Recognition: 2 theorem links
· Lean TheoremUnified Noise Steering for Efficient Human-Guided VLA Adaptation
Pith reviewed 2026-05-12 04:05 UTC · model grok-4.3
The pith
UniSteer inverts human corrective actions to noise targets to jointly steer RL updates in VLA adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
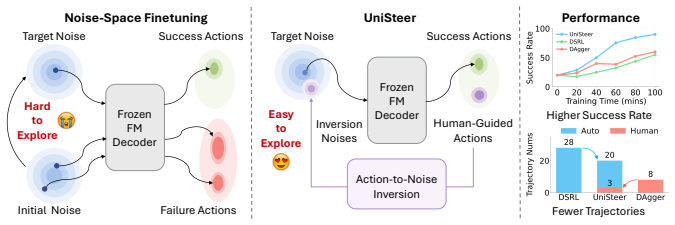
UniSteer recovers noise targets from human corrective actions by inverting the frozen flow-matching decoder, supplying supervised guidance to the same noise actor that is simultaneously optimized via reinforcement learning.
What carries the argument
approximate action-to-noise inversion of the frozen flow-matching decoder, which converts action-space corrections into noise-space supervision signals
If this is right
- The noise actor receives both environment rewards and human-derived supervision without altering the pretrained VLA.
- Human interventions directly reduce the exploration burden that otherwise slows noise-space RL.
- Real-world adaptation reaches 90 percent success in roughly one hour of interaction across varied manipulation tasks.
Where Pith is reading between the lines
- The inversion technique could transfer to other diffusion policies whose training occurs in latent noise space while feedback arrives in output space.
- Hybrid human-RL steering may shorten data collection for any latent-variable policy where approximate inversion of the decoder is feasible.
Load-bearing premise
The inversion of human corrective actions through the frozen decoder produces noise targets accurate enough that the resulting supervision improves rather than harms the joint RL optimization.
What would settle it
A controlled trial in which the inverted noise targets are replaced by random noise or omitted entirely, yet success rates and adaptation speed remain equal or higher than with UniSteer.
Figures






read the original abstract
Diffusion-based vision-language-action (VLA) models have emerged as strong priors for robotic manipulation, yet adapting them to real-world distributions remains challenging. In particular, on-robot reinforcement learning (RL) is expensive and time-consuming, so effective adaptation depends on efficient policy improvement within a limited budget of real-world interactions. Noise-space RL lowers the cost by keeping the pretrained VLA fixed as a denoising generator while updating only a lightweight actor that predicts the noise. However, its performance is still limited due to inefficient autonomous exploration. Human corrective interventions can reduce this exploration burden, but they are naturally provided in action space, whereas noise-space finetuning requires supervision over noise variables. To address these challenges, we propose UniSteer, a Unified Noise Steering framework that combines human corrective guidance with noise-space RL through approximate action-to-noise inversion. Given a human corrective action, UniSteer inverts the frozen flow-matching decoder to recover a noise target, which provides supervised guidance for the same noise actor that is simultaneously optimized via reinforcement learning. Real-world experiments on diverse manipulation tasks show that UniSteer adapts more efficiently than strong noise-space RL and action-space human-in-the-loop baselines, improving the success rate from 20% to 90% in 66 minutes on average across four real-world adaptation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UniSteer, a framework for efficient adaptation of diffusion-based vision-language-action (VLA) models. It augments noise-space RL (which updates only a lightweight noise actor while keeping the pretrained VLA fixed) with human corrective interventions by using an approximate inversion through the frozen flow-matching decoder to convert action-space corrections into noise targets for supervised updates to the same actor. Real-world experiments on four manipulation tasks report that this mixed supervision raises success rates from 20% to 90% in an average of 66 minutes, outperforming pure noise-space RL and action-space human-in-the-loop baselines.
