Recognition: no theorem link
Clin-JEPA: A Multi-Phase Co-Training Framework for Joint-Embedding Predictive Pretraining on EHR Patient Trajectories
Pith reviewed 2026-05-13 05:49 UTC · model grok-4.3
The pith
A five-phase curriculum stabilizes joint training of encoder and predictor in JEPA for EHR trajectories, yielding converging latent forecasts and better multi-task risk prediction from one backbone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
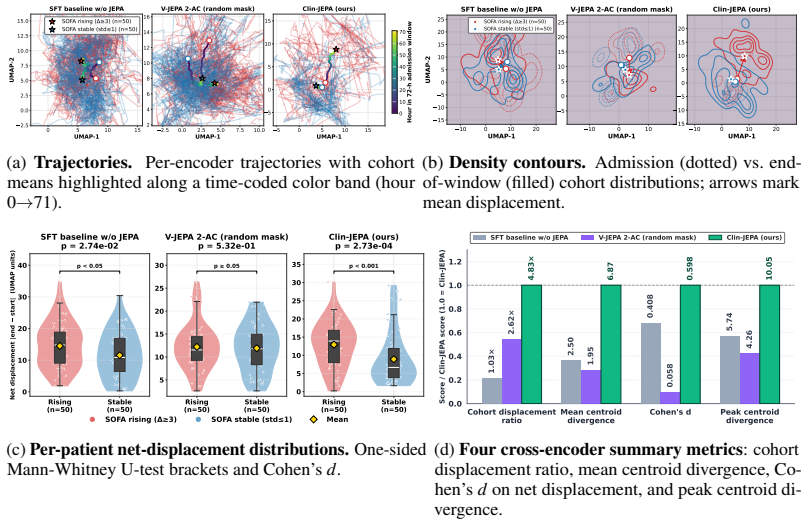
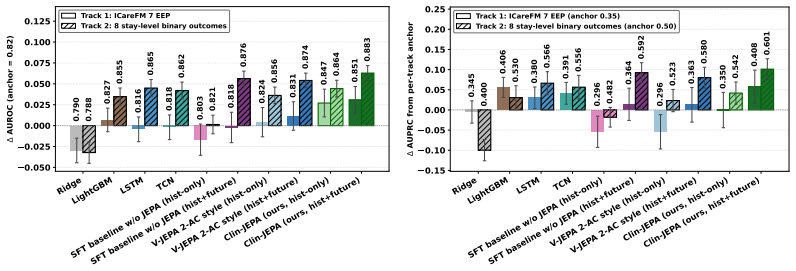
Clin-JEPA uses a five-phase pretraining schedule—predictor warmup, joint refinement, EMA target alignment, hard sync, and predictor finalization—to co-train a Qwen3-8B encoder and a 92 M-parameter latent predictor on MIMIC-IV ICU trajectories under a shared JEPA objective. The resulting model exhibits converging ℓ1 rollout drift of −15.7 % over 48-hour horizons while baselines diverge, places deteriorating patients 4.83 times farther from stable ones in latent space, and achieves mean AUROC 0.851 on ICareFM EEP plus 0.883 across eight binary risk tasks.
What carries the argument
The five-phase co-training curriculum that sequentially stabilizes encoder-predictor interaction under a joint-embedding prediction loss on sequential EHR data.
If this is right
- A single pretrained backbone can generate stable multi-hour latent trajectory forecasts without separate fine-tuning for each horizon.
- The learned latent geometry separates clinically meaningful cohorts by a larger margin than encoders trained without the joint predictor signal.
- Downstream risk prediction across multiple binary tasks improves by roughly 0.04 AUROC when the encoder is grounded by the retained predictor.
- Autoregressive rollout in the latent space converges rather than diverges when the encoder and predictor are co-trained through the staged curriculum.
Where Pith is reading between the lines
- The same staged curriculum might reduce instability when applying JEPA-style methods to other long-horizon time-series domains such as sensor streams or financial sequences.
