Recognition: 2 theorem links
· Lean TheoremGrounded Satirical Generation with RAG
Pith reviewed 2026-05-12 03:55 UTC · model grok-4.3
The pith
Retrieval from news makes generated satirical definitions more political than humorous.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
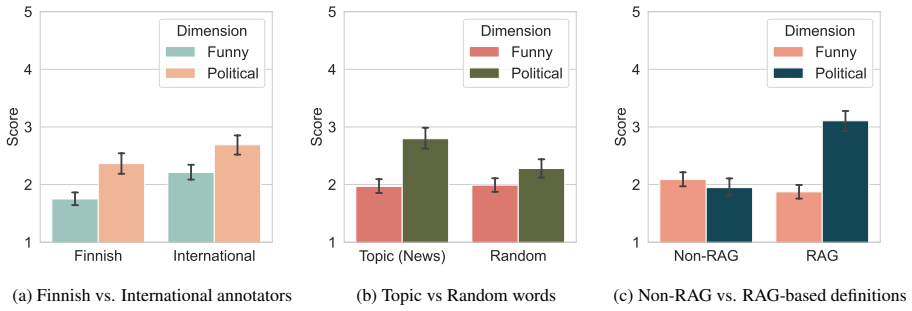
A retrieval-augmented pipeline over current news produces satirical dictionary definitions that six human annotators rate higher on political relevance than on humor. Topic-based word choice and the retrieval step each increase political relevance, but neither step improves perceived humor. Large language models align with human political ratings yet perform poorly when asked to judge humor.
What carries the argument
Retrieval-augmented generation over current news to ground satirical dictionary definitions, evaluated through a task-specific human annotation framework measuring political relevance and humor across conditions.
If this is right
- Human annotators perceive the generated definitions as more political than humorous across tested conditions.
- Topic-based word selection and retrieval-augmented generation each raise the political relevance of the outputs.
- Neither technique produces clear gains in humor ratings.
- Large language models match human judgments on political relevance but not on humor.
- The released dataset supports further experiments on grounded satire generation.
Where Pith is reading between the lines
- The gap between political relevance and humor suggests that current grounding techniques supply context but leave the creative, subjective layer of satire under-served.
- The same pipeline could be tested in other languages to check whether the political-over-humor pattern is language-specific or more general.
- Better humor evaluation might require models trained on larger collections of annotated satirical examples rather than zero-shot prompting.
Load-bearing premise
Ratings of political relevance and humor by six human annotators provide a stable and generalizable measure of satire quality in the Finnish context.
What would settle it
A follow-up annotation study with a larger pool of Finnish speakers rating the same definitions for humor and political content, or direct comparison against published satirical definitions.
Figures







read the original abstract
Humor generation remains challenging task for Large Language Models (LLMs), due to their subjective nature. We focus on satire, a form of humor strongly shaped by context. In this work, we present a novel pipeline for grounded satire generation that uses Retrieval-Augmented Generation (RAG) over current news to produce satirical dictionary definitions in the Finnish context. We also introduce a new task-specific evaluation framework and annotate 100 generated definitions with six human annotators, enabling analysis across multiple experimental conditions, including cultural background, source-word type, and the presence or absence of RAG. Our results show that the generated definitions are perceived as more political than humorous. Both topic-based word selection and RAG improve the political relevance of the outputs, but neither yields clear gains in humor generation. In addition, our LLM-as-a-judge evaluation of five state-of-the-art models indicates that LLMs correlate well with human judgments on political relevance, but perform poorly on humor. We release our code and annotated dataset to support further research on grounded satire generation and evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a RAG-based pipeline that retrieves current news to ground the generation of satirical Finnish dictionary definitions. It introduces a task-specific evaluation framework, has six human annotators rate 100 generated definitions across conditions (RAG vs. no RAG, topic-based vs. random word selection, cultural background), and compares the outputs to five LLMs used as judges. The central empirical claims are that the definitions are perceived as more political than humorous, that both topic-based word selection and RAG increase political relevance without clear gains in humor, and that LLM judges correlate well with humans on political relevance but poorly on humor. The code and annotated dataset are released.
Significance. If the human evaluation is shown to be reliable, the work offers a concrete, grounded approach to satire generation in a non-English setting and supplies a public dataset plus evaluation framework that could support follow-on research on context-dependent humor. The release of code and annotations is a clear positive that increases the paper's utility to the community.
major comments (2)
- [Human Evaluation] Human Evaluation section (and abstract): the central claims rest on ratings from only six annotators on 100 definitions, yet no inter-annotator agreement statistic (Fleiss' kappa, Krippendorff's alpha, or similar), no annotation guidelines, no breakdown by annotator background or cultural expertise, and no statistical significance tests (paired t-tests, ANOVA, or effect sizes) for the reported differences between conditions are provided. Without these, it is impossible to determine whether the headline finding—that definitions are more political than humorous and that RAG improves political relevance but not humor—reflects systematic effects or annotator idiosyncrasy.