Significance. If the inversion step reliably supplies beneficial rather than harmful supervision, the approach could meaningfully lower the real-world sample complexity of adapting large VLA priors by allowing sparse human guidance to steer noise-space optimization, addressing a practical bottleneck in robotic deployment.
major comments (3)
- [Method description of the inversion step] The central claim that human corrections, once inverted, improve the joint RL-plus-human objective rests on the unexamined accuracy of the approximate action-to-noise inversion of the frozen decoder. No error bounds, reconstruction metrics on held-out trajectories, or ablation measuring how inversion mismatch affects actor updates (especially when corrections lie outside current policy support) are provided, leaving open the risk that biased targets could stall or reverse adaptation.
- [Experiments section] Table or figure reporting real-world results: success-rate gains (20% to 90%) and the 66-minute average are stated without variance across runs, number of trials, statistical significance tests, or precise baseline implementations (e.g., how the action-space human-in-the-loop comparator interfaces with the noise actor or how inversion error was quantified in practice).
- [Experiments and ablation studies] No sensitivity analysis or ablation isolates the contribution of the inverted human supervision versus pure RL, nor tests performance when human corrections are deliberately noisy or distant from the current policy distribution, which would directly probe the load-bearing assumption identified in the skeptic note.
minor comments (2)
- [Preliminaries] Notation for the flow-matching decoder and the inversion operator could be introduced earlier and used consistently to improve readability of the mixed objective.
- [Abstract] The abstract and introduction would benefit from a brief statement of the inversion approximation error observed during training or validation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the manuscript to strengthen the presentation of the inversion analysis and experimental results.
read point-by-point responses
-
Referee: [Method description of the inversion step] The central claim that human corrections, once inverted, improve the joint RL-plus-human objective rests on the unexamined accuracy of the approximate action-to-noise inversion of the frozen decoder. No error bounds, reconstruction metrics on held-out trajectories, or ablation measuring how inversion mismatch affects actor updates (especially when corrections lie outside current policy support) are provided, leaving open the risk that biased targets could stall or reverse adaptation.
Authors: We agree that the original manuscript would benefit from a more explicit analysis of inversion accuracy. In the revised version we add reconstruction error metrics computed on held-out trajectories, together with an ablation that quantifies how inversion mismatch propagates to actor updates when corrections fall outside the current policy support. While the real-world results demonstrate consistent gains, we acknowledge that these new analyses will better bound the risk of biased supervision. revision: yes
-
Referee: [Experiments section] Table or figure reporting real-world results: success-rate gains (20% to 90%) and the 66-minute average are stated without variance across runs, number of trials, statistical significance tests, or precise baseline implementations (e.g., how the action-space human-in-the-loop comparator interfaces with the noise actor or how inversion error was quantified in practice).
Authors: We will expand the experimental reporting to include a detailed table listing per-task success rates with standard deviations across five independent runs, total interaction trials, and p-values from paired statistical tests. The revised text will also provide precise descriptions of baseline implementations, including the exact interface used by the action-space human-in-the-loop comparator with the noise actor and the practical procedure for quantifying inversion error during data collection. revision: yes
-
Referee: [Experiments and ablation studies] No sensitivity analysis or ablation isolates the contribution of the inverted human supervision versus pure RL, nor tests performance when human corrections are deliberately noisy or distant from the current policy distribution, which would directly probe the load-bearing assumption identified in the skeptic note.
