Recognition: 2 theorem links
· Lean TheoremEquilibrium Residuals Expose Three Regimes of Matrix-Game Strategic Reasoning in Language Models
Pith reviewed 2026-05-12 04:47 UTC · model grok-4.3
The pith
Language models learn approximate Nash computation for matrix games through residual training but hit an output formatting bottleneck on larger instances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Procedurally generated anonymous matrix games separate three regimes of LLM behavior: semantic recall of named games, acquisition of approximate Nash computation via training on small instances, and a persistent output-formatting bottleneck that prevents reliable scaling. Supervised fine-tuning transfers from 2x2 and 3x3 to larger sizes, and the 2-Lipschitz property of the exploitability residual accounts for stable generalization under payoff shifts where exact solvers would break.
What carries the argument
The exploitability residual, the maximum gain an opponent can obtain by best-responding to the model's output strategy, which supplies a continuous training signal for approximate equilibrium finding.
If this is right
- Residual training transfers across game sizes and payoff shifts because the exploitability signal remains continuous.
- Procedural anonymous evaluation is required to measure genuine strategic reasoning instead of semantic recall.
- The output formatting step, not internal computation, is the primary limit on handling larger matrices.
- Models acquire generalizable approximate equilibrium finding that applies to embedded subgames within bigger instances.
Where Pith is reading between the lines
- Structured output mechanisms could bypass the formatting bottleneck and unlock higher performance on large games.
- Different regimes call for different fixes: prompting for recall, residual objectives for computation, and interface engineering for deployment.
- The continuity advantage may extend to other domains where exact solutions are brittle but approximate residuals are robust.
Load-bearing premise
Performance gains after training on 2x2 and 3x3 games reflect acquisition of approximate Nash computation rather than overfitting to matrix size, formatting conventions, or residual-specific artifacts.
What would settle it
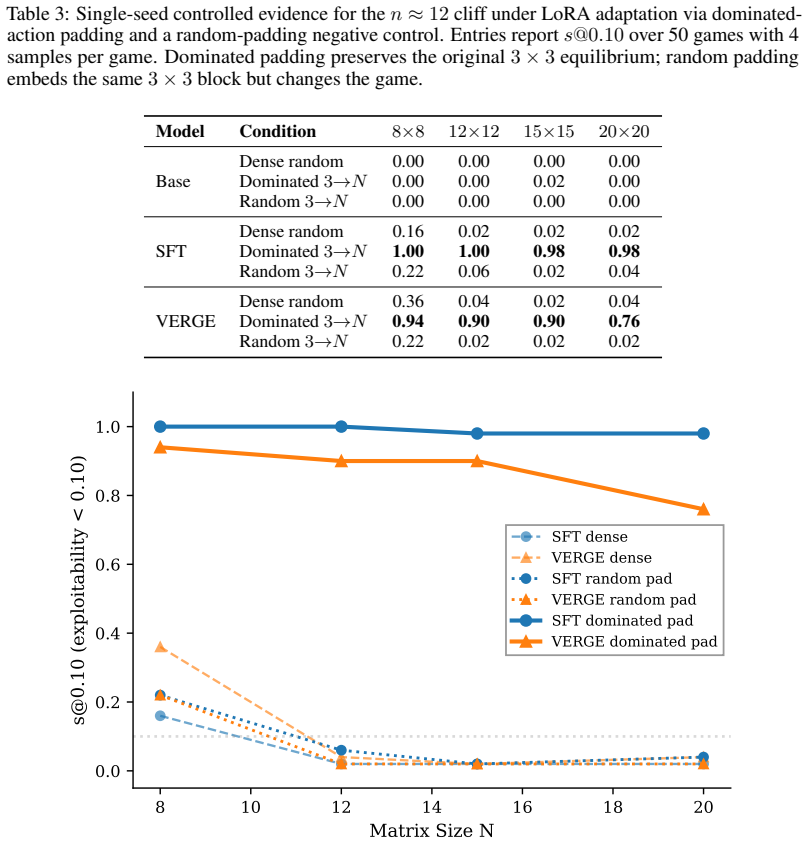
If models trained on small games fail to solve 3x3 subgames embedded via dominated-action padding inside larger matrices at rates clearly above random controls, or if small payoff perturbations cause large discontinuous drops in residual-trained output quality.
