Recognition: no theorem link
MASS-DPO: Multi-negative Active Sample Selection for Direct Policy Optimization
Pith reviewed 2026-05-12 04:11 UTC · model grok-4.3
The pith
MASS-DPO selects compact negative subsets for multi-negative DPO using a Plackett-Luce Fisher-information log-determinant objective that preserves full-pool information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MASS-DPO derives a log-determinant objective from the Plackett-Luce Fisher information to select negatives that contribute complementary information for policy updates, yielding compact subsets that retain the full pool's information while reducing redundancy from similar candidates.
What carries the argument
The PL-specific Fisher-information log-determinant objective for active negative selection, which identifies subsets whose gradients span diverse update directions.
If this is right
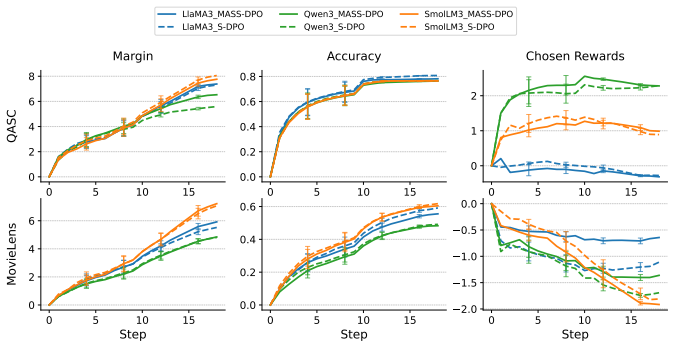
- Training uses substantially fewer negative samples per prompt while matching or exceeding baseline accuracy.
- Recall and NDCG metrics improve along with margin-based optimization dynamics.
- Stronger alignment results hold across recommendation and multiple-choice QA tasks.
- The gains appear consistently across three model families.
Where Pith is reading between the lines
- The selection criterion may generalize to other preference models if a similar Fisher matrix can be derived.
- Large-scale alignment pipelines could adopt this to lower memory and compute demands during preference tuning.
- Similar active selection might reduce redundancy in positive sample pools or in other stages of RLHF.
- Typical negative pools likely contain systematic gradient overlaps that this method systematically removes.
Load-bearing premise
The Fisher-information objective selects negatives whose gradients cover complementary update directions while retaining the full pool's information for policy updates.
What would settle it
Training identical models on the same benchmarks using the full negative pool versus the MASS-DPO selected subsets and checking whether the subset version shows lower Recall, NDCG, or alignment scores.
Figures


read the original abstract
Multi-negative preference optimization under the Plackett--Luce (PL) model extends Direct Preference Optimization (DPO) by leveraging comparative signals across one preferred and multiple rejected responses. However, optimizing over large negative pools is costly, and many candidates contribute redundant gradients due to their similar effects on policy updates. We introduce MASS-DPO, a multi-negative active sample selection method that derives a PL-specific Fisher-information objective for selecting compact, informative negative subsets within each prompt. The resulting log-determinant objective selects negatives that contribute complementary information for policy updates, yielding compact subsets that retain the full pool's information while reducing redundancy. In practice, this favors negatives whose gradients cover different update directions, reducing redundant signal from near-duplicate candidates while preserving the most useful training information. Across four benchmarks spanning recommendation and multiple-choice QA and three model families, MASS-DPO consistently exceeds or matches existing methods in accuracy, improves Recall/NDCG and margin-based optimization dynamics, and delivers stronger alignment with substantially fewer negatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MASS-DPO, a multi-negative active sample selection method for Direct Preference Optimization under the Plackett-Luce (PL) model. It derives a PL-specific Fisher-information log-determinant objective to select compact subsets of negative responses that contribute complementary information for policy updates, reducing redundancy while aiming to retain the information content of the full negative pool. The approach favors negatives whose gradients cover different update directions. Experiments across four benchmarks (recommendation and multiple-choice QA) and three model families show that MASS-DPO consistently matches or exceeds existing methods in accuracy, improves Recall/NDCG and margin-based dynamics, and achieves stronger alignment using substantially fewer negatives.
