Recognition: 2 theorem links
· Lean TheoremCoWorld-VLA: Thinking in a Multi-Expert World Model for Autonomous Driving
Pith reviewed 2026-05-12 03:44 UTC · model grok-4.3
The pith
CoWorld-VLA extracts four expert tokens to condition a diffusion planner for improved autonomous driving planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
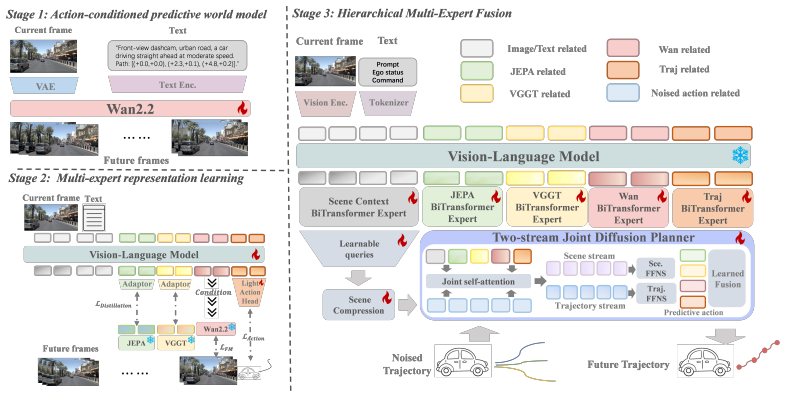
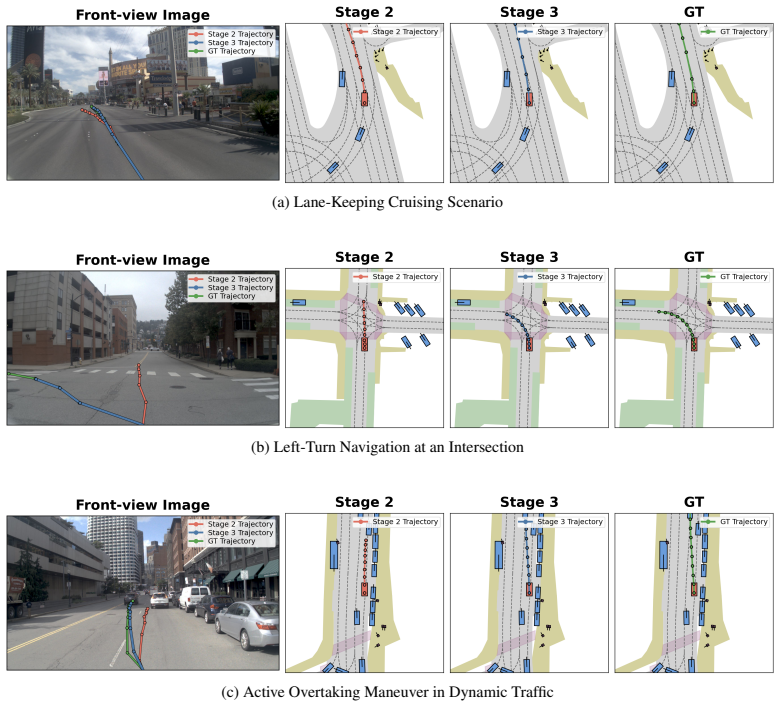
CoWorld-VLA builds a multi-expert world reasoning framework where semantic interaction, geometric structure, dynamic evolution, and ego trajectory tokens are extracted and used as explicit conditions in a diffusion-based hierarchical multi-expert fusion planner to generate continuous ego trajectories, resulting in competitive performance on future scene generation and planning tasks in the NAVSIM v1 benchmark.
What carries the argument
Four expert tokens (semantic interaction, geometric structure, dynamic evolution, ego trajectory) that provide planner-accessible conditioning signals in the joint denoising process of the diffusion planner.
Load-bearing premise
The four expert tokens remain complementary and non-conflicting when used together as conditioning signals in the diffusion planner's denoising process.
What would settle it
An experiment on the NAVSIM benchmark where the planning metrics do not improve or worsen when any expert token is removed would falsify the claim that they provide complementary value.
Figures





read the original abstract
Vision-Language-Action (VLA) models have emerged as a promising paradigm for end-to-end autonomous driving. However, existing reasoning mechanisms still struggle to provide planning-oriented intermediate representations: textual Chain-of-Thought (CoT) fails to preserve continuous spatiotemporal structure, while latent world reasoning remains difficult to use as a direct condition for action generation. In this paper, we propose CoWorld-VLA, a multi-expert world reasoning framework for autonomous driving, where world representations serve as explicit conditions to guide action planning. CoWorld-VLA extracts complementary world information through multi-source supervision and encodes it into expert tokens within the VLA, thereby providing planner-accessible conditioning signals. Specifically, we construct four types of tokens: semantic interaction, geometric structure, dynamic evolution, and ego trajectory tokens, which respectively model interaction intent, spatial structure, future temporal dynamics, and behavioral goals. During action generation, CoWorld-VLA employs a diffusion-based hierarchical multi-expert fusion planner, which is coupled with scene context throughout the joint denoising process to generate continuous ego trajectories. Experiments show that CoWorld-VLA achieves competitive results in both future scene generation and planning on the NAVSIM v1 benchmark, demonstrating strong performance in collision avoidance and trajectory accuracy. Ablation studies further validate the complementarity of expert tokens and their effectiveness as planning conditions for action generation. Code will be available at https://github.com/AFARI-Research/CoWorld-VLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoWorld-VLA, a multi-expert world reasoning framework for Vision-Language-Action models in autonomous driving. It extracts four complementary expert tokens (semantic interaction, geometric structure, dynamic evolution, and ego trajectory) via multi-source supervision to provide explicit conditioning signals for a diffusion-based hierarchical multi-expert fusion planner that generates continuous ego trajectories. The framework is evaluated on the NAVSIM v1 benchmark, with claims of competitive performance in future scene generation and planning (particularly collision avoidance and trajectory accuracy), supported by ablations validating token complementarity.
