Recognition: 2 theorem links
· Lean TheoremGenerate, Filter, Control, Replay: A Comprehensive Survey of Rollout Strategies for LLM Reinforcement Learning
Pith reviewed 2026-05-10 19:11 UTC · model grok-4.3
The pith
Rollout strategies for LLM reinforcement learning decompose into four modular stages: Generate, Filter, Control, and Replay.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
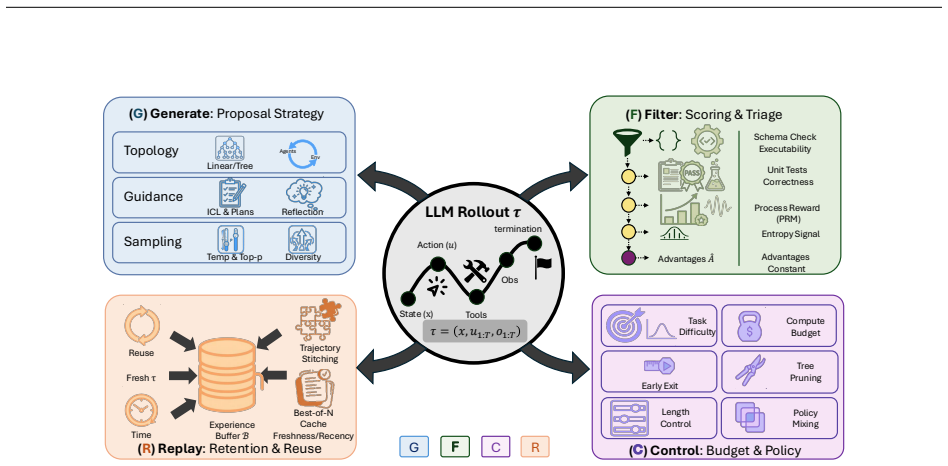
The paper claims that rollout pipelines can be formalized with unified notation and decomposed via the Generate-Filter-Control-Replay lifecycle taxonomy into four modular stages, paired with a criterion taxonomy of reliability, coverage, and cost sensitivity, enabling synthesis of existing techniques and identification of pathologies in RL-based LLM post-training.
What carries the argument
The GFCR lifecycle taxonomy that decomposes rollout pipelines into Generate (candidate trajectories), Filter (intermediate signals), Control (compute allocation and decisions), and Replay (artifact retention and reuse) stages.
If this is right
- Existing methods from verifiable-reward RL, process supervision, judge gating, and tree rollouts can be organized under the same four-stage structure.
- A diagnostic index directly links common rollout failures such as poor coverage or high cost to specific GFCR modules.
- Self-evolving curricula arise naturally when Replay retains and reuses generated tasks across iterations.
- Case studies in math, code, multimodal, and agent benchmarks show how the taxonomy supports skill induction and cross-task transfer.
Where Pith is reading between the lines
- The same four-stage breakdown could help organize rollout design in reinforcement learning outside language models.
- Stronger Control mechanisms might allow more aggressive early stopping to cut post-training compute.
- Widespread adoption of Replay for curricula could shift training toward more autonomous task generation.
Load-bearing premise
The assumption that rollout strategies across the literature can be uniformly mapped to the GFCR stages without oversimplifying interactions between stages.
What would settle it
An examination of published rollout methods that identifies multiple strategies which resist clean mapping into the four GFCR stages without substantial loss of their original design details.
