Recognition: 2 theorem links
· Lean TheoremARM: Advantage Reward Modeling for Long-Horizon Manipulation
Pith reviewed 2026-05-13 19:21 UTC · model grok-4.3
The pith
Advantage Reward Modeling uses simple relative labels to guide long-horizon robot policies without dense rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
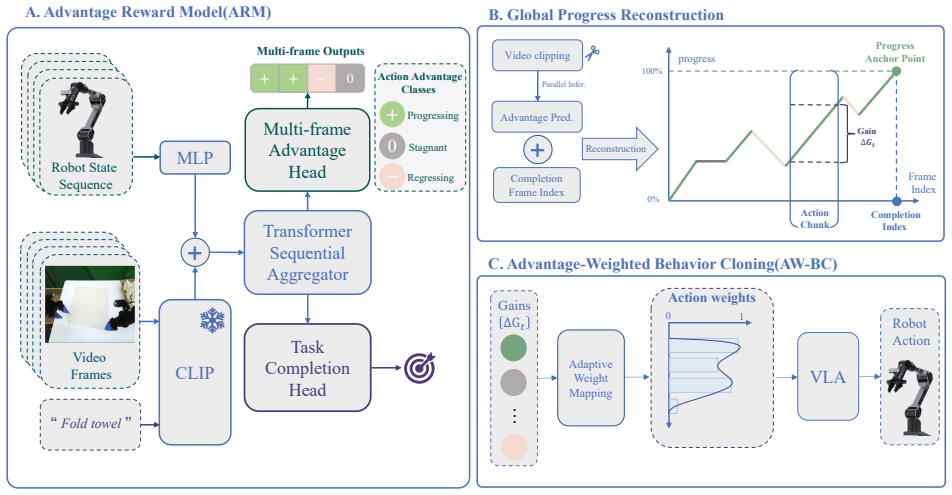
We propose Advantage Reward Modeling (ARM), a framework that shifts from hard-to-quantify absolute progress to estimating relative advantage. We introduce a cost-effective tri-state labeling strategy -- Progressive, Regressive, and Stagnant -- that reduces human cognitive overhead while ensuring high cross-annotator consistency. By training on these intuitive signals, ARM enables automated progress annotation for both complete demonstrations and fragmented DAgger-style data. Integrating ARM into an offline RL pipeline allows for adaptive action-reward reweighting, effectively filtering suboptimal samples. Our approach achieves a 99.4% success rate on a challenging long-horizon towel-folding,
What carries the argument
Tri-state labeling strategy (Progressive, Regressive, Stagnant) that supplies relative advantage signals for training a reward model used in offline RL reweighting.
Load-bearing premise
The three intuitive labels supply enough unbiased signal to estimate advantage accurately on both full demonstrations and partial interactive data without introducing systematic credit-assignment errors.
What would settle it
A controlled test in which reward models trained on tri-state labels produce advantage estimates that fail to improve policy success rates over unweighted baselines on the same towel-folding task or on a new long-horizon manipulation benchmark.
Figures






read the original abstract
Long-horizon robotic manipulation remains challenging for reinforcement learning (RL) because sparse rewards provide limited guidance for credit assignment. Practical policy improvement thus relies on richer intermediate supervision, such as dense progress rewards, which are costly to obtain and ill-suited to non-monotonic behaviors such as backtracking and recovery. To address this, we propose Advantage Reward Modeling (ARM), a framework that shifts from hard-to-quantify absolute progress to estimating relative advantage. We introduce a cost-effective tri-state labeling strategy -- Progressive, Regressive, and Stagnant -- that reduces human cognitive overhead while ensuring high cross-annotator consistency. By training on these intuitive signals, ARM enables automated progress annotation for both complete demonstrations and fragmented DAgger-style data. Integrating ARM into an offline RL pipeline allows for adaptive action-reward reweighting, effectively filtering suboptimal samples. Our approach achieves a 99.4% success rate on a challenging long-horizon towel-folding task, demonstrating improved stability and data efficiency over current VLA baselines with near-zero human intervention during policy training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Advantage Reward Modeling (ARM) to improve credit assignment in long-horizon robotic manipulation under sparse rewards. Instead of dense absolute progress signals, ARM uses a tri-state labeling scheme (Progressive, Regressive, Stagnant) to estimate relative advantage. These labels train an annotator that automatically labels both complete demonstrations and fragmented DAgger-style trajectories; the resulting advantage estimates are integrated into an offline RL pipeline for adaptive action reweighting. The method is evaluated on a towel-folding task, where it reports a 99.4% success rate together with gains in stability and data efficiency over VLA baselines and near-zero human intervention during policy training.
