Recognition: no theorem link
ANCHOR: Abductive Network Construction with Hierarchical Orchestration for Reliable Probability Inference in Large Language Models
Pith reviewed 2026-05-13 07:34 UTC · model grok-4.3
The pith
ANCHOR builds dense hierarchical factor spaces from LLMs via iterative generation and clustering to support reliable Bayesian probability estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ANCHOR constructs dense factor hierarchies through iterative LLM generation and clustering, maps input contexts via hierarchical retrieval and refinement, and augments naive Bayes with a causal Bayesian network to model latent dependencies, thereby reducing unknown predictions and improving the reliability of probability estimates under incomplete information.
What carries the argument
Hierarchical factor space built by iterative generation and clustering, with inference performed by an aggregated Bayesian model that augments naive Bayes using a causal Bayesian network over the hierarchy.
If this is right
- The number of unknown predictions drops markedly relative to direct LLM or flat naive Bayes baselines.
- Probability estimates become more reliable because latent dependencies are explicitly modeled.
- State-of-the-art performance is reached on the evaluated probability-inference tasks.
- Both inference time and token consumption decrease substantially.
Where Pith is reading between the lines
- The same hierarchical orchestration could be applied to uncertainty quantification in other LLM tasks such as risk scoring or multi-step planning.
- If the clustering step can be made more robust, the approach might reduce the need for human-curated factor ontologies in probabilistic reasoning systems.
- Direct measurement of calibration on datasets with verifiable outcome frequencies would provide a stronger test than the current benchmarks.
Load-bearing premise
Iterative LLM generation plus clustering will reliably produce a hierarchical factor space that captures genuine latent dependencies without injecting new noise or spurious correlations.
What would settle it
On a benchmark where ground-truth probabilities are known, if ANCHOR produces higher calibration error or more unknown outputs than a direct LLM baseline after the same number of tokens, the reliability improvement claim does not hold.
Figures



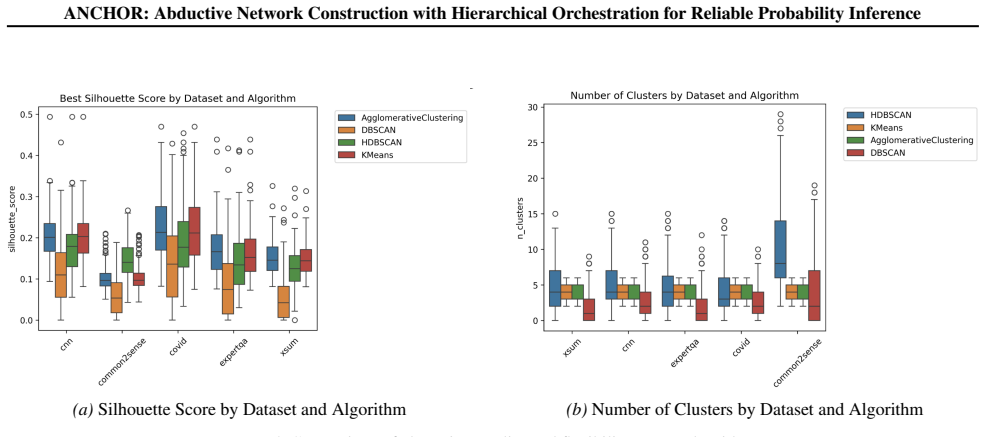
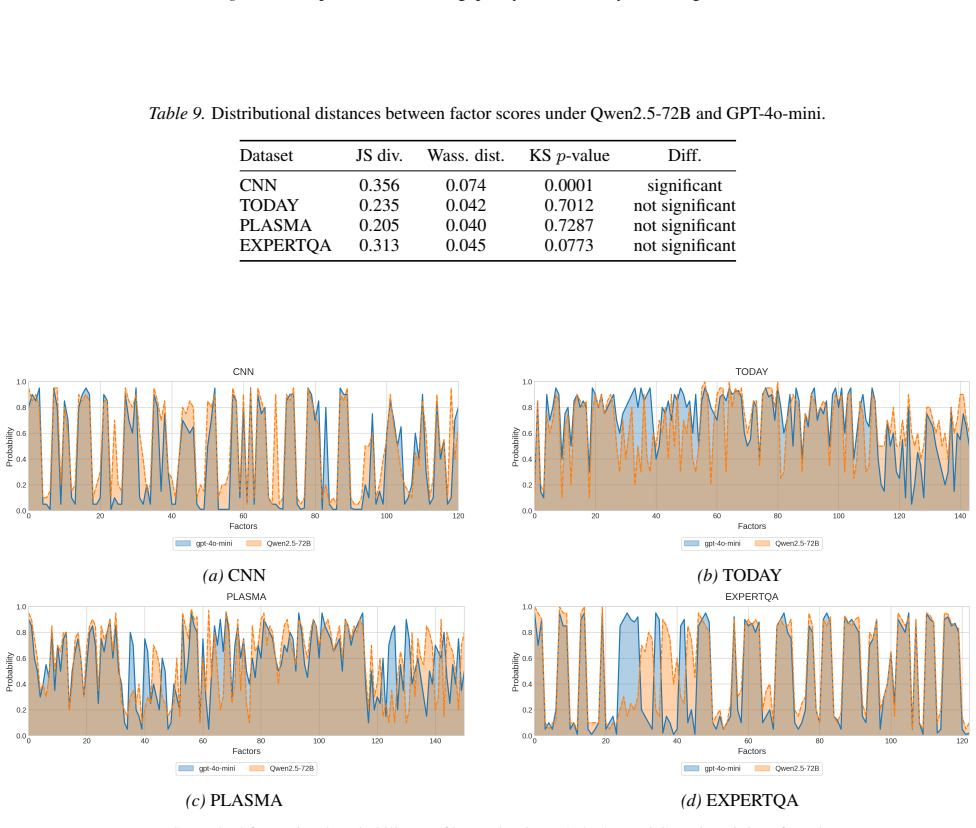









read the original abstract
A central challenge in large-scale decision-making under incomplete information is estimating reliable probabilities. Recent approaches use Large Language Models (LLMs) to generate explanatory factors and coarse-grained probability estimates, which are then refined by a Na\"ive Bayes model over factor combinations. However, sparse factor spaces often yield ``unknown'' predictions, while expanding factors increases noise and spurious correlations, weakening conditional independence and degrading reliability. To address these limitations, we propose \textsc{Anchor}, an aggregated Bayesian inference framework over a hierarchical factor space. It constructs dense factor hierarchies through iterative generation