Authors: We will add new ablation experiments that isolate the contribution of inverted human supervision by comparing UniSteer against pure noise-space RL and human-only baselines. In addition, we include sensitivity tests in which human corrections are deliberately corrupted with noise or sampled from distributions distant from the current policy; these results will directly evaluate the robustness of the inversion step under the conditions highlighted by the referee. revision: yes
Circularity Check
No significant circularity; inversion is an explicit algorithmic bridge
full rationale
The paper's core mechanism is an explicit approximate action-to-noise inversion applied to the frozen flow-matching decoder, used to generate supervision targets for the noise actor that is jointly optimized with RL. This inversion is presented as a new, independent algorithmic step rather than a quantity defined in terms of the target success rates, fitted parameters from the adaptation tasks, or the final performance metric. Empirical results (success rate lift from 20% to 90% in 66 minutes) are obtained from separate real-world experiments on four manipulation tasks and do not reduce to the method definition by construction. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the central claim are present.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The frozen flow-matching decoder can be approximately inverted to recover a noise target from a human corrective action
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
approximate action-to-noise inversion... fixed-point iteration... contractive map gy(x) = y - Δt vθ(x, tk, s)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
noise-space finetuning... frozen FM Decoder... unified RL + demo buffers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
work page 2023
-
[3]
Vima: General robot manipulation with multimodal prompts
Y Zhu et al. Vima: General robot manipulation with multimodal prompts. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[4]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Universal actions for enhanced embodied foundation models
Jinliang Zheng, Jianxiong Li, Dongxiu Liu, Yinan Zheng, Zhihao Wang, Zhonghong Ou, Yu Liu, Jingjing Liu, Ya-Qin Zhang, and Xianyuan Zhan. Universal actions for enhanced embodied foundation models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22508–22519, 2025
work page 2025
-
[7]
Vlas: Vision-language-action model with speech instructions for customized robot manipulation,
Wei Zhao, Pengxiang Ding, Min Zhang, Zhefei Gong, Shuanghao Bai, Han Zhao, and Donglin Wang. Vlas: Vision-language-action model with speech instructions for customized robot manipulation.arXiv preprint arXiv:2502.13508, 2025
-
[8]
Villa-x: enhancing latent action modeling in vision-language-action models,
Xiaoyu Chen, Hangxing Wei, Pushi Zhang, Chuheng Zhang, Kaixin Wang, Yanjiang Guo, Rushuai Yang, Yucen Wang, Xinquan Xiao, Li Zhao, et al. Villa-x: enhancing latent action modeling in vision-language-action models.arXiv preprint arXiv:2507.23682, 2025
-
[9]
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. Up-vla: A unified understanding and prediction model for embodied agent.arXiv preprint arXiv:2501.18867, 2025
-
[10]
Chatvla: Unified multimodal understanding and robot control with vision-language-action model, 2025
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2502.14420, 2025
-
[11]
Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models
Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiangnan Wu, Yan Huang, Liang Wang, Tao Kong, and Tieniu Tan. Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models.arXiv preprint arXiv:2506.07961, 2025
-
[12]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
work page 2024
-
[14]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control. corr, abs/2410.24164, 2024. doi: 10.48550.arXiv preprint ARXIV .2410.24164, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
π0.5: a vision-language-action model with open-world generalization,
Physical Intelligence. π0.5: a vision-language-action model with open-world generalization,
-
[16]
URLhttps://arxiv.org/abs/2504.16054