Figures

read the original abstract
Large language models can score well on named game-theory benchmarks while failing on the same strategic computation once semantic cues are removed. We show this gap with procedurally generated zero-sum matrix games: a model that recognizes familiar games drops to 34%, 18%, and 2% success on anonymous $2{\times}2$, $3{\times}3$, and $5{\times}5$ payoff matrices. The benchmark separates semantic recall, learned approximate Nash computation, and an output-interface bottleneck that limits scale. Training only on $2{\times}2$ and $3{\times}3$ games, supervised fine-tuning raises unseen $5{\times}5$--$7{\times}7$ success from 2% to 61%, while exploitability-reward training averages 37% with high seed variance. We prove that the exploitability residual is $2$-Lipschitz in payoff perturbations, unlike discontinuous vertex-returning LP equilibrium selectors, explaining why residual training can transfer under payoff shifts even when formatting instability limits mean performance. A dominated-action padding experiment provides causal evidence: trained models solve $3{\times}3$ games embedded in much larger matrices, while random-padded controls fail and dense $12{\times}12$ games remain near failure. Procedural evaluation is therefore necessary for measuring strategic reasoning, and residual rewards expose a real but format-limited route to approximate equilibrium computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs succeed on named game-theory benchmarks but drop sharply (to 34%, 18%, 2%) on procedurally generated anonymous zero-sum matrix games of increasing size. Supervised fine-tuning on 2×2 and 3×3 games raises success on unseen 5×5–7×7 matrices from 2% to 61%, while exploitability-reward training reaches 37% (high seed variance). A 2-Lipschitz continuity proof for the exploitability residual (contrasted with discontinuous LP selectors) is offered to explain transfer under payoff shifts, and a dominated-action padding experiment is presented as causal evidence that models solve embedded 3×3 subgames in larger matrices while random-padded controls fail.
Significance. If the central claims hold, the work supplies both a concrete training route to approximate equilibrium computation in LLMs and a mathematical reason (Lipschitz continuity of the residual) why such training can generalize across payoff perturbations where vertex-based solvers cannot. The emphasis on procedural generation and the padding control also strengthens the case that semantic recall and formatting artifacts must be separated from genuine strategic reasoning.
major comments (2)
- [Dominated-action padding experiment] Dominated-action padding experiment (abstract and associated results section): trained models succeed on 3×3 games embedded in larger matrices while random-padded controls fail, yet both conditions employ the identical payoff-generation pipeline and output representation for probability vectors. This does not isolate acquisition of approximate Nash computation from consistent artifacts in matrix presentation or formatting conventions, which is load-bearing for the claim that performance gains reflect strategic reasoning rather than size- or format-specific adaptation.
- [Training results and exploitability-reward training] Exploitability-reward training results (abstract): the reported 37% average success on larger games is accompanied by high seed variance. Without additional ablations that vary output formatting independently of the residual objective or that compare against size-matched but non-strategic baselines, it remains possible that the observed transfer is driven by procedural regularities rather than equilibrium computation.
minor comments (2)
- The title refers to 'three regimes' of strategic reasoning, but the abstract does not delineate them explicitly; ensure the main text defines these regimes with clear operational criteria and supporting figures or tables.
- Report all success rates with standard errors, confidence intervals, or per-seed distributions to allow readers to assess reliability in light of the noted seed variance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, clarifying the role of the controls and theoretical results while noting where the manuscript will be revised for greater precision.
read point-by-point responses
-
Referee: Dominated-action padding experiment (abstract and associated results section): trained models succeed on 3×3 games embedded in larger matrices while random-padded controls fail, yet both conditions employ the identical payoff-generation pipeline and output representation for probability vectors. This does not isolate acquisition of approximate Nash computation from consistent artifacts in matrix presentation or formatting conventions, which is load-bearing for the claim that performance gains reflect strategic reasoning rather than size- or format-specific adaptation.