Significance. If the empirical claims and the generalization of the tri-state labels hold, ARM would offer a practical route to scaling offline RL for non-monotonic manipulation tasks by lowering labeling cost and mitigating credit-assignment errors that arise with absolute progress rewards. The automated handling of DAgger fragments is potentially valuable for real-world data collection pipelines.
major comments (3)
- [§3.2] §3.2 (Tri-state labeling): The definition of Progressive/Regressive/Stagnant labels is given for complete demonstrations, yet the text asserts that the same model automatically annotates fragmented DAgger rollouts. No quantitative comparison of label distributions or credit-assignment accuracy between the two data regimes is reported, leaving open the possibility that locally regressive recovery actions in towel folding receive negative advantage and are down-weighted.
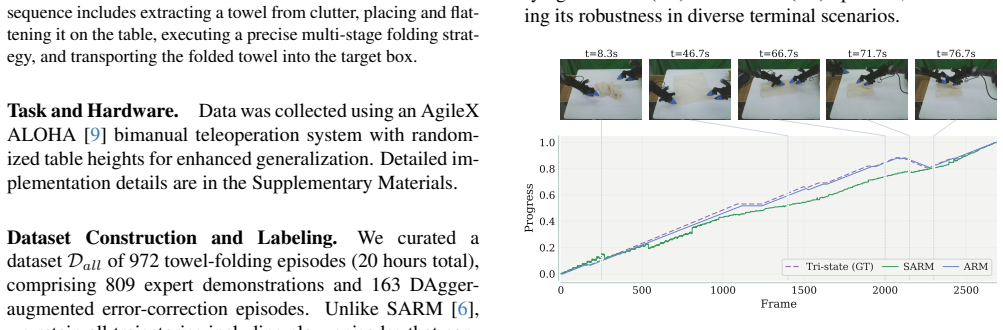
- [§4.2] §4.2 (Experimental results): The 99.4% success rate is presented without the number of evaluation trials, standard deviation across seeds, statistical tests against baselines, or ablation results that isolate the contribution of the advantage reweighting step versus the underlying VLA policy.
- [§4.3] §4.3 (Ablations): No ablation is shown that measures the effect of replacing the tri-state advantage model with a binary success/failure label or with a learned dense progress reward, making it impossible to assess whether the claimed stability and data-efficiency gains are attributable to the proposed labeling strategy.
minor comments (2)
- [§3.1] The notation for advantage estimation (e.g., how the tri-state probabilities are converted into scalar rewards) is introduced in prose without an accompanying equation; adding a compact definition would improve clarity.
- [Figure 3] Figure 3 (labeling interface) would benefit from an explicit example of a non-monotonic recovery sequence and its assigned tri-state labels.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each of the major comments point by point below, and we will incorporate the suggested changes in the revised version.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Tri-state labeling): The definition of Progressive/Regressive/Stagnant labels is given for complete demonstrations, yet the text asserts that the same model automatically annotates fragmented DAgger rollouts. No quantitative comparison of label distributions or credit-assignment accuracy between the two data regimes is reported, leaving open the possibility that locally regressive recovery actions in towel folding receive negative advantage and are down-weighted.
Authors: We agree that a quantitative comparison between the two data regimes would strengthen the presentation. In the revised manuscript, we will add a new subsection or figure in §3.2 that reports the label distributions (percentages of Progressive, Regressive, Stagnant) for both complete demonstrations and DAgger fragments. We will also include qualitative examples showing how recovery actions in towel folding are labeled as Progressive when they contribute to task progress. This should clarify that the model does not indiscriminately assign negative advantage to useful recovery behaviors. revision: yes
-
Referee: [§4.2] §4.2 (Experimental results): The 99.4% success rate is presented without the number of evaluation trials, standard deviation across seeds, statistical tests against baselines, or ablation results that isolate the contribution of the advantage reweighting step versus the underlying VLA policy.
