Recognition: 2 theorem links
· Lean TheoremGridProbe: Posterior-Probing for Adaptive Test-Time Compute in Long-Video VLMs
Pith reviewed 2026-05-12 03:41 UTC · model grok-4.3
The pith
GridProbe selects long-video frames by probing a frozen VLM's own answer posteriors on a grid, cutting compute up to 3x with little accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
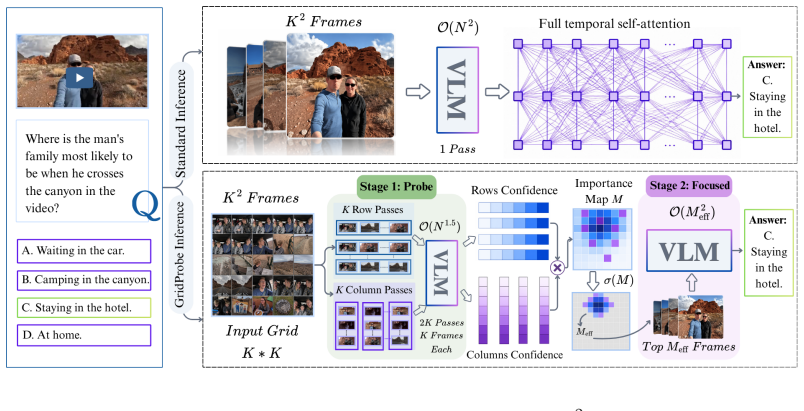
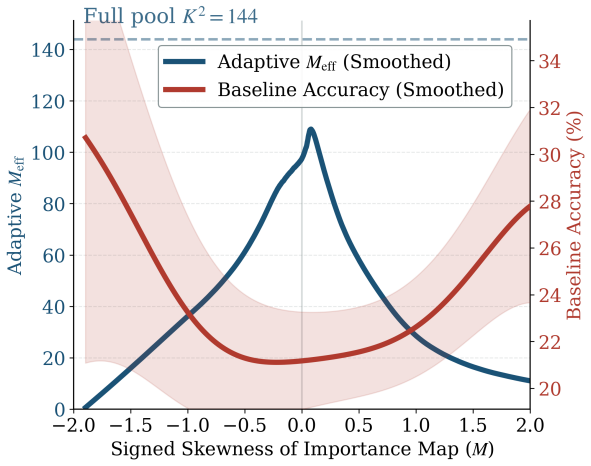
GridProbe arranges frames on a K×K grid and runs lightweight row and column probes on the frozen VLM, each reporting its peak posterior as query-conditioned confidence. The outer product of these posteriors produces an interpretable importance map. Shape-Adaptive Selection applies a closed-form rule based on the map's skewness and kurtosis to replace the fixed frame budget M with a per-question M_eff that tracks intrinsic difficulty without seeing the answer, delivering adaptive test-time compute.
What carries the argument
The importance map formed by the outer product of row and column peak posteriors, which drives Shape-Adaptive Selection to determine question-specific M_eff from skewness and kurtosis.
If this is right
- On Video-MME-v2 it matches the full-frame baseline within 1.6 pp average accuracy at 3.36× lower TFLOPs.
- On LongVideoBench it improves accuracy by 0.9 pp while using 0.35× the compute.
- A 2B selector paired with a 4B or 8B QA model outperforms the 2B monolithic baseline by up to 4.0 pp at 0.52× compute.
- The resulting importance maps support interpretability for diagnostics, grounding, and distillation without retraining.
Where Pith is reading between the lines
- The method shows that a VLM's internal posterior distribution can locate evidence even when its contrastive pretraining features cannot.
- Decoupling the selector from the QA model points to modular long-video systems that scale without joint retraining.
- The same grid-probe idea could be applied to streaming video or other modalities where evidence location needs to be inferred at test time.
Load-bearing premise
The peak posteriors from the lightweight row and column probes reliably mark which frames hold evidence for the question, including on reasoning-heavy queries where contrastive signals are weak.
What would settle it
A collection of reasoning queries on which the importance map concentrates on the wrong frames, producing accuracy below the monolithic baseline despite the claimed compute savings.