and clustering, maps contexts via hierarchical retrieval and refinement, and augments Na\"ive Bayes with a Causal Bayesian Network to model latent factor dependencies. Experiments show that \textsc{Anchor} markedly reduces ``unknown'' predictions and produces more reliable probability estimates than direct LLM baselines, achieving state-of-the-art performance while significantly reducing time and token overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ANCHOR, an aggregated Bayesian inference framework for reliable probability estimation in LLMs under incomplete information. It constructs dense hierarchical factor spaces via iterative LLM generation and clustering, performs hierarchical context retrieval and refinement, and augments a Naïve Bayes model with a Causal Bayesian Network to capture latent factor dependencies. The central claim is that this reduces 'unknown' predictions, yields more reliable probability estimates than direct LLM baselines, achieves state-of-the-art performance, and lowers time and token overhead.
Significance. If the experimental results hold and the constructed hierarchies faithfully recover causal dependencies, the work would provide a practical method to combine LLM generation with structured probabilistic models, addressing sparsity and spurious correlations in factor-based inference. This could advance reliable abductive reasoning in decision-making applications while improving efficiency over pure generative approaches.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The performance claims (marked reduction in 'unknown' predictions, SOTA reliability, lower overhead) are stated without any metrics, baselines, ablation results, or dataset details in the provided text, making it impossible to assess whether the data support the central claims or whether gains arise from the hierarchical CBN augmentation versus other factors.
- [§3.2] §3.2 (Hierarchical factor space construction): The iterative LLM generation plus clustering step is load-bearing for the reliability claim, yet the manuscript provides no validation (e.g., comparison to ground-truth causal graphs, interventional tests, or checks against spurious correlations) that the resulting hierarchy captures true latent dependencies rather than surface-level embeddings; without this, reported improvements in calibration could be artifacts of over-parameterization.
minor comments (2)
- [§3.3] Notation for the Causal Bayesian Network augmentation to Naïve Bayes is introduced without an explicit equation showing how conditional dependencies are incorporated into the joint probability factorization.
- [Abstract] The abstract uses inconsistent quoting for 'unknown' predictions; standardize to single quotes or a defined term throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The performance claims (marked reduction in 'unknown' predictions, SOTA reliability, lower overhead) are stated without any metrics, baselines, ablation results, or dataset details in the provided text, making it impossible to assess whether the data support the central claims or whether gains arise from the hierarchical CBN augmentation versus other factors.
