Recognition: 2 theorem links
· Lean TheoremRelative Score Policy Optimization for Diffusion Language Models
Pith reviewed 2026-05-12 03:40 UTC · model grok-4.3
The pith
Relative Score Policy Optimization calibrates noisy log-ratio estimates in diffusion language models using verifiable rewards as targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By interpreting reward advantages as targets for relative log-ratios and optimizing the policy on the calibration error between noisy estimates and these targets, RSPO enables stable and effective reinforcement learning with verifiable rewards for diffusion language models.
What carries the argument
The calibration step that sets the reward advantage as the target relative log-ratio and updates the policy according to the difference from the current noisy estimate.
Load-bearing premise
Reward advantages give a reliable and unbiased signal for the true relative log-ratio between policies.
What would settle it
A controlled test on a planning benchmark where RSPO produces no gain or added instability when the reward model is replaced with one known to be uncorrelated with actual policy improvements.
Figures



read the original abstract
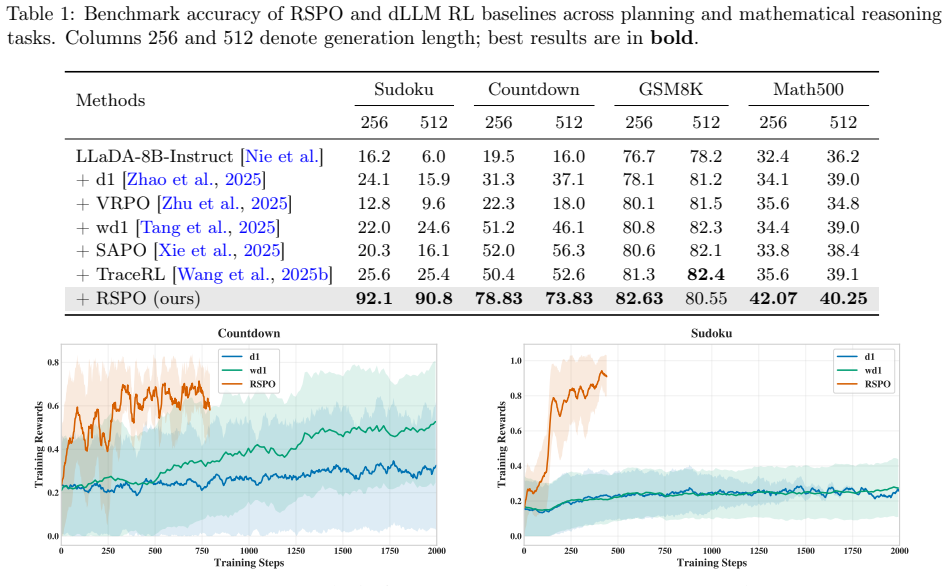
Diffusion large language models (dLLMs) offer a promising route to parallel and efficient text generation, but improving their reasoning ability requires effective post-training. Reinforcement learning with verifiable rewards (RLVR) is a natural choice for this purpose, yet its application to dLLMs is hindered by the absence of tractable sequence-level log-ratios, which are central to standard policy optimization. The lack of tractable sequence-level log-ratios forces existing methods to rely on high-variance ELBO-based approximations, where high verifier rewards can amplify inaccurate score estimates and destabilize RL training. To overcome this issue, we propose \textbf{R}elative \textbf{S}core \textbf{P}olicy \textbf{O}ptimization (RSPO), a simple RLVR method that uses verifiable rewards to calibrate noisy likelihood estimates in dLLMs. The core of our algorithm relies on a key observation: a reward advantage can be interpreted not only as an update direction, but also as a target for the relative log-ratio between the current and reference policies. Accordingly, RSPO calibrates this noisy relative log-ratio estimate by comparing its reward advantage with the reward-implied target relative log-ratio, updating the policy according to the gap between the current estimate and the target rather than the raw advantage alone. Experiments on mathematical reasoning and planning benchmarks show that RSPO yields especially strong gains on planning tasks and competitive mathematical-reasoning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Relative Score Policy Optimization (RSPO) as a reinforcement learning with verifiable rewards (RLVR) method tailored to diffusion large language models (dLLMs). It identifies the intractability of sequence-level log-ratios as the source of high-variance ELBO approximations in existing approaches, which can be destabilized by high verifier rewards. RSPO interprets reward advantage as both an update direction and a target for the relative log-ratio between current and reference policies, then updates the policy on the gap between the noisy estimate and this target to calibrate likelihoods. Experiments are reported to show strong gains on planning benchmarks and competitive performance on mathematical reasoning tasks.
