Recognition: no theorem link
Fast Training of Mixture-of-Experts for Time Series Forecasting via Expert Loss Integration
Pith reviewed 2026-05-12 03:49 UTC · model grok-4.3
The pith
Adding expert-specific losses to the training objective lets mixture-of-experts models forecast time series more accurately with far less computation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
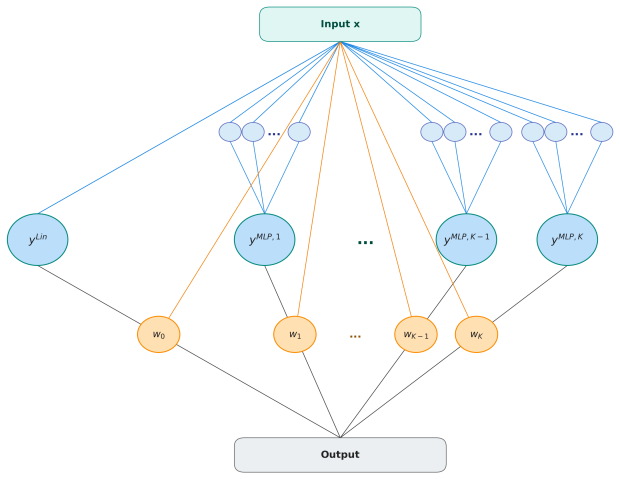
The proposed adaptive Mixture-of-Experts framework incorporates expert-specific loss information directly into the training objective so that the base forecasting loss and the individual expert losses jointly shape the parameters. This combination is paired with a partial online learning strategy that performs incremental updates to both the gating mechanism and the expert parameters, removing the need for repeated full-model retraining and thereby lowering computational cost while preserving predictive performance.
What carries the argument
Expert-specific loss integration, which adds each expert's individual prediction error to the global forecasting loss so that specialization occurs during the same optimization pass.
If this is right
- Forecasting accuracy improves over both classical statistical methods and neural models such as Transformers and WaveNet across datasets of different frequencies.
- Computational cost drops because partial online updates replace full retraining after each new observation.
- Expert specialization increases, as confirmed by ablation studies that isolate the effect of the expert-loss term.
- The same model can be updated incrementally on streaming data without restarting the entire training procedure.
Where Pith is reading between the lines
- The same loss-integration pattern could be tried in mixture-of-experts setups outside time series, such as image or text classification, to test whether per-expert errors help specialization more broadly.
- The partial-update schedule might combine with other memory-efficient techniques like gradient checkpointing to push efficiency further on very long series.
- If expert collapse still occurs on some datasets, a simple regularization term on the gating weights could be added without changing the core objective.
Load-bearing premise
That adding per-expert losses will improve specialization and accuracy without creating training instability or forcing extra hyperparameter choices that erase the efficiency gains.
What would settle it
On one of the economic, tourism, or energy datasets, run the method side-by-side with a standard Transformer baseline and record either higher mean absolute error or longer wall-clock training time than the baseline.
Figures
read the original abstract
We propose a novel adaptive Mixture-of-Experts (MoE) framework for time series forecasting that enhances expert specialization by incorporating expert-specific loss information directly into the training process. Notably, the overall objective comprises the base forecasting loss and expert-specific losses, allowing expert-level prediction errors to jointly shape training alongside the global forecasting loss. This framework is further combined with a partial online learning strategy, enabling incremental updates of both the gating mechanism and expert parameters. This approach significantly reduces computational cost by eliminating the need for repeated full model retraining. By integrating expert-level loss awareness with efficient online optimization, the proposed method achieves improved learning efficiency while maintaining strong predictive performance. Empirical results across economic, tourism, and energy datasets with varying frequencies demonstrate that the proposed approach generally outperforms both statistical methods and state-of-the-art neural network models, such as Transformers and WaveNet, in forecasting accuracy and computational efficiency. Furthermore, ablation studies confirm the effectiveness of the expert-specific loss integration strategy, highlighting its contribution to enhancing predictive performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an adaptive Mixture-of-Experts (MoE) framework for time series forecasting that incorporates expert-specific losses directly into the training objective alongside the base forecasting loss to promote expert specialization. It pairs this with a partial online learning strategy for incremental updates of the gating network and expert parameters without full retraining. Empirical results on economic, tourism, and energy datasets with varying frequencies claim general outperformance over statistical methods and neural baselines such as Transformers and WaveNet in both accuracy and computational efficiency, with ablations supporting the loss integration component.