Authors: We appreciate the referee's point on potential confounds. The random-padded and dominated-action conditions are matched exactly on payoff generation, matrix dimensions, and output format. The sole systematic difference is the strategic structure: dominated-action padding embeds a 3×3 subgame whose Nash equilibrium can be computed from the training distribution, while random padding contains no such structure. Because models were trained exclusively on small anonymous games and succeed selectively on the former, the performance gap indicates transfer of approximate equilibrium computation to embedded subgames rather than format adaptation. We will revise the results section to state this matching and differential more explicitly. revision: partial
-
Referee: Exploitability-reward training results (abstract): the reported 37% average success on larger games is accompanied by high seed variance. Without additional ablations that vary output formatting independently of the residual objective or that compare against size-matched but non-strategic baselines, it remains possible that the observed transfer is driven by procedural regularities rather than equilibrium computation.
Authors: The high seed variance for exploitability-reward training is reported in the manuscript and reflects known instability of that objective. Supervised fine-tuning on the same small games yields stable gains to 61% on larger instances. The 2-Lipschitz continuity of the exploitability residual (contrasted with discontinuous LP selectors) supplies a theoretical reason why residual training transfers under payoff shifts. While we did not run separate ablations isolating output formatting or non-strategic baselines, the procedural anonymous generation already removes semantic cues. We will add a limitations paragraph acknowledging the variance and the value of such ablations for future work. revision: partial
Circularity Check
No significant circularity; mathematical proof and experiments remain independent of fitted inputs
full rationale
The paper's core derivation is a mathematical proof that the exploitability residual is 2-Lipschitz in payoff perturbations, presented as independent of the empirical training results on 2x2/3x3 games. No equation reduces the claimed transferability or generalization to quantities defined by the same fitted parameters or self-citations. The dominated-action padding experiment and procedural generation are described as providing causal evidence without reducing to renaming or ansatz smuggling. The derivation chain is self-contained against external benchmarks and does not invoke load-bearing self-citations or uniqueness theorems from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Existence of Nash equilibria in finite zero-sum matrix games
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We prove that the exploitability residual is 2-Lipschitz in payoff perturbations, unlike discontinuous vertex-returning LP equilibrium selectors
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Training only on 2×2 and 3×3 games, supervised fine-tuning raises unseen 5×5–7×7 success from 2% to 61%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shivam Garg and Dimitris Tsipras and Percy Liang and Gregory Valiant , title =. NeurIPS , year =
-
[2]
Hung Le and Yue Wang and Akhilesh Deepak Gotmare and Silvio Savarese and Steven Chu-Hong Hoi , title =. NeurIPS , year =
-
[3]
Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Xian Li and Sainbayar Sukhbaatar and Jing Xu and Jason Weston , title =. ICML , year =
-
[4]
Nash Learning from Human Feedback , booktitle =
R. Nash Learning from Human Feedback , booktitle =
-
[5]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Xiao Bi and Haowei Zhang and Mingchuan Zhang and Y.K. Li and Y. Wu and Daya Guo , title =. arXiv preprint arXiv:2402.03300 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2305.19165 , year=