Authors: We will revise §4.2 to include the missing details: specifically, we will report that the 99.4% success rate is based on 100 evaluation trials, provide standard deviations computed over 5 independent random seeds, and include statistical significance tests (e.g., Wilcoxon signed-rank test) comparing ARM to the VLA baselines. Additionally, we will add an ablation that compares the full ARM pipeline against the VLA policy without the advantage reweighting step to isolate its contribution. revision: yes
-
Referee: [§4.3] §4.3 (Ablations): No ablation is shown that measures the effect of replacing the tri-state advantage model with a binary success/failure label or with a learned dense progress reward, making it impossible to assess whether the claimed stability and data-efficiency gains are attributable to the proposed labeling strategy.
Authors: We acknowledge the value of these additional ablations. In the revised §4.3, we will include experiments replacing the tri-state model with (i) a binary success/failure label and (ii) a learned dense progress reward model. We will report the resulting success rates, stability (variance in performance), and data efficiency metrics for each variant, allowing readers to directly assess the benefits of the tri-state advantage modeling approach. revision: yes
Circularity Check
No circularity: advantage modeling reduces to standard supervised labeling plus offline RL reweighting
full rationale
The paper presents ARM as a tri-state labeling scheme (Progressive/Regressive/Stagnant) applied to demonstrations, followed by training a model to annotate new fragments and reweighting actions in an offline RL pipeline. No equations are supplied that define the advantage estimator in terms of itself or that rename a fitted parameter as a prediction. The tri-state labels are human-provided inputs; the subsequent model is a conventional supervised predictor whose outputs are then used for reweighting. No self-citation chain, uniqueness theorem, or ansatz smuggling is invoked in the supplied text to close the derivation. The framework therefore remains non-circular; any performance claims rest on empirical validation rather than definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tri-state labels accurately reflect relative advantage for credit assignment
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe introduce a cost-effective tri-state labeling strategy—Progressive, Regressive, and Stagnant—that reduces human cognitive overhead while ensuring high cross-annotator consistency.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclearAdvantage-Weighted Behavior Cloning (AW-BC) ... maximizing the expected return of the policy under the constraint of remaining close to the behavior policy
Forward citations
Cited by 1 Pith paper
-
Unified Noise Steering for Efficient Human-Guided VLA Adaptation
UniSteer unifies human corrective actions and noise-space RL for VLA adaptation by inverting actions to noise targets, raising success rates from 20% to 90% in 66 minutes across four real-world manipulation tasks.
Reference graph
Works this paper leans on
-
[1]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 1, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision-language- action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manip- ulation platform for scalable and intelligent embodied sys- tems.arXiv preprint arXiv:2503.06669, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Lerobot: State-of- the-art machine learning for real-world robotics in pytorch
Remi Cadene, Simon Alibert, Alexander Soare, Quentin Gallouedec, Adil Zouitine, Steven Palma, Pepijn Kooij- mans, Michel Aractingi, Mustafa Shukor, Dana Aubakirova, Martino Russi, Francesco Capuano, Caroline Pascal, Jade Choghari, Jess Moss, and Thomas Wolf. Lerobot: State-of- the-art machine learning for real-world robotics in pytorch. https : / / github...
-
[5]
Letian Chen, Nina Marie Moorman, and Matthew Craig Gombolay. ELEMENTAL: Interactive learning from demon- strations and vision-language models for reward design in robotics. InForty-second International Conference on Ma- chine Learning, 2025. 3
work page 2025
-
[6]
Sarm: Stage-aware reward modeling for long horizon robot manipulation, 2025
Qianzhong Chen, Justin Yu, Mac Schwager, Pieter Abbeel, Yide Shentu, and Philipp Wu. Sarm: Stage-aware reward modeling for long horizon robot manipulation, 2025. 1, 2, 3, 6, 7
work page 2025
-
[7]
Ratliff, Jiafei Duan, Dieter Fox, and Ranjay Krishna
Shirui Chen, Cole Harrison, Ying-Chun Lee, Angela Jin Yang, Zhongzheng Ren, Lillian J. Ratliff, Jiafei Duan, Dieter Fox, and Ranjay Krishna. Topreward: Token probabilities as hidden zero-shot rewards for robotics, 2026. 3
work page 2026
-
[8]
Deep reinforcement learn- ing from human preferences
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learn- ing from human preferences. InAdvances in Neural Infor- mation Processing Systems. Curran Associates, Inc., 2017. 2
work page 2017
-
[9]
Zipeng Fu, Tony Z Zhao, and Chelsea Finn. Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation.arXiv preprint arXiv:2401.02117,
-
[10]
Chengkai Hou et al. Robomind 2.0: A multimodal, biman- ual mobile manipulation dataset for generalizable embodied intelligence.arXiv preprint arXiv:2512.24653, 2025. 1
-
[11]
Zheyuan Hu, Robyn Wu, Naveen Enock, Jasmine Li, Riya Kadakia, Zackory Erickson, and Aviral Kumar. Rac: Robot learning for long-horizon tasks by scaling recovery and cor- rection.arXiv preprint arXiv:2509.07953, 2025. 2
-
[12]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ash- win Balakrishna, Kevin Black, Ken Conley, Grace Con- nors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. π∗ 0.6: A VLA that learns from experience.arXiv preprint arXiv:2511.14759, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Gal- liker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pert...
