Recognition: no theorem link
Measuring Embedding Sensitivity to Authorial Style in French: Comparing Literary Texts with Language Model Rewritings
Pith reviewed 2026-05-12 05:08 UTC · model grok-4.3
The pith
Embeddings capture French author style reliably and retain it after LLM rewriting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Embeddings reliably capture authorial stylistic features and these signals persist after rewriting, while also exhibiting LLM-specific patterns.
What carries the argument
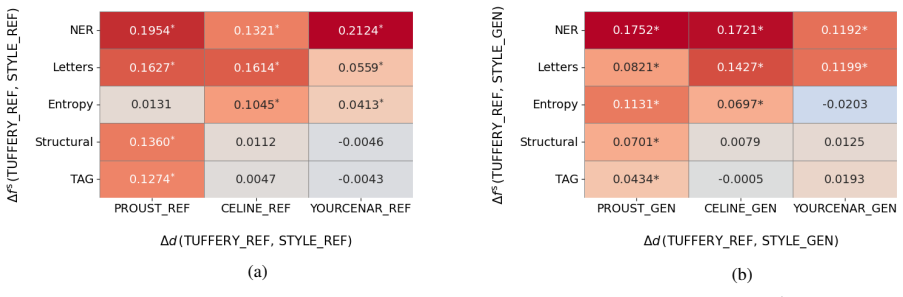
Changes in embedding dispersion as a quantitative measure of stylistic variation between original French literary texts and their LLM-rewritten versions.
If this is right
- Stylistic information in embeddings can support quantitative authorship attribution even in rewritten text.
- LLM rewriting does not fully erase original author signals in embedding space.
- Different language models produce distinct, measurable shifts in how author style appears in embeddings.
- The dispersion-based approach supplies a practical metric for studying style imitation by generative models.
Where Pith is reading between the lines
- The same dispersion method could be tested on non-literary or non-French texts to check whether style capture generalizes.
- If dispersion tracks style independently of topic and length, it could inform the design of style-transfer systems that intentionally preserve or modify author voice.
- Combining embedding dispersion with other signals such as syntactic patterns might strengthen detection of AI-assisted authorship imitation.
Load-bearing premise
Changes in embedding dispersion specifically and accurately quantify authorial stylistic variation rather than being driven by other factors such as text length, topic, or rewriting artifacts.
What would settle it
If dispersion changes correlate more strongly with text length, topic, or surface-level rewriting artifacts than with known differences between authors when those factors are controlled.
Figures





read the original abstract
Large language models (LLMs) can convincingly imitate human writing styles, yet it remains unclear how much stylistic information is encoded in embeddings from any language model and retained after LLM rewriting. We investigate these questions in French, using a controlled literary dataset to quantify the effect of stylistic variation via changes in embedding dispersion. We observe that embeddings reliably capture authorial stylistic features and that these signals persist after rewriting, while also exhibiting LLM-specific patterns. These analytical results offer promising directions for authorship imitation detection in the era of language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates how embeddings encode authorial style in French literary texts by quantifying stylistic variation through changes in embedding dispersion. It compares original texts against LLM-rewritten versions and reports that embeddings reliably capture authorial stylistic features, that these signals persist after rewriting, and that distinct patterns emerge across different LLMs. The results are framed as offering directions for detecting authorship imitation in the LLM era.
Significance. If the dispersion-based measurements prove robust, the work would provide a concrete empirical approach to assessing style encoding in embeddings for a non-English literary corpus and to evaluating how LLM rewriting preserves or alters stylistic signals. This could support stylometric methods and AI-text detection tools, particularly given the use of a controlled literary dataset. The absence of reported statistical details, model specifications, or confound controls in the abstract, however, prevents a full evaluation of whether the observations isolate authorial style.
major comments (2)
- [Abstract and Methods] Abstract and experimental setup: The central claim that embedding dispersion specifically indexes authorial stylistic features (and their persistence post-rewriting) is load-bearing, yet the description provides no indication of length normalization, topic matching across authors, or ablation of LLM-induced syntactic/semantic artifacts. Without these, observed shifts risk reflecting confounds rather than style, as noted in the stress-test concern.
- [Results] Results and interpretation: The observations that 'embeddings reliably capture authorial stylistic features' and 'signals persist after rewriting' are presented without data sizes, statistical methods, specific LLMs, error analysis, or quantitative effect sizes. This makes it impossible to verify support for the claims or to distinguish LLM-specific patterns from artifacts.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., dispersion delta values or statistical significance) to ground the stated observations.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help us clarify the methodological controls and quantitative reporting in our work. We respond to each major point below, drawing on details from the full manuscript, and note the revisions we will implement.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and experimental setup: The central claim that embedding dispersion specifically indexes authorial stylistic features (and their persistence post-rewriting) is load-bearing, yet the description provides no indication of length normalization, topic matching across authors, or ablation of LLM-induced syntactic/semantic artifacts. Without these, observed shifts risk reflecting confounds rather than style, as noted in the stress-test concern.