- If the curriculum phases prove necessary, future work could test whether a shorter subset of phases suffices once the model is scaled or the data distribution changes.
- The clinical separation in latent space suggests the encoder may support unsupervised cohort discovery or anomaly detection without additional labels.
Load-bearing premise
The observed gains in rollout stability and downstream AUROC are produced by the five-phase schedule itself rather than by model scale, preprocessing details, or hyperparameter choices specific to this run.
What would settle it
A controlled ablation that removes one or more curriculum phases and measures whether 48-hour latent ℓ1 drift remains negative and whether AUROC on the eight risk tasks stays above the baseline average.
Figures


read the original abstract
We present Clin-JEPA, a multi-phase co-training framework for joint-embedding predictive (JEPA) pretraining on EHR patient trajectories. JEPA architectures have enabled latent-space planning in robotics and high-quality representation learning in vision, but extending the paradigm to EHR data -- to obtain a single backbone that simultaneously forecasts patient trajectories and serves diverse downstream risk-prediction tasks without per-task fine-tuning -- remains an open challenge. Existing JEPA frameworks either discard the predictor after pretraining (I-JEPA, V-JEPA) or train it on a frozen pretrained encoder (V-JEPA 2-AC), leaving the encoder unaware of the rollout signal that the retained predictor must use at inference; co-training the encoder and predictor under a shared JEPA prediction objective would supply this grounding, but na\"ive co-training is unstable, with representation collapse and online/target drift causing autoregressive rollout to diverge. Clin-JEPA's five-phase pretraining curriculum -- predictor warmup, joint refinement, EMA target alignment, hard sync, and predictor finalization -- addresses each failure mode by phase, stably co-training a Qwen3-8B-based encoder and a 92M-parameter latent trajectory predictor. On MIMIC-IV ICU data, three independent evaluations support the framework: (1) latent $\ell_1$ rollout drift uniquely converges ($-$15.7%) over 48-hour horizons while baselines and ablations diverge (+3% to +4951%); (2) the encoder learns a clinically discriminative latent geometry (deteriorating-patient cohorts displace 4.83$\times$ further than stable patients in latent space, vs $\leq$2.62$\times$ for baseline encoders); (3) a single backbone outperforms strong tabular and sequence baselines on multi-task downstream evaluation. Clin-JEPA achieves mean AUROC 0.851 on ICareFM EEP and 0.883 on 8 binary risk tasks (+0.038 and +0.041 vs baseline average).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Clin-JEPA, a multi-phase co-training framework for joint-embedding predictive pretraining (JEPA) on EHR patient trajectories. It introduces a five-phase curriculum (predictor warmup, joint refinement, EMA target alignment, hard sync, predictor finalization) to stabilize co-training of a Qwen3-8B encoder and 92M-parameter predictor, claiming this yields converging latent ℓ1 rollout drift, clinically discriminative latent geometry, and improved downstream AUROC on MIMIC-IV ICU data compared to baselines.
Significance. If the reported gains in rollout convergence and downstream performance are robust and attributable to the curriculum, the work could advance self-supervised representation learning for clinical time series by enabling a single backbone for both trajectory forecasting and multi-task risk prediction without per-task fine-tuning. The concrete quantitative results on a standard dataset provide a starting point for further development in clinical AI, though broader validation would be needed.
major comments (3)
- [Abstract and evaluation sections] Abstract and evaluation sections: The central claim attributes converging ℓ1 rollout drift (−15.7% over 48 h) and AUROC gains (+0.038 on ICareFM EEP, +0.041 on 8 binary tasks) to the five-phase curriculum. However, no ablation experiments are reported that isolate individual phases (e.g., removing hard sync or EMA alignment) while holding architecture, data splits, and hyperparameters fixed. This leaves open whether the stability and discriminative geometry arise from the curriculum or from the large encoder scale and preprocessing.
