Recognition: 2 theorem links
· Lean TheoremVEGA: Visual Encoder Grounding Alignment for Spatially-Aware Vision-Language-Action Models
Pith reviewed 2026-05-12 05:03 UTC · model grok-4.3
The pith
VEGA aligns VLA visual encoders directly with 3D features before language mixing to improve spatial reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
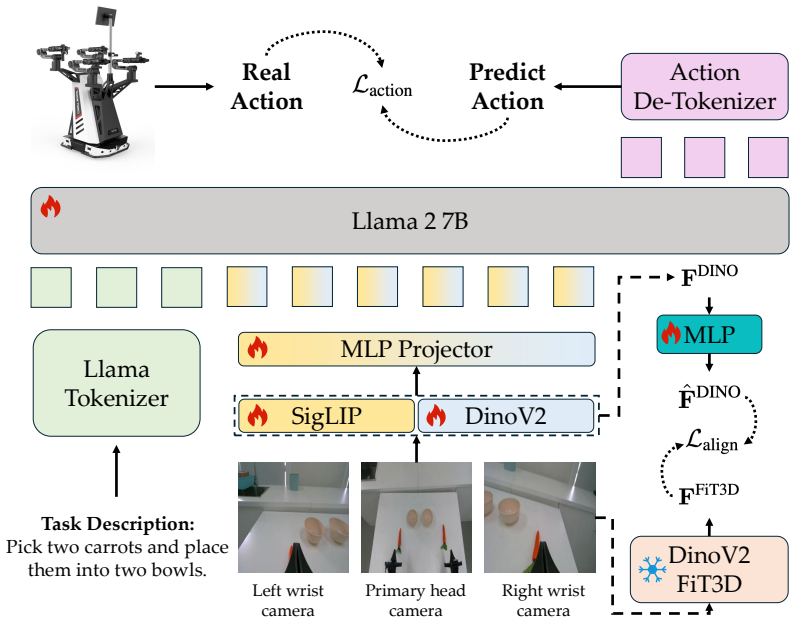
VEGA is a framework that directly aligns the output of the VLA's visual encoder with spatially-aware features from DINOv2-FiT3D, a DINOv2 model fine-tuned with multi-view consistent 3D Gaussian Splatting supervision. The alignment uses a lightweight projector trained with cosine similarity loss alongside the standard action prediction objective and is discarded at inference time. By performing this alignment at the visual encoder level before linguistic entanglement, VEGA provides a more interpretable and principled spatial target than existing implicit methods that operate on LLM-level tokens. Extensive experiments on simulation benchmarks and real-world manipulation tasks show that VEGA is
What carries the argument
A lightweight projector trained with cosine similarity loss to map VLA visual encoder outputs to DINOv2-FiT3D features before language model processing.
Load-bearing premise
That aligning visual encoder outputs directly with DINOv2-FiT3D features grounds spatial awareness before linguistic entanglement in a way that improves downstream action prediction more effectively than prior LLM-level alignments.
What would settle it
A head-to-head experiment on the same VLA backbone where VEGA-aligned models show no improvement or lower success rates than LLM-level alignment baselines on spatial manipulation benchmarks would falsify the claimed advantage.