- [Results / LLM-as-a-Judge] Results and LLM-as-a-Judge subsection: the statement that LLMs 'correlate well with human judgments on political relevance, but perform poorly on humor' is given without any reported correlation coefficients, confusion matrices, or per-model breakdowns. This leaves the comparative evaluation of the five state-of-the-art models unsupported and prevents readers from assessing how well the LLM judges actually track the human signal that underpins the paper's main conclusions.
minor comments (2)
- [Abstract] The abstract refers to 'a new task-specific evaluation framework' without a one-sentence description of its dimensions or scoring procedure; a brief characterization would help readers immediately understand the annotation protocol.
- [Results] Figure or table presenting the per-condition means and standard deviations for the political and humorous ratings would make the quantitative claims easier to inspect and would strengthen the results section.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We believe the suggested additions will improve the clarity and rigor of our evaluation sections. We address each major comment below.
read point-by-point responses
-
Referee: [Human Evaluation] Human Evaluation section (and abstract): the central claims rest on ratings from only six annotators on 100 definitions, yet no inter-annotator agreement statistic (Fleiss' kappa, Krippendorff's alpha, or similar), no annotation guidelines, no breakdown by annotator background or cultural expertise, and no statistical significance tests (paired t-tests, ANOVA, or effect sizes) for the reported differences between conditions are provided. Without these, it is impossible to determine whether the headline finding—that definitions are more political than humorous and that RAG improves political relevance but not humor—reflects systematic effects or annotator idiosyncrasy.
Authors: We thank the referee for highlighting these important aspects of reporting for human evaluations. Upon reflection, we agree that providing inter-annotator agreement, annotation guidelines, annotator details, and statistical tests will enhance the manuscript. In the revised version, we will add: (1) Krippendorff's alpha for agreement on both political relevance and humor ratings; (2) the full annotation guidelines in an appendix; (3) a table or description of annotator backgrounds, including their cultural expertise in Finnish context; and (4) results of paired t-tests or Wilcoxon tests with effect sizes (Cohen's d) for comparisons between conditions (RAG vs. no RAG, topic-based vs. random). We note that the six annotators were all Finnish natives, which supports the cultural grounding, but we will make this explicit. These changes will allow readers to better evaluate the reliability of our findings. revision: yes
-
Referee: [Results / LLM-as-a-Judge] Results and LLM-as-a-Judge subsection: the statement that LLMs 'correlate well with human judgments on political relevance, but perform poorly on humor' is given without any reported correlation coefficients, confusion matrices, or per-model breakdowns. This leaves the comparative evaluation of the five state-of-the-art models unsupported and prevents readers from assessing how well the LLM judges actually track the human signal that underpins the paper's main conclusions.
Authors: We agree that the LLM-as-a-judge results require more quantitative support to be fully convincing. We will revise the subsection to include Spearman rank correlation coefficients (or Pearson, depending on the data) between the human ratings and each LLM's ratings for political relevance and humor separately. Additionally, we will provide per-model performance breakdowns and, where suitable, confusion matrices or agreement tables. This will substantiate our claim that LLMs align better with humans on political relevance than on humor and allow for a more transparent comparison of the five models. revision: yes
Circularity Check
No circularity: purely empirical pipeline with external human/LLM judgments
full rationale
The paper presents a RAG-based generation pipeline for Finnish satirical definitions and evaluates outputs via direct human annotation of 100 items by six annotators plus LLM-as-judge comparisons. No mathematical derivations, equations, fitted parameters, or first-principles predictions exist that could reduce to inputs by construction. All headline results (political vs. humorous perception, effects of topic selection and RAG) are reported from external ratings rather than self-referential logic, self-citations, or renamed empirical patterns. The study is self-contained against its own annotation data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe present a novel pipeline for grounded satire generation that uses Retrieval-Augmented Generation (RAG) over current news to produce satirical dictionary definitions... annotate 100 generated definitions with six human annotators
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearOur results show that the generated definitions are perceived as more political than humorous. Both topic-based word selection and RAG improve the political relevance...
Reference graph
Works this paper leans on
- [1]
-
[2]
Publications Manual , year = "1983", publisher =
work page 1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [4]
-
[5]
Dan Gusfield , title =. 1997
work page 1997
-
[6]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
arXiv preprint arXiv:2511.09133 , year=
Assessing the Capabilities of LLMs in Humor: A Multi-dimensional Analysis of Oogiri Generation and Evaluation , author=. arXiv preprint arXiv:2511.09133 , year=
-
[9]
Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
Horvitz, Zachary and Chen, Jingru and Aditya, Rahul and Srivastava, Harshvardhan and West, Robert and Yu, Zhou and McKeown, Kathleen. Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2024. doi:10.18653/v...