Figures





read the original abstract
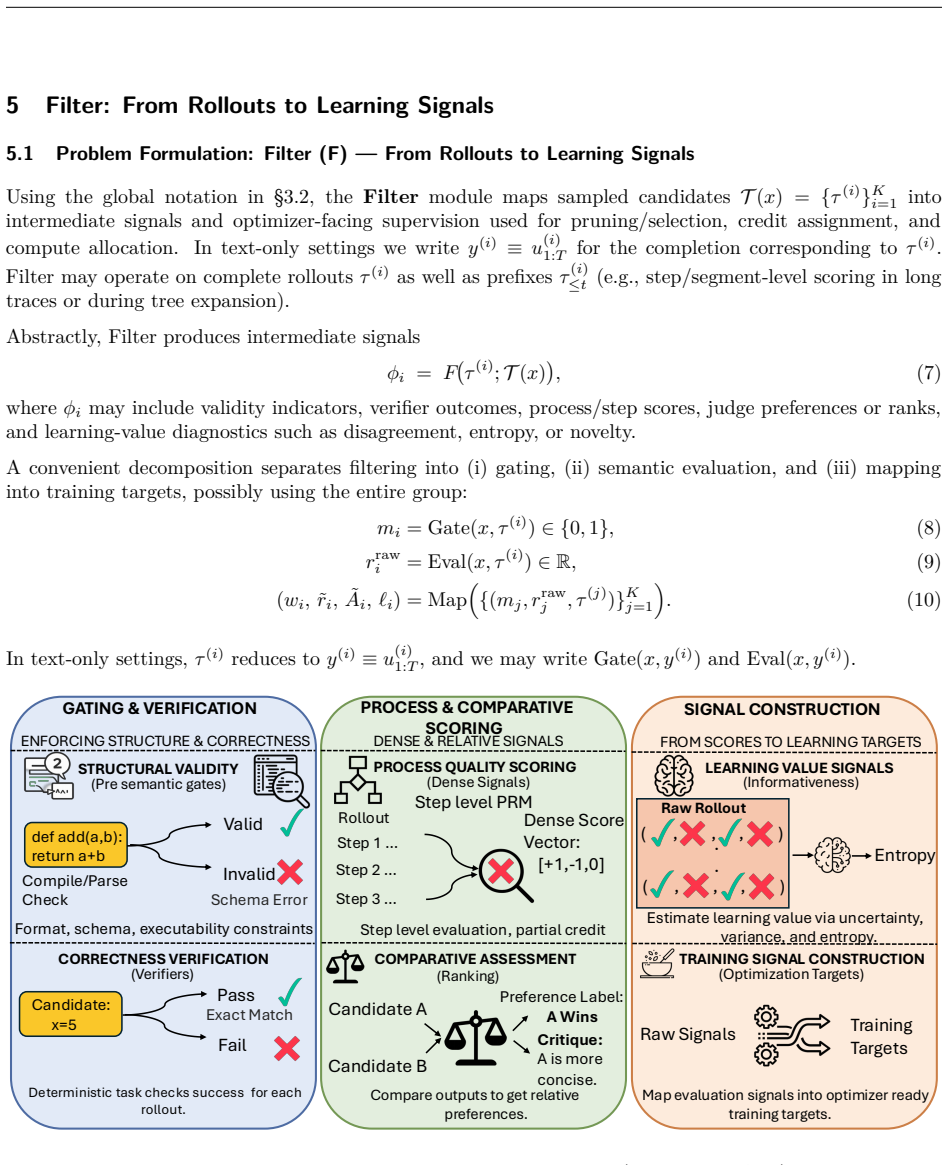
Reinforcement learning (RL) has become a central post-training tool for improving the reasoning abilities of large language models (LLMs). In these systems, the rollout, the trajectory sampled from a prompt to termination, including intermediate reasoning steps and optional tool or environment interactions, determines the data the optimizer learns from, yet rollout design is often underreported. This survey provides an optimizer-agnostic view of rollout strategies for RL-based post-training of reasoning LLMs. We formalize rollout pipelines with unified notation and introduce Generate-Filter-Control-Replay (GFCR), a lifecycle taxonomy that decomposes rollout pipelines into four modular stages: Generate proposes candidate trajectories and topologies; Filter constructs intermediate signals via verifiers, judges, critics; Control allocates compute and makes continuation/branching/stopping decisions under budgets; and Replay retains and reuses artifacts across rollouts without weight updates, including self-evolving curricula that autonomously generate new training tasks. We complement GFCR with a criterion taxonomy of reliability, coverage, and cost sensitivity that characterizes rollout trade-offs. Using this framework, we synthesize methods spanning RL with verifiable rewards, process supervision, judge-based gating, guided and tree/segment rollouts, adaptive compute allocation, early-exit and partial rollouts, throughput optimization, and replay/recomposition for self-improvement. We ground the framework with case studies in math, code/SQL, multimodal reasoning, tool-using agents, and agentic skill benchmarks that evaluate skill induction, reuse, and cross-task transfer. Finally, we provide a diagnostic index that maps common rollout pathologies to GFCR modules and mitigation levers, alongside open challenges for building reproducible, compute-efficient, and trustworthy rollout pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a comprehensive survey of rollout strategies for RL-based post-training of reasoning LLMs. It introduces unified notation for rollout pipelines and the Generate-Filter-Control-Replay (GFCR) lifecycle taxonomy that decomposes them into four modular stages—Generate (proposing trajectories/topologies), Filter (building signals via verifiers/judges/critics), Control (compute allocation and branching/stopping decisions), and Replay (retaining artifacts for reuse and self-evolving curricula)—plus a reliability-coverage-cost criterion taxonomy. The work synthesizes literature on verifiable-reward RL, process supervision, tree/segment rollouts, adaptive compute, and self-improvement; grounds the framework in case studies across math, code/SQL, multimodal, tool-use, and agentic benchmarks; and supplies a diagnostic index mapping pathologies to GFCR modules along with open challenges.
