Recognition: no theorem link
Aligning LLM Uncertainty with Human Disagreement in Subjectivity Analysis
Pith reviewed 2026-05-14 21:37 UTC · model grok-4.3
The pith
A two-phase framework lets LLMs express uncertainty that tracks human disagreement on subjective tasks while preserving prediction accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
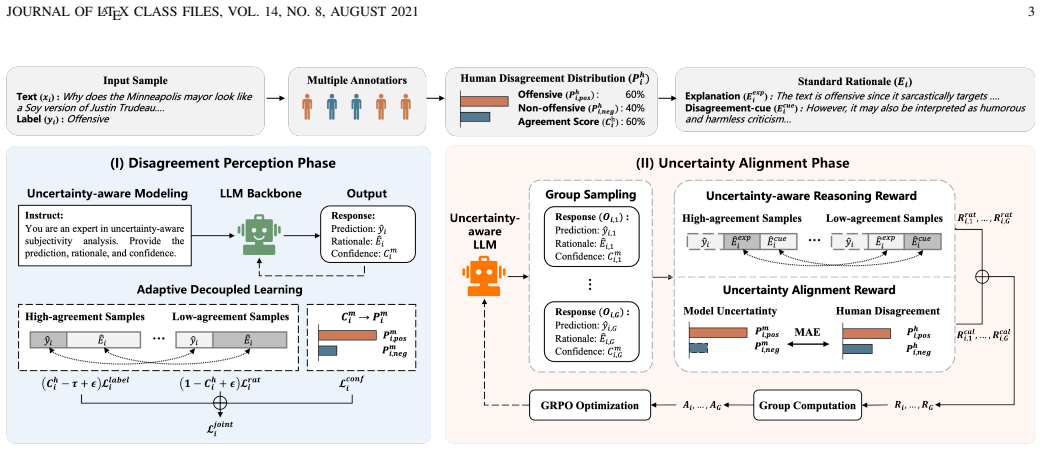
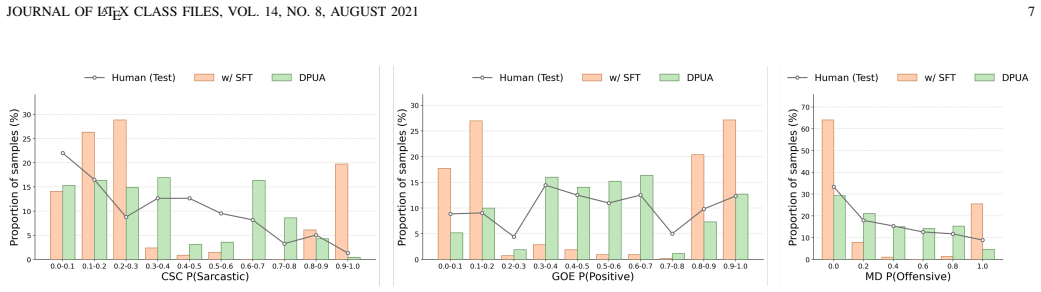
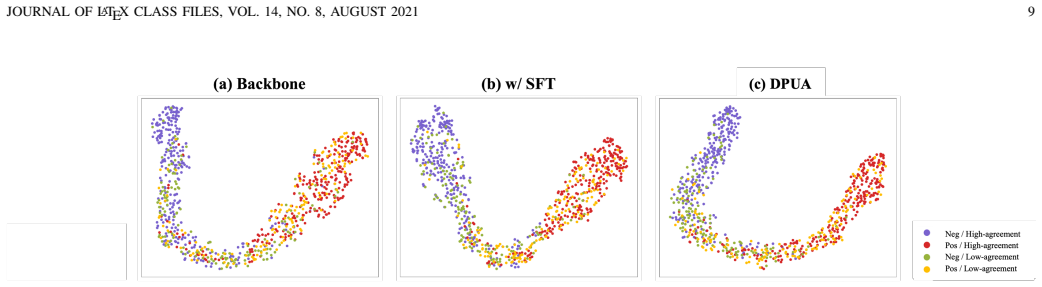
The DPUA framework operationalizes uncertainty-aware subjectivity analysis by jointly modeling label prediction, rationale generation, and uncertainty expression. In the disagreement perception phase, adaptive decoupled learning increases the model's sensitivity to disagreement-related cues while preserving task performance. In the uncertainty alignment phase, GRPO-based reward optimization improves uncertainty-aware reasoning and aligns the model's confidence expression with the human disagreement distribution. Experiments on three subjectivity analysis tasks confirm that the method preserves task performance, better matches model uncertainty to human disagreement, reduces overconfidence on
What carries the argument
The DPUA two-phase framework, where adaptive decoupled learning detects disagreement cues and GRPO-based reward optimization aligns expressed confidence to human disagreement distributions.
