Recognition: 2 theorem links
· Lean TheoremThreat Modelling using Domain-Adapted Language Models: Empirical Evaluation and Insights
Pith reviewed 2026-05-12 03:46 UTC · model grok-4.3
The pith
Domain-adapted language models do not consistently outperform general-purpose models on structured threat modeling tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
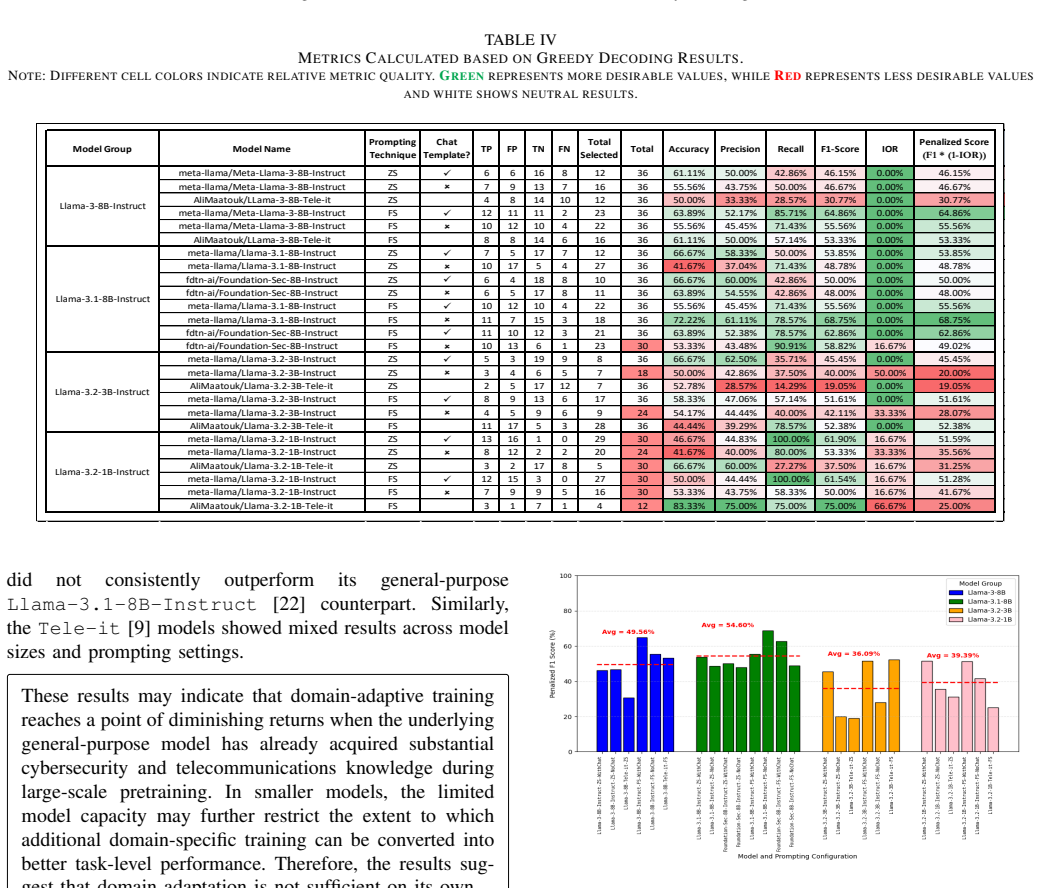
The central claim is that domain-adapted LLMs and SLMs trained on telecommunications and cybersecurity data do not consistently surpass their base counterparts when performing STRIDE threat classification on 5G use cases. Across the tested configurations, model scale correlates with better results but the gains remain neither uniform nor sufficient for dependable application. Decoding strategies exert a pronounced influence on both the validity of generated outputs and the accuracy of threat categorization, while prompting adjustments offer limited mitigation. The work therefore concludes that fundamental limitations in current language models prevent reliable structured threat modeling and,
What carries the argument
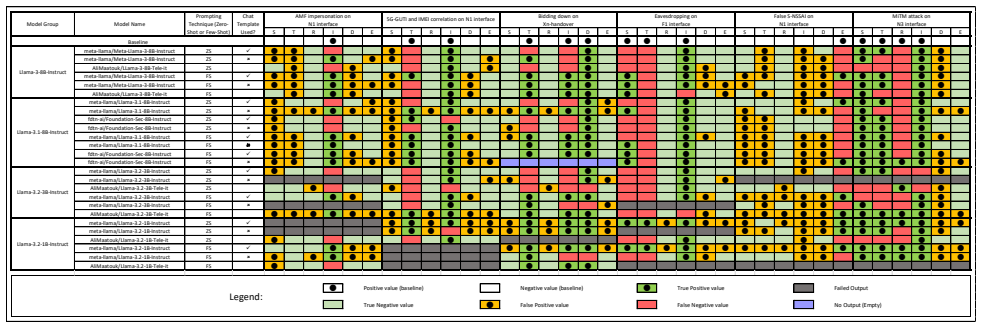
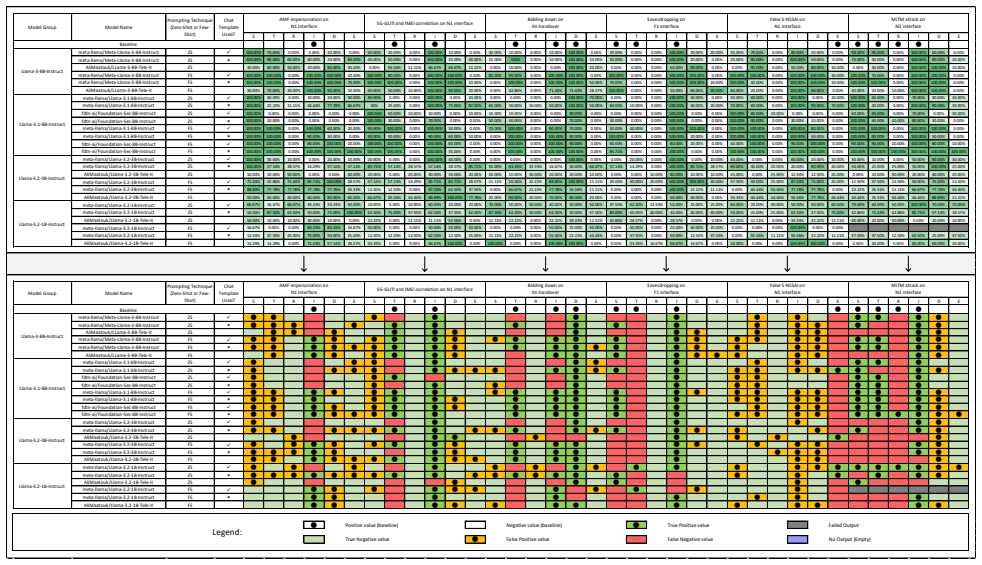
Systematic empirical comparison of eight general and domain-adapted language models under fifty-two configurations for STRIDE threat classification on 5G scenarios, isolating effects of adaptation, scale, decoding, and prompting.
If this is right
- Domain adaptation alone does not deliver consistent gains for STRIDE-based threat classification.
- Choice of decoding strategy affects output validity and model behavior more than model type or adaptation status.
- Larger models tend to perform better yet still fall short of the consistency required for practical threat modeling.
- Prompting techniques can be refined for STRIDE tasks but do not overcome the observed limitations.
- Reliable LLM use in structured security tasks will need additions such as explicit reasoning mechanisms beyond data or scale.
Where Pith is reading between the lines
- Similar output validity and consistency problems may surface in other structured security tasks such as attack surface mapping or control selection.
- Security tools built on LLMs would benefit from mandatory output validation layers and hybrid rule-based components.
- The results encourage development of models that embed security ontologies or step-by-step threat reasoning during training.
- In operational settings, human review will likely remain necessary for threat modeling outputs generated by current language models.
Load-bearing premise
The chosen eight models, fifty-two configurations, and STRIDE classification task on 5G scenarios provide a representative test of whether domain-adapted LLMs can perform reliable structured threat modelling in real deployments.
What would settle it
A controlled study in an actual 5G network showing domain-adapted models produce reliably higher accuracy and fewer invalid outputs than general models across repeated independent threat modeling exercises would disprove the main finding.