Significance. If the GFCR decomposition holds without substantial oversimplification, the survey would provide a useful synthesis tool for the field, enabling clearer comparison of rollout designs, identification of trade-offs, and guidance toward reproducible and compute-efficient pipelines. The case studies and diagnostic index add concrete value for practitioners working on skill induction and cross-task transfer in LLM RL.
major comments (1)
- [GFCR taxonomy and synthesis of methods] The central claim that rollout strategies across the literature map cleanly to the four GFCR stages without losing essential cross-stage dependencies is load-bearing but insufficiently substantiated. The synthesis of tree/segment rollouts and adaptive compute (mentioned in the abstract) does not explicitly discuss hybrids in which filtering (e.g., joint critic evaluation) and control (e.g., branching or early stopping) are computed together inside the same search step, as occurs in many guided tree-search methods. This leaves the modularity claim vulnerable to post-hoc categorization rather than predictive structure.
minor comments (2)
- The unified notation for rollout pipelines would be easier to follow if accompanied by a compact summary table of symbols and their definitions early in the manuscript.
- A few citations to recent tree-search and self-improvement works appear to be missing from the synthesis section; adding them would strengthen coverage of the surveyed literature.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The feedback on the GFCR taxonomy's handling of modularity and cross-stage dependencies is well-taken, and we address it directly below with a commitment to targeted revisions.
read point-by-point responses
-
Referee: The central claim that rollout strategies across the literature map cleanly to the four GFCR stages without losing essential cross-stage dependencies is load-bearing but insufficiently substantiated. The synthesis of tree/segment rollouts and adaptive compute (mentioned in the abstract) does not explicitly discuss hybrids in which filtering (e.g., joint critic evaluation) and control (e.g., branching or early stopping) are computed together inside the same search step, as occurs in many guided tree-search methods. This leaves the modularity claim vulnerable to post-hoc categorization rather than predictive structure.
Authors: We acknowledge that the current synthesis section on tree/segment rollouts and adaptive compute does not provide explicit examples of tightly interleaved hybrids, where Filter-stage signals (such as joint critic evaluation) and Control-stage decisions (such as branching or early stopping) are computed within the same search step. While the GFCR framework is designed to accommodate such interleaving by treating Control as the locus for integrating Filter outputs under compute budgets, the manuscript would be strengthened by concrete illustrations showing that this decomposition remains predictive rather than purely post-hoc. In the revised version, we will expand the relevant synthesis subsection to include a dedicated discussion of guided tree-search methods, clarifying how joint computation is modeled as a Control operation that consumes Filter signals without collapsing the stages. This addition will reference representative works on hybrid search and demonstrate that the taxonomy preserves essential dependencies by design. revision: yes
Circularity Check
No circularity: descriptive taxonomy with no derivations or self-referential reductions
full rationale
The paper is a survey that introduces the GFCR taxonomy as a classification framework for existing rollout strategies in LLM RL literature. It formalizes notation and decomposes pipelines into Generate, Filter, Control, and Replay stages, then maps methods from the literature onto this structure. No mathematical derivations, equations, fitted parameters, or predictions are present. The taxonomy is defined explicitly in the abstract and used to synthesize prior work without any step reducing to a self-definition, fitted input renamed as prediction, or load-bearing self-citation chain. The central claim (uniform mapping of strategies to GFCR) is a descriptive organization, not a derivation that collapses by construction. This is the expected non-finding for a taxonomy survey.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize rollout pipelines with unified notation and introduce Generate-Filter-Control-Replay (GFCR), a lifecycle taxonomy that decomposes rollout pipelines into four modular stages: Generate proposes candidate trajectories... Filter constructs intermediate signals... Control allocates compute... Replay retains and reuses artifacts...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We complement GFCR with a criterion taxonomy of reliability, coverage, and cost sensitivity...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
F-GRPO: Factorized Group-Relative Policy Optimization for Unified Candidate Generation and Ranking
F-GRPO factorizes group-relative policy optimization into generation and ranking phases within one autoregressive sequence, using order-invariant coverage and position-aware utility rewards to improve top-ranked perfo...