Authors: The complete manuscript contains a detailed Section 4 reporting quantitative results across multiple datasets, including specific metrics for the reduction in 'unknown' predictions, calibration and reliability scores, direct comparisons to LLM baselines and prior SOTA methods, ablation studies isolating the contribution of the hierarchical CBN component, and measurements of time/token overhead. These results indicate that the observed gains are attributable to the proposed architecture rather than other factors. We will revise the abstract to include key quantitative highlights and add a concise summary table of metrics at the start of §4 to make the supporting evidence immediately accessible. revision: yes
-
Referee: [§3.2] §3.2 (Hierarchical factor space construction): The iterative LLM generation plus clustering step is load-bearing for the reliability claim, yet the manuscript provides no validation (e.g., comparison to ground-truth causal graphs, interventional tests, or checks against spurious correlations) that the resulting hierarchy captures true latent dependencies rather than surface-level embeddings; without this, reported improvements in calibration could be artifacts of over-parameterization.
Authors: We agree that direct validation against ground-truth causal graphs would be ideal; however, no such annotated ground-truth structures exist for the open-domain decision-making tasks in our evaluation. We therefore rely on downstream empirical improvements in reliability and efficiency. In the revision we will (1) expand §3.2 with a discussion of possible spurious correlations and embedding artifacts, (2) add an ablation comparing the hierarchical construction against a flat factor baseline to isolate its contribution, and (3) include a limitations paragraph acknowledging the absence of interventional or causal-fidelity tests. These additions should help address concerns about over-parameterization. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper constructs a hierarchical factor space via iterative LLM generation and clustering, then augments standard Naive Bayes with a Causal Bayesian Network. No equations or steps reduce by construction to fitted parameters on the same test data, no self-citation is load-bearing for the core claim, and no ansatz or uniqueness result is smuggled in from prior author work. The reported gains in reducing 'unknown' predictions are presented as empirical outcomes of the new construction pipeline rather than tautological redefinitions of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Naive Bayes conditional independence assumptions can be usefully relaxed by adding explicit causal dependencies among factors
invented entities (1)
-
Hierarchical factor space
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.1145/3677389.3702605. URL https: //doi.org/10.1145/3677389.3702605. Babakov, N., Reiter, E., and Bugarín-Diz, A. Scalabil- ity of Bayesian network structure elicitation with large language models: a novel methodology and compara- tive analysis. In Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B. D., and Schockaert, S. (eds.),Pro...
-
[2]
doi: 10.1109/ICCV51070.2023.01398. Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., and Larson, J. From local to global: A graph RAG approach to query-focused summarization. CoRR, abs/2404.16130, 2024. doi: 10.48550/ARXIV . 2404.16130. Feng, Y ., Zhou, B., Wang, H., Jin, H., and Roth, D. Generic temporal reasoning with differen...
-
[3]
Feng, Y ., Zhou, B., Lin, W., and Roth, D
doi: 10.18653/V1/2023.ACL-LONG.671. Feng, Y ., Zhou, B., Lin, W., and Roth, D. Bird: A trust- worthy bayesian inference framework for large language models. InProceedings of the International Conference on Learning Representations (ICLR), 2025. Fragoso, T., Bertoli, W., and Louzada, F. Bayesian model averaging: A systematic review and conceptual classific...
-
[4]
URL https://aclanthology.org/2025. findings-emnlp.321/. Jayaweera, C., Youm, S., and Dorr, B. J. AMREx: AMR for explainable fact verification. In Schlichtkrull, M., Chen, Y ., Whitehouse, C., Deng, Z., Akhtar, M., Aly, R., Guo, Z., Christodoulopoulos, C., Cocarascu, O., Mittal, A., Thorne, J., and Vlachos, A. (eds.),Proceedings of the Seventh Fact Extract...
work page 2025
-
[5]
doi: 10.18653/v1/2024.fever-1.26
Association for Computational Linguistics. doi: 10.18653/v1/2024.fever-1.26. Ji, Z., Yu, T., Xu, Y ., Lee, N., Ishii, E., and Fung, P. To- wards mitigating LLM hallucination via self reflection. In Bouamor, H., Pino, J., and Bali, K. (eds.),Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pp. 1827–1843...