If this is right
- Task accuracy on standard subjectivity benchmarks stays comparable to conventional training.
- Model uncertainty scores show stronger correlation with observed human disagreement levels.
- Overconfident errors decrease on boundary cases where human labels vary.
- Out-of-distribution performance improves on subjective data drawn from different sources.
Where Pith is reading between the lines
- The same alignment technique could be tested on other ambiguous labeling settings such as preference data or multi-label annotation.
- If uncertainty better tracks human variation, downstream systems that route uncertain cases to humans would see fewer false confident predictions.
- Extending the reward signal to include rationale quality might further strengthen the connection between stated uncertainty and actual judgment spread.
Load-bearing premise
That GRPO-based reward optimization can reliably align the model's confidence expression with the human disagreement distribution without introducing new biases or degrading core task performance.
What would settle it
Running DPUA on a new set of subjectivity tasks and finding no reduction in overconfidence metrics or no improvement in correlation between model uncertainty scores and measured human disagreement rates.
Figures


read the original abstract
Large language models for subjectivity analysis are typically trained with aggregated labels, which compress variations in human judgment into a single supervision signal. This paradigm overlooks the intrinsic uncertainty of low-agreement samples and often induces overconfident predictions, undermining reliability and generalization in complex subjective settings. In this work, we advocate uncertainty-aware subjectivity analysis, where models are expected to make predictions while expressing uncertainty that reflects human disagreement. To operationalize this perspective, we propose a two-phase Disagreement Perception and Uncertainty Alignment (DPUA) framework. Specifically, DPUA jointly models label prediction, rationale generation, and uncertainty expression under an uncertainty-aware setting. In the disagreement perception phase, adaptive decoupled learning enhances the model's sensitivity to disagreement-related cues while preserving task performance. In the uncertainty alignment phase, GRPO-based reward optimization further improves uncertainty-aware reasoning and aligns the model's confidence expression with the human disagreement distribution. Experiments on three subjectivity analysis tasks show that DPUA preserves task performance while better aligning model uncertainty with human disagreement, mitigating overconfidence on boundary samples, and improving out-of-distribution generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a two-phase Disagreement Perception and Uncertainty Alignment (DPUA) framework for LLMs in subjectivity analysis. In the disagreement perception phase, adaptive decoupled learning improves sensitivity to disagreement cues while preserving task performance. In the uncertainty alignment phase, GRPO-based reward optimization aligns the model's confidence expression with the human disagreement distribution. Experiments on three subjectivity tasks claim that DPUA preserves performance, better aligns uncertainty with human disagreement, mitigates overconfidence on boundary samples, and improves OOD generalization.
Significance. If the empirical claims hold with proper verification, the work addresses an important limitation in LLM training for subjective tasks by treating human disagreement as a signal for uncertainty rather than noise. The two-phase design combining decoupled learning with RL-based alignment could inform more reliable systems in opinion mining, sentiment analysis, and other domains with inherent label variability.
major comments (3)
- [Uncertainty Alignment Phase] Uncertainty Alignment Phase: The description of GRPO-based reward optimization provides neither the explicit reward function nor a derivation showing that the policy gradient converges to the target per-instance human disagreement distribution rather than an average or correlated proxy. This directly affects verifiability of the claim that alignment mitigates overconfidence on boundary samples.