Significance. If the calibration mechanism proves robust, RSPO could enable more stable post-training of dLLMs for reasoning, addressing a key barrier to their adoption over autoregressive models. The approach builds on standard RL concepts with a targeted adaptation, and the empirical focus on verifiable rewards aligns with current trends in LLM alignment. However, the significance hinges on whether the method genuinely reduces variance without introducing reward-model biases, which the provided description leaves open.
major comments (3)
- [Abstract and §3] Abstract and §3 (method description): The core claim that 'a reward advantage can be interpreted ... as a target for the relative log-ratio' is load-bearing but under-specified for binary 0/1 verifiable rewards. Advantage is discrete and bounded while log-ratios are unbounded; without an explicit temperature β, baseline subtraction, or value function to scale the target, the gap update risks driving probability mass to extremes rather than stabilizing the ELBO estimate.
- [Experiments] Experiments section (results on planning and math benchmarks): The reported 'especially strong gains on planning tasks' and 'competitive mathematical-reasoning performance' lack effect sizes, standard deviations, number of runs, or direct comparison to ELBO-based RLVR baselines. This makes it impossible to verify whether the calibration step reduces variance or simply correlates with other implementation choices.
- [§3.2] §3.2 or algorithm pseudocode: No derivation or variance analysis is shown demonstrating that updating on the gap between noisy relative log-ratio and reward-implied target reduces ELBO variance rather than coupling reward noise into the already-approximate diffusion likelihoods.
minor comments (2)
- [Abstract] Notation for the reference policy and current policy should be introduced consistently (e.g., π_ref vs. π_θ) at first use to aid readability.
- [Abstract] The abstract would benefit from naming the specific planning and math benchmarks (e.g., GSM8K, MATH, or planning-specific suites) and listing the main baselines.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below with clarifications and commitments to revisions that strengthen the presentation of the method, experiments, and analysis without misrepresenting the original contributions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): The core claim that 'a reward advantage can be interpreted ... as a target for the relative log-ratio' is load-bearing but under-specified for binary 0/1 verifiable rewards. Advantage is discrete and bounded while log-ratios are unbounded; without an explicit temperature β, baseline subtraction, or value function to scale the target, the gap update risks driving probability mass to extremes rather than stabilizing the ELBO estimate.
Authors: We agree that the scaling for binary verifiable rewards requires explicit treatment to prevent potential instability from unbounded log-ratios. In the revised manuscript we will introduce a temperature parameter β that scales the reward advantage to define the target relative log-ratio (target = β × advantage). This provides a continuous, tunable calibration signal, bounds the magnitude of updates, and avoids driving probability mass to extremes. We will update the abstract, §3, and the method description accordingly, while preserving the core interpretation that the advantage serves as both direction and target. revision: yes
-
Referee: [Experiments] Experiments section (results on planning and math benchmarks): The reported 'especially strong gains on planning tasks' and 'competitive mathematical-reasoning performance' lack effect sizes, standard deviations, number of runs, or direct comparison to ELBO-based RLVR baselines. This makes it impossible to verify whether the calibration step reduces variance or simply correlates with other implementation choices.