Kanishk Gandhi and Dorsa Sadigh and Noah D. Goodman , title =. arXiv preprint arXiv:2305.19165 , year =
-
[7]
Jinhao Duan and Renming Zhang and James Diffenderfer and Bhavya Kailkhura and Lichao Sun and Elias Stengel-Eskin and Mohit Bansal and Tianlong Chen and Kaidi Xu , title =. NeurIPS , year =
-
[8]
Caoyun Fan and Jindou Chen and Yaohui Jin and Hao He , title =. AAAI , year =
-
[9]
arXiv preprint arXiv:2406.10574 , year =
Alonso Silva , title =. arXiv preprint arXiv:2406.10574 , year =
-
[10]
arXiv preprint arXiv:2410.10479 , year =
Haochuan Wang and Xiachong Feng and Lei Li and Zhanyue Qin and Dianbo Sui and Lingpeng Kong , title =. arXiv preprint arXiv:2410.10479 , year =
-
[11]
Cem Anil and Yuhuai Wu and Anders Andreassen and Aitor Lewkowycz and Vedant Misra and Vinay Ramasesh and Ambrose Slone and Guy Gur-Ari and Ethan Dyer and Behnam Neyshabur , title =. NeurIPS , year =
-
[12]
Zixiang Chen and Yihe Deng and Huizhuo Yuan and Kaixuan Ji and Quanquan Gu , title =. ICML , year =
-
[13]
A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning , booktitle =
Marc Lanctot and Vinicius Zambaldi and Audrunas Gruslys and Angeliki Lazaridou and Karl Tuyls and Julien P. A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning , booktitle =
-
[14]
Yue Wu and Zhiqing Sun and Huizhuo Yuan and Kaixuan Ji and Yiming Yang and Quanquan Gu , title =. NeurIPS , year =
-
[15]
arXiv preprint arXiv:2510.15414 , year =
Huining Yuan and Zelai Xu and Zheyue Tan and Xiangmin Yi and Mo Guang and Kaiwen Long and Haojia Hui and Boxun Li and Xinlei Chen and Bo Zhao and Xiao-Ping Zhang and Chao Yu and Yu Wang , title =. arXiv preprint arXiv:2510.15414 , year =
-
[16]
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Fei Xia and Ed Chi and Quoc V. Le and Denny Zhou , title =. NeurIPS , year =
-
[17]
Takeshi Kojima and Shixiang Shane Gu and Machel Reid and Yutaka Matsuo and Yusuke Iwasawa , title =. NeurIPS , year =
-
[18]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Maxwell Nye and Anders Johan Andreassen and Guy Gur-Ari and Henryk Michalewski and Jacob Austin and David Bieber and David Dohan and Aitor Lewkowycz and Maarten Bosma and David Luan and Charles Sutton and Augustus Odena , title =. arXiv preprint arXiv:2112.00114 , year =
work page internal anchor Pith review arXiv
-
[19]
Training Verifiers to Solve Math Word Problems
Karl Cobbe and Vineet Kosaraju and Mohammad Bavarian and Mark Chen and Heewoo Jun and Lukasz Kaiser and Matthias Plappert and Jerry Tworek and Jacob Hilton and Reiichiro Nakano and Christopher Hesse and John Schulman , title =. arXiv preprint arXiv:2110.14168 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Christiano and Jan Leike and Tom B
Paul F. Christiano and Jan Leike and Tom B. Brown and Miljan Martic and Shane Legg and Dario Amodei , title =. NeurIPS , year =
-
[21]
Eric Zelikman and Yuhuai Wu and Jesse Mu and Noah D. Goodman , title =. NeurIPS , year =
-
[22]
Anton Bakhtin and Noam Brown and Emily Dinan and Gabriele Farina and Colin Flaherty and Daniel Fried and Andrew Goff and Jonathan Gray and Hengyuan Hu and Athul Paul Jacob and others , title =. Science , year =
- [23]
-
[24]
Carlton E. Lemke and Joseph T. Howson Jr. , title =. Journal of the Society for Industrial and Applied Mathematics , year =
-
[25]
Algorithmic Game Theory , publisher =
Noam Nisan and Tim Roughgarden and. Algorithmic Game Theory , publisher =
-
[26]
Hunter Lightman and Vineet Kosaraju and Yuri Burda and Harrison Edwards and Bowen Baker and Teddy Lee and Jan Leike and John Schulman and Ilya Sutskever and Karl Cobbe , title =. arXiv preprint arXiv:2305.20050 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo and Dejian Yang and Haowei Zhang and Junxiao Song and Ruoyu Zhang and Runxin Xu and Qihao Zhu and Shirong Ma and Peiyi Wang and Xiao Bi and others , title =. arXiv preprint arXiv:2501.12948 , year =. 2501.12948 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.