Figures

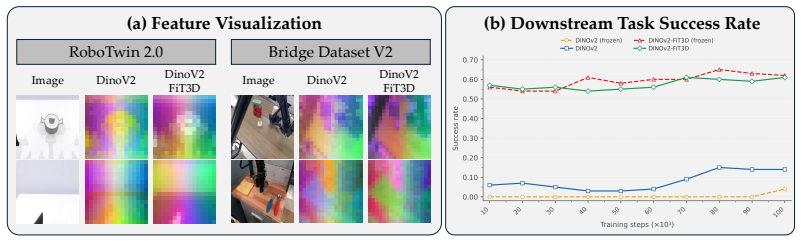



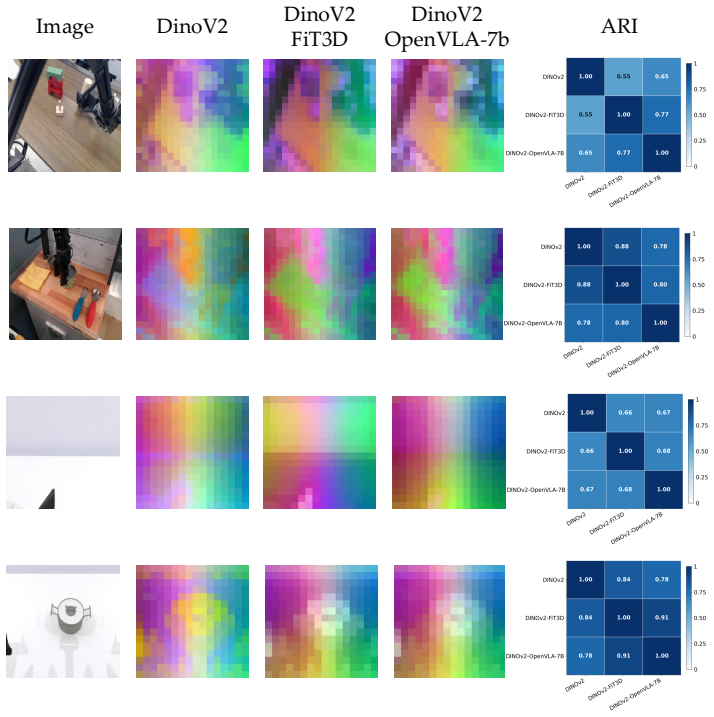



read the original abstract
Precise spatial reasoning is fundamental to robotic manipulation, yet the visual backbones of current vision-language-action (VLA) models are predominantly pretrained on 2D image data without explicit 3D geometric supervision, resulting in representations that lack accurate spatial awareness. Existing implicit spatial grounding methods partially address this by aligning VLA features with those of 3D-aware foundation models, but they rely on empirical layer search and perform alignment on LLM-level visual tokens where spatial structure has already been entangled with linguistic semantics, limiting both generalizability and geometric interpretability. We propose VEGA (Visual Encoder Grounding Alignment), a simple yet effective framework that directly aligns the output of the VLA's visual encoder with spatially-aware features from DINOv2-FiT3D, a DINOv2 model fine-tuned with multi-view consistent 3D Gaussian Splatting supervision. By performing alignment at the visual encoder output level, VEGA grounds spatial awareness before any linguistic entanglement occurs, offering a more interpretable and principled alignment target. The alignment is implemented via a lightweight projector trained with a cosine similarity loss alongside the standard action prediction objective, and is discarded at inference time, introducing no additional computational overhead. Extensive experiments on simulation benchmark and real-world manipulation tasks demonstrate that VEGA consistently outperforms existing implicit spatial grounding baselines, establishing a new state-of-the-art among implicit spatial grounding methods for VLA models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VEGA, a framework that directly aligns the output of a VLA model's visual encoder with spatially-aware features from DINOv2-FiT3D (a DINOv2 variant fine-tuned via multi-view 3D Gaussian Splatting) using a cosine similarity loss on a lightweight projector, trained jointly with the standard action prediction objective. Alignment occurs before linguistic tokens are formed to avoid entanglement with semantics; the projector is discarded at inference with no added cost. The paper claims this yields more interpretable spatial grounding than prior LLM-level implicit alignment methods and reports consistent outperformance on simulation benchmarks and real-world manipulation tasks, establishing a new SOTA among implicit spatial grounding approaches for VLA models.
Significance. If the superiority holds under rigorous controls, VEGA offers a lightweight, inference-free way to inject explicit 3D geometric supervision into VLA visual backbones, which could meaningfully advance spatial reasoning for robotic manipulation. The choice of a 3D-supervised target and the emphasis on pre-entanglement alignment are conceptually clean; the absence of inference overhead is a practical strength.
major comments (3)
- [Abstract] Abstract: the claim of 'consistent outperformance' and 'new state-of-the-art' among implicit spatial grounding methods is presented without any mention of statistical significance, error bars, data splits, or exact baseline implementations, rendering the central empirical claim unverifiable from the provided information.