Authors: We acknowledge that the current experimental reporting is insufficient for rigorous verification. In the revised experiments section we will add absolute effect sizes, standard deviations computed across multiple independent runs (explicitly stating the number of random seeds), and direct head-to-head comparisons against ELBO-based RLVR baselines. These additions will allow readers to isolate the contribution of the RSPO calibration to variance reduction. revision: yes
-
Referee: [§3.2] §3.2 or algorithm pseudocode: No derivation or variance analysis is shown demonstrating that updating on the gap between noisy relative log-ratio and reward-implied target reduces ELBO variance rather than coupling reward noise into the already-approximate diffusion likelihoods.
Authors: The original manuscript emphasizes the algorithmic intuition and empirical results. To address the request for theoretical grounding, we will add a concise derivation in the appendix (and reference it from §3.2) showing that the gap update minimizes a calibrated surrogate whose fixed point aligns the noisy log-ratio estimate to the reward-derived target. This anchoring demonstrably reduces the variance of the effective ELBO gradient without directly injecting reward noise into the diffusion likelihood parameters, as the update operates on the discrepancy rather than the raw advantage. revision: partial
Circularity Check
No circularity: RSPO is a design choice built on an interpretive observation, not a reduction to fitted inputs or self-citations
full rationale
The paper's central step is the stated observation that reward advantage can serve as a target for relative log-ratio, followed by an update rule that minimizes the gap between the noisy estimate and this target. This is presented as a modeling choice adapting RLVR to dLLMs rather than a derivation whose equations reduce by construction to the inputs (no self-definitional loops, no fitted parameters renamed as predictions, and no load-bearing self-citations appear in the provided text). The method remains self-contained against external benchmarks because the calibration rule is independently motivated and falsifiable via downstream task performance; the binary-reward scaling concern is a question of correctness, not circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward advantage can be interpreted as a target for the relative log-ratio between current and reference policies
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleara reward advantage can be interpreted not only as an update direction, but also as a target for the relative log-ratio between the current and reference policies... wi = eAi − λ sg(bδi)
Reference graph
Works this paper leans on
-
[1]
Reinforcement learning: An introduction , author=. 1998 , publisher=
work page 1998
-
[6]
Open-Sora: Democratizing Efficient Video Production for All
Open-sora: Democratizing efficient video production for all , author=. arXiv preprint arXiv:2412.20404 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
-
[11]
von Werra, Leandro and Belkada, Younes and Tunstall, Lewis and Beeching, Edward and Thrush, Tristan and Lambert, Nathan and Huang, Shengyi and Rasul, Kashif and Gallouédec, Quentin , license =
-
[17]
Advances in Neural Information Processing Systems , volume=
Simple and effective masked diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data , author=
-
[20]
Advances in neural information processing systems , volume=
Simplified and generalized masked diffusion for discrete data , author=. Advances in neural information processing systems , volume=
-
[21]
Large Language Diffusion Models , author=
-
[28]
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author=
-
[31]
Score-Based Generative Modeling through Stochastic Differential Equations , author=
-
[32]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[33]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[34]
Advances in neural information processing systems , volume=
Structured denoising diffusion models in discrete state-spaces , author=. Advances in neural information processing systems , volume=
-
[35]
Advances in Neural Information Processing Systems , volume=
A continuous time framework for discrete denoising models , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author=
-
[38]
arXiv preprint arXiv:2510.08554 , year=
Improving reasoning for diffusion language models via group diffusion policy optimization , author=. arXiv preprint arXiv:2510.08554 , year=
-
[43]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[44]
Large deviations techniques and applications , author=. 2009 , publisher=
work page 2009
