Recognition: 2 theorem links
· Lean TheoremThe First Drop of Ink: Nonlinear Impact of Misleading Information in Long-Context Reasoning
Pith reviewed 2026-05-12 03:39 UTC · model grok-4.3
The pith
A small proportion of misleading documents causes most of the performance drop in long-context language model reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
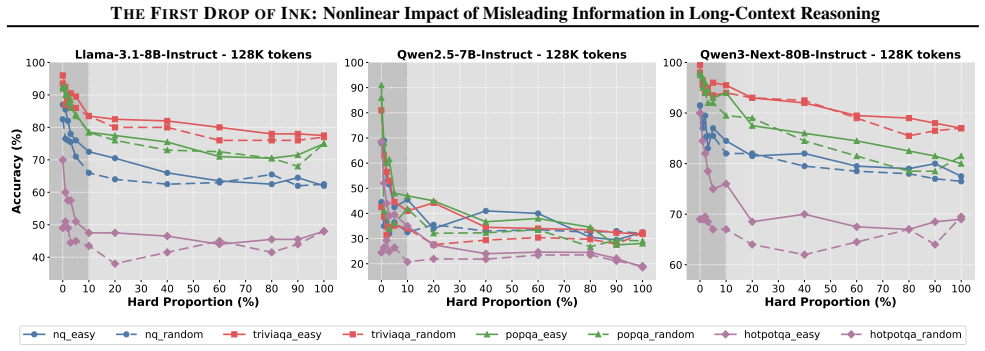
As the proportion of hard distractors increases in fixed-length contexts, performance drops sharply within the first small fraction, while the remainder of the range yields only marginal additional decline. Hard distractors capture disproportionate attention even at small proportions, with diminishing marginal impact as their proportion grows. Filtering gains come mainly from context-length reduction rather than distractor removal, and substantial recovery requires reducing the hard-distractor proportion to near zero.
What carries the argument
The First Drop of Ink effect, which describes the nonlinear performance degradation caused by hard distractors capturing disproportionate attention at low proportions.
If this is right
- Filtering gains come mainly from shortening overall context length rather than from removing the distractors themselves.
- Substantial performance recovery requires bringing the hard-distractor proportion close to zero.
- Attention mechanisms allocate disproportionate focus to semantically relevant misleading content even when that content is rare.
- Upstream retrieval systems must achieve high precision to keep hard distractors out of the context.
Where Pith is reading between the lines
- Retrieval pipelines may need to favor precision over recall to avoid introducing even small numbers of hard distractors.
- The effect could compound in multi-turn agent workflows where context accumulates across steps.
- Models might be trained or prompted to down-weight content that is semantically close but factually inconsistent.
Load-bearing premise
That the controlled construction of hard distractors isolates their misleading effect without introducing uncontrolled changes in task difficulty or attention behavior.
What would settle it
If performance declines linearly rather than sharply at low proportions when the same models are tested on naturally retrieved documents instead of synthetically inserted hard distractors, the nonlinear pattern would be falsified.
Figures







read the original abstract
As large language models are increasingly deployed in retrieval-augmented generation and agentic systems that accumulate extensive context, understanding how distracting information affects long-context performance becomes critical. Prior work shows that semantically relevant yet misleading documents degrade performance, but the quantitative relationship between the proportion of distractors and performance remains unstudied. In this work, we systematically vary the hard-distractor proportion in fixed-length contexts, revealing a striking nonlinear pattern: as the proportion of hard distractors increases, performance drops sharply within the first small fraction, while the remainder of the range yields only marginal additional decline. We term this ''The First Drop of Ink'' effect, analogous to how a single drop of ink contaminates water. Our theoretical and empirical analyses grounded in attention mechanics show that hard distractors capture disproportionate attention even at small proportions, with diminishing marginal impact as their proportion grows. Controlled experiments further show that filtering gains mainly come from context-length reduction rather than distractor removal; substantial recovery requires reducing the hard-distractor proportion to near zero, highlighting the importance of upstream retrieval precision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in fixed-length long contexts for LLM reasoning, increasing the proportion of hard distractors (semantically relevant but misleading documents) produces a nonlinear 'First Drop of Ink' effect: performance drops sharply at small proportions and then flattens, explained by hard distractors capturing disproportionate attention even at low densities. This is supported by theoretical attention analysis and controlled experiments showing that filtering gains come mainly from context-length reduction rather than distractor removal, with substantial recovery only when hard-distractor proportion approaches zero.
