Recognition: no theorem link
Acceptance Cards:A Four-Diagnostic Standard for Safe Fine-Tuning Defense Claims
Pith reviewed 2026-05-12 04:52 UTC · model grok-4.3
The pith
Safe fine-tuning defense claims require passing four specific diagnostics before a gap reduction counts as evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Acceptance Cards supplies an evaluation protocol, a documentation object, an executable audit package, and a claim-specific evidential standard that together require statistical reliability, fresh semantic generalization, mechanism alignment, and cross-task transfer before a gap reduction is accepted as proof of a safe fine-tuning defense; under this standard SafeLoRA fails the full-card pass on Gemma-2-2B-it.
What carries the argument
Acceptance Cards, the four-diagnostic protocol that verifies a defense's gap reduction is reliable, generalizes to fresh semantics, aligns with an identifiable mechanism, and transfers across tasks.
If this is right
- Gap reductions observed only on held-out sets cannot be treated as safety evidence until the four diagnostics are also satisfied.
- Mechanism alignment must be checked explicitly rather than inferred from performance alone.
- Any defense that incurs measurable accuracy loss on clean tasks while failing transfer will not receive a full-card pass.
- Audits that omit fresh-subject or cross-task checks leave open the possibility that observed safety is an artifact of the test distribution.
Where Pith is reading between the lines
- The protocol could be extended to other model families and defenses to produce comparable scores across the literature.
- If adopted, future papers would need to supply the additional data required for reliability, generalization, and transfer tests.
- The observed deployment-accuracy cost in near-miss cases suggests that stricter standards may trade off capability for documented safety.
Load-bearing premise
The four chosen diagnostics are the right and sufficient criteria for distinguishing genuine safe fine-tuning mechanisms from artifacts or noise.
What would settle it
A defense that fails at least one of the four diagnostics yet still produces verifiably lower unsafe behavior on new tasks and models, or a defense that passes all four yet still permits unsafe outputs in deployment.
Figures

read the original abstract
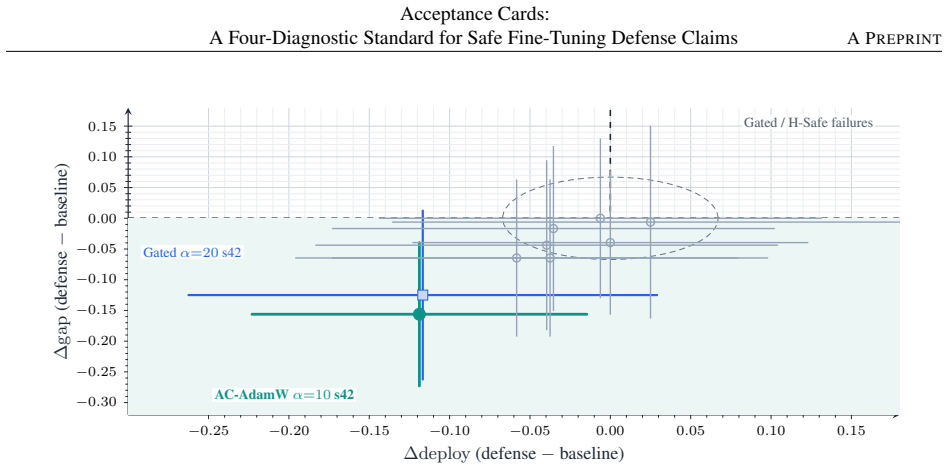
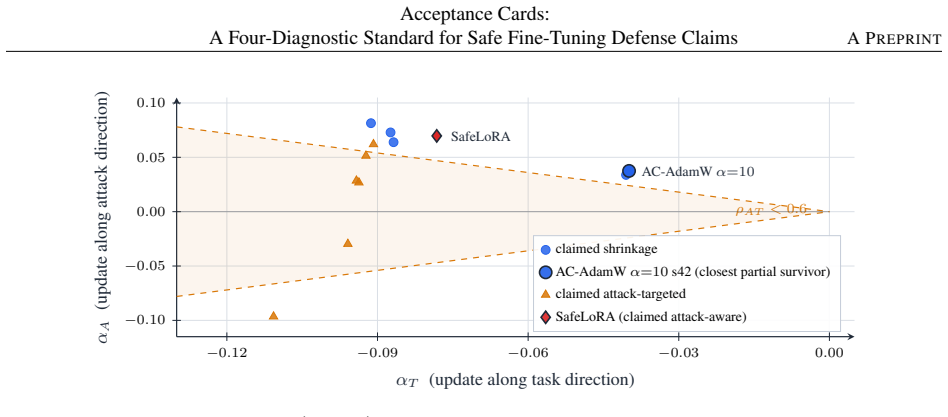
Safe fine-tuning defenses are often endorsed on the basis of a held-out gap reduction, but the same reduction can come from sampling noise, subject artifacts, capability loss, or a mechanism that does not transfer. We introduce Acceptance Cards: an evaluation protocol, a documentation object, an executable audit package, and a claim-specific evidential standard for safe fine-tuning defense claims. The protocol checks statistical reliability, fresh semantic generalization, mechanism alignment, and cross-task transfer before treating a gap reduction as a full-card pass. Re-scored under this installed-gap