Recognition: 2 theorem links
· Lean TheoremWhen Prompts Become Payloads: A Framework for Mitigating SQL Injection Attacks in Large Language Model-Driven Applications
Pith reviewed 2026-05-12 04:49 UTC · model grok-4.3
The pith
A multi-layered framework can detect and block SQL injection attacks that arrive through natural language prompts to LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
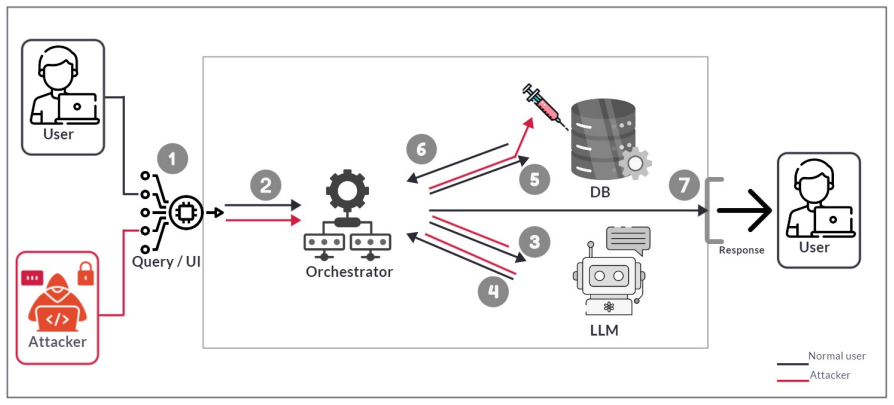
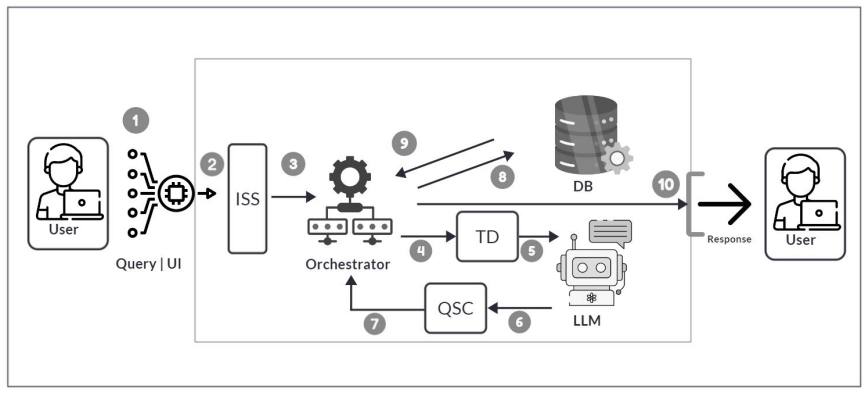
The authors propose a multi-layered security framework for LLM-driven database applications that integrates a front-end security shield for prompt sanitization, an advanced threat detection model for behavioral and semantic anomaly identification, and a signature-based control layer for known attack patterns. They generate a benchmark dataset of adversarial prompts covering prompt injection, obfuscated SQL payloads, and context-manipulation attacks, then evaluate a fine-tuned LLM configuration that achieves high detection accuracy and low false-positive rates.
What carries the argument
The multi-layered security framework that sanitizes prompts, detects anomalies in behavior and semantics, and matches signatures of known attacks to prevent unsafe SQL generation.
If this is right
- The framework achieves high detection accuracy across diverse attack scenarios while maintaining low false-positive rates.
- It supports the secure deployment of LLM-powered applications that allow natural language queries to databases.
- It handles prompt injection, obfuscated payloads, and context manipulation attacks effectively.
- Using a curated benchmark of adversarial prompts ensures robustness in testing.
Where Pith is reading between the lines
- Similar layered defenses might apply to other LLM tasks like generating code or controlling devices where inputs could be manipulated.
- Combining this with traditional database permissions could create stronger overall protection without replacing existing systems.
- Testing the framework on live user queries in a production setting would reveal how well it performs under real usage patterns.
Load-bearing premise
The generated benchmark dataset captures enough of the real-world variety of possible attacks and the fine-tuned model will work on prompts outside the test set.
What would settle it
A test where new adversarial prompts are created by independent attackers or methods not used in the benchmark, and the framework's accuracy on those is measured to see if it drops significantly.