-
[49]
Arel's Sudoku Generator , howpublished =
-
[50]
Jiayi Pan and Junjie Zhang and Xingyao Wang and Lifan Yuan and Hao Peng and Alane Suhr , title =
-
[51]
The twelfth international conference on learning representations , year=
Let's verify step by step , author=. The twelfth international conference on learning representations , year=
-
[53]
Advances in Neural Information Processing Systems , year=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , year=
-
[55]
International Conference on Machine Learning , year=
Trust Region Policy Optimization , author=. International Conference on Machine Learning , year=
-
[56]
Advances in Neural Information Processing Systems , year=
Policy Gradient Methods for Reinforcement Learning with Function Approximation , author=. Advances in Neural Information Processing Systems , year=
-
[57]
arXiv preprint arXiv:2308.12219 , year=
Diffusion Language Models Can Perform Many Tasks with Scaling and Instruction-Finetuning , author=. arXiv preprint arXiv:2308.12219 , year=
-
[58]
https://www.ocf.berkeley.edu/ arel/sudoku/main.html
Arel's sudoku generator. https://www.ocf.berkeley.edu/ arel/sudoku/main.html. Accessed: 2026-05-03
work page 2026
-
[59]
Inclusion AI, Tiwei Bie, Haoxing Chen, Tieyuan Chen, Zhenglin Cheng, Long Cui, Kai Gan, Zhicheng Huang, Zhenzhong Lan, Haoquan Li, et al. Llada2. 0-uni: Unifying multimodal understanding and generation with diffusion large language model. arXiv preprint arXiv:2604.20796, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Block diffusion: Interpolating between autoregressive and diffusion language models
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. In The Thirteenth International Conference on Learning Representations
-
[61]
Structured denoising diffusion models in discrete state-spaces
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces. Advances in neural information processing systems, 34: 0 17981--17993, 2021
work page 2021
-
[62]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b. arXiv preprint arXiv:2512.15745, 2025
work page internal anchor Pith review arXiv 2025
-
[63]
A continuous time framework for discrete denoising models
Andrew Campbell, Joe Benton, Valentin De Bortoli, Thomas Rainforth, George Deligiannidis, and Arnaud Doucet. A continuous time framework for discrete denoising models. Advances in Neural Information Processing Systems, 35: 0 28266--28279, 2022
work page 2022
-
[64]
Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, Kai Chen, Biqing Qi, et al. Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation. arXiv preprint arXiv:2510.06303, 2025
-
[65]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[66]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34: 0 8780--8794, 2021
work page 2021
-
[67]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model. arXiv preprint arXiv:2601.03233, 2026
work page Pith review arXiv 2026
-
[70]
Shenghua He, Tian Xia, Xuan Zhou, and Hui Wei. Response-level rewards are all you need for online reinforcement learning in llms: A mathematical perspective. arXiv preprint arXiv:2506.02553, 2025
-
[71]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 0 6840--6851, 2020
work page 2020
-
[72]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. Iclr, 1 0 (2): 0 3, 2022
work page 2022
-
[73]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In The twelfth international conference on learning representations, 2023
work page 2023
-
[75]
Boundary-guided policy optimization for memory-efficient rl of diffusion large language models
Nianyi Lin, Jiajie Zhang, Lei Hou, and Juanzi Li. Boundary-guided policy optimization for memory-efficient rl of diffusion large language models. arXiv preprint arXiv:2510.11683, 2025
-
[76]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[77]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. In Forty-first International Conference on Machine Learning
-
[78]
Large language diffusion models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, JUN ZHOU, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[79]
Your absorbing discrete diffusion secretly models the conditional distributions of clean data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. In The Thirteenth International Conference on Learning Representations
-
[80]
Principled rl for diffusion llms emerges from a sequence-level perspective, 2025
Jingyang Ou, Jiaqi Han, Minkai Xu, Shaoxuan Xu, Jianwen Xie, Stefano Ermon, Yi Wu, and Chongxuan Li. Principled rl for diffusion llms emerges from a sequence-level perspective. arXiv preprint arXiv:2512.03759, 2025
-
[81]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, 2022