Significance. If the central nonlinear pattern and attention-based mechanism hold after controlling for confounds, the result would be significant for retrieval-augmented generation and long-context systems, as it implies that even small fractions of misleading content can be disproportionately damaging and that upstream retrieval precision is critical. The attention-grounded explanation offers a concrete mechanistic account that could inform model design.
major comments (1)
- [Experimental Setup] Experimental Setup (fixed-length context construction): Raising the hard-distractor proportion in fixed-length contexts necessarily reduces the count or density of relevant documents. This signal reduction alone can generate a steep early performance drop (loss of the first few critical pieces) followed by diminishing marginal losses, independent of any attention-capture mechanism. The theoretical and empirical attention analyses must therefore either hold relevant content constant across proportions or provide direct measurements that isolate disproportionate capture from this confound.
minor comments (2)
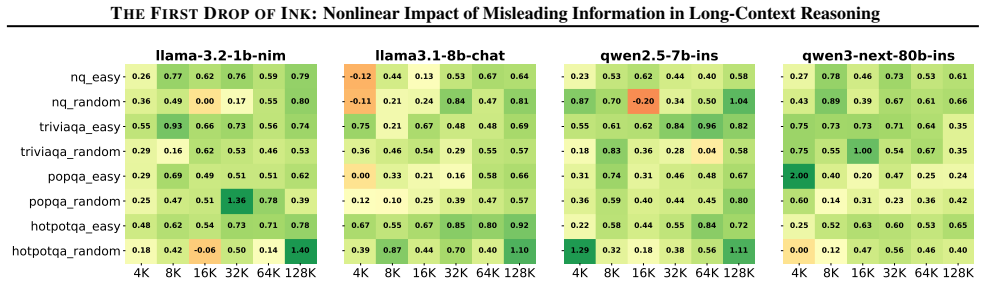
- [Results] The abstract and results sections mention 'controlled experiments' and attention observations but do not report error bars, statistical tests, or data-split details; these should be added for reproducibility.
- [Methods] Notation for 'hard distractors' vs. other distractor types is introduced without a clear table or definition in the methods; a dedicated table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their valuable feedback, particularly on the experimental setup. We clarify below how our analyses address the potential confound raised.
read point-by-point responses
-
Referee: [Experimental Setup] Experimental Setup (fixed-length context construction): Raising the hard-distractor proportion in fixed-length contexts necessarily reduces the count or density of relevant documents. This signal reduction alone can generate a steep early performance drop (loss of the first few critical pieces) followed by diminishing marginal losses, independent of any attention-capture mechanism. The theoretical and empirical attention analyses must therefore either hold relevant content constant across proportions or provide direct measurements that isolate disproportionate capture from this confound.
Authors: We appreciate the referee's identification of this potential confound in the fixed-length context construction. Although raising the hard-distractor proportion reduces the count of relevant documents, our theoretical attention analysis models the softmax attention allocation explicitly as a function of the proportion, revealing that hard distractors receive attention weights far exceeding their share due to their semantic relevance, causing a sharp initial drop in attention to relevant content. This mechanism produces the observed nonlinear performance pattern. Empirically, the attention analyses include direct measurements of attention weights for hard distractors and relevant documents at each proportion level. These show disproportionate capture at small proportions, with the effect saturating as proportion increases, which we correlate with the performance metrics. This goes beyond simple signal reduction, as a pure loss-of-relevant model would not predict the specific attention reallocation patterns we observe and measure. We believe our existing theoretical and empirical results isolate the attention-capture mechanism as requested. revision: no
Circularity Check
No circularity: central claim is direct empirical observation of nonlinear performance drop under controlled distractor variation.
full rationale
The paper reports an observed nonlinear pattern ('First Drop of Ink') from systematically varying hard-distractor proportion in fixed-length contexts, supported by performance metrics and attention measurements. No derivation chain, fitted parameters renamed as predictions, or self-referential definitions are present; the effect is presented as an experimental result rather than a mathematical consequence of its own inputs. Attention-mechanics analyses are described as grounded in the same empirical setups without reducing to tautology. The setup is self-contained against external benchmarks via direct measurement.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hard distractors capture disproportionate attention even at small proportions in transformer models.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lemma 4.2 (Monotonicity and Convexity). Let f(p)=αi,J∗(p)=1/(1+(1−p)a+pb+c). Then f′(p)<0 (strictly decreasing) and f′′(p)>0 (strictly convex) for all p∈[0,1].