- [Experiments] Experiments: The manuscript supplies no quantitative metrics, baselines, or statistical tests for the asserted performance preservation and improved alignment, so the data-to-claim link cannot be evaluated from the presented evidence.
- [Method] Method: No ablation isolating the GRPO phase from the preceding adaptive decoupled learning stage is reported, leaving open whether observed alignment gains are attributable to the uncertainty alignment component or to earlier training choices.
minor comments (2)
- [Abstract] Abstract: Include at least one key quantitative result (e.g., alignment metric delta or accuracy delta) to support the high-level claims.
- [Notation] Notation: Define 'uncertainty expression' and 'human disagreement distribution' formally with equations to improve precision.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment point by point below and commit to revisions that improve verifiability and rigor without altering the core claims.
read point-by-point responses
-
Referee: [Uncertainty Alignment Phase] Uncertainty Alignment Phase: The description of GRPO-based reward optimization provides neither the explicit reward function nor a derivation showing that the policy gradient converges to the target per-instance human disagreement distribution rather than an average or correlated proxy. This directly affects verifiability of the claim that alignment mitigates overconfidence on boundary samples.
Authors: We acknowledge the need for greater mathematical detail. The reward function is the negative KL divergence between the model's per-instance uncertainty distribution (derived from rationale token probabilities) and the empirical human disagreement distribution. In the revision we will insert the explicit reward equation, the GRPO objective, and a short derivation showing that the gradient update targets the instance-level distribution (via per-sample normalization) rather than a global average. This will directly support the overconfidence mitigation claim on boundary samples. revision: yes
-
Referee: [Experiments] Experiments: The manuscript supplies no quantitative metrics, baselines, or statistical tests for the asserted performance preservation and improved alignment, so the data-to-claim link cannot be evaluated from the presented evidence.
Authors: Section 4 and the appendix already report accuracy, macro-F1, ECE, KL divergence to human distributions, and OOD accuracy, with comparisons to standard fine-tuning and uncertainty baselines. Paired t-tests appear in the appendix. To resolve the presentation concern we will move key tables into the main text, add two additional baselines, and explicitly state p-values for all alignment and performance claims. revision: partial
-
Referee: [Method] Method: No ablation isolating the GRPO phase from the preceding adaptive decoupled learning stage is reported, leaving open whether observed alignment gains are attributable to the uncertainty alignment component or to earlier training choices.
Authors: We agree that isolating the GRPO phase is necessary. The revised manuscript will include a new ablation table comparing (i) adaptive decoupled learning only and (ii) the full DPUA pipeline. The results will quantify the incremental improvement in alignment metrics and OOD generalization attributable to the GRPO stage while confirming that task performance remains comparable. revision: yes
Circularity Check
No load-bearing circularity; framework grounded in external labels
full rationale
The DPUA framework is presented as a two-phase process (adaptive decoupled learning followed by GRPO reward optimization) that references external human disagreement labels as independent grounding. No equations or derivations in the abstract or described method reduce the claimed alignment to a parameter fitted from the same data by construction, nor do they rely on self-citation chains or imported uniqueness theorems for the core result. The central claims are supported by experimental outcomes on three tasks rather than tautological redefinition of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large language models are zero-shot reasoners,
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large language models are zero-shot reasoners,” inAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and ...
work page 2022
-
[2]
[Online]. Available: http://papers.nips.cc/paper files/paper/2022/ hash/8bb0d291acd4acf06ef112099c16f326-Abstract-Conference.html
work page 2022
-
[3]
OpenAI, “GPT-4 technical report,”CoRR, vol. abs/2303.08774, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[4]
Palm: Scaling language modeling with pathways,
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y . Tay, N. Shazeer, V . Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev,...
