Recognition: 1 theorem link
· Lean TheoremThe Last Word Often Wins: A Format Confound in Chain-of-Thought Corruption Studies
Pith reviewed 2026-05-12 03:42 UTC · model grok-4.3
The pith
Corruption studies on chain-of-thought chains detect the location of explicit answer statements rather than actual reasoning steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
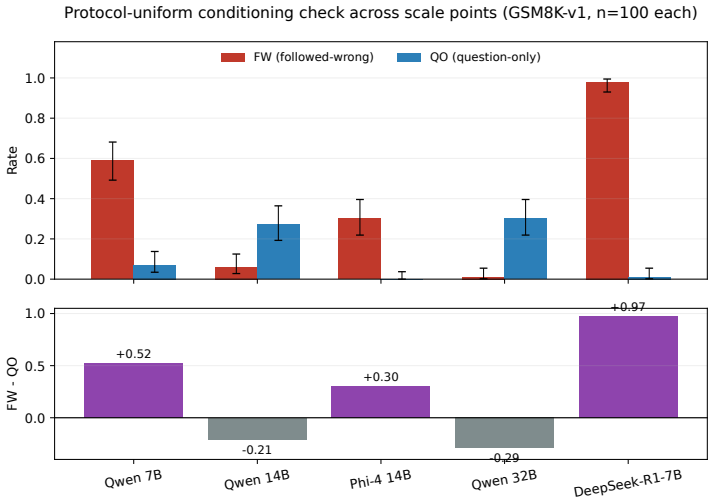
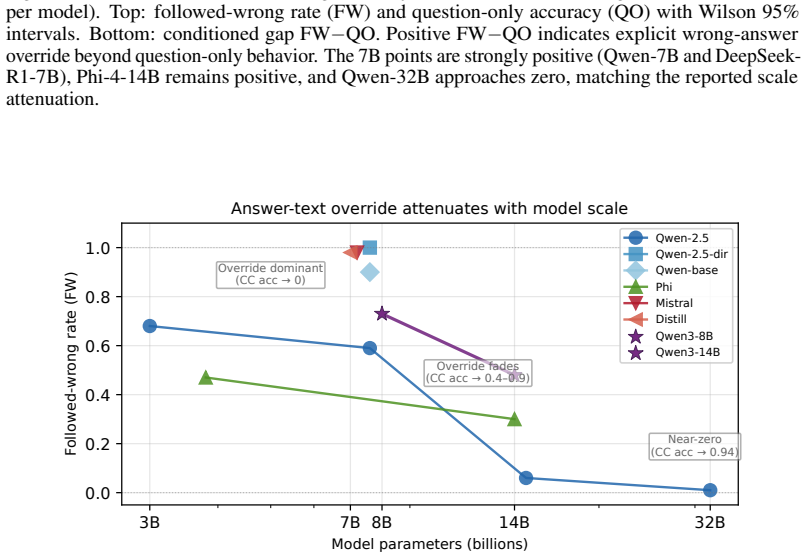
In chains with explicit terminal answer statements, corruption studies measure the placement of the answer text rather than the location of computational steps. Within-dataset ablations show that deleting only the answer statement collapses suffix sensitivity by a factor of 19 at 3B scale. Conflicting-answer insertions drive accuracy to near zero and produce followed-wrong rates from 0.63 to 1.00 at smaller scales, with the bias attenuating toward zero at 32B. The same protocol on suffix-free chains instead flags the prefix as load-bearing, and generation probes confirm the answer is not early-committed yet is followed at consumption time.
What carries the argument
The terminal answer statement in standard CoT formats, which serves as a positional cue that models follow at output time even when it contradicts prior reasoning.
If this is right
- Standard GSM8K-style benchmarks systematically inflate apparent faithfulness for terminal positions.
- Models follow explicit answer text at consumption time even when generation-time probes show no early commitment.
- The bias appears across five architecture families at 7B scale and attenuates only beyond 14B.
- Chains without answer suffixes shift load-bearing status to the prefix instead.