Significance. If the central empirical claims hold after detailed verification, the work could provide a practical route to more efficient MoE training for non-stationary time series, particularly in settings where models must be updated incrementally. The multi-domain evaluation and emphasis on reducing full retraining costs are positive aspects that address real deployment constraints.
major comments (2)
- [Methodology] Methodology section: The overall objective is stated to comprise the base forecasting loss and expert-specific losses, yet no explicit equation defines the expert loss term, its weighting relative to the global loss, or how gradients flow back to the gating network. This formulation is load-bearing for the specialization claim, as the skeptic correctly notes that without an explicit utilization penalty or routing-entropy analysis the added losses can simply reinforce the current gate and produce collapse rather than specialization, especially under frequency shifts.
- [Experiments] Experiments and results section: The reported outperformance across datasets lacks error bars, number of independent runs, or statistical significance tests. Without these, it is impossible to determine whether the accuracy and efficiency gains are robust or sensitive to post-hoc hyperparameter choices, directly affecting the reliability of the central empirical claim.
minor comments (1)
- [Abstract] The abstract would benefit from a brief parenthetical mention of the base MoE architecture (e.g., number of experts, gating function) to orient readers before the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Methodology] Methodology section: The overall objective is stated to comprise the base forecasting loss and expert-specific losses, yet no explicit equation defines the expert loss term, its weighting relative to the global loss, or how gradients flow back to the gating network. This formulation is load-bearing for the specialization claim, as the skeptic correctly notes that without an explicit utilization penalty or routing-entropy analysis the added losses can simply reinforce the current gate and produce collapse rather than specialization, especially under frequency shifts.
Authors: We agree that an explicit equation is needed for full transparency. In the revised manuscript, we will insert the complete objective L = L_base + λ * Σ L_expert_i (where L_expert_i is the per-expert forecasting loss on routed samples) along with the weighting scheme for λ and a description of gradient flow through the gating network. On the collapse concern, the partial online updates continuously adjust the gate using recent expert losses, which our ablations indicate maintains balanced utilization even across frequency shifts; however, we will add a routing-entropy plot and discussion in the revision to directly address this point. revision: yes
-
Referee: [Experiments] Experiments and results section: The reported outperformance across datasets lacks error bars, number of independent runs, or statistical significance tests. Without these, it is impossible to determine whether the accuracy and efficiency gains are robust or sensitive to post-hoc hyperparameter choices, directly affecting the reliability of the central empirical claim.
Authors: We acknowledge this limitation in the current reporting. We will re-execute all experiments using at least five independent random seeds, report means with standard deviations as error bars in the tables and figures, and include paired statistical significance tests (e.g., t-tests) against baselines. These additions will appear in the main results section and supplementary material of the revised version. revision: yes
Circularity Check
No circularity: empirical claims rest on experimental validation, not self-referential derivations
full rationale
The paper introduces an algorithmic MoE framework for time series forecasting that augments the training objective with expert-specific losses and pairs it with partial online updates. All performance claims are supported by direct empirical comparisons on economic, tourism, and energy datasets against statistical baselines and neural models such as Transformers and WaveNet; ablation studies are likewise reported as experimental outcomes. No derivation chain, uniqueness theorem, fitted-parameter-as-prediction step, or self-citation load-bearing argument appears in the provided text. The method is therefore self-contained as a proposed training procedure whose validity is assessed externally via held-out forecasting accuracy and runtime measurements rather than by construction from its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In Claude Sammut and Geoffrey I