-
[6]
URL https://aclanthology.org/2025. findings-acl.1123/. Lin, B. Y ., Fu, Y ., Yang, K., Brahman, F., Huang, S., Bha- gavatula, C., Ammanabrolu, P., Choi, Y ., and Ren, X. Swiftsage: A generative agent with fast and slow think- ing for complex interactive tasks. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.),Advances in ...
work page 2025
-
[7]
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long
-
[8]
GCoT-Decoding: Unlocking Deep Reasoning Paths for Universal Question Answering
URL https://aclanthology.org/2025. acl-long.536/. Luo, G., Qiu, W., Jian, Z., Wang, M., and Wu, Q. Gcot- decoding: Unlocking deep reasoning paths for universal question answering, 2026a. URL https://arxiv. org/abs/2604.06794. Luo, G., Qiu, W., Zhao, W., Lv, W., Jian, Z., Wang, M., and Wu, Q. Agsc: Adaptive granularity and semantic clustering for uncertain...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.naacl-long.167 2025
-
[10]
doi: https://doi.org/10.1016/j.ijcce.2024.11
-
[11]
Prabha, D., Aswini, J., Maheswari, B., Subramanian, R
URL https://www.sciencedirect.com/ science/article/pii/S2666307424000482. Prabha, D., Aswini, J., Maheswari, B., Subramanian, R. S., Nithyanandhan, R., and Girija, P. A survey on alleviat- ing the naive bayes conditional independence assumption. 11 ANCHOR: Abductive Network Construction with Hierarchical Orchestration for Reliable Probability Inference In...
-
[12]
doi: 10.48550/ARXIV .2503.17523. URL https: //doi.org/10.48550/arXiv.2503.17523. Renze, M. and Guven, E. Self-reflection in large language model agents: Effects on problem-solving performance. In2024 2nd International Conference on Foundation and Large Language Models (FLLM), pp. 516–525, 2024. doi: 10.1109/FLLM63129.2024.10852426. Reuter, A., Rudner, T. ...
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[13]
Rethinking tabular data understanding with large language models
URL https://aclanthology.org/2022. emnlp-main.134/. Tang, L., Laban, P., and Durrett, G. MiniCheck: Efficient fact-checking of LLMs on grounding documents. pp. 8818–8847, November 2024. doi: 10.18653/v1/2024. emnlp-main.499. URL https://aclanthology. org/2024.emnlp-main.499/. Wang, W., Wei, F., Dong, L., Bao, H., Yang, N., and Zhou, M. Minilm: deep self-a...
-
[14]
Curran Associates Inc. Zaidi, N. A., Cerquides, J., Carman, M. J., and Webb, G. I. Alleviating naive bayes attribute independence assumption by attribute weighting.J. Mach. Learn. Res., 14(1):1947–1988, 2013. doi: 10.5555/2567709. 2567725. URL https://dl.acm.org/doi/10. 5555/2567709.2567725. Zhang, H. The optimality of naive bayes. pp. 562–567,
-
[15]
URL http://www.aaai.org/Library/ FLAIRS/2004/flairs04-097.php. Zhang, N. L. and Poole, D. A simple approach to bayesian network computations. InProceedings of the biennial conference-Canadian society for computational studies of intelligence, pp. 171–178. CANADIAN INFORMATION PROCESSING SOCIETY , 1994. Zhang, X., Wang, M., Yang, X., Wang, D., Feng, S., an...
-
[16]
URL https://aclanthology.org/2023. emnlp-main.858/. Zhao, H., Chen, H., Yang, F., Liu, N., Deng, H., Cai, H., Wang, S., Yin, D., and Du, M. Explainability for large language models: A survey.ACM Trans. Intell. Syst. Technol., 15(2), February 2024. ISSN 2157-6904. doi: 10.1145/3639372. Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurma...