- [Method] Method section (alignment procedure): the paper asserts that performing alignment at the visual-encoder output (before linguistic entanglement) is the decisive factor for improved spatial awareness, yet no ablation applies the identical DINOv2-FiT3D target and cosine-similarity loss at the LLM visual-token stage. Without this matched control, performance gains cannot be attributed specifically to the timing of alignment rather than to the quality of the 3D-supervised features or the projector acting as a regularizer.
- [Experiments] Experiments section: the absence of an ablation isolating the pre-entanglement property (as opposed to the specific target or training setup) is load-bearing for the main contribution, because the skeptic's concern that gains may arise from non-timing factors is not addressed by the reported comparisons.
minor comments (2)
- [Method] Clarify the precise architecture of the lightweight projector (number of layers, hidden dimension) and whether it is frozen or jointly optimized with the visual encoder.
- [Experiments] Ensure all tables reporting quantitative results include standard deviations or confidence intervals and specify the number of random seeds or trials.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We have revised the manuscript to improve the verifiability of our empirical claims and to provide additional justification for the design choices regarding alignment timing. Our point-by-point responses to the major comments are provided below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent outperformance' and 'new state-of-the-art' among implicit spatial grounding methods is presented without any mention of statistical significance, error bars, data splits, or exact baseline implementations, rendering the central empirical claim unverifiable from the provided information.
Authors: We agree that the original abstract lacked sufficient context for the empirical claims. In the revised manuscript, we have updated the abstract to reference the evaluation protocol (results averaged over multiple seeds with standard deviations reported in the main text) and direct readers to the experiments section for data splits and baseline details. Error bars have been added to all relevant figures, and we now report statistical significance where applicable. revision: yes
-
Referee: [Method] Method section (alignment procedure): the paper asserts that performing alignment at the visual-encoder output (before linguistic entanglement) is the decisive factor for improved spatial awareness, yet no ablation applies the identical DINOv2-FiT3D target and cosine-similarity loss at the LLM visual-token stage. Without this matched control, performance gains cannot be attributed specifically to the timing of alignment rather than to the quality of the 3D-supervised features or the projector acting as a regularizer.
Authors: This is a valid concern regarding attribution. We have expanded the method section in the revision with a new discussion clarifying the conceptual motivation for pre-entanglement alignment (preserving spatial structure prior to semantic mixing) and explaining why a post-tokenization application of the identical target would not serve as a clean control due to intervening language model layers. We compare against existing post-entanglement baselines and acknowledge that a perfectly matched new ablation would require substantial additional compute; this is noted as a limitation and direction for future work. revision: partial
-
Referee: [Experiments] Experiments section: the absence of an ablation isolating the pre-entanglement property (as opposed to the specific target or training setup) is load-bearing for the main contribution, because the skeptic's concern that gains may arise from non-timing factors is not addressed by the reported comparisons.