Figures



read the original abstract
Long-video understanding in VLMs is bottlenecked by a single monolithic forward pass over thousands of frames at quadratic attention cost. A common mitigation is to first select a small subset of informative frames before the forward pass; common for training-free selectors via auxiliary encoder-space similarities. Such signals are capped by contrastive pretraining, which usually fails on reasoning-heavy queries (negation, cross-frame counting, holistic summarization). We propose GridProbe, an efficient training-free posterior-probing inference paradigm that scores evidence in answer space using a frozen VLM's own reasoning and then selects question-relevant frames adaptively, resulting in sub-quadratic attention cost with little to no accuracy loss. We arrange frames on a $K{\times}K$ grid and run lightweight row R and column C probes, where each probe reads its peak posterior as a query-conditioned confidence. The outer product of R and C yields an interpretable importance map whose skewness and kurtosis drive Shape-Adaptive Selection, a closed-form rule that reliably replaces the fixed frame budget $M$ with a per-question $M_{\mathrm{eff}}$. We show empirically that $M_{\mathrm{eff}}$ tracks intrinsic question difficulty without ever seeing the answer, a sign of test-time adaptive compute. On Video-MME-v2, GridProbe matches the monolithic baseline within $1.6$ pp Avg Acc at $3.36\times$ TFLOPs reduction, while on LongVideoBench it Pareto-dominates the baseline ($+0.9$ pp at $0.35\times$ compute). Because the selector and QA models can be decoupled, pairing a small 2B selector with a stronger 4B or 8B QA is strictly Pareto-dominant over the 2B monolithic baseline (up to $+4.0$ pp at $0.52\times$ compute, on average), with no retraining. Finally, the interpretability of the importance maps opens future avenues for behavioral diagnostics, grounding, and frame-selection distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GridProbe, a training-free posterior-probing inference paradigm for long-video VLMs. Frames are arranged on a K×K grid; lightweight row R and column C probes extract peak posteriors as query-conditioned confidence scores from the frozen VLM; their outer product yields an interpretable importance map; skewness and kurtosis of this map drive a closed-form Shape-Adaptive Selection rule that replaces a fixed frame budget M with a per-question M_eff, achieving sub-quadratic attention cost. Empirical results show near-parity or better accuracy than monolithic baselines on Video-MME-v2 and LongVideoBench, with additional gains from decoupling small selector models from larger QA models.
Significance. If the localization assumption holds, the work delivers practical efficiency gains (3.36× TFLOPs reduction at 1.6 pp accuracy drop on Video-MME-v2; +0.9 pp at 0.35× compute on LongVideoBench) plus model-decoupling benefits without retraining and interpretable importance maps. These are load-bearing strengths for test-time adaptive compute in VLMs.
major comments (2)
- [Abstract / §3] Abstract and §3 (method): the headline gains (matching baseline within 1.6 pp at 3.36× TFLOPs on Video-MME-v2; Pareto dominance +0.9 pp at 0.35× on LongVideoBench) depend on the claim that peak posteriors from linear row/column probes reliably localize evidence for reasoning-heavy queries (negation, cross-frame counting, holistic summarization). Because each probe sees only a linear subset of frames, the outer-product map and subsequent Shape-Adaptive Selection can inherit partial or spurious signals; this assumption is central and requires explicit per-query-type validation or failure-case analysis to support the reported improvements.
- [§4] §4 (experiments): the Pareto claims and decoupling results (2B selector + 4B/8B QA) are presented without visible error bars, data-split details, or controls for post-hoc tuning/selection bias. This makes it impossible to verify that M_eff genuinely tracks intrinsic question difficulty rather than benchmark artifacts, directly affecting the soundness of the adaptive-compute conclusion.
minor comments (2)
- [Abstract] Abstract: the definition of M_eff and the role of skewness/kurtosis in the closed-form rule could be stated more explicitly to aid readers before the method section.
- [§3] Notation: the grid size K and probe dimensions are introduced without a short illustrative example; a small diagram or equation for the outer-product map would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the efficiency and interpretability contributions of GridProbe. We address each major comment below and indicate the revisions planned for the next manuscript version.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method): the headline gains (matching baseline within 1.6 pp at 3.36× TFLOPs on Video-MME-v2; Pareto dominance +0.9 pp at 0.35× on LongVideoBench) depend on the claim that peak posteriors from linear row/column probes reliably localize evidence for reasoning-heavy queries (negation, cross-frame counting, holistic summarization). Because each probe sees only a linear subset of frames, the outer-product map and subsequent Shape-Adaptive Selection can inherit partial or spurious signals; this assumption is central and requires explicit per-query-type validation or failure-case analysis to support the reported improvements.
Authors: We agree that the localization assumption for reasoning-heavy queries is central and that a more granular validation would strengthen the paper. While the reported results on Video-MME-v2 and LongVideoBench already encompass such queries and demonstrate near-parity performance, the current manuscript does not include an explicit per-query-type breakdown or dedicated failure-case analysis. We will revise §4 to add this: accuracy stratified by query category (negation, cross-frame counting, summarization), plus selected importance-map visualizations for both successful and partial-localization cases, to directly address potential spurious signals from the linear probes. revision: yes
-
Referee: [§4] §4 (experiments): the Pareto claims and decoupling results (2B selector + 4B/8B QA) are presented without visible error bars, data-split details, or controls for post-hoc tuning/selection bias. This makes it impossible to verify that M_eff genuinely tracks intrinsic question difficulty rather than benchmark artifacts, directly affecting the soundness of the adaptive-compute conclusion.