-
MASS-DPO: Multi-negative Active Sample Selection for Direct Policy Optimization
MASS-DPO derives a Plackett-Luce-specific log-determinant Fisher information objective to select non-redundant negative samples, matching or exceeding multi-negative DPO performance with substantially fewer negatives ...
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gall \'e , Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet \"U st \"u n, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms. arXiv preprint arXiv:2402.14740, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
A state-of-the-art sql reasoning model using rlvr, 2025
Alnur Ali, Ashutosh Baheti, Jonathan Chang, Ta-Chung Chi, Brandon Cui, Andrew Drozdov, Jonathan Frankle, Abhay Gupta, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Misra, Krista Opsahl-Ong, Jose Javier Gonzalez Ortiz, Matei Zaharia, and Yue Zhang. A state-of-the-art sql reasoning model using rlvr, 2025. URL https://arxiv.org/abs/2509.21459
-
[3]
Udbhav Bamba, Minghao Fang, Yifan Yu, Haizhong Zheng, and Fan Lai. Xrpo: Pushing the limits of grpo with targeted exploration and exploitation. arXiv preprint arXiv:2510.06672, 2025
-
[4]
Brian Bartoldson, Siddarth Venkatraman, James Diffenderfer, Moksh Jain, Tal Ben-Nun, Seanie Lee, Minsu Kim, Johan Obando-Ceron, Yoshua Bengio, and Bhavya Kailkhura. Trajectory balance with asynchrony: Decoupling exploration and learning for fast, scalable llm post-training, 2025. URL https://arxiv.org/abs/2503.18929
-
[5]
Troll: Trust regions improve reinforcement learning for large language models, 2025
Philipp Becker, Niklas Freymuth, Serge Thilges, Fabian Otto, and Gerhard Neumann. Troll: Trust regions improve reinforcement learning for large language models, 2025. URL https://arxiv.org/abs/2510.03817
-
[6]
Rlhf deciphered: A critical analysis of reinforcement learning from human feedback for llms
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, and Bruno Castro da Silva. Rlhf deciphered: A critical analysis of reinforcement learning from human feedback for llms. ACM Comput. Surv., 58 0 (2), September 2025. ISSN 0360-0300. doi:10.1145/3743127. URL https://doi.org/10.1145/3743127
-
[7]
xverify: Efficient answer verifier for reasoning model evaluations
Ding Chen, Qingchen Yu, Pengyuan Wang, Wentao Zhang, Bo Tang, Feiyu Xiong, Xinchi Li, Minchuan Yang, and Zhiyu Li. xverify: Efficient answer verifier for reasoning model evaluations. arXiv preprint arXiv:2504.10481, 2025 a . URL https://arxiv.org/abs/2504.10481
-
[8]
Minghan Chen, Guikun Chen, Wenguan Wang, and Yi Yang. Seed-grpo: Semantic entropy enhanced grpo for uncertainty-aware policy optimization, 2025 b . URL https://arxiv.org/abs/2505.12346
-
[9]
Stepwise guided policy optimization: Coloring your incorrect reasoning in grpo
Peter Chen, Xiaopeng Li, Ziniu Li, Xi Chen, and Tianyi Lin. Stepwise guided policy optimization: Coloring your incorrect reasoning in grpo. arXiv preprint arXiv:2505.11595, 2025 c . URL https://arxiv.org/abs/2505.11595
-
[10]
Respec: Towards optimizing speculative decoding in reinforcement learning systems
Qiaoling Chen, Zijun Liu, Peng Sun, Shenggui Li, Guoteng Wang, Ziming Liu, Yonggang Wen, Siyuan Feng, and Tianwei Zhang. Respec: Towards optimizing speculative decoding in reinforcement learning systems. arXiv preprint arXiv:2510.26475, 2025 d
-
[11]
Self-evolving curriculum for llm reasoning.arXiv preprint arXiv:2505.14970, 2025
Xiaoyin Chen, Jiarui Lu, Minsu Kim, Dinghuai Zhang, Jian Tang, Alexandre Piché, Nicolas Gontier, Yoshua Bengio, and Ehsan Kamalloo. Self-evolving curriculum for llm reasoning, 2025 e . URL https://arxiv.org/abs/2505.14970
-
[12]
From data-centric to sample-centric: Enhancing llm reasoning via progressive optimization
Xinjie Chen, Minpeng Liao, Guoxin Chen, Chengxi Li, Biao Fu, Kai Fan, and Xinggao Liu. From data-centric to sample-centric: Enhancing llm reasoning via progressive optimization. arXiv preprint arXiv:2507.06573, 2025 f
-
[13]
The BrowserGym ecosystem for web agent research.arXiv preprint arXiv:2412.05467,
De Chezelles, Thibault Le Sellier, Sahar Omidi Shayegan, Lawrence Keunho Jang, Xing Han L \`u , Ori Yoran, Dehan Kong, Frank F Xu, Siva Reddy, Quentin Cappart, et al. The browsergym ecosystem for web agent research. arXiv preprint arXiv:2412.05467, 2024
-
[14]
Deep reinforcement learning from human preferences
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017
2017
-
[15]
Soft policy optimization: Online off-policy rl for sequence models