Mean absolute error. In Claude Sammut and Geoffrey I. Webb, editors,Encyclopedia of Machine Learning, pages 652–652. Springer US, Boston, MA, 2010. ISBN 978-0-387-30164-8
work page 2010
-
[2]
V . Assimakopoulos and K. Nikolopoulos. The theta model: a decomposition approach to forecasting.International Journal of Forecasting, 16(4):521–530, 2000. doi: https://doi.org/10. 1016/S0169-2070(00)00066-2. The M3- Competition
work page 2000
-
[3]
The tourism forecasting competition.International Journal of Forecasting, 27(3):822–844, 2011
George Athanasopoulos, Rob J Hyndman, Haiyan Song, and Doris C Wu. The tourism forecasting competition.International Journal of Forecasting, 27(3):822–844, 2011
work page 2011
-
[4]
James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. Algorithms for hyper- parameter optimization.Advances in neural information processing systems, 24, 2011
work page 2011
-
[5]
Anastasia Borovykh, Sander Bohte, and Cornelis W Oosterlee. Conditional time series forecast- ing with convolutional neural networks.arXiv preprint arXiv:1703.04691, 2017
- [6]
-
[7]
Tcomp: Data from the 2010 tourism forecasting competition
Peter Ellis. Tcomp: Data from the 2010 tourism forecasting competition. https://cran. r-project.org/web/packages/Tcomp, 2018
work page 2010
-
[8]
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
work page 2022
-
[9]
Rakshitha Godahewa, Christoph Bergmeir, Geoffrey I. Webb, Rob J. Hyndman, and Pablo Montero-Manso. Monash time series forecasting archive. InNeural Information Processing Systems Track on Datasets and Benchmarks, 2021
work page 2021
-
[10]
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org
work page 2016
-
[11]
Charles C. Holt. Forecasting seasonals and trends by exponentially weighted moving averages. International Journal of Forecasting, 20(1):5–10, 2004
work page 2004
-
[12]
Hyndman.Forecasting with exponential smoothing: the state space approach
R.J. Hyndman.Forecasting with exponential smoothing: the state space approach. Springer, 2008
work page 2008
-
[13]
Rob J. Hyndman. expsmooth: Data sets from forecasting with exponential smoothing. https: //cran.r-project.org/web/packages/expsmooth, 2015. R package
work page 2015
-
[14]
Hyndman and George Athanasopoulos.Forecasting: Principles and Practice
Rob J. Hyndman and George Athanasopoulos.Forecasting: Principles and Practice. OTexts, Melbourne, Australia, 3rd edition, 2021. URLhttps://otexts.com/fpp3/
work page 2021
-
[15]
Rob J Hyndman and Anne B Koehler. Another look at measures of forecast accuracy.Interna- tional journal of forecasting, 22(4):679–688, 2006
work page 2006
-
[16]
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. Adaptive mixtures of local experts.Neural Computation, 3(1):79–87, 1991. doi: 10.1162/neco.1991.3.1. 79
-
[17]
James M. Kilts Center. Dominick’s dataset. https://www.chicagobooth.edu/research/ kilts/datasets/dominicks, 2020
work page 2020
-
[18]
Michael I. Jordan and Robert A. Jacobs. Hierarchical mixtures of experts and the EM algorithm. Neural Computation, 6(2):181–214, 1994. doi: 10.1162/neco.1994.6.2.181
-
[19]
GShard: Scaling giant models with condi- tional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. GShard: Scaling giant models with condi- tional computation and automatic sharding. InInternational Conference on Learning Represen- tations (ICLR), 2021. 9
work page 2021
-
[20]
BASE layers: Simplifying training of large, sparse models
Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer. BASE layers: Simplifying training of large, sparse models. InProceedings of the 38th International Conference on Machine Learning (ICML), volume 139 ofProceedings of Machine Learning Research, pages 6265–6274. PMLR, 2021
work page 2021
-
[21]
Moirai-MoE: Empowering time series foundation models with sparse mixture of experts, 2024