Authors: We acknowledge that the experimental section would benefit from greater statistical transparency. The manuscript reports mean accuracies but omits error bars, explicit split details, and bias controls. In the revision we will add: (i) standard-error bars over multiple runs, (ii) precise documentation of the Video-MME-v2 and LongVideoBench splits, and (iii) additional ablations comparing M_eff against fixed-budget and random-selection baselines on the same splits. We will also clarify that Shape-Adaptive Selection hyperparameters were tuned on a small held-out validation set disjoint from the reported test sets, thereby addressing post-hoc selection concerns. revision: yes
Circularity Check
No circularity: mechanism defined directly from VLM forward passes
full rationale
The derivation consists of arranging frames into a KxK grid, extracting peak posteriors from row/column probes on the frozen VLM, forming an importance map via outer product, and applying a closed-form Shape-Adaptive Selection rule driven by skewness and kurtosis. These operations are explicit algorithmic definitions that consume the model's own outputs; they do not reduce any claimed performance gain or M_eff to a quantity fitted from the target data or to a self-citation chain. Empirical results on Video-MME-v2 and LongVideoBench are presented as external validation rather than forced equalities. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A frozen VLM's peak posteriors on lightweight row and column probes serve as reliable proxies for frame importance on the original query.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearWe arrange frames on a K×K grid and run lightweight row R and column C probes... The outer product of R and C yields an interpretable importance map whose skewness and kurtosis drive Shape-Adaptive Selection... Meff = ⌈K² / (1 + γ₀ · K · σ(M))⌉
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearσ(M) = |skew(M)| + 0.5·max(0,kurt_ex(M))
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Mdp3: A training-free approach for list-wise frame selection in video-llms
Hui Sun, Shiyin Lu, Huanyu Wang, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Ming Li. Mdp3: A training-free approach for list-wise frame selection in video-llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24090–24101, 2025
work page 2025
-
[3]
Sicheng Yu, Chengkai Jin, Huanyu Wang, Zhenghao Chen, Sheng Jin, Zhongrong Zuo, Xiaolei Xu, Zhenbang Sun, Bingni Zhang, Jiawei Wu, et al. Frame-voyager: Learning to query frames for video large language models.arXiv preprint arXiv:2410.03226, 2024
- [4]
-
[5]
Hfs: Holistic query-aware frame selection for efficient video reasoning
Yiqing Yang and Kin-Man Lam. Hfs: Holistic query-aware frame selection for efficient video reasoning. arXiv preprint arXiv:2512.11534, 2025
-
[6]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Llava-st: A multimodal large language model for fine-grained spatial-temporal understanding
Hongyu Li, Jinyu Chen, Ziyu Wei, Shaofei Huang, Tianrui Hui, Jialin Gao, Xiaoming Wei, and Si Liu. Llava-st: A multimodal large language model for fine-grained spatial-temporal understanding. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8592–8603, 2025. 10
work page 2025
-
[8]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[9]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
work page 2023
-
[10]
De-An Huang, Subhashree Radhakrishnan, Zhiding Yu, and Jan Kautz. Frag: Frame selection augmented generation for long video and long document understanding.arXiv preprint arXiv:2504.17447, 2025
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Videoatlas: Navigating long-form video in logarithmic compute.arXiv preprint arXiv:2603.17948, 2026
Mohamed Eltahir, Ali Habibullah, Yazan Alshoibi, Lama Ayash, Tanveer Hussain, and Naeemullah Khan. Videoatlas: Navigating long-form video in logarithmic compute.arXiv preprint arXiv:2603.17948, 2026
-
[13]
Videoagent: Long-form video under- standing with large language model as agent
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. Videoagent: Long-form video under- standing with large language model as agent. InEuropean Conference on Computer Vision, pages 58–76. Springer, 2024
work page 2024
-
[14]
Sullam Jeoung, Goeric Huybrechts, Bhavana Ganesh, Aram Galstyan, and Sravan Bodapati. Adaptive video understanding agent: Enhancing efficiency with dynamic frame sampling and feedback-driven reasoning.arXiv preprint arXiv:2410.20252, 2024
-
[15]
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
Chaoyou Fu, Haozhi Yuan, Yuhao Dong, Yi-Fan Zhang, Yunhang Shen, Xiaoxing Hu, Xueying Li, Jinsen Su, Chengwu Long, Xiaoyao Xie, et al. Video-mme-v2: Towards the next stage in benchmarks for comprehensive video understanding.arXiv preprint arXiv:2604.05015, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37:28828– 28857, 2024. 11 A Implementation Details Models.All experiments use Qwen3-VL-Instruct backbones at three sizes (2B, 4B, 8B parameters) loaded from HuggingFace Tra...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.