- [Experiments and baselines sections] Experiments and baselines sections: Baselines are not described as scale-matched to the Qwen3-8B encoder or trained under identical preprocessing and hyperparameter regimes. Without scale-matched single-phase JEPA controls on the same MIMIC-IV splits, the causal link between the multi-phase curriculum and the observed non-divergence of autoregressive rollouts cannot be isolated from model capacity effects.
- [Results sections] Results sections: The three quantitative evaluations lack error bars, statistical significance tests, exact data-split details, and full baseline implementation specifications. This weakens confidence that the mean AUROC values of 0.851 and 0.883, as well as the 4.83× displacement ratio, reliably exceed baseline performance rather than reflecting unstated tuning advantages.
minor comments (2)
- [Results] A table summarizing per-task AUROCs for the 8 binary risk tasks and ICareFM EEP would improve clarity of the multi-task evaluation.
- [Methods] The definition of latent ℓ1 rollout drift would benefit from an explicit equation in the methods to make the −15.7% convergence metric fully reproducible.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of experimental design and reporting that we address below. We will revise the manuscript to strengthen the evidence for the five-phase curriculum's contributions while clarifying baseline comparisons and adding missing statistical details.
read point-by-point responses
-
Referee: The central claim attributes converging ℓ1 rollout drift (−15.7% over 48 h) and AUROC gains (+0.038 on ICareFM EEP, +0.041 on 8 binary tasks) to the five-phase curriculum. However, no ablation experiments are reported that isolate individual phases (e.g., removing hard sync or EMA alignment) while holding architecture, data splits, and hyperparameters fixed.
Authors: We agree that targeted ablations isolating each phase would provide stronger causal evidence. The current manuscript reports some ablation variants showing divergence when the full curriculum is not used, but these do not systematically disable one phase at a time. In the revised version we will add a dedicated ablation table and section that removes or disables individual phases (predictor warmup, joint refinement, EMA target alignment, hard sync, predictor finalization) while freezing all other factors, reporting effects on both rollout drift and downstream AUROC. revision: yes
-
Referee: Baselines are not described as scale-matched to the Qwen3-8B encoder or trained under identical preprocessing and hyperparameter regimes. Without scale-matched single-phase JEPA controls on the same MIMIC-IV splits, the causal link between the multi-phase curriculum and the observed non-divergence of autoregressive rollouts cannot be isolated from model capacity effects.
Authors: We acknowledge that the primary baselines are not trained at identical 8B scale under the exact same regime, which limits direct isolation of the curriculum from capacity. The contribution of Clin-JEPA is precisely the curriculum that makes stable co-training feasible at this scale; single-phase JEPA diverges even with the same encoder. In revision we will expand the baseline description to include all preprocessing steps, hyperparameter ranges, and model sizes used, and we will add a note on computational constraints preventing full 8B-scale single-phase retraining of every baseline. We will also include a smaller-scale controlled comparison where feasible. revision: partial
-
Referee: The three quantitative evaluations lack error bars, statistical significance tests, exact data-split details, and full baseline implementation specifications. This weakens confidence that the mean AUROC values of 0.851 and 0.883, as well as the 4.83× displacement ratio, reliably exceed baseline performance rather than reflecting unstated tuning advantages.