protocol, SafeLoRA fails the full-card pass on Gemma-2-2B-it: under strict mechanism-class coding it fails all four diagnostics, and under a permissive shrinkage relabel it still fails three of four. This is a narrow installed-gap audit on one model family, not a global judgment of SafeLoRA's effectiveness. In a 46-cell audit, no cell satisfies the strict conjunction. The closest family is a near miss that passes reliability and mechanism checks where the required data are available, but fails the fresh-subject threshold, lacks a strict transfer pass, and carries a measurable deployment-accuracy cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Acceptance Cards as a four-diagnostic protocol (statistical reliability, fresh semantic generalization, mechanism alignment, and cross-task transfer), along with a documentation object and executable audit package, to evaluate safe fine-tuning defense claims. It applies the protocol to SafeLoRA on Gemma-2-2B-it and reports failure to achieve a full-card pass in a 46-cell audit under both strict mechanism-class coding (fails all four) and permissive shrinkage relabeling (fails three of four), while explicitly scoping the result as narrow and limited to one model family rather than a global judgment.
Significance. If the protocol holds and is adopted, it could raise the evidentiary bar for safe fine-tuning claims by requiring evidence against noise, artifacts, capability loss, and non-transfer, moving beyond single held-out gap reductions. The executable audit package and narrow scoping are strengths that support verifiability and avoid overclaiming. The work's impact would depend on community uptake of these specific criteria as sufficient.
major comments (1)
- [Abstract] Abstract: the central empirical claim that SafeLoRA fails the strict conjunction (and still fails three of four under permissive relabeling) in a 46-cell audit is presented without raw data, statistical details, full audit tables, or per-cell results. This absence is load-bearing for independent verification of the failure on all four diagnostics and undermines the reported outcome.
minor comments (1)
- [Abstract] The abstract introduces the four diagnostics without brief inline definitions or examples; adding one-sentence characterizations would improve accessibility for readers encountering the protocol for the first time.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for emphasizing the need for transparent, verifiable evidence in claims about safe fine-tuning defenses. We address the single major comment below and outline a targeted revision to strengthen the manuscript's clarity and accessibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that SafeLoRA fails the strict conjunction (and still fails three of four under permissive relabeling) in a 46-cell audit is presented without raw data, statistical details, full audit tables, or per-cell results. This absence is load-bearing for independent verification of the failure on all four diagnostics and undermines the reported outcome.