Authors: We agree the abstract is too concise to list these elements. The full Methods section specifies that texts were drawn from a controlled literary corpus with authors matched by genre and historical period to limit topical confounds, and that all samples were truncated to identical token lengths prior to embedding. A dedicated stress-test subsection compares dispersion shifts under LLM rewriting to those from random syntactic and lexical perturbations. We will revise the abstract to reference these controls explicitly. revision: yes
-
Referee: [Results] Results and interpretation: The observations that 'embeddings reliably capture authorial stylistic features' and 'signals persist after rewriting' are presented without data sizes, statistical methods, specific LLMs, error analysis, or quantitative effect sizes. This makes it impossible to verify support for the claims or to distinguish LLM-specific patterns from artifacts.
Authors: The Results section reports the corpus composition, applies statistical comparisons (including significance testing and effect-size metrics) to dispersion values, names the LLMs used for rewriting, and presents error analysis together with LLM-specific pattern quantification via comparative metrics and figures. We will add a compact summary of these elements to the abstract to improve verifiability. revision: yes
Circularity Check
No circularity: purely empirical measurements with no derivations or self-referential fits
full rationale
The paper reports direct empirical observations of embedding dispersion changes across original literary texts and LLM rewritings in French. No equations, parameter fittings, predictions derived from subsets of the same data, or load-bearing self-citations appear in the provided abstract or description. The central claims rest on controlled dataset comparisons rather than any reduction of results to inputs by construction, satisfying the criteria for a self-contained non-circular analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Exercices de Style: Edition Gallimard , author=. Collection Folio , year=
-
[2]
ACM Transactions on Intelligent Systems and Technology , volume=
Explainability for large language models: A survey , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2024 , publisher=
work page 2024
-
[3]
Glove: Global vectors for word representation , author=. Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) , pages=
work page 2014
-
[4]
Journal of machine Learning research , volume=
Latent dirichlet allocation , author=. Journal of machine Learning research , volume=
-
[5]
Characterizing stylistic elements in syntactic structure , author=. Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning , pages=
work page 2012
- [6]
-
[7]
Effective Purity Method for Measuring the Clustering Accuracy and its Illustration , volume =
Sikhakolli, Srinivasa and Sikhakolli, Asha Kiran , year =. Effective Purity Method for Measuring the Clustering Accuracy and its Illustration , volume =. International Journal of Computer Applications , doi =
-
[8]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. arXiv preprint arXiv:1810.04805 , url=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
Writing Style Author Embedding Evaluation , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=. 2021 , organization=
work page 2021
-
[10]
Authorship identification using ensemble learning , author=. Scientific reports , volume=. 2022 , publisher=
work page 2022
-
[11]
CLEF 2023 Working Notes , year=
A Writing Style Embedding Based on Contrastive Learning for Multi-Author Writing Style Analysis , author=. CLEF 2023 Working Notes , year=
work page 2023
-
[12]
Proceedings of the 7th Workshop on Representation Learning for NLP , pages=
Same Author or Just Same Topic? Towards Content-Independent Style Representations , author=. Proceedings of the 7th Workshop on Representation Learning for NLP , pages=. 2022 , organization=
work page 2022
-
[13]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
BERTopic: Neural topic modeling with a class-based TF-IDF procedure , author=. arXiv preprint arXiv:2203.05794 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Maharjan, Suraj and Mave, Deepthi and Shrestha, Prasha and Montes, Manuel and Gonz \'a lez, Fabio A. and Solorio, Thamar. Jointly Learning Author and Annotated Character N-gram Embeddings: A Case Study in Literary Text. Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019). 2019
work page 2019
-
[15]
Transactions of the Association for Computational Linguistics , volume=
Topic modeling in embedding spaces , author=. Transactions of the Association for Computational Linguistics , volume=. 2020 , publisher=
work page 2020
-
[16]
arXiv preprint arXiv:1909.08349 , year=
A lexical, syntactic, and semantic perspective for understanding style in text , author=. arXiv preprint arXiv:1909.08349 , year=
- [17]
-
[18]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[19]
Handbook of Empirical Literary Studies , pages=
Computational stylistics , author=. Handbook of Empirical Literary Studies , pages=. 2021 , url=