Taco Cohen, David W Zhang, Kunhao Zheng, Yunhao Tang, Remi Munos, and Gabriel Synnaeve. Soft policy optimization: Online off-policy rl for sequence models. arXiv preprint arXiv:2503.05453, 2025
-
[16]
Jeff Da, Clinton Wang, Xiang Deng, Yuntao Ma, Nikhil Barhate, and Sean Hendryx. Agent-rlvr: Training software engineering agents via guidance and environment rewards, 2025. URL https://arxiv.org/abs/2506.11425
-
[17]
Muzhi Dai, Chenxu Yang, and Qingyi Si. S-grpo: Early exit via reinforcement learning in reasoning models. arXiv preprint arXiv:2505.07686, 2025
-
[18]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tram \`e r. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents. Advances in Neural Information Processing Systems, 37: 0 82895--82920, 2024
2024
-
[19]
Nianchen Deng, Lixin Gu, Shenglong Ye, Yinan He, Zhe Chen, Songze Li, Haomin Wang, Xingguang Wei, Tianshuo Yang, Min Dou, et al. Internspatial: A comprehensive dataset for spatial reasoning in vision-language models. arXiv preprint arXiv:2506.18385, 2025
-
[20]
Zheng Ding and Weirui Ye. Treegrpo: Tree-advantage grpo for online rl post-training of diffusion models. arXiv preprint arXiv:2512.08153, 2025
-
[21]
Plan then action:high-level planning guidance reinforcement learning for llm reasoning, 2025
Zhihao Dou, Qinjian Zhao, Zhongwei Wan, Dinggen Zhang, Weida Wang, Towsif Raiyan, Benteng Chen, Qingtao Pan, Yang Ouyang, Zhiqiang Gao, Shufei Zhang, and Sumon Biswas. Plan then action:high-level planning guidance reinforcement learning for llm reasoning, 2025. URL https://arxiv.org/abs/2510.01833
-
[22]
Memp: Exploring Agent Procedural Memory
Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Memp: Exploring agent procedural memory, 2026. URL https://arxiv.org/abs/2508.06433
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training. arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review arXiv 2025
-
[24]
Saman Forouzandeh, Wei Peng, Parham Moradi, Xinghuo Yu, and Mahdi Jalili. Learning hierarchical procedural memory for llm agents through bayesian selection and contrastive refinement. arXiv preprint arXiv:2512.18950, 2025
-
[25]
Xiaolong Fu, Lichen Ma, Zipeng Guo, Gaojing Zhou, Chongxiao Wang, ShiPing Dong, Shizhe Zhou, Ximan Liu, Jingling Fu, Tan Lit Sin, et al. Dynamic-treerpo: Breaking the independent trajectory bottleneck with structured sampling. arXiv preprint arXiv:2509.23352, 2025
-
[26]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pp.\ 10835--10866. PMLR, 2023
2023
-
[27]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on llm-as-a-judge. arXiv preprint arXiv:2411.15594, 2024. URL https://arxiv.org/abs/2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[29]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
G\^2rpo-a: Guided group relative policy optimization with adaptive guidance
Yongxin Guo, Wenbo Deng, Zhenglin Cheng, and Xiaoying Tang. G\^2rpo-a: Guided group relative policy optimization with adaptive guidance. arXiv preprint arXiv:2508.13023, 2025 c
-
[31]
A survey of reinforcement learning in large language models: From data generation to test-time inference
Zichuan Guo and Hao Wang. A survey of reinforcement learning in large language models: From data generation to test-time inference. Available at SSRN 5128927, 2025
2025
-
[32]
Train long, think short: Curriculum learning for efficient reasoning
Hasan Abed Al Kader Hammoud, Kumail Alhamoud, Abed Hammoud, Elie Bou-Zeid, Marzyeh Ghassemi, and Bernard Ghanem. Train long, think short: Curriculum learning for efficient reasoning. arXiv preprint arXiv:2508.08940, 2025
-
[33]
LEGOMem : Modular procedural memory for multi-agent LLM systems for workflow automation, 2025
Dongge Han, Camille Couturier, Daniel Madrigal Diaz, Xuchao Zhang, Victor R \"u hle, and Saravan Rajmohan. Legomem: Modular procedural memory for multi-agent llm systems for workflow automation. arXiv preprint arXiv:2510.04851, 2025
-
[34]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems, 2024. URL https://arxiv.org/abs/2402.14008
work page internal anchor Pith review arXiv 2024
-
[35]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset, 2021. URL https://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[36]
T ree RL : LLM reinforcement learning with on-policy tree search
Zhenyu Hou, Ziniu Hu, Yujiang Li, Rui Lu, Jie Tang, and Yuxiao Dong. T ree RL : LLM reinforcement learning with on-policy tree search. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 12355--12369, Vie...