Significance. If the derivation of the log-determinant objective is sound and the selection mechanism indeed preserves full-pool information while eliminating redundant gradients, the method could meaningfully improve the scalability of multi-negative DPO by lowering computational cost without sacrificing alignment quality. The reported consistent empirical gains across tasks and model families provide supporting evidence for practical utility in LLM preference optimization.
minor comments (3)
- The abstract states that the log-determinant objective 'selects negatives that contribute complementary information' and 'favors negatives whose gradients cover different update directions,' but the precise connection between the Fisher matrix and gradient complementarity should be stated more explicitly with a short derivation sketch or reference to the relevant equation in the main text.
- The manuscript should clarify the exact criteria used for data exclusion or negative pool construction in the experiments, as these details affect reproducibility of the reported Recall/NDCG improvements.
- Figure captions and axis labels for the optimization dynamics plots could be expanded to indicate the exact margin metric and number of negatives used in each curve for easier comparison.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of MASS-DPO, including the recognition of the Plackett-Luce-specific log-determinant Fisher information objective and the consistent empirical results across benchmarks and model families. The recommendation for minor revision is noted, and we are encouraged by the assessment of potential practical utility.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper frames MASS-DPO as deriving a PL-specific Fisher-information objective (log-determinant form) directly from the Plackett-Luce model to select informative negatives. This is a standard information-theoretic construction for active selection and D-optimal design, not a self-referential definition or a fitted parameter relabeled as a prediction. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatz smuggling are indicated in the provided text. The central claims rest on the derivation plus empirical validation across benchmarks, keeping the chain self-contained and independent of the target results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Plackett-Luce model governs comparative preference signals across one preferred and multiple rejected responses
Reference graph
Works this paper leans on
-
[1]
Yasin Abbasi-Yadkori, Dávid Pál, and Csaba Szepesvári. Improved algorithms for linear stochastic bandits.Advances in neural information processing systems, 24, 2011
work page 2011
-
[2]
Zeyuan Allen-Zhu, Yuanzhi Li, Aarti Singh, and Yining Wang. Near-optimal discrete optimiza- tion for experimental design: A regret minimization approach.Mathematical Programming, 186:439–478, 2021
work page 2021
-
[3]
arXiv preprint arXiv:2402.10571 , year=
Afra Amini, Tim Vieira, and Ryan Cotterell. Direct preference optimization with an offset. arXiv preprint arXiv:2402.10571, 2024
-
[4]
Jordan Ash, Surbhi Goel, Akshay Krishnamurthy, and Sham Kakade. Gone fishing: Neural active learning with fisher embeddings.Advances in Neural Information Processing Systems, 34:8927–8939, 2021
work page 2021
-
[5]
arXiv preprint arXiv:1906.03671 , year=
Jordan T Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agar- wal. Deep batch active learning by diverse, uncertain gradient lower bounds.arXiv preprint arXiv:1906.03671, 2019
-
[6]
Finetuning large language model for personalized ranking.arXiv preprint arXiv:2405.16127, 2024
Zhuoxi Bai, Ning Wu, Fengyu Cai, Xinyi Zhu, and Yun Xiong. Finetuning large language model for personalized ranking.arXiv preprint arXiv:2405.16127, 2024
-
[7]
SmolLM3: smol, multilingual, long-context reasoner.https://huggingface.co/blog/smollm3, 2025
Elie Bakouch, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Lewis Tunstall, Car- los Miguel Patiño, Edward Beeching, Aymeric Roucher, Aksel Joonas Reedi, Quentin Gal- louédec, Kashif Rasul, Nathan Habib, Clémentine Fourrier, Hynek Kydlicek, Guilherme Penedo, Hugo Larcher, Mathieu Morlon, Vaibhav Srivastav, Joshua Lochner, Xuan-Son Nguyen, Colin Raffel, ...