- A minimum protocol of question-only control, format characterization, and full-position sweep is required for valid corruption studies.
Where Pith is reading between the lines
- This format effect may explain why some faithfulness claims fail to generalize when answer phrasing changes across datasets.
- Larger models may reduce reliance on the cue through scale alone, but the paper leaves open whether training interventions could eliminate it earlier.
- The dissociation between generation and consumption suggests models treat the final statement as a separate retrieval cue rather than a recomputed result.
Load-bearing premise
The format ablations and conflicting-answer changes isolate the effect of the terminal statement without creating separate artifacts from chain editing or model training patterns.
What would settle it
Re-running the suffix corruption protocol on a new set of CoT chains that contain no explicit terminal answer statements and finding that suffix positions still show high sensitivity to corruption.
Figures




read the original abstract
Corruption studies, the primary tool for evaluating chain-of-thought (CoT) faithfulness, identify which chain positions are "computationally important" by measuring accuracy when steps are replaced with errors. We identify a systematic confound: for chains with explicit terminal answer statements, the dominant format in standard benchmarks, corruption studies detect where the answer text appears, not where computation occurs. A within-dataset format ablation provides the key evidence: on standard GSM8K chains ending with "the answer is X," removing only the answer statement, preserving all reasoning, collapses suffix sensitivity ~19x at 3B (N=300, p=0.022). Conflicting-answer experiments quantify the causal mechanism: at 7B, CC accuracy drops to near-zero (<=0.02) across five architecture families; the followed-wrong rate spans 0.63-1.00 at 3B-7B and attenuates at larger scales (0.300 at Phi-4-14B, ~0.01 at 32B). A within-stable 7B replication (9.3x attenuation, N=76, p=7.8e-3; Qwen3-8B N=299, p=0.004) provides converging evidence, and the pattern replicates on MATH (DeepSeek-R1-7B: 10.9x suffix-survival recovery). On chains without answer suffixes the same protocol identifies the prefix as load-bearing (Delta=-0.77, p<10^-12). Generation-time probes confirm a dissociation: the answer is not early-determined during generation (early commitment <5%), yet at consumption time model outputs systematically follow the explicit answer text. The format-determination effect persists through 14B (8.5x ratio, p=0.001) and converges toward zero at 32B. We propose a three-prerequisite protocol (question-only control, format characterization, all-position sweep) as a minimum standard for corruption-based faithfulness studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that corruption studies, the main method for probing chain-of-thought (CoT) faithfulness, are systematically confounded by chain format: when chains contain explicit terminal answer statements (the dominant format in benchmarks such as GSM8K), these studies measure sensitivity to the location of the answer text rather than the location of actual computation. Key evidence includes a within-dataset format ablation showing ~19x collapse in suffix sensitivity after answer-statement removal (3B scale, N=300), conflicting-answer manipulations yielding near-zero accuracy and high followed-wrong rates across five 7B-scale architectures (attenuating at 14B–32B), a within-stable replication, reversal to prefix sensitivity on no-suffix chains (Delta=-0.77), generation-time dissociation (<5% early commitment), and replication on MATH. The authors recommend a three-prerequisite protocol (question-only control, format characterization, all-position sweep) as a minimum standard.
Significance. If the central claim holds, the result is significant for LLM reasoning evaluation: it indicates that much existing work on CoT faithfulness may be capturing format sensitivity rather than computational importance, with direct implications for benchmark design and interpretation. Strengths include converging empirical lines (ablations, causal interventions, cross-scale and cross-dataset tests) with explicit statistical reporting (p-values, N sizes) and no free parameters or circular derivations. The proposed protocol offers a concrete, falsifiable improvement that could raise standards in future corruption studies.
minor comments (4)
- The format ablation reports a ~19x collapse at 3B; the exact token-level editing procedure (how the terminal statement is excised while 'preserving all reasoning') should be described in a dedicated methods subsection or appendix to allow exact replication.
- Generation-time probes state early commitment <5%; the precise operationalization of 'early commitment' (e.g., first-token probability threshold or prefix-matching criterion) should be stated explicitly.