-
[37]
Figure captioning with large generative models: A survey
Chan-Wei Hu, Reuben Luera, Franck Dernoncourt, Huanjiang Liu, Seon Gyeom Kim, Ashish Singh, Puneet Mathur, Bo Ni, Samyadeep Basu, Hongjie Chen, et al. Figure captioning with large generative models: A survey. 2026
2026
-
[38]
Qinghao Hu, Shang Yang, Junxian Guo, Xiaozhe Yao, Yujun Lin, Yuxian Gu, Han Cai, Chuang Gan, Ana Klimovic, and Song Han. Taming the long-tail: Efficient reasoning rl training with adaptive drafter. arXiv preprint arXiv:2511.16665, 2025 a
-
[39]
Zengjie Hu, Jiantao Qiu, Tianyi Bai, Haojin Yang, Binhang Yuan, Qi Jing, Conghui He, and Wentao Zhang. Vade: Variance-aware dynamic sampling via online sample-level difficulty estimation for multimodal rl, 2025 b . URL https://arxiv.org/abs/2511.18902
-
[40]
arXiv preprint arXiv:2509.09284 , year=
Bingning Huang, Tu Nguyen, and Matthieu Zimmer. Tree-opo: Off-policy monte carlo tree-guided advantage optimization for multistep reasoning. arXiv preprint arXiv:2509.09284, 2025 a
-
[41]
Pluralistic off-policy evaluation and alignment
Chengkai Huang, Junda Wu, Zhouhang Xie, Yu Xia, Rui Wang, Tong Yu, Subrata Mitra, Julian McAuley, and Lina Yao. Pluralistic off-policy evaluation and alignment. arXiv preprint arXiv:2509.19333, 2025 b
-
[42]
Listwise preference diffusion optimization for user behavior trajectories prediction
Hongtao Huang, Chengkai Huang, Junda Wu, Tong Yu, Julian McAuley, and Lina Yao. Listwise preference diffusion optimization for user behavior trajectories prediction. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025 c . URL https://openreview.net/forum?id=x5KUOlYKQr
2025
-
[43]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models, 2025 d . URL https://arxiv.org/abs/2503.06749
work page internal anchor Pith review arXiv 2025
-
[44]
Yuzhen Huang, Weihao Zeng, Xingshan Zeng, Qi Zhu, and Junxian He. From accuracy to robustness: A study of rule- and model-based verifiers in mathematical reasoning, 2025 e . URL https://arxiv.org/abs/2505.22203
-
[45]
Image difference captioning via adversarial preference optimization
Zihan Huang, Junda Wu, Rohan Surana, Tong Yu, David Arbour, Ritwik Sinha, and Julian McAuley. Image difference captioning via adversarial preference optimization. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 33746--33758, 2025 f
2025
-
[46]
Math-verify: A robust mathematical expression evaluation system
Hugging Face . Math-verify: A robust mathematical expression evaluation system. https://github.com/huggingface/Math-Verify, 2025. Accessed: 2026-02-03
2025
-
[47]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Guiding exploration in reinforcement learning through llm-augmented observations, 2025
Vaibhav Jain and Gerrit Grossmann. Guiding exploration in reinforcement learning through llm-augmented observations, 2025. URL https://arxiv.org/abs/2510.08779
-
[49]
Tree search for llm agent reinforcement learning, 2026
Yuxiang Ji, Ziyu Ma, Yong Wang, Guanhua Chen, Xiangxiang Chu, and Liaoni Wu. Tree search for llm agent reinforcement learning. arXiv preprint arXiv:2509.21240, 2025
-
[50]
arXiv preprint arXiv:2509.01055 , year=
Dongfu Jiang, Yi Lu, Zhuofeng Li, Zhiheng Lyu, Ping Nie, Haozhe Wang, Alex Su, Hui Chen, Kai Zou, Chao Du, et al. Verltool: Towards holistic agentic reinforcement learning with tool use. arXiv preprint arXiv:2509.01055, 2025 a
-
[51]
Vcrl: Variance-based curriculum reinforcement learning for large language models
Guochao Jiang, Wenfeng Feng, Guofeng Quan, Chuzhan Hao, Yuewei Zhang, Guohua Liu, and Hao Wang. Vcrl: Variance-based curriculum reinforcement learning for large language models. arXiv preprint arXiv:2509.19803, 2025 b