Authors: We accept this criticism. The reported means are from multiple random seeds, but error bars, p-values, and exact split information were omitted for brevity. In the revised manuscript we will add standard deviation error bars across seeds, paired statistical significance tests against each baseline, precise patient-level train/validation/test split ratios with stratification details, and an expanded appendix with full baseline hyperparameter tables, preprocessing code references, and implementation specifications to ensure reproducibility. revision: yes
Circularity Check
No circularity: empirical claims rest on external baselines and held-out metrics
full rationale
The paper introduces a five-phase curriculum for co-training an encoder and predictor under a JEPA objective on EHR trajectories, then reports three independent empirical evaluations on MIMIC-IV data: converging latent ℓ1 rollout drift, discriminative geometry, and improved AUROC on downstream tasks. These results are measured against external baselines and ablations rather than derived from internal equations or self-referential definitions. No mathematical derivation chain exists that reduces a claimed prediction or uniqueness result to quantities defined by the same fitted parameters or prior self-citations; the central attribution to the curriculum is supported by reported performance deltas on held-out data, rendering the argument self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- Phase-specific learning rates and durations
- EMA decay and sync thresholds
axioms (1)
- domain assumption EHR trajectories contain stable latent structure that a predictor can learn to roll out
Reference graph
Works this paper leans on
-
[1]
Nikita Makarov, Maria Bordukova, Papichaya Quengdaeng, Daniel Garger, Raul Rodriguez-Esteban, Fabian Schmich, and Michael P Menden. Large language models forecast patient health trajectories enabling digital twins.npj Digital Medicine, 8(1):588, 2025
work page 2025
-
[2]
Zero shot health trajectory prediction using transformer.NPJ digital medicine, 7(1):256, 2024
Pawel Renc, Yugang Jia, Anthony E Samir, Jaroslaw Was, Quanzheng Li, David W Bates, and Arkadiusz Sitek. Zero shot health trajectory prediction using transformer.NPJ digital medicine, 7(1):256, 2024
work page 2024
-
[3]
Zhenbang Wu, Anant Dadu, Mike Nalls, Faraz Faghri, and Jimeng Sun. Instruction tuning large language models to understand electronic health records.Advances in Neural Information Processing Systems, 37: 54772–54786, 2024
work page 2024
-
[4]
Yusheng Liao, Chaoyi Wu, Junwei Liu, Shuyang Jiang, Pengcheng Qiu, Haowen Wang, Yun Yue, Shuai Zhen, Jian Wang, Qianrui Fan, et al. Ehr-r1: A reasoning-enhanced foundational language model for electronic health record analysis.arXiv preprint arXiv:2510.25628, 2025
-
[5]
Manuel Burger, Daphné Chopard, Gregor Lichtner, Malte Londschien, Fedor Sergeev, Moritz Fuchs, Hugo Yèche, Rita Kuznetsova, Martin Faltys, Eike Gerdes, et al. A foundation model for intensive care: Unlocking generalization across tasks and domains at scale.medRxiv, pages 2025–07, 2025
work page 2025
-
[6]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27.Open Review, 62(1):1–62, 2022
work page 2022
-
[7]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
work page 2023
-
[8]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video. arXiv preprint arXiv:2404.08471, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al. Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
work page 2023
-
[11]
Laila Rasmy, Yang Xiang, Ziqian Xie, Cui Tao, and Degui Zhi. Med-bert: pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction.NPJ digital medicine, 4(1):86, 2021
work page 2021
-
[12]
A large language model for electronic health records.NPJ digital medicine, 5(1):194, 2022
Xi Yang, Aokun Chen, Nima PourNejatian, Hoo Chang Shin, Kaleb E Smith, Christopher Parisien, Colin Compas, Cheryl Martin, Anthony B Costa, Mona G Flores, et al. A large language model for electronic health records.NPJ digital medicine, 5(1):194, 2022
work page 2022
-
[13]
Zeljko Kraljevic, Dan Bean, Anthony Shek, Rebecca Bendayan, Harry Hemingway, Joshua Au Yeung, Alexander Deng, Alfred Balston, Jack Ross, Esther Idowu, et al. Foresight—a generative pretrained transformer for modelling of patient timelines using electronic health records: a retrospective modelling study.The Lancet Digital Health, 6(4):e281–e290, 2024
