Recognition: no theorem link
RW-Post: Auditable Evidence-Grounded Multimodal Fact-Checking in the Wild
Pith reviewed 2026-05-13 03:02 UTC · model grok-4.3
The pith
RW-Post supplies a benchmark of real social-media posts with auditable links to evidence items and reasoning traces extracted from human fact-check articles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
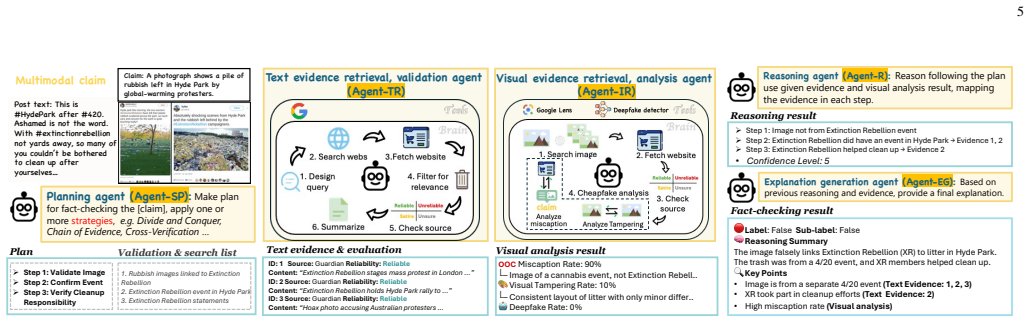
RW-Post is a post-aligned text-image benchmark that supplies auditable annotations linking each social-media post to reasoning traces and explicitly matched evidence items taken from human fact-check articles via an LLM-assisted extraction-and-auditing pipeline. The dataset supports controlled evaluation in closed-book, evidence-bounded, and open-web regimes. When strong open-source LVLMs are tested under unified protocols with AgentFact as baseline, they exhibit substantial difficulty with faithful evidence grounding; performance and faithfulness both rise when evaluation is restricted to the provided evidence.
What carries the argument
RW-Post benchmark: a collection of social-media posts paired with auditable, post-aligned annotations that extract reasoning traces and evidence items from human fact-check articles using an LLM-assisted pipeline.
Load-bearing premise
The LLM-assisted extraction-and-auditing pipeline produces accurate, unbiased annotations that faithfully link social-media posts to reasoning traces and evidence items from human fact-check articles.
What would settle it
Independent human review of a random sample of RW-Post instances that finds more than 15 percent of the extracted evidence links or reasoning steps disagree with the original fact-check articles.
Figures





read the original abstract
Multimodal misinformation increasingly leverages visual persuasion, where repurposed or manipulated images strengthen misleading text. We introduce \textbf{RW-Post}, a post-aligned \textbf{text--image benchmark} for real-world multimodal fact-checking with \emph{auditable} annotations: each instance links the original social-media post with reasoning traces and explicitly linked evidence items derived from human fact-check articles via an LLM-assisted extraction-and-auditing pipeline. RW-Post supports controlled evaluation across closed-book, evidence-bounded, and open-web regimes, enabling systematic diagnosis of visual grounding and evidence utilization. We provide \textbf{AgentFact} as a reference verification baseline and benchmark strong open-source LVLMs under unified protocols. Experiments show substantial headroom: current models struggle with faithful evidence grounding, while evidence-bounded evaluation improves both accuracy and faithfulness. Code and dataset will be released at https://github.com/xudanni0927/AgentFact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RW-Post, a post-aligned text-image benchmark for real-world multimodal fact-checking. Each instance links original social-media posts to reasoning traces and explicitly linked evidence items extracted from human fact-check articles via an LLM-assisted extraction-and-auditing pipeline. The work provides AgentFact as a reference verification baseline, evaluates strong open-source LVLMs under unified protocols across closed-book, evidence-bounded, and open-web regimes, and reports that current models struggle with faithful evidence grounding while evidence-bounded evaluation improves both accuracy and faithfulness. Code and dataset release is promised.
Significance. If the benchmark instances are reliable, the work supplies a needed resource for controlled diagnosis of visual grounding and evidence utilization in multimodal models. The three-regime evaluation design and promise of public release could support reproducible progress on evidence-grounded fact-checking.
major comments (2)
- [Abstract] Abstract: The central empirical claims (models struggle with faithful grounding; evidence-bounded regimes improve accuracy and faithfulness) rest entirely on the fidelity of the LLM-assisted extraction-and-auditing pipeline that produces the RW-Post instances. No quantitative validation, inter-annotator agreement, human auditing protocol, or error analysis of the extracted links is mentioned, yet any systematic misalignment in those links would invalidate the controlled comparison across regimes and the reported headroom.
- [Abstract] Abstract: The abstract asserts that 'experiments demonstrate model struggles and improvements' but supplies no information on the metrics for accuracy and faithfulness, the data splits, the number of instances, the LVLMs tested, or any error analysis. Without these details the support for the headline result cannot be assessed.
minor comments (1)
- [Abstract] The abstract states that code and dataset 'will be released' at a GitHub URL; confirming that the release actually contains the full annotation pipeline, raw fact-check articles, and auditing logs would strengthen the auditable claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claims (models struggle with faithful grounding; evidence-bounded regimes improve accuracy and faithfulness) rest entirely on the fidelity of the LLM-assisted extraction-and-auditing pipeline that produces the RW-Post instances. No quantitative validation, inter-annotator agreement, human auditing protocol, or error analysis of the extracted links is mentioned, yet any systematic misalignment in those links would invalidate the controlled comparison across regimes and the reported headroom.
Authors: We agree that the abstract does not mention quantitative validation, inter-annotator agreement, or error analysis for the pipeline. This omission weakens the presentation of the central claims. We will revise the abstract to include a concise summary of the human auditing protocol, inter-annotator agreement scores, and error analysis performed during instance construction. These additions will better substantiate the reported improvements in accuracy and faithfulness under evidence-bounded regimes. revision: yes
-
Referee: [Abstract] Abstract: The abstract asserts that 'experiments demonstrate model struggles and improvements' but supplies no information on the metrics for accuracy and faithfulness, the data splits, the number of instances, the LVLMs tested, or any error analysis. Without these details the support for the headline result cannot be assessed.
Authors: We concur that the abstract lacks these essential experimental details, limiting assessment of the headline results. We will revise the abstract to specify the accuracy and faithfulness metrics, the total number of instances, the data splits used, the LVLMs evaluated, and a brief overview of the error analysis. This will provide necessary context while preserving the abstract's brevity. revision: yes
Circularity Check
No circularity: empirical benchmark creation without derivations or self-referential reductions
full rationale
The paper presents RW-Post as a new text-image benchmark built from social-media posts and human fact-check articles via an LLM-assisted extraction pipeline, then evaluates LVLMs and AgentFact under closed-book, evidence-bounded, and open-web regimes. No equations, parameter fitting, uniqueness theorems, or ansatzes appear in the provided text. The reported headroom (models struggle with faithful grounding; evidence-bounded regimes improve accuracy) consists of direct empirical measurements on the constructed instances rather than any quantity that reduces by construction to the pipeline outputs or prior self-citations. The work is therefore self-contained as standard benchmark creation and evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human fact-check articles provide reliable ground-truth evidence and reasoning traces
invented entities (2)
-
RW-Post benchmark
no independent evidence
-
AgentFact baseline
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.