work page 2025
-
[8]
Ellis, Brian Whitman, and Paul Lamere
Thierry Bertin-Mahieux, Daniel P.W. Ellis, Brian Whitman, and Paul Lamere. The million song dataset. InProceedings of the 12th International Conference on Music Information Retrieval (ISMIR 2011), 2011
work page 2011
- [9]
-
[10]
Bayesian experimental design: A review.Statistical science, pages 273–304, 1995
Kathryn Chaloner and Isabella Verdinelli. Bayesian experimental design: A review.Statistical science, pages 273–304, 1995
work page 1995
-
[11]
On softmax direct preference optimization for recommendation.arXiv preprint arXiv:2406.09215, 2024
Yuxin Chen, Junfei Tan, An Zhang, Zhengyi Yang, Leheng Sheng, Enzhi Zhang, Xiang Wang, and Tat-Seng Chua. On softmax direct preference optimization for recommendation.arXiv preprint arXiv:2406.09215, 2024
-
[12]
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 4302–4310, Red Hook, NY , USA, 2017. Curran Associates Inc. ISBN 9781510860964
work page 2017
-
[13]
David Cohn. Neural network exploration using optimal experiment design.Advances in neural information processing systems, 6, 1993
work page 1993
-
[14]
Active preference optimization for sample efficient rlhf.arXiv preprint arXiv:2402.10500, 2024
Nirjhar Das, Souradip Chakraborty, Aldo Pacchiano, and Sayak Ray Chowdhury. Active preference optimization for sample efficient rlhf.arXiv preprint arXiv:2402.10500, 2024
-
[15]
Neighborhood-based hard negative mining for sequential recommendation
Lu Fan, Jiashu Pu, Rongsheng Zhang, and Xiao-Ming Wu. Neighborhood-based hard negative mining for sequential recommendation. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2042–2046, 2023
work page 2042
-
[16]
R. A. Fisher and Edward John Russell. On the mathematical foundations of theoreti- cal statistics.Philosophical Transactions of the Royal Society of London. Series A, Con- taining Papers of a Mathematical or Physical Character, 222(594-604):309–368, 1922. doi: 10.1098/rsta.1922.0009. URL https://royalsocietypublishing.org/doi/abs/ 10.1098/rsta.1922.0009
-
[17]
Robust design of biological experiments
Patrick Flaherty, Adam Arkin, and Michael Jordan. Robust design of biological experiments. Advances in neural information processing systems, 18, 2005. 10
work page 2005
-
[18]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Efficient dynamic hard negative sampling for dialogue selection
Janghoon Han, Dongkyu Lee, Joongbo Shin, Hyunkyung Bae, Jeesoo Bang, Seonghwan Kim, Stanley Jungkyu Choi, and Honglak Lee. Efficient dynamic hard negative sampling for dialogue selection. In Elnaz Nouri, Abhinav Rastogi, Georgios Spithourakis, Bing Liu, Yun-Nung Chen, Yu Li, Alon Albalak, Hiromi Wakaki, and Alexandros Papangelis, editors, Proceedings of t...
work page 2024
-
[20]
F Maxwell Harper and Joseph A Konstan. The movielens datasets: History and context.Acm transactions on interactive intelligent systems (tiis), 5(4):1–19, 2015
work page 2015
-
[21]
Reclaif: Reinforcement learning from ai feedback for recommendation systems
Xiaoxin He, Nurendra Choudhary, Jieyi Jiang, Edward W Huang, Bryan Hooi, Xavier Bresson, and Karthik Subbian. Reclaif: Reinforcement learning from ai feedback for recommendation systems. 2025
work page 2025
-
[22]
Pluralistic off-policy evaluation and alignment
Chengkai Huang, Junda Wu, Zhouhang Xie, Yu Xia, Rui Wang, Tong Yu, Subrata Mitra, Julian McAuley, and Lina Yao. Pluralistic off-policy evaluation and alignment.arXiv preprint arXiv:2509.19333, 2025
-
[23]
Hongtao Huang, Chengkai Huang, Junda Wu, Tong Yu, Julian McAuley, and Lina Yao. Listwise preference diffusion optimization for user behavior trajectories prediction.Advances in Neural Information Processing Systems, 38:159383–159408, 2026
work page 2026
-
[24]
Traceable and explainable multimodal large language models: An information-theoretic view