work page 2025
-
[14]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ash- win Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yun- liang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Fos- ter, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kol- lar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.0924...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Offline re- inforcement learning with implicit q-learning, 2021
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline re- inforcement learning with implicit q-learning, 2021. 3
work page 2021
-
[17]
Roboreward: General- purpose vision-language reward models for robotics, 2026
Tony Lee, Andrew Wagenmaker, Karl Pertsch, Percy Liang, Sergey Levine, and Chelsea Finn. Roboreward: General- purpose vision-language reward models for robotics, 2026. 3
work page 2026
-
[18]
Yunfei Li, Xiao Ma, Jiafeng Xu, Yu Cui, Zhongren Cui, Zhi- gang Han, Liqun Huang, Tao Kong, Yuxiao Liu, Hao Niu, et al. Gr-rl: Going dexterous and precise for long-horizon robotic manipulation.arXiv preprint arXiv:2512.01801,
-
[19]
Anthony Liang, Yigit Korkmaz, Jiahui Zhang, Minyoung Hwang, Abrar Anwar, Sidhant Kaushik, Aditya Shah, Alex S Huang, Luke Zettlemoyer, Dieter Fox, et al. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons.arXiv preprint arXiv:2603.02115, 2026. 1
-
[20]
Focal loss for dense object detection, 2018
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection, 2018. 4
work page 2018
-
[21]
arXiv preprint arXiv:2210.00030 , year=
Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Os- bert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training.arXiv preprint arXiv:2210.00030, 2022. 2, 3
-
[22]
Liv: Language-image represen- tations and rewards for robotic control
Yecheng Jason Ma, Vikash Kumar, Amy Zhang, Osbert Bas- tani, and Dinesh Jayaraman. Liv: Language-image represen- tations and rewards for robotic control. InInternational Con- ference on Machine Learning, pages 23301–23320. PMLR,
-
[23]
Vision language models are in-context value learners, 2024
Yecheng Jason Ma, Joey Hejna, Ayzaan Wahid, Chuyuan Fu, Dhruv Shah, Jacky Liang, Zhuo Xu, Sean Kirmani, Peng Xu, Danny Driess, Ted Xiao, Jonathan Tompson, Osbert Bas- tani, Dinesh Jayaraman, Wenhao Yu, Tingnan Zhang, Dorsa 9 Sadigh, and Fei Xia. Vision language models are in-context value learners, 2024. 1, 3
work page 2024
-
[24]
Awac: Accelerating online reinforcement learning with offline datasets, 2021
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online reinforcement learning with offline datasets, 2021. 3
work page 2021
-
[25]
Andrew Y . Ng and Stuart J. Russell. Algorithms for in- verse reinforcement learning. InProceedings of the Seven- teenth International Conference on Machine Learning, page 663–670, San Francisco, CA, USA, 2000. Morgan Kauf- mann Publishers Inc. 2
work page 2000
-
[26]
Andrew Bagnell, Pieter Abbeel, and Jan Peters
Takayuki Osa, Joni Pajarinen, Gerhard Neumann, J. Andrew Bagnell, Pieter Abbeel, and Jan Peters. An algorithmic per- spective on imitation learning.Foundations and Trends® in Robotics, 7(1–2):1–179, 2018. 1
work page 2018
-
[27]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Ab- hishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Poo- ley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024. 1
work page 2024
-
[28]
Advantage-weighted regression: Simple and scal- able off-policy reinforcement learning, 2019
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scal- able off-policy reinforcement learning, 2019. 3, 5
work page 2019
-
[29]
QwenLM. Qwen3-vl.https : / / github . com / QwenLM/Qwen3-VL, 2025. GitHub repository, accessed 2025-11-09. 6
work page 2025
-
[30]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. 4
work page 2021
-
[31]
Stephane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning, 2011. 2
work page 2011
-
[32]