work page 2024
-
[14]
Adibvafa Fallahpour, Mahshid Alinoori, Wenqian Ye, Xu Cao, Arash Afkanpour, and Amrit Krishnan. Ehrmamba: Towards generalizable and scalable foundation models for electronic health records.arXiv preprint arXiv:2405.14567, 2024
-
[15]
Hejie Cui, Alyssa Unell, Bowen Chen, Jason Alan Fries, Emily Alsentzer, Sanmi Koyejo, and Nigam H Shah. Timer: Temporal instruction modeling and evaluation for longitudinal clinical records.npj Digital Medicine, 8(1):577, 2025
work page 2025
-
[16]
Building the ehr foundation model via next event prediction
Zekai Chen, Arda Pekis, and Kevin Brown. Building the ehr foundation model via next event prediction. arXiv preprint arXiv:2509.25591, 2025
-
[17]
Pawel Renc, Michal K Grzeszczyk, Nassim Oufattole, Deirdre Goode, Yugang Jia, Szymon Bieganski, Matthew BA McDermott, Jaroslaw Was, Anthony E Samir, Jonathan W Cunningham, et al. Foundation model of electronic medical records for adaptive risk estimation.GigaScience, 14:giaf107, 2025. 11
work page 2025
-
[18]
Foundation models for electronic health records: representation dynamics and transferability
Michael C Burkhart, Bashar Ramadan, Zewei Liao, Kaveri Chhikara, Juan C Rojas, William F Parker, and Brett K Beaulieu-Jones. Foundation models for electronic health records: representation dynamics and transferability.arXiv preprint arXiv:2504.10422, 2025
-
[19]
Hai Huang, Yann LeCun, and Randall Balestriero. Llm-jepa: Large language models meet joint embedding predictive architectures.arXiv preprint arXiv:2509.14252, 2025
-
[20]
Vl-jepa: Joint em- bedding predictive architecture for vision-language,
Delong Chen, Mustafa Shukor, Theo Moutakanni, Willy Chung, Jade Yu, Tejaswi Kasarla, Yejin Bang, Allen Bolourchi, Yann LeCun, and Pascale Fung. Vl-jepa: Joint embedding predictive architecture for vision-language.arXiv preprint arXiv:2512.10942, 2025
-
[21]
Irsyad Adam, Zekai Chen, David Laprade, Shaun Porwal, David Laub, Erik Reinertsen, Arda Pekis, and Kevin Brown. The patient is not a moving document: A world model training paradigm for longitudinal ehr.arXiv preprint arXiv:2601.22128, 2026
-
[22]
Qianyi Xu, Gousia Habib, Feng Wu, Dilruk Perera, and Mengling Feng. Meddreamer: Model-based rein- forcement learning with latent imagination on complex ehrs for clinical decision support. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 1693–1704, 2026
work page 2026
-
[23]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models.arXiv preprint arXiv:2010.02193, 2020
work page internal anchor Pith review arXiv 2010
-
[24]
Shane Lowe, Garrett Park, Liam Lee, and Parker Smith. Latent physiology as language: A state-space foundation model for multimodal icu and ehr representation learning
-
[25]
Tianxingjian Ding, Yuanhao Zou, Chen Chen, Mubarak Shah, and Yu Tian. Clarity: Medical world model for guiding treatment decisions by modeling context-aware disease trajectories in latent space.arXiv preprint arXiv:2512.08029, 2025
-
[26]
Mohammad Areeb Qazi, Maryam Nadeem, and Mohammad Yaqub. Beyond generative ai: World models for clinical prediction, counterfactuals, and planning.arXiv preprint arXiv:2511.16333, 2025
-
[27]
Multitask learning and benchmarking with clinical time series data.Scientific data, 6(1):96, 2019
Hrayr Harutyunyan, Hrant Khachatrian, David C Kale, Greg Ver Steeg, and Aram Galstyan. Multitask learning and benchmarking with clinical time series data.Scientific data, 6(1):96, 2019
work page 2019
-
[28]
Sanjay Purushotham, Chuizheng Meng, Zhengping Che, and Yan Liu. Benchmarking deep learning models on large healthcare datasets.Journal of biomedical informatics, 83:112–134, 2018
work page 2018
-
[29]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems, 30, 2017
work page 2017
-
[30]
Long short-term memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural computation, 9(8):1735–1780, 1997
work page 1997
-
[31]
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling.arXiv preprint arXiv:1803.01271, 2018. 12 Appendix A Source tables and feature inventory This appendix documents the MIMIC-IV [ 10] source tables and the per-hour features used to construct the encoder’s state and a...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.