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review arXiv 2025
-
[21]
Dexgraspvla: A vision-language- action framework towards general dexterous grasping,
Yifan Zhong, Xuchuan Huang, Ruochong Li, Ceyao Zhang, Zhang Chen, Tianrui Guan, Fanlian Zeng, Ka Num Lui, Yuyao Ye, Yitao Liang, et al. Dexgraspvla: A vision-language-action framework towards general dexterous grasping.arXiv preprint arXiv:2502.20900, 2025
-
[22]
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855, 2025
work page Pith review arXiv 2025
-
[23]
Gu Zhang, Qicheng Xu, Haozhe Zhang, Jianhan Ma, Long He, Yiming Bao, Zeyu Ping, Zhecheng Yuan, Chenhao Lu, Chengbo Yuan, et al. Unidex: A robot foundation suite for uni- versal dexterous hand control from egocentric human videos.arXiv preprint arXiv:2603.22264, 2026
-
[24]
Guangqi Jiang, Yutong Liang, Jianglong Ye, Jia-Yang Huang, Changwei Jing, Rocky Duan, Pieter Abbeel, Xiaolong Wang, and Xueyan Zou. Cross-hand latent representation for vision- language-action models.arXiv preprint arXiv:2603.10158, 2026
-
[25]
Yuhui Chen, Shuai Tian, Shugao Liu, Yingting Zhou, Haoran Li, and Dongbin Zhao. Con- rft: A reinforced fine-tuning method for vla models via consistency policy.arXiv preprint arXiv:2502.05450, 2025
-
[26]
Steering your diffusion policy with latent space reinforcement learning
Andrew Wagenmaker, Mitsuhiko Nakamoto, Yunchu Zhang, Seohong Park, Waleed Yagoub, Anusha Nagabandi, Abhishek Gupta, and Sergey Levine. Steering your diffusion policy with latent space reinforcement learning.arXiv preprint arXiv:2506.15799, 2025
-
[27]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. π∗ 0.6: A VLA That Learns From Experience.arXiv preprint arXiv:2511.14759, 2025
work page Pith review arXiv 2025
-
[28]
Interactive post-training for vision-language- action models, 2025
Shuhan Tan, Kairan Dou, Yue Zhao, and Philipp Krähenbühl. Interactive post-training for vision-language-action models.arXiv preprint arXiv:2505.17016, 2025
-
[29]
Guanxing Lu, Wenkai Guo, Chubin Zhang, Yuheng Zhou, Haonan Jiang, Zifeng Gao, Yansong Tang, and Ziwei Wang. Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning.arXiv preprint arXiv:2505.18719, 2025
-
[30]
Hongyin Zhang, Zifeng Zhuang, Han Zhao, Pengxiang Ding, Hongchao Lu, and Donglin Wang. Reinbot: Amplifying robot visual-language manipulation with reinforcement learning.arXiv preprint arXiv:2505.07395, 2025
-
[31]
Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, et al. Rlinf-vla: A unified and efficient framework for vla+ rl training.arXiv preprint arXiv:2510.06710, 2025. 11
-
[32]
Improving vision-language-action model with online reinforcement learning
Yanjiang Guo, Jianke Zhang, Xiaoyu Chen, Xiang Ji, Yen-Jen Wang, Yucheng Hu, and Jianyu Chen. Improving vision-language-action model with online reinforcement learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15665–15672. IEEE, 2025
work page 2025
-
[33]
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
work page internal anchor Pith review arXiv 2025
-
[34]
Yunfei Li, Xiao Ma, Jiafeng Xu, Yu Cui, Zhongren Cui, Zhigang Han, Liqun Huang, Tao Kong, Yuxiao Liu, Hao Niu, et al. Gr-rl: Going dexterous and precise for long-horizon robotic manipulation.arXiv preprint arXiv:2512.01801, 2025
-
[35]
Piaopiao Jin, Qi Wang, Guokang Sun, Ziwen Cai, Pinjia He, and Yangwei You. Dual-actor fine-tuning of vla models: A talk-and-tweak human-in-the-loop approach.arXiv preprint arXiv:2509.13774, 2025
-
[36]
Srpo: Self-referential policy optimization for vision-language-action models,
Senyu Fei, Siyin Wang, Li Ji, Ao Li, Shiduo Zhang, Liming Liu, Jinlong Hou, Jingjing Gong, Xianzhong Zhao, and Xipeng Qiu. Srpo: Self-referential policy optimization for vision- language-action models.arXiv preprint arXiv:2511.15605, 2025
-
[37]
You've Got a Golden Ticket: Improving Generative Robot Policies With A Single Noise Vector
Omkar Patil, Ondrej Biza, Thomas Weng, Karl Schmeckpeper, Wil Thomason, Xiaohan Zhang, Robin Walters, Nakul Gopalan, Sebastian Castro, and Eric Rosen. You’ve got a golden ticket: Improving generative robot policies with a single noise vector.arXiv preprint arXiv:2603.15757, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth interna- tional conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