Figures



read the original abstract
Natural language interfaces to structured databases are becoming increasingly common, largely due to advances in large language models (LLMs) that enable users to query data using conversational input rather than formal query languages such as SQL. While this paradigm significantly improves usability and accessibility, it introduces new security risks, particularly the amplification of SQL injection vulnerabilities through the prompt-to-SQL translation process. Malicious users can exploit these mechanisms by crafting adversarial prompts that manipulate model behavior and generate unsafe queries. In this work, we propose a multi-layered security framework designed to detect and mitigate LLM-mediated SQL injection attacks. The framework integrates a front-end security shield for prompt sanitization, an advanced threat detection model for behavioral and semantic anomaly identification, and a signature-based control layer for known attack patterns. We evaluate the proposed framework under diverse and realistic attack scenarios, including prompt injection, obfuscated SQL payloads, and context-manipulation attacks. To ensure robustness, we generate and curate a comprehensive benchmark dataset of adversarial prompts and assess performance across a fine-tuned LLM configuration. Experimental results demonstrate that the proposed approach achieves high detection accuracy while maintaining low false-positive rates, significantly improving the secure deployment of LLM-powered database applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-layered security framework to detect and mitigate SQL injection attacks in LLM-driven natural language to SQL applications. The framework combines a front-end prompt sanitization shield, a behavioral/semantic anomaly detection model, and a signature-based control layer for known patterns. The authors generate and curate a benchmark of adversarial prompts covering prompt injection, obfuscated payloads, and context manipulation, then evaluate a fine-tuned LLM configuration on this dataset, claiming high detection accuracy and low false-positive rates.
Significance. If the evaluation holds under realistic conditions, the work addresses an emerging and practically relevant security gap at the intersection of LLMs and database interfaces. The multi-layer design is a reasonable engineering response to the problem, and the emphasis on generating an adversarial benchmark is a positive step toward reproducible evaluation in this domain.
major comments (3)
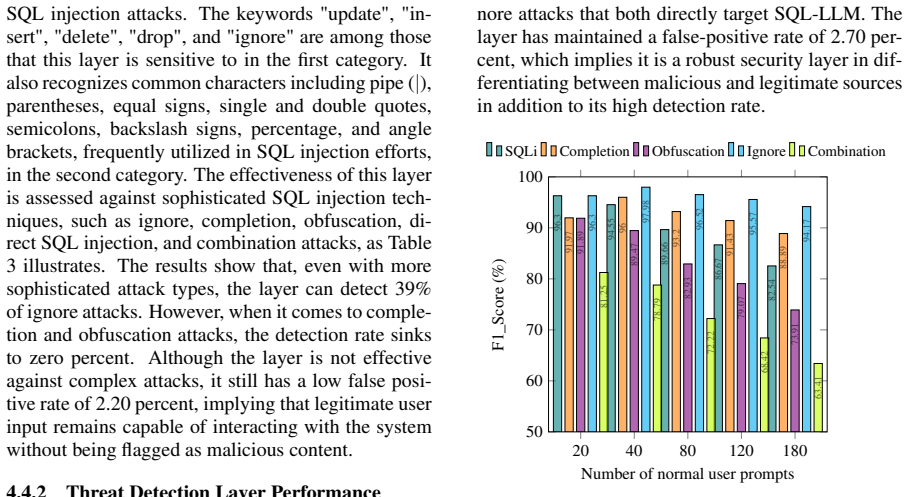
- [Abstract, §4] Abstract and §4 (Evaluation): The central claim that the framework 'achieves high detection accuracy while maintaining low false-positive rates' is unsupported by any quantitative metrics, dataset statistics, train/test split details, or baseline comparisons. No accuracy, precision, recall, or F1 numbers appear, nor is the benchmark size, generation procedure, or diversity (e.g., novel obfuscations vs. template reuse) described.
- [§4] §4: The evaluation relies entirely on a self-generated benchmark of adversarial prompts. Without external validation sets, production-style query distributions, or tests against unseen attack variants, it is impossible to determine whether reported performance reflects genuine generalization or overfitting to the authors' own prompt templates.
- [§3] §3 (Framework): The integration of the three layers is described at a high level only. No formal threat model, pseudocode, or interaction protocol between the sanitization shield, anomaly detector, and signature layer is provided, leaving the concrete mitigation mechanism underspecified.
minor comments (2)
- [Abstract, §1] The abstract and introduction would benefit from a brief related-work paragraph situating the approach against prior LLM prompt-injection defenses and traditional SQL-injection tools.