Figures









read the original abstract
Large Language Models(LLMs) are increasingly explored for cybersecurity applications such as vulnerability detection. In the domain of threat modelling, prior work has primarily evaluated a number of general-purpose Large Language Models under limited prompting settings. In this study, we extend the research area of structured threat modelling by systematically evaluating domain-adapted language models of different sizes to their general counterparts. We use both LLMs and Small Language Models(SLMs) that were domain adapted to telecommunications and cybersecuirty. For the structured threat modelling, we selected the widely used STRIDE approach and the application area is 5G security. We present a comprehensive empirical evaluation using 52 different configurations (on 8 different language models) to analyze the impact of 1) domain adaptation, 2) model scale, 3) decoding strategies (greedy vs. stochastic sampling), and 4) prompting technique on STRIDE threat classification. Our results show that domain-adapted models do not consistently outperform their general-purpose counterparts, and decoding strategies significantly affect model behavior and output validity. They also show that while larger models generally achieve higher performance, these gains are neither consistent nor sufficient for reliable threat modelling. These findings highlight fundamental limitations of current LLMs for structured threat modelling tasks and suggest that improvements require more than additional training data or model scaling, motivating the need for incorporating more task-specific reasoning and stronger grounding in security concepts. We present insights on invalid outputs encountered and present suggestions for prompting tailored specifically for STRIDE threat modelling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a systematic empirical evaluation of 8 language models (mix of LLMs and SLMs, domain-adapted to telecom/cybersecurity vs. general-purpose) on STRIDE-based threat classification for 5G security scenarios. Using 52 configurations, it tests the effects of domain adaptation, model scale, decoding strategies (greedy vs. sampling), and prompting on classification accuracy and output validity. Central claims are that domain-adapted models do not consistently outperform general counterparts, decoding strategies significantly impact behavior and validity, larger models yield inconsistent gains insufficient for reliability, and current LLMs have fundamental limitations for structured threat modelling that require more than data or scaling.
Significance. If the empirical patterns hold after methodological clarification, the work offers a useful stress-test of LLMs for cybersecurity applications, showing that domain adaptation and scale alone do not guarantee reliable structured outputs on STRIDE tasks. The multi-factor design (explicitly varying adaptation, size, decoding, and prompting) is a strength that allows isolation of effects and could inform more targeted future work on task-specific reasoning or security grounding. The insights on invalid outputs and prompting suggestions add practical value.
major comments (3)
- [Methodology section] Methodology (likely §3 or §4): No description is provided of how ground-truth STRIDE labels were assigned to the 5G scenarios, including whether expert consensus, single annotator, or automated mapping was used, nor any inter-rater agreement metric (e.g., Cohen's kappa). This directly undermines assessment of the reported performance deltas and the claim that domain-adapted models 'do not consistently outperform' general ones.
- [Results section] Results (likely §5, Tables 1-3): The statement that 'decoding strategies significantly affect model behavior and output validity' is presented without statistical tests (e.g., significance levels, confidence intervals, or p-values on accuracy/validity differences across greedy vs. sampling). Observed inconsistencies could be artifacts of the 52 configurations rather than general effects.
- [Discussion section] Discussion/Conclusion (likely §6): The generalization to 'fundamental limitations of current LLMs for structured threat modelling tasks' and the assertion that 'improvements require more than additional training data or model scaling' rests on the narrow 5G STRIDE classification task with 8 models; the paper does not address how representative these scenarios are or test broader threat-modelling contexts.
minor comments (2)
- [Abstract] Abstract: 'Large Language Models(LLMs)' and 'cybersecuirty' contain typographical issues (missing space and misspelling).
- [Abstract] The repeated phrasing 'We present insights on invalid outputs encountered and present suggestions' could be streamlined for conciseness.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing honest clarifications based on the manuscript and indicating planned revisions where the concerns are valid.
read point-by-point responses
-
Referee: [Methodology section] Methodology (likely §3 or §4): No description is provided of how ground-truth STRIDE labels were assigned to the 5G scenarios, including whether expert consensus, single annotator, or automated mapping was used, nor any inter-rater agreement metric (e.g., Cohen's kappa). This directly undermines assessment of the reported performance deltas and the claim that domain-adapted models 'do not consistently outperform' general ones.
Authors: We acknowledge that the methodology section lacks an explicit description of the ground-truth labeling process. The 5G scenarios were labeled through expert analysis by the authors (who have domain expertise in 5G security and threat modelling), using a systematic review of each scenario description against STRIDE categories; this was performed primarily by one annotator with cross-checks by co-authors, but without formal inter-rater agreement metrics such as Cohen's kappa. We will revise the methodology section to include a clear description of this process and note the absence of quantitative agreement metrics as a study limitation. This will allow better evaluation of the performance claims without misrepresenting the original work. revision: yes
-
Referee: [Results section] Results (likely §5, Tables 1-3): The statement that 'decoding strategies significantly affect model behavior and output validity' is presented without statistical tests (e.g., significance levels, confidence intervals, or p-values on accuracy/validity differences across greedy vs. sampling). Observed inconsistencies could be artifacts of the 52 configurations rather than general effects.