-
[5]
Available: http://jmlr.org/papers/v24/22-1144.html
[Online]. Available: http://jmlr.org/papers/v24/22-1144.html
-
[6]
The best instruction-tuning data are those that fit,
D. Zhang, Q. Dai, and H. Peng, “The best instruction-tuning data are those that fit,”CoRR, vol. abs/2502.04194, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2502.04194
-
[7]
Is your model really A good math reasoner? evaluating mathematical reasoning with checklist,
Z. Zhou, S. Liu, M. Ning, W. Liu, J. Wang, D. F. Wong, X. Huang, Q. Wang, and K. Huang, “Is your model really A good math reasoner? evaluating mathematical reasoning with checklist,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. [Online]. Available: https://openreview....
work page 2025
-
[8]
Towards understanding factual knowledge of large language models,
X. Hu, J. Chen, X. Li, Y . Guo, L. Wen, P. S. Yu, and Z. Guo, “Towards understanding factual knowledge of large language models,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. [Online]. Available: https://openreview.net/forum?id=9OevMUdods
work page 2024
-
[9]
L. Aroyo, L. Dixon, N. Thain, O. Redfield, and R. Rosen, “Crowdsourcing subjective tasks: The case study of understanding JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11 toxicity in online discussions,” inCompanion of The 2019 World Wide Web Conference, WWW 2019, San Francisco, CA, USA, May 13-17, 2019, S. Amer-Yahia, M. Mahdian, A. Goel, G. ...
work page 2021
-
[10]
Available: https://doi.org/10.1145/3308560.3317083
[Online]. Available: https://doi.org/10.1145/3308560.3317083
-
[11]
Learning from disagreement: A survey,
A. Uma, T. Fornaciari, D. Hovy, S. Paun, B. Plank, and M. Poesio, “Learning from disagreement: A survey,”J. Artif. Intell. Res., vol. 72, pp. 1385–1470, 2021. [Online]. Available: https://doi.org/10.1613/jair. 1.12752
-
[12]
V . Basile, “It’s the end of the gold standard as we know it. on the impact of pre-aggregation on the evaluation of highly subjective tasks,” in Proceedings of the AIxIA 2020 Discussion Papers Workshop co-located with the the 19th International Conference of the Italian Association for Artificial Intelligence (AIxIA2020), Anywhere, November 27th, 2020, se...
work page 2020
-
[13]
We need to consider disagreement in evaluation,
V . Basile, M. Fell, T. Fornaciari, D. Hovy, S. Paun, B. Plank, M. Poesio, and A. Uma, “We need to consider disagreement in evaluation,” inProceedings of the 1st Workshop on Benchmarking: Past, Present and Future, K. Church, M. Liberman, and V . Kordoni, Eds. Online: Association for Computational Linguistics, Aug. 2021, pp. 15–21. [Online]. Available: htt...
work page 2021
-
[14]
SemEval-2021 task 12: Learning with disagreements,
A. Uma, T. Fornaciari, A. Dumitrache, T. Miller, J. Chamberlain, B. Plank, E. Simpson, and M. Poesio, “SemEval-2021 task 12: Learning with disagreements,” inProceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021). Online: Association for Computational Linguistics, Aug. 2021, pp. 338–347. [Online]. Available: https://aclantholo...
work page 2021
-
[15]
Semeval-2023 task 11: Learning with disagreements (lewidi),
E. Leonardelli, G. Abercrombie, D. Almanea, V . Basile, T. Fornaciari, B. Plank, V . Rieser, A. Uma, and M. Poesio, “Semeval-2023 task 11: Learning with disagreements (lewidi),” inProceedings of the The 17th International Workshop on Semantic Evaluation, SemEval@ACL 2023, Toronto, Canada, 13-14 July 2023, A. K. Ojha, A. S. Dogru ¨oz, G. D. S. Martino, H. ...
