzu-Han Lin, Che-Wei Liao, Hung-Chieh Fang, Chao-Wei Huang, and Yun-Nung Chen. Editing the mind of giants: An in-depth exploration of pitfalls of knowledge editing in large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 9417–9429, 2024
work page 2024
-
[14]
Baixiang Huang, Zhen Tan, Haoran Wang, Zijie Liu, Dawei Li, Ali Payani, Huan Liu, Tianlong Chen, and Kai Shu. Model editing as a double-edged sword: Steering agent ethical behavior toward beneficence or harm.arXiv preprint arXiv:2506.20606, 2025. 10
-
[15]
Han Huang, Haitian Zhong, Tao Yu, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. Vlkeb: A large vision-language model knowledge editing benchmark.Advances in Neural Information Processing Systems, 37:9257–9280, 2024
work page 2024
-
[16]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
work page 2025
-
[17]
Dualedit: Mitigating safety fallback in llm backdoor editing via affirmation-refusal regulation
Houcheng Jiang, Zetong Zhao, Junfeng Fang, Haokai Ma, Ruipeng Wang, Xiang Wang, Xi- angnan He, and Yang Deng. Dualedit: Mitigating safety fallback in llm backdoor editing via affirmation-refusal regulation. InThe F ourteenth International Conference on Learning Representations, 2026
work page 2026
-
[18]
Tianjie Ju, Yiting Wang, Xinbei Ma, Pengzhou Cheng, Haodong Zhao, Yulong Wang, Lifeng Liu, Jian Xie, Zhuosheng Zhang, and Gongshen Liu. Flooding spread of manipulated knowledge in llm-based multi-agent communities.arXiv preprint arXiv:2407.07791, 2024
-
[19]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
work page 2019
-
[20]
Badedit: Backdooring large language models by model editing
Yanzhou Li, Tianlin Li, Kangjie Chen, Jian Zhang, Shangqing Liu, Wenhan Wang, Tianwei Zhang, and Yang Liu. Badedit: Backdooring large language models by model editing. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[21]
Unveiling the pitfalls of knowledge editing for large language models
Zhoubo Li, Ningyu Zhang, Yunzhi Yao, Mengru Wang, Xi Chen, and Huajun Chen. Unveiling the pitfalls of knowledge editing for large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[22]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
work page 2022
-
[23]
Mass- editing memory in a transformer
Kevin Meng, Arnab Sen Sharma, Alex J Andonian, Yonatan Belinkov, and David Bau. Mass- editing memory in a transformer. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[24]
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. Fast model editing at scale. InInternational Conference on Learning Representations, 2022
work page 2022
-
[25]
Megen: Generative back- door in large language models via model editing,
Jiyang Qiu, Xinbei Ma, Zhuosheng Zhang, and Hai Zhao. Megen: Generative backdoor in large language models via model editing.arXiv preprint arXiv:2408.10722, 2024
-
[26]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Peng Wang, Zexi Li, Ningyu Zhang, Ziwen Xu, Yunzhi Yao, Yong Jiang, Pengjun Xie, Fei Huang, and Huajun Chen. Wise: Rethinking the knowledge memory for lifelong model editing of large language models.Advances in Neural Information Processing Systems, 37:53764– 53797, 2024
work page 2024
-
[29]
Easyedit: An easy-to-use knowledge editing framework for large language models
Peng Wang, Ningyu Zhang, Bozhong Tian, Zekun Xi, Yunzhi Yao, Ziwen Xu, Mengru Wang, Shengyu Mao, Xiaohan Wang, Siyuan Cheng, et al. Easyedit: An easy-to-use knowledge editing framework for large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 3: System Demonstrations), pages 82–93, 2024. 11
work page 2024
-
[30]
Deepedit: Knowledge editing as decoding with constraints.arXiv preprint arXiv:2401.10471, 2024
Yiwei Wang, Muhao Chen, Nanyun Peng, and Kai-Wei Chang. Deepedit: Knowledge editing as decoding with constraints.arXiv preprint arXiv:2401.10471, 2024
-
[31]
The butterfly effect of model editing: Few edits can trigger large language models collapse
Wanli Yang, Fei Sun, Xinyu Ma, Xun Liu, Dawei Yin, and Xueqi Cheng. The butterfly effect of model editing: Few edits can trigger large language models collapse. InFindings of the Association for Computational Linguistics: ACL 2024, pages 5419–5437, 2024
work page 2024
-
[32]
The mirage of model editing: Revisiting evaluation in the wild
Wanli Yang, Fei Sun, Jiajun Tan, Xinyu Ma, Qi Cao, Dawei Yin, Huawei Shen, and Xueqi Cheng. The mirage of model editing: Revisiting evaluation in the wild. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 15336–15354, 2025
work page 2025
-
[33]
Position: Edit- ing large language models poses serious safety risks
Paul Youssef, Zhixue Zhao, Daniel Braun, Jörg Schlötterer, and Christin Seifert. Position: Edit- ing large language models poses serious safety risks. InF orty-second International Conference on Machine Learning Position Paper Track, 2025
work page 2025
-
[34]
How to make llms forget: On reversing in-context knowledge edits
Paul Youssef, Zhixue Zhao, Jörg Schlötterer, and Christin Seifert. How to make llms forget: On reversing in-context knowledge edits. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 12656–12669, 2025
work page 2025
-
[35]
Has this fact been edited? detecting knowledge edits in language models
Paul Youssef, Zhixue Zhao, Christin Seifert, and Jörg Schlötterer. Has this fact been edited? detecting knowledge edits in language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 9768–9784, 2025
work page 2025
-
[36]
A Comprehensive Study of Knowledge Editing for Large Language Models, November 2024
Ningyu Zhang, Yunzhi Yao, Bozhong Tian, Peng Wang, Shumin Deng, Mengru Wang, Zekun Xi, Shengyu Mao, Jintian Zhang, Yuansheng Ni, et al. A comprehensive study of knowledge editing for large language models.arXiv preprint arXiv:2401.01286, 2024
-
[37]
Ce Zheng, Lei Li, Qingxiu Dong, Yuxuan Fan, Zhiyong Wu, Jingjing Xu, and Baobao Chang. Can we edit factual knowledge by in-context learning? InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4862–4876, 2023
work page 2023
-
[38]
Mquake: Assessing knowledge editing in language models via multi-hop questions
Zexuan Zhong, Zhengxuan Wu, Christopher D Manning, Christopher Potts, and Danqi Chen. Mquake: Assessing knowledge editing in language models via multi-hop questions. InProceed- ings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 15686–15702, 2023. A Additional Results on Main Benchmark We provide additional benchmark res...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.