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hard distractors capture disproportionate attention even at small proportions, with diminishing marginal impact as their proportion grows
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Math-Shepherd: Verify and reinforce LLMs step-by-step without human annotations
Association for Computational Linguistics, 2024. doi: 10.18653/V1/2024.ACL- LONG.172. URL https://doi.org/10.18653/v1/2024.acl -long.172. Bianchi, O., Koretsky, M. J., Willey, M., Alvarado, C. X., Nayak, T., Asija, A., Kuznetsov, N., Nalls, M. A., Faghri, F., and Khashabi, D. Hidden in the Haystack: Smaller Needles are More Difficult for LLMs to Find, 202...
-
[2]
URL https: //doi.org/10.1145/3626772.3657834
doi: 10.1145/3626772.3657834. URL https: //doi.org/10.1145/3626772.3657834. Ding, Y ., Zhang, L. L., Zhang, C., Xu, Y ., Shang, N., Xu, J., Yang, F., and Yang, M. LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens. In Salakhut- dinov, R., Kolter, Z., Heller, K. A., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F. (eds.),Forty-first Int...
-
[3]
doi: 10.18653/V1/2024.FINDINGS-EMNLP.447
Association for Computational Linguistics, 2024. doi: 10.18653/V1/2024.FINDINGS-EMNLP.447. URL https://doi.org/10.18653/v1/2024.fin dings-emnlp.447. Glass, M. R., Rossiello, G., Chowdhury, M. F. M., Naik, A., Cai, P., and Gliozzo, A. Re2G: Retrieve, Rerank, Gener- ate. In Carpuat, M., de Marneffe, M., and Ru´ız, I. V . M. (eds.),Proceedings of the 2022 Co...
-
[4]
R e2 G : Retrieve, rerank, generate
doi: 10.18653/V1/2022.NAACL-MAIN.194. URL https://doi.org/10.18653/v1/2022.naa cl-main.194. Guha, N., Nyarko, J., Ho, D. E., R´e, C., Chilton, A., Aditya, K., Chohlas-Wood, A., Peters, A., Waldon, B., Rockmore, D. N., Zambrano, D., Talisman, D., Hoque, E., Surani, F., Fagan, F., Sarfaty, G., Dickinson, G. M., Porat, H., Hegland, J., Wu, J., Nudell, J., Ni...
-
[5]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Association for Computational Linguistics. doi: 10.18653/v1/P17-1147. URL https://aclantho logy.org/P17-1147/. Kamradt, G. Needle In A Haystack - pressure testing LLMs,
-
[6]
URL https://github.com/gkamradt/ LLMTest_NeedleInAHaystack . GitHub reposi- tory. Ke, W., Zheng, Y ., Li, Y ., Xu, H., Nie, D., Wang, P., and He, Y . Large Language Models in Document Intelligence: A Comprehensive Survey, Recent Advances, Challenges, and Future Trends.ACM Trans. Inf. Syst., 44(1):18:1– 18:64, 2026. doi: 10.1145/3768156. URL https: //doi.o...
-
[7]
Peng, B., Quesnelle, J., Fan, H., and Shippole, E
Accessed: 2025-01-20. Peng, B., Quesnelle, J., Fan, H., and Shippole, E. YaRN: Efficient Context Window Extension of Large Language Models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https: //openreview.net/forum?id=wHBfxhZu1u. Petroni, F., Piktus, A., Fan, A., ...
-
[8]
URL https://doi.org/10.48550/arXiv.2 511.06818. Ryan, N. Introducing a learnable temperature value into the softmax self-attention scores, 8 2024. Schick, T., Dwivedi-Yu, J., Dess`ı, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., and Scialom, T. Toolformer: Language Models Can Teach Themselves to Use Tools. In Oh, A., Naumann, T....
-
[9]
Yen, H., Gao, T., Hou, M., Ding, K., Fleischer, D., Izsak, P., Wasserblat, M., and Chen, D
URL https://openreview.net/forum ?id=WE_vluYUL-X. Yen, H., Gao, T., Hou, M., Ding, K., Fleischer, D., Izsak, P., Wasserblat, M., and Chen, D. HELMET: How to evaluate long-context models effectively and thoroughly. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview .net/forum?id=293V3bJbmE. Yoran, O., Wolfso...
-
[10]
It matches or is semantically equivalent to the reference answer
-
[11]
It accurately answers the question using information from the documents
-
[12]
It does not contain extra hallucinated or incorrect information The answer should be consideredCORRECTeven if: • It uses slightly different wording but conveys the same meaning • It uses synonyms or alternative names for the same entity • It is a shorter or longer form of the reference answer (e.g., “Steven Weber” vs “Steven Robert Weber”) Respond withONL...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.