Authors: We agree that the absence of statistical tests weakens the support for the claim. While differences in accuracy and validity between greedy and sampling were observed consistently across the 52 configurations and 8 models, no formal tests were included in the original submission. In the revised manuscript, we will add appropriate statistical analyses (e.g., McNemar's test or Wilcoxon signed-rank tests for paired comparisons, with p-values, confidence intervals, and effect sizes) to quantify the significance of decoding strategy effects and address potential artifacts from the experimental design. revision: yes
-
Referee: [Discussion section] Discussion/Conclusion (likely §6): The generalization to 'fundamental limitations of current LLMs for structured threat modelling tasks' and the assertion that 'improvements require more than additional training data or model scaling' rests on the narrow 5G STRIDE classification task with 8 models; the paper does not address how representative these scenarios are or test broader threat-modelling contexts.
Authors: We accept that the conclusions are based on a focused evaluation of 5G STRIDE scenarios with the selected models and that broader generalization requires caution. The 5G scenarios were selected to cover diverse real-world threats in a critical domain, but we did not explicitly discuss their representativeness or test other threat-modelling contexts. We will revise the discussion and conclusion to more explicitly qualify the scope, describe why 5G STRIDE provides relevant insights for structured tasks, and frame the 'fundamental limitations' claim as specific to this setting while calling for future work on additional domains. This addresses the concern without expanding the experimental scope. revision: partial
Circularity Check
No significant circularity in empirical evaluation of LLM performance
full rationale
The paper reports direct empirical measurements of model outputs on STRIDE classification tasks across 52 configurations and 8 models, comparing domain-adapted vs. general-purpose LLMs on 5G scenarios. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text. Central claims rest on observed performance deltas and invalid output patterns rather than any reduction to inputs by construction. Prior work is referenced only for context, not as load-bearing justification for uniqueness or ansatz. This is a standard empirical study with no circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present a comprehensive empirical evaluation using 52 different configurations (on 8 different language models) to analyze the impact of 1) domain adaptation, 2) model scale, 3) decoding strategies... on STRIDE threat classification.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our results show that domain-adapted models do not consistently outperform their general-purpose counterparts...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
H. Zhou, C. Hu, Y . Yuan, Y . Cui, Y . Jin, C. Chen, H. Wu, D. Yuan, L. Jiang, D. Wuet al., “Large language model (llm) for telecommu- nications: A comprehensive survey on principles, key techniques, and opportunities,”IEEE Communications Surveys & Tutorials, vol. 27, no. 3, pp. 1955–2005, 2024
work page 1955
-
[2]
When llms meet cybersecurity: A systematic literature review,
J. Zhang, H. Bu, H. Wen, Y . Liu, H. Fei, R. Xi, L. Li, Y . Yang, H. Zhu, and D. Meng, “When llms meet cybersecurity: A systematic literature review,”Cybersecurity, vol. 8, no. 1, p. 55, 2025
work page 2025
-
[3]
Large language models for cyber security: A systematic literature review,
H. Xu, S. Wang, N. Li, K. Wang, Y . Zhao, K. Chen, T. Yu, Y . Liu, and H. Wang, “Large language models for cyber security: A systematic literature review,”ACM Transactions on Software Engineering and Methodology, 2024
work page 2024
-
[4]
Observations on llms for telecom domain: capabilities and limitations,
S. Soman and R. HG, “Observations on llms for telecom domain: capabilities and limitations,” inProceedings of the Third International Conference on AI-ML Systems, 2023, pp. 1–5
work page 2023
-
[5]
Towards explainable network intrusion detection using large language models,
P. R. Houssel, P. Singh, S. Layeghy, and M. Portmann, “Towards explainable network intrusion detection using large language models,” in2024 IEEE/ACM International Conference on Big Data Computing, Applications and Technologies (BDCAT). IEEE, 2024, pp. 67–72
work page 2024
-
[6]
Microsoft, “The stride threat model.” [Online]. Available: http://msdn.microsoft.com/en-us/library/ee823878(v=cs.20).aspx
-
[7]
From large to mammoth: A comparative evaluation of large language models in vulnerability detection