- The five architecture families tested at 7B are referenced but not enumerated in the main text; listing them (with exact model names and parameter counts) would improve reproducibility.
- The no-suffix reversal result (Delta=-0.77, p<10^-12) is striking; a supplementary figure showing position-wise accuracy curves for both suffix and no-suffix conditions would aid visual comparison.
Simulated Author's Rebuttal
We thank the referee for their positive and accurate summary of our work, as well as the recommendation for minor revision. The report correctly captures the central claim that corruption studies on CoT chains with explicit terminal answer statements primarily detect answer-text location rather than computational steps, supported by the format ablation, conflicting-answer interventions, scale effects, and the proposed protocol. We have no major points of disagreement and will incorporate minor revisions to enhance clarity, presentation, and any additional details on the protocol as needed.
Circularity Check
No significant circularity
full rationale
The paper's claims rest entirely on empirical measurements from controlled interventions (format ablations, conflicting-answer manipulations, within-dataset controls, cross-architecture replications, and generation-time probes). No derivations, equations, fitted parameters, or self-citations are invoked as load-bearing steps; the central finding that corruption studies track answer-text location rather than computation is directly evidenced by the reported deltas, p-values, and attenuation patterns across scales and datasets. This is self-contained experimental work with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Accuracy under corruption accurately reflects computational dependence when format confounds are absent
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
for chains with explicit terminal answer statements, the dominant format in standard benchmarks, corruption studies detect where the answer text appears, not where computation occurs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, 2022
work page 2022
-
[2]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations, 2023
work page 2023
- [3]
-
[4]
Measuring Faithfulness in Chain-of-Thought Reasoning
T. Lanham, A. Chen, A. Radhakrishnan, B. Steiner, C. Durmus, D. Hernandez, N. Joseph, Z. Kernion, A. Askell, B. Jones, S. Bowman, T. Conerly, N. DasSarma, D. Drain, N. Elhage, S. El-Showk, S. Fort, Z. Hatfield-Dodds, T. Henighan, D. Jacobson, S. Johnson, J. Kernion, S. Kravec, L. Lovitt, S. Ringer, E. Tran-Johnson, and C. Olah. Measuring faithfulness in c...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [5]
- [6]
-
[7]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. InInternational Conference on Learning Representations, 2024
work page 2024
-
[9]
Solving math word problems with process- and outcome-based feedback
J. Uesato, N. Kushman, R. Kumar, F. Song, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins. Solving math word problems with process- and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [10]
-
[11]
A. Madaan and A. Yazdanbakhsh. Text and patterns: For effective chain of thought, it takes two to tango.arXiv preprint arXiv:2209.07686, 2022
-
[12]
W. Merrill and A. Sabharwal. The expressive power of transformers with chain of thought. In International Conference on Learning Representations, 2024
work page 2024
-
[13]
A. Saparov and H. He. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. InInternational Conference on Learning Representations, 2023
work page 2023
- [14]
- [15]
- [16]
-
[17]
Towards Understanding Sycophancy in Language Models
M. Sharma, M. Tong, T. Korbak, D. Duvenaud, A. Askell, S. Bowman, N. Cheng, E. Durmus, Z. Hatfield-Dodds, S. Johnston, S. Kravec, T. Maxwell, S. McCandlish, K. Ndousse, O. Rausch, N. Schiefer, D. Yan, M. Zhang, and J. Kaplan. Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548, 2023. A Slice Development Narrative The easy s...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Generation phase.The model generates a complete chain of thought for each problem. We retain only examples where the self-generated chain produces the correct answer (Ncorrect = 147; generation accuracy = 0.49)
-
[19]
Consumption phase.For each correctly-solved example, we take the model’sowngenerated steps and apply the same three-condition protocol from Section 7.2: •SG-SC: self-generated steps + correct answer line, •SG-CC: self-generated steps + conflicting wrong answer, •QO: question only (no chain). If the consumption objection holds, i.e., the model reasons more...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.