Sumedh Sontakke, Jesse Zhang, Séb Arnold, Karl Pertsch, Erdem Bıyık, Dorsa Sadigh, Chelsea Finn, and Laurent Itti. Roboclip: One demonstration is enough to learn robot poli- cies.Advances in Neural Information Processing Systems, 36:55681–55693, 2023. 1
work page 2023
-
[33]
MIT press, second edition, 2018
Richard S Sutton and Andrew G Barto.Reinforcement learn- ing: An introduction. MIT press, second edition, 2018. 1
work page 2018
-
[34]
Robo-dopamine: General process reward modeling for high-precision robotic manipulation, 2025
Huajie Tan, Sixiang Chen, Yijie Xu, Zixiao Wang, Yuheng Ji, Cheng Chi, Yaoxu Lyu, Zhongxia Zhao, Xiansheng Chen, Peterson Co, Shaoxuan Xie, Guocai Yao, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Robo-dopamine: General process reward modeling for high-precision robotic manipulation, 2025. 1, 3
work page 2025
-
[35]
Bridgedata v2: A dataset for robot learning at scale, 2024
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen- Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, and Sergey Levine. Bridgedata v2: A dataset for robot learning at scale, 2024. 1
work page 2024
-
[36]
Robomind: Benchmark on multi- embodiment intelligence normative data for robot manipula- tion
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xi- aozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, et al. Robomind: Benchmark on multi- embodiment intelligence normative data for robot manipula- tion. InRobotics: Science and Systems, 2025. 1
work page 2025
-
[37]
Large reward models: Generalizable online robot reward generation with vision-language models,
Yanru Wu, Weiduo Yuan, Ang Qi, Vitor Guizilini, Jiageng Mao, and Yue Wang. Large reward models: Generalizable online robot reward generation with vision-language models,
-
[38]
Shaopeng Zhai, Qi Zhang, Tianyi Zhang, Fuxian Huang, Haoran Zhang, Ming Zhou, Shengzhe Zhang, Litao Liu, Sixu Lin, and Jiangmiao Pang. A vision-language-action-critic model for robotic real-world reinforcement learning.arXiv preprint arXiv:2509.15937, 2025. 2
-
[39]
Rewind: Language-guided rewards teach robot policies without new demonstrations, 2025
Jiahui Zhang, Yusen Luo, Abrar Anwar, Sumedh Anand Sontakke, Joseph J Lim, Jesse Thomason, Erdem Biyik, and Jesse Zhang. Rewind: Language-guided rewards teach robot policies without new demonstrations, 2025. 1, 3 10 Author Contributions Yiming Maois the primary architect of the ARM frame- work and spearheaded its development from the ground up. He designe...
work page 2025
-
[40]
Extracting exactly one towel from an unstructured, clut- tered pile
-
[41]
Placing it onto the central tabletop
-
[42]
Flattening the towel to a planar initial state
-
[43]
Performing a bottom-to-up longitudinal fold
-
[44]
Executing a top-to-bottom longitudinal fold
-
[45]
Conducting a right-to-center lateral fold
-
[46]
Completing the sequence with a left-to-right lateral fold to form a compact rectangle
-
[47]
Transporting and depositing the folded towel fully inside a target storage box on the left. The effective prompt is: # Role You are a Robotics Vision System specializing in temporal action localization for robot manipulation. Your job is to segment a single demonstration video into distinct, non-overlapping atomic actions from a fixed label list. # Label ...
-
[48]
The full video from “00:00” to the final timestamp must be covered without gaps
-
[49]
The end timestamp of one stage must equal the start timestamp of the next stage
-
[50]
Each stage appears exactly once and in logical order
-
[51]
Uniform or near-uniform segmentation should be avoided unless the video genuinely supports it
-
[52]
MM:SS” format; the first stage starts at “00:00
Timestamps must be in “MM:SS” format; the first stage starts at “00:00”. # Step 1 -- Textual Timeline First, write a detailed textual timeline with approximate timestamps. For each stage, include its name, approximate start and end time, and the visual event that defines the boundary. # Step 2 -- Structured Output Then output only valid JSON consistent wi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.