Chenghao Liu, Taha Aksu, Juncheng Liu, Xu Liu, Hanshu Yan, Quang Pham, Silvio Savarese, Doyen Sahoo, Caiming Xiong, and Junnan Li. Moirai-MoE: Empowering time series foundation models with sparse mixture of experts, 2024. URLhttps://arxiv.org/abs/2410.10469
-
[22]
Alysha M. De Livera, Rob J. Hyndman, and Ralph D. Snyder. Forecasting time series with complex seasonal patterns using exponential smoothing.Journal of the American Statistical Association, 106(496):1513–1527, 2011. doi: 10.1198/jasa.2011.tm09771
-
[23]
Btissame El Mahtout and Florian Ziel. Electricity price forecasting: Bridging linear models, neural networks and online learning.arXiv preprint arXiv:2601.02856, 2026
-
[24]
Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. The m4 competition: Results, findings, conclusion and way forward.International Journal of forecasting, 34(4): 802–808, 2018
work page 2018
-
[25]
Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. The m4 competition: 100,000 time series and 61 forecasting methods.International Journal of Forecasting, 36(1): 54–74, 2020
work page 2020
-
[26]
AI McLeod and Hyukjun Gweon. Optimal deseasonalization for monthly and daily geophysical time series.Journal of Environmental statistics, 4(11):1–11, 2013
work page 2013
-
[27]
Mixture-of-linear-experts for long-term time series forecasting
Ronghao Ni, Zinan Lin, Shuaiqi Wang, and Giulia Fanti. Mixture-of-linear-experts for long-term time series forecasting. InProceedings of the 27th International Conference on Artificial Intelli- gence and Statistics (AISTATS), volume 238 ofProceedings of Machine Learning Research, pages 4672–4680. PMLR, 2024
work page 2024
-
[28]
arXiv preprint arXiv:1905.10437 (2019)
Boris N Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-beats: Neural basis expansion analysis for interpretable time series forecasting.arXiv preprint arXiv:1905.10437, 2019
-
[29]
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin. Catboost: unbiased boosting with categorical features.Advances in neural information processing systems, 31, 2018
work page 2018
-
[30]
David Salinas, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. Deepar: Probabilistic forecasting with autoregressive recurrent networks.International journal of forecasting, 36(3): 1181–1191, 2020
work page 2020
-
[31]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations (ICLR), 2017
work page 2017
-
[32]
Time-MoE: Billion-scale time series foundation models with mixture of experts
Xiaoming Shi, Shiyu Wang, Yuqi Nie, Dianqi Li, Zhou Ye, Qingsong Wen, and Ming Jin. Time-MoE: Billion-scale time series foundation models with mixture of experts. InInterna- tional Conference on Learning Representations (ICLR), 2025. Spotlight presentation; preprint arXiv:2409.16040
-
[33]
Juan R Trapero, Nikolaos Kourentzes, and Robert Fildes. On the identification of sales forecast- ing models in the presence of promotions.Journal of the operational Research Society, 66(2): 299–307, 2015
work page 2015
-
[34]
Electricityloaddiagrams2011–2014 data set
UCI Machine Learning Repository. Electricityloaddiagrams2011–2014 data set. https: //archive.ics.uci.edu/dataset/321/electricityloaddiagrams20112014, 2020
work page 2014
-
[35]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 10
work page 2017
-
[36]
Kyrylo Yemets, Ivan Izonin, Mariia Zimokha, and Michal Gregus. Load-balancing strategies for forecasting with mixture-of-experts architecture.Procedia Computer Science, 2025. https: //www.sciencedirect.com/science/article/pii/S1877050925035380
work page 2025
-
[37]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 11106–11115,
-
[38]
doi: 10.1609/aaai.v35i12.17325
-
[39]
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M. Dai, Quoc V . Le, James Laudon, and Zhifeng Chen. Mixture-of-experts with expert choice routing. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, 2022
work page 2022
-
[40]
Taming sparsely activated transformer with stochastic experts
Simiao Zuo, Xiaodong Liu, Jian Jiao, Young Jin Kim, Hany Hassan, Ruofei Zhang, Tuo Zhao, and Jianfeng Gao. Taming sparsely activated transformer with stochastic experts. In International Conference on Learning Representations (ICLR), 2022. 11 Appendices A Tables 13 B Forecast Study 14 12 A Tables Table 3: Median MASE values of the benchmark models and the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.