Zihan Huang, Junda Wu, Rohan Surana, Raghav Jain, Tong Yu, Raghavendra Addanki, David Arbour, Sungchul Kim, and Julian McAuley. Traceable and explainable multimodal large language models: An information-theoretic view. InSecond Conference on Language Modeling, 2025
work page 2025
-
[25]
Image difference captioning via adversarial preference optimization
Zihan Huang, Junda Wu, Rohan Surana, Tong Yu, David Arbour, Ritwik Sinha, and Julian McAuley. Image difference captioning via adversarial preference optimization. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33746– 33758, 2025
work page 2025
-
[26]
arXiv preprint arXiv:2602.12533 , year=
Zihan Huang, Xintong Li, Rohan Surana, Tong Yu, Rui Wang, Julian McAuley, Jingbo Shang, and Junda Wu. Amps: Adaptive modality preference steering via functional entropy.arXiv preprint arXiv:2602.12533, 2026
-
[27]
Yongsu Jung and Ikjin Lee. Optimal design of experiments for optimization-based model calibration using fisher information matrix.Reliability Engineering & System Safety, 216: 107968, 2021. ISSN 0951-8320. doi: https://doi.org/10.1016/j.ress.2021.107968. URL https: //www.sciencedirect.com/science/article/pii/S0951832021004798
-
[28]
Yannis Kalantidis, Mert Bulent Sariyildiz, Noe Pion, Philippe Weinzaepfel, and Diane Larlus. Hard negative mixing for contrastive learning.Advances in neural information processing systems, 33:21798–21809, 2020
work page 2020
-
[29]
Tushar Khot, Peter Clark, Michal Guerquin, Peter Jansen, and Ashish Sabharwal. Qasc: A dataset for question answering via sentence composition.Proceedings of the AAAI Conference on Artificial Intelligence, 34(05):8082–8090, Apr. 2020. doi: 10.1609/aaai.v34i05.6319. URL https://ojs.aaai.org/index.php/AAAI/article/view/6319
-
[30]
Jack Kiefer. Optimum experimental designs.Journal of the Royal Statistical Society: Series B (Methodological), 21(2):272–304, 1959
work page 1959
-
[31]
Andreas Kirsch and Yarin Gal. Unifying approaches in active learning and active sampling via fisher information and information-theoretic quantities.arXiv preprint arXiv:2208.00549, 2022
-
[32]
Andreas Kirsch, Joost Van Amersfoort, and Yarin Gal. Batchbald: Efficient and diverse batch acquisition for deep bayesian active learning.Advances in neural information processing systems, 32, 2019
work page 2019
-
[33]
Near-optimal nonmyopic value of information in graphical models.arXiv preprint arXiv:1207.1394, 2012
Andreas Krause and Carlos E Guestrin. Near-optimal nonmyopic value of information in graphical models.arXiv preprint arXiv:1207.1394, 2012. 11
-
[34]
Andreas Krause, Ajit Singh, and Carlos Guestrin. Near-optimal sensor placements in gaussian processes: Theory, efficient algorithms and empirical studies.Journal of Machine Learning Research, 9(2), 2008
work page 2008
-
[35]
Active learning for direct preference optimization
Branislav Kveton, Xintong Li, Julian McAuley, Ryan Rossi, Jingbo Shang, Junda Wu, and Tong Yu. Active learning for direct preference optimization.arXiv preprint arXiv:2503.01076, 2025
-
[36]
Importance sampling for multi-negative multimodal direct preference optimization
Xintong Li, Chuhan Wang, Junda Wu, Rohan Surana, Tong Yu, Julian McAuley, and Jingbo Shang. Importance sampling for multi-negative multimodal direct preference optimization. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=HEFPwoGtTj
work page 2026
-
[37]
arXiv preprint arXiv:2410.12854 , year=
Weibin Liao, Xu Chu, and Yasha Wang. Tpo: Aligning large language models with multi-branch & multi-step preference trees.arXiv preprint arXiv:2410.12854, 2024
-
[38]
arXiv preprint arXiv:2410.02504 , year=
Pangpang Liu, Chengchun Shi, and Will Wei Sun. Dual active learning for reinforcement learning from human feedback.arXiv preprint arXiv:2410.02504, 2024