-
[52]
Think only when you need with large hybrid-reasoning models.arXiv preprint arXiv:2505.14631,
Lingjie Jiang, Xun Wu, Shaohan Huang, Qingxiu Dong, Zewen Chi, Li Dong, Xingxing Zhang, Tengchao Lv, Lei Cui, and Furu Wei. Think only when you need with large hybrid-reasoning models. arXiv preprint arXiv:2505.14631, 2025 c
-
[53]
A survey on human preference learning for aligning large language models
Ruili Jiang, Kehai Chen, Xuefeng Bai, Zhixuan He, Juntao Li, Muyun Yang, Tiejun Zhao, Liqiang Nie, and Min Zhang. A survey on human preference learning for aligning large language models. ACM Computing Surveys, 58 0 (6): 0 1--39, 2025 d
2025
-
[54]
Overthinking reduction with decoupled rewards and curriculum data scheduling, 2025 e
Shuyang Jiang, Yusheng Liao, Ya Zhang, Yanfeng Wang, and Yu Wang. Overthinking reduction with decoupled rewards and curriculum data scheduling, 2025 e . URL https://arxiv.org/abs/2509.25827
-
[55]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
arXiv preprint arXiv:2511.02755 , year =
Bowen Jin, TJ Collins, Donghan Yu, Mert Cemri, Shenao Zhang, Mengyu Li, Jay Tang, Tian Qin, Zhiyang Xu, Jiarui Lu, et al. Controlling performance and budget of a centralized multi-agent llm system with reinforcement learning. arXiv preprint arXiv:2511.02755, 2025 a
-
[57]
Search-r1: Training llms to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. In Second Conference on Language Modeling, 2025 b
2025
-
[58]
Reasoning with sampling: Your base model is smarter than you think.arXiv preprint arXiv:2510.14901,
Aayush Karan and Yilun Du. Reasoning with sampling: Your base model is smarter than you think, 2025. URL https://arxiv.org/abs/2510.14901
-
[59]
A Survey of Reinforcement Learning from Human Feedback
Timo Kaufmann, Paul Weng, Viktor Bengs, and Eyke H \"u llermeier. A Survey of Reinforcement Learning from Human Feedback . Transactions on Machine Learning Research, 2025. ISSN 2835-8856
2025
- [60]
-
[61]
Reinforcing code generation: Improving text-to-sql with execution-based learning
Atharv Kulkarni and Vivek Srikumar. Reinforcing code generation: Improving text-to-sql with execution-based learning. arXiv preprint arXiv:2506.06093, 2025
- [62]
-
[63]
arXiv preprint arXiv:2309.00267 , year=
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Cărbune, Abhinav Rastogi, and Sushant Prakash. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267, 2023. URL https://arxiv.org/abs/2309.00267
-
[64]
Sicong Leng, Jing Wang, Jiaxi Li, Hao Zhang, Zhiqiang Hu, Boqiang Zhang, Yuming Jiang, Hang Zhang, Xin Li, Lidong Bing, Deli Zhao, Wei Lu, Yu Rong, Aixin Sun, and Shijian Lu. Mmr1: Enhancing multimodal reasoning with variance-aware sampling and open resources, 2025. URL https://arxiv.org/abs/2509.21268
-
[65]
From generation to judgment: Opportunities and challenges of llm-as-a-judge
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, et al. From generation to judgment: Opportunities and challenges of llm-as-a-judge. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 2757--2791, 2025 a
2025
-
[66]
Gang Li, Yulei Qin, Xiaoyu Tan, Dingkang Yang, Yuchen Shi, Zihan Xu, Xiang Li, Xing Sun, and Ke Li. Rorecomp: Enhancing reasoning efficiency via rollout response recomposition in reinforcement learning. arXiv preprint arXiv:2509.25958, 2025 b
-
[67]
Chang, Fei Huang, Reynold Cheng, and Yongbin Li
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin C.C. Chang, Fei Huang, Reynold Cheng, and Yongbin Li. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. In Proceedings of the 37th International...