Authors: We agree that the abstract, constrained by length, summarizes the outcome without embedding the raw per-cell results, full statistical breakdowns, or complete audit tables. The manuscript body (Section 4 and Appendix) contains the 46-cell audit design, per-diagnostic pass/fail counts under both strict and permissive codings, statistical reliability thresholds, and the executable audit package that reproduces all cells. To directly address the verifiability concern, we will revise the abstract to (1) explicitly state the audit scale (46 cells), (2) report the exact failure counts (0/46 strict; 3/4 permissive), and (3) add a concise pointer to the public audit package and supplementary tables. This change preserves the abstract's brevity while making the central claim easier to trace without requiring readers to reach the body first. No other sections require alteration for this point. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines Acceptance Cards as a new four-diagnostic protocol (statistical reliability, fresh semantic generalization, mechanism alignment, cross-task transfer) from first principles in the abstract, then applies the protocol to re-score SafeLoRA on Gemma-2-2B-it via a 46-cell audit. The failure claim is a direct application of the independently stated criteria to the audit data, with explicit scoping as narrow and not global. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes smuggled via citation appear in the central claim or derivation; the protocol does not reduce to its own evaluation inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Safe fine-tuning defenses are often endorsed on the basis of a held-out gap reduction, but the same reduction can come from sampling noise, subject artifacts, capability loss, or a mechanism that does not transfer.
invented entities (1)
-
Acceptance Cards
no independent evidence
Reference graph
Works this paper leans on
-
[1]
HarmBench: A standardized evaluation framework for automated red teaming and robust refusal,
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Li, D. Forsyth, and D. Hendrycks, “HarmBench: A standardized evaluation framework for automated red teaming and robust refusal,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 235. PMLR, 2024, p...
work page 2024
-
[2]
Holistic evaluation of language models,
P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y . Zhang, D. Narayanan, Y . Wu, A. Kumar et al., “Holistic evaluation of language models,”Transactions on Machine Learning Research, 2023. [Online]. Available: https://openreview.net/forum?id=iO4LZibEqW
work page 2023
-
[3]
The WMDP benchmark: Measuring and reducing malicious use with unlearning,
N. Li, A. Pan, A. Gopal, S. Yue, D. Berrios, A. Gatti, J. D. Li, A.-K. Dombrowski, S. Goel, G. Mukobiet al., “The WMDP benchmark: Measuring and reducing malicious use with unlearning,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 235. PMLR, 2024, pp. 28 525–28 550. [Online]. Av...
work page 2024
-
[4]
Fine-tuning aligned language models compromises safety, even when users do not intend to!
X. Qi, Y . Zeng, T. Xie, P.-Y . Chen, R. Jia, P. Mittal, and P. Henderson, “Fine-tuning aligned language models compromises safety, even when users do not intend to!” inInternational Conference on Learning Representations,
-
[5]
Available: https://openreview.net/forum?id=hTEGyKf0dZ
[Online]. Available: https://openreview.net/forum?id=hTEGyKf0dZ
-
[6]
Assessing the brittleness of safety alignment via pruning and low-rank modifications,
B. Wei, K. Huang, Y . Huang, T. Xie, X. Qi, M. Xia, P. Mittal, M. Wang, and P. Henderson, “Assessing the brittleness of safety alignment via pruning and low-rank modifications,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 235. PMLR, 2024, pp. 52 588–52 610. [Online]. Available...
work page 2024
-
[7]
Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack,
T. Huang, S. Hu, and L. Liu, “Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack,” inAdvances in Neural Information Processing Sys- tems, vol. 37, 2024. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2024/hash/ 873c86d9a979ab80d8e2919510d4446b-Abstract-Conference.html
work page 2024
-
[8]
Representation noising: A defence mechanism against harmful finetuning,
D. Rosati, J. Wehner, K. Williams,Ł. Bartoszcze, D. Atanasov, R. Gonzales, S. Majumdar, C. Maple, H. Sajjad, and F. Rudzicz, “Representation noising: A defence mechanism against harmful finetuning,” inAdvances in Neural Information Processing Systems, vol. 37, 2024. [Online]. Available: https://proceedings.neurips.cc/ paper files/paper/2024/hash/172be8b0b...