-
[39]
R Duncan Luce et al.Individual choice behavior, volume 4. Wiley New York, 1959
work page 1959
-
[40]
Haokai Ma, Ruobing Xie, Lei Meng, Fuli Feng, Xiaoyu Du, Xingwu Sun, Zhanhui Kang, and Xiangxu Meng. Negative sampling in recommendation: A survey and future directions.arXiv preprint arXiv:2409.07237, 2024
-
[41]
Subhojyoti Mukherjee, Anusha Lalitha, Kousha Kalantari, Aniket Anand Deshmukh, Ge Liu, Yifei Ma, and Branislav Kveton. Optimal design for human preference elicitation.Advances in Neural Information Processing Systems, 37:90132–90159, 2024
work page 2024
-
[42]
Ws-grpo: Weakly-supervised group-relative policy optimization for rollout-efficient reasoning
Gagan Mundada, Zihan Huang, Rohan Surana, Sheldon Yu, Jennifer Yuntong Zhang, Xintong Li, Tong Yu, Lina Yao, Jingbo Shang, Julian McAuley, et al. Ws-grpo: Weakly-supervised group- relative policy optimization for rollout-efficient reasoning.arXiv preprint arXiv:2602.17025, 2026
-
[43]
Tracianne B. Neilsen, David F. Van Komen, Mark K. Transtrum, Makenzie B. Allen, and David P. Knobles. Optimal experimental design for machine learning using the fisher information. Proceedings of Meetings on Acoustics, 35(1):055004, 01 2019. ISSN 1939-800X. doi: 10.1121/ 2.0000953. URLhttps://doi.org/10.1121/2.0000953
- [44]
-
[45]
A survey on llm-based conversational user simulation
Bo Ni, Yu Wang, Leyao Wang, Branislav Kveton, Franck Dernoncourt, Yu Xia, Hongjie Chen, Reuben Luera, Samyadeep Basu, Subhojyoti Mukherjee, et al. A survey on llm-based conversational user simulation. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4266–4301, 2026
work page 2026
-
[46]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[47]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Gerardo Flores, George H Chen, Tom Pollard, Joyce C Ho, and Tristan Naumann, editors,Proceedings of the Conference on Health, Inference, and Learning, volume 174 ofProceedings of Machine Learni...
work page 2022
-
[48]
Robin L Plackett. The analysis of permutations.Journal of the Royal Statistical Society Series C: Applied Statistics, 24(2):193–202, 1975
work page 1975
- [49]
-
[50]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36:53728–53741, 2023. 12
work page 2023
-
[51]
Carlos Riquelme, George Tucker, and Jasper Snoek. Deep bayesian bandits showdown: An empirical comparison of bayesian deep networks for thompson sampling.arXiv preprint arXiv:1802.09127, 2018
-
[52]
Contrastive learning with hard negative samples,
Joshua Robinson, Ching-Yao Chuang, Suvrit Sra, and Stefanie Jegelka. Contrastive learning with hard negative samples.arXiv preprint arXiv:2010.04592, 2020
-
[53]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach.arXiv preprint arXiv:1708.00489, 2017
work page Pith review arXiv 2017
-
[54]
Jamshid Sourati, Murat Akcakaya, Todd K Leen, Deniz Erdogmus, and Jennifer G Dy. Asymp- totic analysis of objectives based on fisher information in active learning.Journal of Machine Learning Research, 18(34):1–41, 2017
work page 2017
-
[55]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc. ISBN 9781713829546
work page 2020
-
[56]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020
work page 2020
-
[57]
Chao Sun, Yaobo Liang, Yaming Yang, Shilin Xu, Tianmeng Yang, and Yunhai Tong. Di- rect preference optimization for llm-enhanced recommendation systems.arXiv preprint arXiv:2410.05939, 2024
-
[58]
Rohan Surana, Gagan Mundada, Xunyi Jiang, Chuhan Wang, Zhenwei Tang, Difan Jiao, Zihan Huang, Yuxin Xiong, Junda Wu, Sheldon Yu, et al. Generate, filter, control, replay: A comprehensive survey of rollout strategies for llm reinforcement learning.arXiv preprint arXiv:2605.02913, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
Qwen Team. Qwen3, April 2025. URLhttps://qwenlm.github.io/blog/qwen3/
work page 2025
-