-
[16]
Dealing with disagreements: Looking beyond the majority vote in subjective annotations,
A. M. Davani, M. D ´ıaz, and V . Prabhakaran, “Dealing with disagreements: Looking beyond the majority vote in subjective annotations,”Trans. Assoc. Comput. Linguistics, vol. 10, pp. 92–110,
-
[17]
Zhang, Z., Zhao, J., Zhang, Q., Gui, T., and Huang, X
[Online]. Available: https://doi.org/10.1162/tacl a 00449
work page internal anchor Pith review doi:10.1162/tacl
-
[18]
J. Lu, K. Ma, K. Wang, K. Xiao, R. K. Lee, B. Xu, L. Yang, and H. Lin, “Is LLM an overconfident judge? unveiling the capabilities of llms in detecting offensive language with annotation disagreement,” inFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, ser. Findings of ACL, W. Che, J. Nabende, ...
work page 2025
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”CoRR, vol. abs/2402.03300, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[20]
Hatexplain: A benchmark dataset for explainable hate speech detection,
B. Mathew, P. Saha, S. M. Yimam, C. Biemann, P. Goyal, and A. Mukherjee, “Hatexplain: A benchmark dataset for explainable hate speech detection,” inThirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in A...
work page 2021
-
[21]
Automated hate speech detection and the problem of offensive language,
T. Davidson, D. Warmsley, M. W. Macy, and I. Weber, “Automated hate speech detection and the problem of offensive language,” inProceedings of the Eleventh International Conference on Web and Social Media, ICWSM 2017, Montr ´eal, Qu ´ebec, Canada, May 15-18, 2017. AAAI Press, 2017, pp. 512–515. [Online]. Available: https://aaai.org/ocs/index.php/ICWSM/ICWS...
work page 2017
-
[22]
B. Plank, “The “problem” of human label variation: On ground truth in data, modeling and evaluation,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Y . Goldberg, Z. Kozareva, and Y . Zhang, Eds. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, Dec. 2022, pp. 10 671–10 682. [Online]. Av...
work page 2022
-
[23]
Beyond black & white: Leveraging annotator disagreement via soft-label multi-task learning,
T. Fornaciari, A. Uma, S. Paun, B. Plank, D. Hovy, and M. Poesio, “Beyond black & white: Leveraging annotator disagreement via soft-label multi-task learning,” inProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, K. Toutano...
-
[24]
Which examples should be multiply annotated? active learning when annotators may disagree,
C. Baumler, A. Sotnikova, and H. D. III, “Which examples should be multiply annotated? active learning when annotators may disagree,” inFindings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, ser. Findings of ACL, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Association for Computational Linguistics, 20...
-
[25]
T. C. Weerasooriya, A. Ororbia, R. Bhensadadia, A. KhudaBukhsh, and C. Homan, “Disagreement matters: Preserving label diversity by jointly modeling item and annotator label distributions with DisCo,” inFindings of the Association for Computational Linguistics: ACL
- [26]
-
[27]
Learning subjective label distributions via sociocultural descriptors,
M. F. Parappan and R. Henao, “Learning subjective label distributions via sociocultural descriptors,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Association for Computational Linguistics, 2025, pp...
-
[28]
A survey of uncertainty estimation in llms: Theory meets practice,
H. Huang, Y . Yang, Z. Zhang, S. Lee, and Y . Wu, “A survey of uncertainty estimation in llms: Theory meets practice,”CoRR, vol. abs/2410.15326, 2024. [Online]. Available: https://doi.org/10.48550/ arXiv.2410.15326
-
[29]
O. Shorinwa, Z. Mei, J. Lidard, A. Z. Ren, and A. Majumdar, “A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions,”ACM Comput. Surv., vol. 58, no. 3, pp. 63:1–63:38, 2026. [Online]. Available: https://doi.org/10.1145/3744238
-
[30]
Z. Xu, T. Song, and Y . Lee, “Confronting verbalized uncertainty: Understanding how llm’s verbalized uncertainty influences users in ai-assisted decision-making,”Int. J. Hum. Comput. Stud., vol. 197, p. 103455, 2025. [Online]. Available: https://doi.org/10.1016/j.ijhcs.2025. 103455
-
[31]
Teaching models to express their uncertainty in words,
S. Lin, J. Hilton, and O. Evans, “Teaching models to express their uncertainty in words,”Trans. Mach. Learn. Res., vol. 2022, 2022. [Online]. Available: https://openreview.net/forum?id=8s8K2UZGTZ
work page 2022
-
[32]
TokUR: Token-Level Uncertainty Estimation for Large Language Model Reasoning
T. Zhang, H. Shi, Y . Wang, H. Wang, X. He, Z. Li, H. Chen, L. Han, K. Xu, H. Zhang, D. Metaxas, and H. Wang, “Tokur: Token-level uncertainty estimation for large language model reasoning,” 2026. [Online]. Available: https://arxiv.org/abs/2505.11737
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Fact-checking the output of large language models via token-level uncertainty quantification,
E. Fadeeva, A. Rubashevskii, A. Shelmanov, S. Petrakov, H. Li, H. Mubarak, E. Tsymbalov, G. Kuzmin, A. Panchenko, T. Baldwin, P. Nakov, and M. Panov, “Fact-checking the output of large language models via token-level uncertainty quantification,” inFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, A...