Authors: We recognize that stronger isolation of the timing effect would bolster the core contribution. The revised experiments section now includes additional feature analysis (e.g., spatial similarity metrics at encoder vs. token stages) and visualizations to demonstrate that geometric information is better retained before linguistic entanglement. We have also clarified how the reported baselines function as controls for post-entanglement methods, while discussing potential confounding factors. A fully isolated ablation with identical target and setup is computationally demanding and is flagged for future investigation. revision: partial
Circularity Check
No circularity in the alignment training procedure
full rationale
The paper proposes VEGA as a training framework that adds a cosine similarity loss between the VLA visual encoder outputs and external DINOv2-FiT3D features, optimized jointly with the standard action prediction objective. This is a conventional multi-task loss setup with no self-referential definitions, no fitted parameters renamed as predictions, and no load-bearing self-citations that collapse the central claim. The timing of alignment (pre-linguistic entanglement) is an explicit design choice justified by the method description and empirical results on benchmarks, not by construction from the inputs. The derivation chain is self-contained as an empirical method proposal.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Cosine similarity loss is suitable for aligning visual feature representations from different models
- domain assumption DINOv2 fine-tuned with multi-view consistent 3D Gaussian Splatting supervision yields spatially-aware features superior for grounding
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearBy performing alignment at the visual encoder output level, VEGA grounds spatial awareness before any linguistic entanglement occurs, offering a more interpretable and principled alignment target. The alignment is implemented via a lightweight projector trained with a cosine similarity loss
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearVEGA consistently outperforms existing implicit spatial grounding baselines
Reference graph
Works this paper leans on
-
[1]
Vineet Bhat, Yu-Hsiang Lan, Prashanth Krishnamurthy, Ramesh Karri, and Farshad Khorrami. 3d cavla: Leveraging depth and 3d context to generalize vision language action models for unseen tasks.arXiv preprint arXiv:2505.05800, 2025
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
π0.5: A vision- language-action model with open-world generalization
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y Galliker, et al. π0.5: A vision- language-action model with open-world generalization. In9th Annual Conference on Robot Learning, 2025
work page 2025
-
[4]
π0: A vision-language-action flow model for general robot control, 2026
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
work page 2026
-
[5]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
work page 2024
-
[7]
Knowledge distillation with the reused teacher classifier
Defang Chen, Jian-Ping Mei, Hailin Zhang, Can Wang, Yan Feng, and Chun Chen. Knowledge distillation with the reused teacher classifier. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11933–11942, 2022
work page 2022
-
[8]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Pali-3 vision language models: Smaller, faster, stronger.arXiv preprint arXiv:2310.09199, 2023
Xi Chen, Xiao Wang, Lucas Beyer, Alexander Kolesnikov, Jialin Wu, Paul V oigtlaender, Basil Mustafa, Sebastian Goodman, Ibrahim Alabdulmohsin, Piotr Padlewski, et al. Pali-3 vision language models: Smaller, faster, stronger.arXiv preprint arXiv:2310.09199, 2023
-
[10]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[11]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023
work page 2023
-
[12]
Rvt: Robotic view transformer for 3d object manipulation
Ankit Goyal, Jie Xu, Yijie Guo, Valts Blukis, Yu-Wei Chao, and Dieter Fox. Rvt: Robotic view transformer for 3d object manipulation. InConference on Robot Learning, pages 694–710. PMLR, 2023
work page 2023
-
[13]
arXiv preprint arXiv:2512.09619 (2025)
Minghao Guo, Meng Cao, Jiachen Tao, Rongtao Xu, Yan Yan, Xiaodan Liang, Ivan Laptev, and Xiaojun Chang. Glad: Geometric latent distillation for vision-language-action models.arXiv preprint arXiv:2512.09619, 2025
-
[14]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. 10
work page 2022
-
[15]
arXiv preprint arXiv:2311.12871
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world. arXiv preprint arXiv:2311.12871, 2023
-
[16]
Xiaohu Huang, Jingjing Wu, Qunyi Xie, and Kai Han. Mllms need 3d-aware representation supervision for scene understanding.arXiv e-prints, pages arXiv–2506, 2025
work page 2025
-
[17]
What’s “up” with vision-language models? investigating their struggle with spatial reasoning
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’s “up” with vision-language models? investigating their struggle with spatial reasoning. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9161–9175, 2023
work page 2023
-
[18]