2023
-
[68]
arXiv preprint arXiv:2506.09340 (2025) 3
Siheng Li, Zhanhui Zhou, Wai Lam, Chao Yang, and Chaochao Lu. Repo: Replay-enhanced policy optimization, 2025 c . URL https://arxiv.org/abs/2506.09340
-
[69]
Importance sampling for multi-negative multimodal direct preference optimization
Xintong Li, Chuhan Wang, Junda Wu, Rohan Surana, Tong Yu, Julian McAuley, and Jingbo Shang. Importance sampling for multi-negative multimodal direct preference optimization. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=HEFPwoGtTj
2026
-
[70]
arXiv preprint arXiv:2508.17445 , year=
Yizhi Li, Qingshui Gu, Zhoufutu Wen, Ziniu Li, Tianshun Xing, Shuyue Guo, Tianyu Zheng, Xin Zhou, Xingwei Qu, Wangchunshu Zhou, et al. Treepo: Bridging the gap of policy optimization and efficacy and inference efficiency with heuristic tree-based modeling. arXiv preprint arXiv:2508.17445, 2025 d
-
[71]
arXiv preprint arXiv:2509.06040 (2025) 2, 3
Yuming Li, Yikai Wang, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, and Shanghang Zhang. Branchgrpo: Stable and efficient grpo with structured branching in diffusion models. arXiv preprint arXiv:2509.06040, 2025 e
-
[72]
Review of reinforcement learning for large language models: Formulations, algorithms, and opportunities, 2025 f
Ziniu Li, Pengyuan Wang, Tian Xu, Tian Ding, Ruoyu Sun, and Yang Yu. Review of reinforcement learning for large language models: Formulations, algorithms, and opportunities, 2025 f
2025
-
[73]
arXiv preprint arXiv:2507.06892 (2025) 3
Jing Liang, Hongyao Tang, Yi Ma, Jinyi Liu, Yan Zheng, Shuyue Hu, Lei Bai, and Jianye Hao. Squeeze the soaked sponge: Efficient off-policy reinforcement finetuning for large language model. arXiv preprint arXiv:2507.06892, 2025
-
[74]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step, 2023. URL https://arxiv.org/abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[75]
Ravr: Reference-answer-guided variational reasoning for large language models
Tianqianjin Lin, Xi Zhao, Xingyao Zhang, Rujiao Long, Yi Xu, Zhuoren Jiang, Wenbo Su, and Bo Zheng. Ravr: Reference-answer-guided variational reasoning for large language models. arXiv preprint arXiv:2510.25206, 2025. URL https://arxiv.org/abs/2510.25206
-
[76]
Rltf: Reinforcement learning from unit test feedback.arXiv preprint arXiv:2307.04349, 2023
Jiate Liu, Yiqin Zhu, Kaiwen Xiao, Qiang Fu, Xiao Han, Wei Yang, and Deheng Ye. Rltf: Reinforcement learning from unit test feedback, 2023. URL https://arxiv.org/abs/2307.04349
-
[77]
Enhancing large language model reasoning with reward models: An analytical survey
Qiyuan Liu, Hao Xu, Xuhong Chen, Wei Chen, Yee Whye Teh, and Ning Miao. Enhancing large language model reasoning with reward models: An analytical survey. arXiv preprint arXiv:2510.01925, 2025 a
-
[78]
Reuseit: Synthesizing reusable ai agent workflows for web automation
Yimeng Liu, Misha Sra, Jeevana Priya Inala, and Chenglong Wang. Reuseit: Synthesizing reusable ai agent workflows for web automation. arXiv preprint arXiv:2510.14308, 2025 b
-
[79]
Spark: Synergistic policy and reward co-evolving framework
Ziyu Liu, Yuhang Zang, Shengyuan Ding, Yuhang Cao, Xiaoyi Dong, Haodong Duan, Dahua Lin, and Jiaqi Wang. Spark: Synergistic policy and reward co-evolving framework. arXiv preprint arXiv:2509.22624, 2025 c
-
[80]
Explorllm: Guiding exploration in reinforcement learning with large language models, 2025
Runyu Ma, Jelle Luijkx, Zlatan Ajanovic, and Jens Kober. Explorllm: Guiding exploration in reinforcement learning with large language models, 2025. URL https://arxiv.org/abs/2403.09583
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.