work page 2021
-
[20]
arXiv preprint arXiv:1905.05621 , year=
Style transformer: Unpaired text style transfer without disentangled latent representation , author=. arXiv preprint arXiv:1905.05621 , year=
-
[21]
Embeddings in natural language processing: Theory and advances in vector representations of meaning , author=. 2020 , publisher=
work page 2020
-
[22]
WWW (Companion volume) , pages=
Author2Vec: Learning Author Representations by Combining Content and Link Information , author=. WWW (Companion volume) , pages=
-
[23]
Nature Biotechnology , volume =
Initialization is critical for preserving global data structure in both t-SNE and UMAP , author =. Nature Biotechnology , volume =. 2021 , doi =
work page 2021
-
[24]
Journal of Open Source Software , volume =
UMAP: Uniform Manifold Approximation and Projection , author =. Journal of Open Source Software , volume =. 2018 , doi =
work page 2018
-
[25]
5th online world conference on soft computing in industrial applications (WSC5) , volume=
The curse of dimensionality , author=. 5th online world conference on soft computing in industrial applications (WSC5) , volume=
-
[26]
Similarity measures for text document clustering , author=. Proceedings of the sixth new zealand computer science research student conference (NZCSRSC2008), Christchurch, New Zealand , volume=
-
[27]
Universal sentence encoder , author=. arXiv preprint arXiv:1803.11175 , url=
-
[28]
International conference on machine learning , pages=
Distributed representations of sentences and documents , author=. International conference on machine learning , pages=. 2014 , url=
work page 2014
-
[29]
2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003
Robust data clustering , author=. 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003. Proceedings. , volume=. 2003 , organization=
work page 2003
-
[30]
International Journal of Future Computer and Communication , volume=
Clutching of Clustering Validation Criteria , author=. International Journal of Future Computer and Communication , volume=. 2024 , url=
work page 2024
-
[31]
Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability , volume=
Some methods for classification and analysis of multivariate observations , author=. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability , volume=
-
[32]
Principal component analysis , author=. Technometrics , volume=. 1987 , url=
work page 1987
-
[33]
Proceedings of the International Conference on Data Mining , year=
Purity: A new measure for clustering evaluation , author=. Proceedings of the International Conference on Data Mining , year=
-
[34]
Journal of Machine Learning Research , volume=
Relationship-based clustering and cluster ensembles , author=. Journal of Machine Learning Research , volume=
-
[35]
Simple and Effective Dimensionality Reduction for Word Embeddings , author=. 2017 , eprint=
work page 2017
-
[36]
Cross-validation methods in principal component analysis: A comparison , volume =
Diana, Giancarlo and Tommasi, Chiara , year =. Cross-validation methods in principal component analysis: A comparison , volume =. Statistical Methods & Applications , doi =
-
[37]
Statistical Methods & Applications , volume=
Cross-validation methods in principal component analysis: A comparison , author=. Statistical Methods & Applications , volume=. 2002 , publisher=
work page 2002
-
[38]
I. T. Jolliffe , title =. 2016 , publisher =
work page 2016
-
[39]
A Tutorial on Principal Component Analysis
J. Shlens , title =. arXiv preprint arXiv:1404.1100 , year =
- [40]
-
[41]
Fachada, J. and others , title =. Data Mining and Knowledge Discovery , year =
-
[42]
Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , pages=
Directed diversity: Leveraging language embedding distances for collective creativity in crowd ideation , author=. Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , pages=
work page 2021
-
[43]
Computer Science Review , volume=
Conceptual and empirical comparison of dimensionality reduction algorithms (pca, kpca, lda, mds, svd, lle, isomap, le, ica, t-sne) , author=. Computer Science Review , volume=. 2021 , publisher=
work page 2021
- [44]
- [45]
-
[46]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
2011 International Conference on Document Analysis and Recognition , pages=
Writer identification using TF-IDF for cursive handwritten word recognition , author=. 2011 International Conference on Document Analysis and Recognition , pages=. 2011 , url=
work page 2011
-
[49]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Self-attention attribution: Interpreting information interactions inside transformer , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[50]
Team liuc0757 at PAN: A Writing Style Embedding Method Based on Contrastive Learning for Multi-Author Writing Style Analysis , author=. Working Notes of CLEF , url=
-
[51]
European Conference on Information Retrieval , pages=
Overview of PAN 2024: multi-author writing style analysis, multilingual text detoxification, oppositional thinking analysis, and generative AI authorship verification , author=. European Conference on Information Retrieval , pages=. 2024 , organization=