work page 2024
-
[9]
Model cards for model reporting
M. Mitchell, S. Wu, A. Zaldivar, P. Barnes, L. Vasserman, B. Hutchinson, E. Spitzer, I. D. Raji, and T. Gebru, “Model cards for model reporting,” inProceedings of the Conference on Fairness, Accountability, and Transparency (FAT*), 2019, pp. 220–229. [Online]. Available: https://doi.org/10.1145/3287560.3287596
-
[10]
Data cards: Purposeful and transparent dataset documentation for responsible AI
M. Pushkarna, A. Zaldivar, and O. Kjartansson, “Data cards: Purposeful and transparent dataset documentation for responsible AI,” inProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 2022, pp. 1776–1826. [Online]. Available: https://dl.acm.org/doi/10.1145/3531146.3533231
-
[11]
B. Efron and R. Tibshirani, “Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy,”Statistical Science, vol. 1, no. 1, pp. 54–75, 1986. [Online]. Available: https://doi.org/10.1214/ss/1177013815
-
[12]
Measuring massive multitask language understanding,
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https://iclr.cc/virtual/2021/poster/2962 9 Acceptance Cards: A Four-Diagnostic Standard for Safe Fine-Tuning Defense ClaimsA PREPRINT
work page 2021
-
[13]
AI sandbagging: Language models can strategically underperform on evaluations,
T. van der Weij, F. Hofst¨atter, O. Jaffe, S. F. Brown, and F. R. Ward, “AI sandbagging: Language models can strategically underperform on evaluations,” inInternational Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=7Qa2SpjxIS
work page 2025
-
[14]
Towards understanding sycophancy in language models,
M. Sharma, M. Tong, T. Korbak, D. Duvenaud, A. Askell, S. R. Bowman, E. Durmus, Z. Hatfield-Dodds, S. R. Johnston, S. M. Kravec, T. Maxwell, S. McCandlish, K. Ndousse, O. Rausch, N. Schiefer, D. Yan, M. Zhang, and E. Perez, “Towards understanding sycophancy in language models,” inInternational Conference on Learning Representations, 2024. [Online]. Availa...
work page 2024
-
[15]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=nZeVKeeFYf9
work page 2022
-
[16]
Safe LoRA: The silver lining of reducing safety risks when finetuning large language models,
C.-Y . Hsu, Y .-L. Tsai, C.-H. Lin, P.-Y . Chen, C.-M. Yu, and C.-Y . Huang, “Safe LoRA: The silver lining of reducing safety risks when finetuning large language models,” inAdvances in Neural Information Processing Systems, vol. 37, 2024. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2024/ hash/77baa7c2a3a675823e89131698fd6e19-Abs...
work page 2024
-
[17]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations, 2019. [Online]. Available: https://openreview.net/forum?id=Bkg6RiCqY7
work page 2019
-
[19]
Gemma 2: Improving Open Language Models at a Practical Size
[Online]. Available: https://arxiv.org/abs/2408.00118
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Are emergent abilities of large language models a mirage?
R. Schaeffer, B. Miranda, and S. Koyejo, “Are emergent abilities of large language models a mirage?” inAdvances in Neural Information Processing Systems, vol. 36, 2023. [Online]. Available: https: //papers.nips.cc/paper files/paper/2023/hash/adc98a266f45005c403b8311ca7e8bd7-Abstract-Conference.html
work page 2023
-
[21]
E. Miller, “Adding error bars to evals: A statistical approach to language model evaluations,”arXiv preprint arXiv:2411.00640, 2024. [Online]. Available: https://arxiv.org/abs/2411.00640
-
[22]
Qwen, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Weiet al., “Qwen2.5 technical report,”arXiv preprint arXiv:2412.15115, 2024. [Online]. Available: https://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yanget al., “The Llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, A. A. Awan, N. Bach, A. Bahree, A. Bakhtiari, J. Bao, H. Behlet al., “Phi-3 technical report: A highly capable language model locally on your phone,”arXiv preprint arXiv:2404.14219, 2024. [Online]. Available: https://arxiv.org/abs/2404.14219 A Acceptance Card A safe fine-tuning defense paper should fill in th...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.