work page 2011
-
[39]
Hg- dagger: Interactive imitation learning with human experts
Michael Kelly, Chelsea Sidrane, Katherine Driggs-Campbell, and Mykel J Kochenderfer. Hg- dagger: Interactive imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), pages 8077–8083. IEEE, 2019
work page 2019
-
[40]
Zheyuan Hu, Robyn Wu, Naveen Enock, Jasmine Li, Riya Kadakia, Zackory Erickson, and Aviral Kumar. Rac: Robot learning for long-horizon tasks by scaling recovery and correction. arXiv preprint arXiv:2509.07953, 2025
-
[41]
Guanxing Lu, Rui Zhao, Haitao Lin, He Zhang, and Yansong Tang. Human-in-the-loop online rejection sampling for robotic manipulation.arXiv preprint arXiv:2510.26406, 2025
-
[42]
Jianlan Luo, Charles Xu, Jeffrey Wu, and Sergey Levine. Precise and dexterous robotic manip- ulation via human-in-the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
work page 2025
-
[43]
Wenke Xia, Yichu Yang, Hongtao Wu, Xiao Ma, Tao Kong, and Di Hu. Human-assisted robotic policy refinement via action preference optimization.arXiv preprint arXiv:2506.07127, 2025
-
[44]
The Principles of Diffusion Models,
Chieh-Hsin Lai, Yang Song, Dongjun Kim, Yuki Mitsufuji, and Stefano Ermon. The principles of diffusion models.arXiv preprint arXiv:2510.21890, 2025
-
[45]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[46]
Dita: Scaling diffusion transformer for generalist vision-language-action policy
Zhi Hou, Tianyi Zhang, Yuwen Xiong, Haonan Duan, Hengjun Pu, Ronglei Tong, Chengyang Zhao, Xizhou Zhu, Yu Qiao, Jifeng Dai, et al. Dita: Scaling diffusion transformer for generalist vision-language-action policy. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7686–7697, 2025
work page 2025
-
[47]
arXiv preprint arXiv:2412.03293 , year=
Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chaomin Shen, et al. Diffusion-vla: Generalizable and interpretable robot foundation model via self-generated reasoning.arXiv preprint arXiv:2412.03293, 2024. 12
-
[48]
Flow matching policy gradients.arXiv preprint arXiv:2507.21053,
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
-
[49]
Zhian Su, Weijie Kong, Haonan Dong, and Huixu Dong. Ig-rft: An interaction-guided rl frame- work for vla models in long-horizon robotic manipulation.arXiv preprint arXiv:2602.20715, 2026
-
[50]
Rushuai Yang, Hecheng Wang, Chiming Liu, Xiaohan Yan, Yunlong Wang, Xuan Du, Shuoyu Yue, Yongcheng Liu, Chuheng Zhang, Lizhe Qi, et al. Aloe: Action-level off-policy evaluation for vision-language-action model post-training.arXiv preprint arXiv:2602.12691, 2026
-
[51]
ARM: Advantage Reward Modeling for Long-Horizon Manipulation
Yiming Mao, Zixi Yu, Weixin Mao, Yinhao Li, Qirui Hu, Zihan Lan, Minzhao Zhu, and Hua Chen. Arm: Advantage reward modeling for long-horizon manipulation.arXiv preprint arXiv:2604.03037, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Wenli Xiao, Haotian Lin, Andy Peng, Haoru Xue, Tairan He, Yuqi Xie, Fengyuan Hu, Jimmy Wu, Zhengyi Luo, Linxi Fan, et al. Self-improving vision-language-action models with data generation via residual rl.arXiv preprint arXiv:2511.00091, 2025
-
[53]
RL Token: Bootstrapping Online RL with Vision-Language-Action Models
Charles Xu, Jost Tobias Springenberg, Michael Equi, Ali Amin, Adnan Esmail, Sergey Levine, and Liyiming Ke. Rl token: Bootstrapping online rl with vision-language-action models, 2026. URLhttps://arxiv.org/abs/2604.23073. 13 A Theoretical Analysis and Proofs A.1 Invertibility of the Continuous Flow Decoder Setup and statement.For a fixed states, consider t...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
=a , then the reverse-time ODE from the same terminal value a has a unique solution, so the recovered initial values must coincide: z0 =z ′
-
[55]
Therefore, Gθ(s,·) is bijective. □ A.2 One-Step Fixed-Point Inversion Setup.We analyze the inverse of one Euler step of the frozen flow decoder. The forward step, inverse equation, and associated fixed-point map are y=x+ ∆t v θ(x, tk, s), x=y−∆t v θ(x, tk, s), gy(x) :=y−∆t v θ(x, tk, s). Proposition A.2.Assume that vθ(·, tk, s) is L-Lipschitz and ∆tL <1 ....
work page 2055
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.