[60]
Kiran Koshy Thekumparampil, Gaurush Hiranandani, Kousha Kalantari, Shoham Sabach, and Branislav Kveton. Comparing few to rank many: Active human preference learning using randomized frank-wolfe.arXiv preprint arXiv:2412.19396, 2024
-
[61]
Scenealign: Aligning multimodal reasoning to scene graphs in complex visual scenes
Chuhan Wang, Xintong Li, Jennifer Yuntong Zhang, Junda Wu, Chengkai Huang, Lina Yao, Julian McAuley, and Jingbo Shang. Scenealign: Aligning multimodal reasoning to scene graphs in complex visual scenes.arXiv preprint arXiv:2601.05600, 2026
-
[62]
Franklin Wang and Sumanth Hegde. Accelerating direct preference optimization with prefix sharing.arXiv preprint arXiv:2410.20305, 2024
- [63]
-
[64]
Junda Wu, Tong Yu, Rui Wang, Zhao Song, Ruiyi Zhang, Handong Zhao, Chaochao Lu, Shuai Li, and Ricardo Henao. Infoprompt: Information-theoretic soft prompt tuning for natural language understanding.Advances in neural information processing systems, 36:61060–61084, 2023
work page 2023
-
[65]
Ocean: Offline chain-of-thought evaluation and alignment in large language models
Junda Wu, Xintong Li, Ruoyu Wang, Yu Xia, Yuxin Xiong, Jianing Wang, Tong Yu, Xiang Chen, Branislav Kveton, Lina Yao, et al. Ocean: Offline chain-of-thought evaluation and alignment in large language models. InInternational Conference on Learning Representations, volume 2025, pages 100570–100589, 2025
work page 2025
-
[66]
Rossi, Prithviraj Ammanabrolu, and Julian McAuley
Junda Wu, Rohan Surana, Zhouhang Xie, Yiran Shen, Yu Xia, Tong Yu, Ryan A. Rossi, Prithviraj Ammanabrolu, and Julian McAuley. In-context ranking preference optimization. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum? id=L2NPhLAKEd
work page 2025
-
[67]
Shuo Xie, Fangzhi Zhu, Jiahui Wang, Lulu Wen, Wei Dai, Xiaowei Chen, Junxiong Zhu, Kai Zhou, and Bo Zheng. Mppo: Multi pair-wise preference optimization for llms with arbitrary negative samples.arXiv preprint arXiv:2412.15244, 2024
-
[68]
Zhouhang Xie, Junda Wu, Yiran Shen, Raghav Jain, Yu Xia, Xintong Li, Aaron Chang, Ryan A. Rossi, Tong Yu, Sachin Kumar, Bodhisattwa Prasad Majumder, Jingbo Shang, Prithviraj 13 Ammanabrolu, and Julian McAuley. A survey on personalized and pluralistic preference alignment in large language models. InSecond Conference on Language Modeling, 2025. URL https:/...
work page 2025
-
[69]
Zhi Yang, Jiwei Qin, Chuan Lin, Yanping Chen, Ruizhang Huang, and Yongbin Qin. Ganrec: A negative sampling model with generative adversarial network for recommendation.Expert Systems with Applications, 214:119155, 2023. ISSN 0957-4174. doi: https://doi.org/10.1016/ j.eswa.2022.119155. URL https://www.sciencedirect.com/science/article/pii/ S095741742202173X
-
[70]
Optimizing dense retrieval model training with hard negatives, 2021
Jingtao Zhan, Jiaxin Mao, Yiqun Liu, Jiafeng Guo, Min Zhang, and Shaoping Ma. Optimizing dense retrieval model training with hard negatives, 2021. URL https://arxiv.org/abs/ 2104.08051
-
[71]
Zhaoyang Zhang, Xuying Wang, Xiaoming Mei, Chao Tao, and Haifeng Li. False: False negative samples aware contrastive learning for semantic segmentation of high-resolution remote sensing image.IEEE Geoscience and Remote Sensing Letters, 19:1–5, 2022. A Appendix Lemma A.1(Gradient Derivation).Consider the loss for a single sample L(θ) =−logσ Z(θ) ,withZ(θ) ...
work page 2022
-
[72]
Proof.Let xk = (v0 ik)⊤(H0 k−1)−1v0 ik
Under Assumptions C.1–C.4, for any candidate i∈ C and any subset Sn of sizenproduced by Algorithm 1, (ϕi − ¯ϕ0)⊤Σ−1 n (ϕi − ¯ϕ0)≤ κ ρq0 min · 1 +α 0L0 v/γ α0 · d n log 1 + α0nL0 v γd . Proof.Let xk = (v0 ik)⊤(H0 k−1)−1v0 ik . By the max-marginal construction in Algorithm 1, xk = maxj /∈Ik−1(v0 j )⊤(H0 k−1)−1v0 j . By Assump- tion C.3, for anyi∈ C, (v0 i )...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.