-
[34]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=1PL1NIMMrw
work page 2023
-
[35]
Quantifying uncertainty in answers from any language model and enhancing their trustworthiness,
J. Chen and J. Mueller, “Quantifying uncertainty in answers from any language model and enhancing their trustworthiness,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, L. Ku, A. Martins, and V . Srikumar, Eds. Association for Computational...
-
[36]
Calibrating large language models with sample consistency,
Q. Lyu, K. Shridhar, C. Malaviya, L. Zhang, Y . Elazar, N. Tandon, M. Apidianaki, M. Sachan, and C. Callison-Burch, “Calibrating large language models with sample consistency,” inThirty-Ninth AAAI Conference on Artificial Intelligence, Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence, Fifteenth Symposium JOURNAL OF LATEX CLA...
-
[37]
Why don’t you do it right? analysing annotators’ disagreement in subjective tasks,
M. Sandri, E. Leonardelli, S. Tonelli, and E. Jezek, “Why don’t you do it right? analysing annotators’ disagreement in subjective tasks,” inProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2023, Dubrovnik, Croatia, May 2-6, 2023, A. Vlachos and I. Augenstein, Eds. Association for Computation...
-
[38]
You are what you annotate: Towards better models through annotator representations,
N. Deng, X. F. Zhang, S. Liu, W. Wu, L. Wang, and R. Mihalcea, “You are what you annotate: Towards better models through annotator representations,” inFindings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6- 10, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023, pp. 12 475–12 ...
-
[39]
Generalizable sarcasm detection is just around the corner, of course!
H. Jang and D. Frassinelli, “Generalizable sarcasm detection is just around the corner, of course!” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024, K. Duh, H. G ´omez-Adorno, and S. Be...
-
[40]
G o E motions: A Dataset of Fine-Grained Emotions
D. Demszky, D. Movshovitz-Attias, J. Ko, A. S. Cowen, G. Nemade, and S. Ravi, “Goemotions: A dataset of fine-grained emotions,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, D. Jurafsky, J. Chai, N. Schluter, and J. R. Tetreault, Eds. Association for Computational Linguistics,...
-
[41]
Agreeing to disagree: Annotating offensive language datasets with annotators’ disagreement,
E. Leonardelli, S. Menini, A. P. Aprosio, M. Guerini, and S. Tonelli, “Agreeing to disagree: Annotating offensive language datasets with annotators’ disagreement,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, M. Moens, X. Huang, L....
-
[42]
Lewidi-2025 at nlperspectives: The third edition of the learning with disagreements shared task,
E. Leonardelli, S. Casola, S. Peng, G. Rizzi, V . Basile, E. Fersini, D. Frassinelli, H. Jang, M. Pavlovic, B. Plank, and M. Poesio, “Lewidi-2025 at nlperspectives: The third edition of the learning with disagreements shared task,”CoRR, vol. abs/2510.08460, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.08460
-
[43]
Eval- uating GPT-3 generated explanations for hateful content moderation,
H. Wang, M. S. Hee, M. R. Awal, K. T. W. Choo, and R. K. Lee, “Eval- uating GPT-3 generated explanations for hateful content moderation,” inProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI 2023, 19th-25th August 2023, Macao, SAR, China. ijcai.org, 2023, pp. 6255–6263
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.