Prismatic vlms: Investigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[19]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
work page 2023
-
[20]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Oliver Kroemer, Scott Niekum, and George Konidaris. A review of robot learning for manip- ulation: Challenges, representations, and algorithms.Journal of machine learning research, 22(30):1–82, 2021
work page 2021
-
[23]
Christian Landsiedel, Verena Rieser, Matthew Walter, and Dirk Wollherr. A review of spatial reasoning and interaction for real-world robotics.Advanced Robotics, 31(5):222–242, 2017
work page 2017
-
[24]
Chengmeng Li, Junjie Wen, Yaxin Peng, Yan Peng, and Yichen Zhu. Pointvla: Injecting the 3d world into vision-language-action models.IEEE Robotics and Automation Letters, 11(3):2506–2513, 2026
work page 2026
-
[25]
Fuhao Li, Wenxuan Song, Han Zhao, Jingbo Wang, Pengxiang Ding, Donglin Wang, Long Zeng, and Haoang Li. Spatial forcing: Implicit spatial representation alignment for vision- language-action model.arXiv preprint arXiv:2510.12276, 2025
-
[26]
Tao Lin, Gen Li, Yilei Zhong, Yanwen Zou, Yuxin Du, Jiting Liu, Encheng Gu, and Bo Zhao. Evo-0: Vision-language-action model with implicit spatial understanding.arXiv preprint arXiv:2507.00416, 2025
-
[27]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[28]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
work page 2024
-
[31]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018. 11
work page 2018
-
[32]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
Perceiver-actor: A multi-task transformer for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
work page 2023
-
[34]
Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics
Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15768– 15780, 2025
work page 2025
-
[35]
Guoheng Sun, Tingting Du, Kaixi Feng, Chenxiang Luo, Xingguo Ding, Zheyu Shen, Ziyao Wang, Yexiao He, and Ang Li. Rocket: Residual-oriented multi-layer alignment for spatially- aware vision-language-action models.arXiv preprint arXiv:2602.17951, 2026
-
[36]
Geovla: Em- powering 3d representations in vision-language-action models,
Lin Sun, Bin Xie, Yingfei Liu, Hao Shi, Tiancai Wang, and Jiale Cao. Geovla: Empowering 3d representations in vision-language-action models.arXiv preprint arXiv:2508.09071, 2025
-
[37]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen- Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–1736. PMLR, 2023
work page 2023
-
[39]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
work page 2025
-
[40]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024
work page 2024
-
[41]
Depth anything v2.Advances in Neural Information Processing Systems, 37:21875– 21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Information Processing Systems, 37:21875– 21911, 2024
work page 2024
-
[42]
Scannet++: A high- fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high- fidelity dataset of 3d indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023
work page 2023
-
[43]
arXiv preprint arXiv:2406.10721 (2024)
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousavian, and Dieter Fox. Robopoint: A vision-language model for spatial affordance prediction for robotics.arXiv preprint arXiv:2406.10721, 2024
-
[44]
Improving 2d feature representations by 3d-aware fine-tuning
Yuanwen Yue, Anurag Das, Francis Engelmann, Siyu Tang, and Jan Eric Lenssen. Improving 2d feature representations by 3d-aware fine-tuning. InEuropean Conference on Computer Vision, pages 57–74. Springer, 2024
work page 2024
-
[45]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
work page 2023
-
[46]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631, 2024
work page internal anchor Pith review arXiv 2024
-
[47]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 12 A Additional Experimental Setup A.1 Pretraining Details For the controlled pretrain...
work page 2023
-
[48]
Close Laptop.The robot uses a single arm to close an open laptop screen. This task requires precise spatial perception to locate the screen and hinge, as well as smooth and controlled motion to avoid damaging the articulated structure during contact
-
[49]
Handover Cucumber.The robot grasps a cucumber from one plate and places it onto another using a single arm. This task requires accurate object localization and a smooth transfer trajectory to ensure stable grasping and precise placement without dropping the object
-
[50]
Pick Dual Carrots into Dual Bowls.Each arm simultaneously grasps a carrot and places it into the nearest corresponding bowl. This bimanual task requires synchronized motion planning and spatial reasoning to correctly associate each carrot with its target bowl, while executing two independent manipulation sequences in parallel without inter-arm interference
-
[51]
Pick Dual Flowers into Vase.Each arm independently grasps a flower and inserts it into its corresponding vase. This bimanual task requires coordinated motion planning and spatial reasoning, as the robot must simultaneously manage two independent manipulation sequences while avoiding inter-arm interference. B Additional Analysis B.1 Feature Representation ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.