- [§3] Notation for the threat detection model (e.g., input features, fine-tuning objective) is introduced without a dedicated equation or diagram, reducing clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improvement in the presentation of our evaluation and framework details. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Evaluation): The central claim that the framework 'achieves high detection accuracy while maintaining low false-positive rates' is unsupported by any quantitative metrics, dataset statistics, train/test split details, or baseline comparisons. No accuracy, precision, recall, or F1 numbers appear, nor is the benchmark size, generation procedure, or diversity (e.g., novel obfuscations vs. template reuse) described.
Authors: We agree that the current manuscript presents performance claims qualitatively without sufficient quantitative support. Our experiments produced specific metrics, but these were not included in the submitted version. In the revision, we will expand §4 with accuracy, precision, recall, F1 scores, dataset statistics, train/test split details, benchmark generation procedure, diversity analysis, and baseline comparisons. The abstract will be updated to reference key quantitative results. revision: yes
-
Referee: [§4] §4: The evaluation relies entirely on a self-generated benchmark of adversarial prompts. Without external validation sets, production-style query distributions, or tests against unseen attack variants, it is impossible to determine whether reported performance reflects genuine generalization or overfitting to the authors' own prompt templates.
Authors: This observation is correct and points to a genuine limitation of the current evaluation. While self-generated benchmarks are necessary in this emerging domain due to the lack of public datasets, we will revise §4 to include performance results on a held-out subset of unseen attack variants created with novel obfuscations and templates. We will also add an explicit discussion of the risks of overfitting and the absence of external or production-style validation sets as a limitation. revision: partial
-
Referee: [§3] §3 (Framework): The integration of the three layers is described at a high level only. No formal threat model, pseudocode, or interaction protocol between the sanitization shield, anomaly detector, and signature layer is provided, leaving the concrete mitigation mechanism underspecified.
Authors: We concur that the framework description in §3 remains at a conceptual level. The revised manuscript will add a formal threat model, pseudocode for the end-to-end detection and mitigation workflow, and a precise specification of the interaction protocol among the three layers, including decision rules for sanitization, anomaly flagging, and signature matching. revision: yes
Circularity Check
No circularity in framework proposal or evaluation
full rationale
The paper proposes a multi-layered security framework integrating prompt sanitization, behavioral anomaly detection, and signature-based controls, then reports empirical performance on a generated benchmark of adversarial prompts. No equations, self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described structure. The evaluation is presented as direct assessment of the proposed components rather than any derivation that reduces to its own inputs by construction. The chain is self-contained as a design plus empirical test on curated data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-layered security framework... Input Security Shield... Advanced Threat Detection layer... Query Signature Control layer
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fine-tuned LLM configuration... high detection accuracy while maintaining low false-positive rates
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ahmed, A. S. S. and Shachi, M. (2021). SQL Injec- tion Dataset on kaggle.com. https://www.kaggle.com/ datasets/sajid576/sql-injection-dataset. [Accessed 10- 10-2025]. Ahmed, T. and Devanbu, P. (2022). Few-shot training llms for project-specific code-summarization. In Proceed- ings of the 37th IEEE/ACM International Conference on Automated Software Enginee...
work page 2021
-
[2]
Baryannis, G., Validi, S., Dani, S., and Antoniou, G
IEEE. Baryannis, G., Validi, S., Dani, S., and Antoniou, G. (2019). Supply chain risk management and artificial intel- ligence: state of the art and future research direc- tions. International journal of production research , 57(7):2179–2202. Boekweg, K. I. (2024). Developing a sql injection exploita- tion tool with natural language generation. Brown, H.,...
-
[3]
Dhamankar, M. (2024). Extraction of Training Data from Fine-Tuned Large Language Models . PhD thesis, Carnegie Mellon University Pittsburgh, PA. Dunkin, M. (2024). Detecting cypher injection with open- source network intrusion detection. Fang, R., Bindu, R., Gupta, A., and Kang, D. (2024). Llm agents can autonomously exploit one-day vulnerabili- ties. arX...
-
[4]
Shaikh, O., Zhang, H., Held, W., Bernstein, M., and Yang, D. (2022). On second thought, let’s not think step by step! bias and toxicity in zero-shot reasoning. arXiv preprint arXiv:2212.08061. Sree, D. U., Reddy, P. H., Reddy, G. V . K., and Sumanth, M. (2024). Sql injection attacks: Exploiting vulnera- bilities in database systems. In Advances in Computa...
-
[5]
Wei, W., Le, Q., Dai, A., and Li, J. (2018). AirDialogue: An environment for goal-oriented dialogue research. In Riloff, E., Chiang, D., Hockenmaier, J., and Tsu- jii, J., editors, Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages 3844–3854, Brussels, Belgium. Association for Computational Linguistics. Winograd...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.