-
[17]
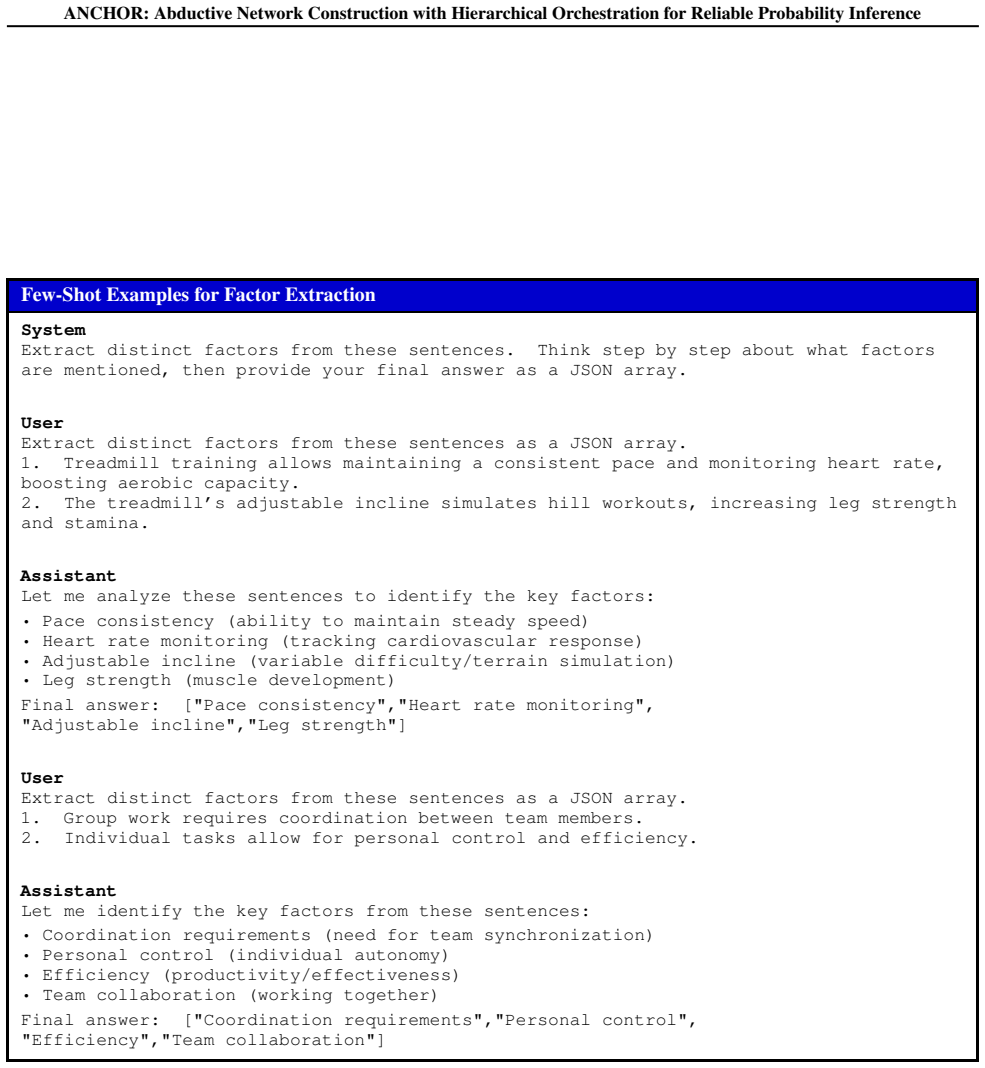
Treadmill training allows Alice to maintain a consistent pace and monitor heart rate, boosting her aerobic capacity
-
[18]
User Scenario: Bob studies every evening
The treadmill’s adjustable incline simulates hill workouts, increasing leg strength and stamina. User Scenario: Bob studies every evening. Outcome: Studying in short, focused bursts enhances retention. Opposite Outcome: Studying in short, focused bursts does not enhance retention. Generate 2 sentences. Assistant
-
[19]
Brief study sessions with breaks prevent mental fatigue and improve long-term recall
-
[20]
Frequent reviews in small intervals reinforce memory pathways, aiding retention. Figure 7.Example Prompt for Generating Supporting or Refuting Sentences 30 ANCHOR: Abductive Network Construction with Hierarchical Orchestration for Reliable Probability Inference Few-Shot Examples for Factor Extraction System Extract distinct factors from these sentences. T...
-
[21]
Treadmill training allows maintaining a consistent pace and monitoring heart rate, boosting aerobic capacity
-
[22]
The treadmill’s adjustable incline simulates hill workouts, increasing leg strength and stamina. Assistant Let me analyze these sentences to identify the key factors: • Pace consistency (ability to maintain steady speed) • Heart rate monitoring (tracking cardiovascular response) • Adjustable incline (variable difficulty/terrain simulation) • Leg strength ...
-
[23]
Group work requires coordination between team members
-
[24]
Individual tasks allow for personal control and efficiency. Assistant Let me identify the key factors from these sentences: • Coordination requirements (need for team synchronization) • Personal control (individual autonomy) • Efficiency (productivity/effectiveness) • Team collaboration (working together) Final answer: ["Coordination requirements","Person...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.