work page 2024
-
[52]
Transactions of the Association for Computational Linguistics , volume=
Can Authorship Representation Learning Capture Stylistic Features? , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
work page 2023
-
[53]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
tBERT: Topic models and BERT joining forces for semantic similarity detection , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[54]
The statistical study of literary vocabulary , author=. 2014 , publisher=
work page 2014
-
[55]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
work page 1948
-
[56]
Derivation of new readability formulas (Automated readability index, fog count, and flesch reading ease formula) for Navy enlisted personnel , author=
- [57]
-
[58]
Journal of statistical mechanics: Theory and experiment , volume=
Comparing community structure identification , author=. Journal of statistical mechanics: Theory and experiment , volume=. 2005 , publisher=
work page 2005
-
[59]
Detection of changes in literary writing style using N-grams as style markers and supervised machine learning , author=. Plos one , volume=. 2022 , publisher=
work page 2022
-
[60]
2018 IEEE 5th International Conference on data science and advanced analytics (DSAA) , pages=
Explaining explanations: An overview of interpretability of machine learning , author=. 2018 IEEE 5th International Conference on data science and advanced analytics (DSAA) , pages=. 2018 , organization=
work page 2018
-
[61]
MTEB: Massive Text Embedding Benchmark
MTEB: Massive text embedding benchmark , author=. arXiv preprint arXiv:2210.07316 , year=
work page internal anchor Pith review arXiv
-
[62]
Faye, G. Exposing propaganda: an analysis of stylistic cues comparing human annotations and machine classification , booktitle =. 2024 , address =
work page 2024
-
[63]
A Multi-Label Dataset of French Fake News: Human and Machine Insights , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
work page 2024
-
[64]
Embedding Style Beyond Topics: Analyzing Dispersion Effects Across Different Language Models
Icard, Benjamin and Zve, Evangelia and Sainero, Lila and Breton, Alice and Ganascia, Jean-Gabriel. Embedding Style Beyond Topics: Analyzing Dispersion Effects Across Different Language Models. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[65]
A survey of ai-generated text forensic systems: Detection, attribution, and characterization , author=. arXiv preprint arXiv:2403.01152 , year=
-
[66]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=. 2017 , url=
work page 2017
-
[67]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
- [68]
-
[69]
À la recherche du temps perdu , volume =
Marcel Proust , title =. À la recherche du temps perdu , volume =. 1913 , publisher =
work page 1913
- [70]
- [71]
-
[72]
DOI: 10.1109/TVCG.2023.3326569 , year =
Large-Scale Evaluation of Topic Models and Dimensionality Reduction Methods for 2D Text Spatialization , author =. DOI: 10.1109/TVCG.2023.3326569 , year =
- [73]
-
[74]
2020 IEEE 7th international conference on data science and advanced analytics (DSAA) , pages=
Cluster quality analysis using silhouette score , author=. 2020 IEEE 7th international conference on data science and advanced analytics (DSAA) , pages=. 2020 , organization=
work page 2020
-
[75]
T iny S tyler: Efficient Few‑Shot Text Style Transfer with Authorship Embeddings
Horvitz, Zachary and Patel, Ajay and Singh, Kanishk and Callison‑Burch, Chris and McKeown, Kathleen and Yu, Zhou. T iny S tyler: Efficient Few‑Shot Text Style Transfer with Authorship Embeddings. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.781
-
[76]
RAG s to Style: Personalizing LLMs with Style Embeddings
Neelakanteswara, Abhiman and Chaudhari, Shreyas and Zamani, Hamed. RAG s to Style: Personalizing LLMs with Style Embeddings. Proceedings of the 1st Workshop on Personalization of Generative AI Systems (PERSONALIZE 2024). 2024
work page 2024
-
[77]
Style Extraction on Text Embeddings Using VAE and Parallel Dataset
Kong, InJin and Kang, Shinyee and Park, Yuna and Kim, Sooyong and Park, Sanghyun. Style Extraction on Text Embeddings Using VAE and Parallel Dataset. 2025
work page 2025
-
[78]
Robust AI-Generated Text Detection by Restricted Embeddings
Kuznetsov, Kristian and Tulchinskii, Eduard and Kushnareva, Laida and Magai, German and Barannikov, Serguei and Nikolenko, Sergey and Piontkovskaya, Irina. Robust AI-Generated Text Detection by Restricted Embeddings. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.992
-
[79]
Journal of the royal statistical society
Algorithm AS 136: A k-means clustering algorithm , author=. Journal of the royal statistical society. series c (applied statistics) , volume=. 1979 , url=
work page 1979
-
[80]
Language Resources and Evaluation , volume =
Moshe Koppel and Jonathan Schler and Shlomo Argamon , title =. Language Resources and Evaluation , volume =. 2011 , doi =
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.