J. Lin, D. Mohaisenet al., “From large to mammoth: A comparative evaluation of large language models in vulnerability detection.” inNDSS, 2025
work page 2025
-
[8]
Llms’ suitability for network security: A case study of stride threat modeling,
A. AbdulGhaffar and A. Matrawy, “Llms’ suitability for network security: A case study of stride threat modeling,” 2025. [Online]. Available: https://arxiv.org/abs/2505.04101
-
[9]
Tele-llms: A series of specialized large language models for telecommunications,
A. Maatouk, K. C. Ampudia, R. Ying, and L. Tassiulas, “Tele-llms: A series of specialized large language models for telecommunications,”
-
[10]
Available: https://arxiv.org/abs/2409.05314
[Online]. Available: https://arxiv.org/abs/2409.05314
-
[11]
Telecomgpt: A framework to build telecom-specific large language models,
H. Zou, Q. Zhao, Y . Tian, L. Bariah, F. Bader, T. Lestable, and M. Deb- bah, “Telecomgpt: A framework to build telecom-specific large language models,”IEEE Transactions on Machine Learning in Communications and Networking, 2025
work page 2025
-
[12]
Llama-3.1-foundationai-securityllm-base-8b technical report,
P. Kassianik, B. Saglam, A. Chen, B. Nelson, A. Vellore, M. Aufiero, F. Burch, D. Kedia, A. Zohary, S. Weerawardhena, A. Priyanshu, A. Swanda, A. Chang, H. Anderson, K. Oshiba, O. Santos, Y . Singer, and A. Karbasi, “Llama-3.1-foundationai-securityllm-base-8b technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2504.21039
-
[13]
A practical guide for evaluating llms and llm-reliant systems,
E. M. Rudd, C. Andrews, and P. Tully, “A practical guide for evaluating llms and llm-reliant systems,” 2025. [Online]. Available: https://arxiv.org/abs/2506.13023
-
[14]
A survey on small language models,
C. Van Nguyen, X. Shen, R. Aponte, Y . Xia, S. Basu, Z. Hu, J. Chen, M. Parmar, S. Kunapuli, J. Barrowet al., “A survey on small language models,” inProceedings of the 15th International Conference on Recent Advances in Natural Language Processing-Natural Language Process- ing in the Generative AI Era, 2025, pp. 807–821
work page 2025
-
[15]
Security analysis of critical 5g interfaces,
M. Mahyoubet al., “Security analysis of critical 5g interfaces,”IEEE Communications Surveys & Tutorials, 2024
work page 2024
-
[16]
Reuse, don’t retrain: A recipe for continued pretraining of language models,
J. Parmar, S. Satheesh, M. Patwary, M. Shoeybi, and B. Catanzaro, “Reuse, don’t retrain: A recipe for continued pretraining of language models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.07263
-
[17]
K., Sharma, N., Bethge, M., and Ermis, B
C ¸ a˘gatay Yıldız, N. K. Ravichandran, N. Sharma, M. Bethge, and B. Ermis, “Investigating continual pretraining in large language models: Insights and implications,” 2025. [Online]. Available: https://arxiv.org/abs/2402.17400
-
[18]
Mistral AI, “Mixtral-8x7B-Instruct-v0.1,” 2023. [Online]. Available: https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1
work page 2023
-
[19]
Teleqna: A benchmark dataset to assess large language models telecommunications knowledge,
A. Maatouk, F. Ayed, N. Piovesan, A. De Domenico, M. Debbah, and Z.- Q. Luo, “Teleqna: A benchmark dataset to assess large language models telecommunications knowledge,”IEEE Network, 2025
work page 2025
-
[20]
Large language models are not robust multiple choice selectors.arXiv preprint arXiv:2309.03882, 2023
C. Zheng, H. Zhou, F. Meng, J. Zhou, and M. Huang, “Large language models are not robust multiple choice selectors,” 2024. [Online]. Available: https://arxiv.org/abs/2309.03882
-
[21]
AI@Meta, “Llama 3 model card,” 2024. [Online]. Available: https://github.com/meta-llama/llama3/blob/main/MODEL CARD.md
work page 2024
-
[22]
Llama-3.1-foundationai-securityllm-8b-instruct technical report,
S. Weerawardhena, P. Kassianik, B. Nelson, B. Saglam, A. Vellore, A. Priyanshu, S. Vijay, M. Aufiero, A. Goldblatt, F. Burch, E. Li, J. He, D. Kedia, K. Oshiba, Z. Yang, Y . Singer, and A. Karbasi, “Llama-3.1-foundationai-securityllm-8b-instruct technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2508.01059
-
[23]
AI@Meta, “Llama 3.1 8b model,” 2024. [Online]. Available: https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct
work page 2024
-
[24]
Large language models do multi-label classification differently,
M. Ma, G. Chochlakis, N. M. Pandiyan, J. Thomason, and S. Narayanan, “Large language models do multi-label classification differently,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Suzhou, China: Association for Computational Linguistics, Nov. 2025, pp. 2472–2495. [Online]. Available: https://aclanthology.org/2...