work page 2022
- [82]
-
[83]
d-treerpo: Towards more reliable policy optimization for diffusion language models
Leyi Pan, Shuchang Tao, Yunpeng Zhai, Zheyu Fu, Liancheng Fang, Minghua He, Lingzhe Zhang, Zhaoyang Liu, Bolin Ding, Aiwei Liu, et al. d-treerpo: Towards more reliable policy optimization for diffusion language models. arXiv preprint arXiv:2512.09675, 2025 b
work page internal anchor Pith review arXiv 2025
-
[84]
Simple and effective masked diffusion language models
Subham S Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and Volodymyr Kuleshov. Simple and effective masked diffusion language models. Advances in Neural Information Processing Systems, 37: 0 130136--130184, 2024
work page 2024
-
[85]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[86]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity. arXiv preprint arXiv:2604.14148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[87]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[88]
Simplified and generalized masked diffusion for discrete data
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data. Advances in neural information processing systems, 37: 0 103131--103167, 2024
work page 2024
-
[89]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations
-
[90]
Reinforcement learning: An introduction, volume 1
Richard S Sutton, Andrew G Barto, et al. Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
work page 1998
-
[91]
wd1: Weighted policy optimization for reasoning in diffusion language models
Xiaohang Tang, Rares Dolga, Sangwoong Yoon, and Ilija Bogunovic. wd1: Weighted policy optimization for reasoning in diffusion language models. arXiv preprint arXiv:2507.08838, 2025
-
[92]
TRL: Transformers Reinforcement Learning , 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: Transformers Reinforcement Learning , 2020. URL https://github.com/huggingface/trl
work page 2020
-
[93]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[94]
SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models
Chenyu Wang, Paria Rashidinejad, DiJia Su, Song Jiang, Sid Wang, Siyan Zhao, Cai Zhou, Shannon Zejiang Shen, Feiyu Chen, Tommi Jaakkola, et al. Spg: Sandwiched policy gradient for masked diffusion language models. arXiv preprint arXiv:2510.09541, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[95]
Revolutionizing reinforcement learning framework for diffusion large language models
Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang. Revolutionizing reinforcement learning framework for diffusion large language models. arXiv preprint arXiv:2509.06949, 2025 b
-
[96]
Advancing Reasoning in Diffusion Language Models with Denoising Process Rewards
Shaoan Xie, Lingjing Kong, Xiangchen Song, Xinshuai Dong, Guangyi Chen, Eric P Xing, and Kun Zhang. Step-aware policy optimization for reasoning in diffusion large language models. arXiv preprint arXiv:2510.01544, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[97]
Mmada: Multimodal large diffusion language models.arXiv preprint arXiv:2505.15809,
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. Mmada: Multimodal large diffusion language models. arXiv preprint arXiv:2505.15809, 2025
-
[98]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[99]
Zebin You, Shen Nie, Xiaolu Zhang, Jun Hu, Jun Zhou, Zhiwu Lu, Ji-Rong Wen, and Chongxuan Li. Llada-v: Large language diffusion models with visual instruction tuning. arXiv preprint arXiv:2505.16933, 2025
-
[100]
Llada-o: An effective and length-adaptive omni diffusion model
Zebin You, Xiaolu Zhang, Jun Zhou, Chongxuan Li, and Ji-Rong Wen. Llada-o: An effective and length-adaptive omni diffusion model. arXiv preprint arXiv:2603.01068, 2026
-
[101]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[102]
Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. d1: Scaling reasoning in diffusion large language models via reinforcement learning. arXiv preprint arXiv:2504.12216, 2025
-
[103]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization. arXiv preprint arXiv:2507.18071, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[104]
Open-sora 2.0: Training a commercial-level video generation model in $200k,
Zangwei Zheng, Xiangyu Peng, Yuxuan Lou, Chenhui Shen, Tom Young, Xinying Guo, Binluo Wang, Hang Xu, Hongxin Liu, Mingyan Jiang, et al. Open-sora 2.0: Training a commercial-level video generation model in \ 200 k. arXiv preprint arXiv:2503.09642, 2025 b
- [105]
-
[106]
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, et al. Llada 1.5: Variance-reduced preference optimization for large language diffusion models. arXiv preprint arXiv:2505.19223, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.