Significance. If the empirical results hold with proper validation, this approach could meaningfully advance end-to-end autonomous driving by supplying planner-accessible, continuous world representations that address shortcomings of textual Chain-of-Thought and purely latent reasoning in VLA models. The multi-expert token design and joint denoising in the diffusion planner represent a structured way to fuse semantic, geometric, dynamic, and behavioral information.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The manuscript asserts 'competitive results' and 'strong performance in collision avoidance and trajectory accuracy' on NAVSIM v1, yet provides no quantitative metrics, baseline comparisons, error bars, data splits, or training procedure details. This absence leaves the central performance claims without visible supporting evidence and prevents assessment of whether the multi-expert conditioning actually delivers the claimed gains.
- [Ablation studies] Ablation studies (mentioned in Abstract): The claim that ablations validate 'complementarity of expert tokens and their effectiveness as planning conditions' is presented without any reported quantitative ablation results, such as performance drops when removing individual tokens or metrics showing non-conflicting fusion. This directly affects the load-bearing assumption that the four tokens remain complementary inside the joint denoising process.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., a specific NAVSIM score) to ground the 'competitive' claim.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback emphasizing the need for explicit quantitative support. We will revise the manuscript to incorporate the requested metrics, comparisons, and ablation results, thereby strengthening the empirical claims.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The manuscript asserts 'competitive results' and 'strong performance in collision avoidance and trajectory accuracy' on NAVSIM v1, yet provides no quantitative metrics, baseline comparisons, error bars, data splits, or training procedure details. This absence leaves the central performance claims without visible supporting evidence and prevents assessment of whether the multi-expert conditioning actually delivers the claimed gains.
Authors: We agree that the abstract and experiments summary in the submitted version present high-level claims without accompanying numerical details. The full manuscript contains experimental tables on NAVSIM v1, but to address this concern directly we will expand the Experiments section with explicit quantitative metrics (collision rates, trajectory accuracy), baseline comparisons, error bars from repeated runs, data splits, and training hyperparameters. This revision will make the performance gains attributable to multi-expert conditioning transparent and verifiable. revision: yes
-
Referee: [Ablation studies] Ablation studies (mentioned in Abstract): The claim that ablations validate 'complementarity of expert tokens and their effectiveness as planning conditions' is presented without any reported quantitative ablation results, such as performance drops when removing individual tokens or metrics showing non-conflicting fusion. This directly affects the load-bearing assumption that the four tokens remain complementary inside the joint denoising process.
Authors: We acknowledge that the current manuscript mentions ablation studies only at a high level without quantitative results. We will add a dedicated ablation subsection containing tables that report performance drops upon removal of each expert token, metrics quantifying fusion quality, and evidence that the four tokens remain complementary during joint denoising. These additions will substantiate the claim that the tokens provide non-redundant conditioning signals. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmark evaluation
full rationale
The paper's central claims concern competitive performance on the external NAVSIM v1 benchmark for scene generation and planning, with ablations validating token complementarity. No equations, fitted parameters, or self-citations are shown to reduce the reported metrics or planning outputs to quantities defined by the model's own inputs by construction. The multi-expert token extraction and diffusion planner follow standard conditioning practices without self-referential loops or imported uniqueness theorems from the authors' prior work.
Axiom & Free-Parameter Ledger
free parameters (2)
- Expert token embedding dimensions and fusion parameters
- Diffusion scheduler and conditioning strength hyperparameters
axioms (2)
- domain assumption Multi-source supervision extracts non-redundant world information across semantic, geometric, dynamic, and behavioral axes
- domain assumption A diffusion process can be stably conditioned on scene context and expert tokens to produce collision-free trajectories
invented entities (4)
-
Semantic interaction token
no independent evidence
-
Geometric structure token
no independent evidence
-
Dynamic evolution token
no independent evidence
-
Ego trajectory token
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearCoWorld-VLA extracts complementary world information through multi-source supervision and encodes it into expert tokens... diffusion-based hierarchical multi-expert fusion planner... joint denoising process
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearfour types of tokens: semantic interaction, geometric structure, dynamic evolution, and ego trajectory tokens
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.