work page 2025
-
[25]
Security architecture and procedures for 5G system,
3rd Generation Partnership Project (3GPP), “Security architecture and procedures for 5G system,” Tech. Rep., TS 33.501, Release 19, 2025, version 19.2.0
work page 2025
-
[26]
Security Assurance Specification (SCAS) threats and critical assets in 3GPP network product classes,
——, “Security Assurance Specification (SCAS) threats and critical assets in 3GPP network product classes,” Tech. Rep., TS 33.926, Release 19, 2025, version 19.3.0
work page 2025
-
[27]
M. Bartocket al., “5G Cybersecurity,” National Institute of Standards and Technology, NIST Special Publication 800-33B, Apr. 2022. [Online]. Available: https://www.nccoe.nist.gov/sites/default/files/2022- 04/nist-5G-sp1800-33b-preliminary-draft.pdf
work page 2022
-
[28]
Study on Security for Next Radio (NR) Integrated Access and Backhaul (IAB) (Release 17),
3rd Generation Partnership Project (3GPP), “Study on Security for Next Radio (NR) Integrated Access and Backhaul (IAB) (Release 17),” Tech. Rep., TS 33.824, Release 17, 2022, version 17.0.0
work page 2022
-
[29]
AI@Meta, “Llama 3.2 3b model,” 2024. [Online]. Available: https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct
work page 2024
-
[30]
——, “Llama 3.2 1b model,” 2024. [Online]. Available: https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct
work page 2024
-
[31]
The effect of sampling temperature on problem solving in large language models,
M. Renze, “The effect of sampling temperature on problem solving in large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2024. Association for Computational Linguistics, Nov. 2024, pp. 7346–7356. [Online]. Available: https://aclanthology.org/2024.findings-emnlp.432/
work page 2024
-
[32]
Exploring the impact of temperature on large language models: Hot or cold?
L. Li, L. Sleem, G. Nichil, R. Stateet al., “Exploring the impact of temperature on large language models: Hot or cold?”Procedia Computer Science, vol. 264, pp. 242–251, 2025
work page 2025
-
[33]
The curious case of neural text degeneration,
A. Holtzman, J. Buys, L. Du, M. Forbes, and Y . Choi, “The curious case of neural text degeneration,” inInternational Conference on Learning Representations, 2020. [Online]. Available: https://openreview.net/forum?id=rygGQyrFvH
work page 2020
-
[34]
Hugging Face – The AI community building the future
“Hugging Face – The AI community building the future.” [Online]. Available: https://huggingface.co/
-
[35]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
work page 1901
-
[36]
M. Turpin, J. Michael, E. Perez, and S. Bowman, “Language models don’t always say what they think: Unfaithful explanations in chain- of-thought prompting,”Advances in Neural Information Processing Systems, vol. 36, pp. 74 952–74 965, 2023
work page 2023
-
[37]
Do large language models know what they don’t know?
Z. Yin, Q. Sun, Q. Guo, J. Wu, X. Qiu, and X. Huang, “Do large language models know what they don’t know?” inFindings of the Association for Computational Linguistics: ACL 2023, A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 8653–8665. [Online]. Available: https://aclanthology.org...
work page 2023
-
[38]
Better zero-shot reasoning with role-play prompting,
A. Kong, S. Zhao, H. Chen, Q. Li, Y . Qin, R. Sun, X. Zhou, E. Wang, and X. Dong, “Better zero-shot reasoning with role-play prompting,” in Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 4099–4113. IX. APPENDIX: FAILEDLLM OUTP...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.