-
[10]
Make Satire Boring Again: Reducing Stylistic Bias of Satirical Corpus by Utilizing Generative LLM s
Ozturk, Asli Umay and Cekinel, Recep Firat and Karagoz, Pinar. Make Satire Boring Again: Reducing Stylistic Bias of Satirical Corpus by Utilizing Generative LLM s. Proceedings of the 18th Workshop on Building and Using Comparable Corpora (BUCC). 2025
work page 2025
-
[11]
International Conference on Applications of Natural Language to Information Systems , pages=
Cross-domain and cross-language irony detection: The impact of bias on models’ generalization , author=. International Conference on Applications of Natural Language to Information Systems , pages=. 2023 , organization=
work page 2023
-
[12]
Journal of Ambient Intelligence and Humanized Computing , volume=
Transformer-based models for multimodal irony detection , author=. Journal of Ambient Intelligence and Humanized Computing , volume=. 2023 , publisher=
work page 2023
-
[13]
Workshop on Chinese Lexical Semantics , pages=
Augmenting emotion features in irony detection with large language modeling , author=. Workshop on Chinese Lexical Semantics , pages=. 2024 , organization=
work page 2024
-
[14]
Bulletin of the Transilvania University of Bra
Evaluating AI-Generated Satire against Human-Written Content: A Comparative Analysis , author=. Bulletin of the Transilvania University of Bra
-
[15]
Comedy: A geographic and historical guide , volume=
The philosophy of humor , author=. Comedy: A geographic and historical guide , volume=. 2005 , publisher=
work page 2005
-
[16]
and Lee, Lillian and Da, Jeff and Zellers, Rowan and Mankoff, Robert and Choi, Yejin
Hessel, Jack and Marasovic, Ana and Hwang, Jena D. and Lee, Lillian and Da, Jeff and Zellers, Rowan and Mankoff, Robert and Choi, Yejin. Do Androids Laugh at Electric Sheep? Humor ``Understanding'' Benchmarks from The New Yorker Caption Contest. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)...
-
[17]
Proceedings of the ACL Interactive Poster and Demonstration Sessions , pages=
Hahacronym: A computational humor system , author=. Proceedings of the ACL Interactive Poster and Demonstration Sessions , pages=
-
[18]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
BottleHumor: Self-informed humor explanation using the information bottleneck principle , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[19]
Retrieved on December , volume=
Humor detection in yelp reviews , author=. Retrieved on December , volume=
-
[20]
Qwen 2.5: A comprehensive review of the leading resource-efficient llm with potentioal to surpass all competitors , author=. Authorea Preprints , year=
-
[21]
Aya expanse: Combining research breakthroughs for a new multilingual frontier , author=. arXiv preprint arXiv:2412.04261 , year=
-
[22]
Procedia Computer Science , volume=
Eurollm: Multilingual language models for europe , author=. Procedia Computer Science , volume=. 2025 , publisher=
work page 2025
- [23]
-
[24]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Humor Recognition Using Deep Learning
Chen, Peng-Yu and Soo, Von-Wun. Humor Recognition Using Deep Learning. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018. doi:10.18653/v1/N18-2018
-
[26]
Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics , pages=
From punchlines to predictions: A metric to assess llm performance in identifying humor in stand-up comedy , author=. Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics , pages=
-
[27]
Second Workshop on Language Models for Underserved Communities (LM4UC) , year=
Not Funny Anymore: LLM Judges Confuse Literal Similarity for Humor in Translated Jokes , author=. Second Workshop on Language Models for Underserved Communities (LM4UC) , year=
-
[28]
Proceedings of the 10th Workshop on Slavic Natural Language Processing (Slavic NLP 2025) , pages=
Few-shot prompting, full-scale confusion: Evaluating large language models for humor detection in croatian tweets , author=. Proceedings of the 10th Workshop on Slavic Natural Language Processing (Slavic NLP 2025) , pages=
work page 2025
-
[29]
Baranov, Alexander and Kniazhevsky, Vladimir and Braslavski, Pavel. You Told Me That Joke Twice: A Systematic Investigation of Transferability and Robustness of Humor Detection Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.845
-
[30]
Oxford Research Encyclopedia of Literature , year=
Satire , author=. Oxford Research Encyclopedia of Literature , year=
-
[31]
The Routledge handbook of language and humor , pages=
An overview of humor theory , author=. The Routledge handbook of language and humor , pages=. 2017 , publisher=
work page 2017
-
[32]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
We are humor beings: Understanding and predicting visual humor , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
paper on computational humor accepted despite making serious advances
Reverse-engineering satire, or “paper on computational humor accepted despite making serious advances” , author=. Proceedings of the aaai conference on artificial intelligence , volume=
-
[34]
Human Evaluation of Creative NLG Systems: An Interdisciplinary Survey on Recent Papers
H. Human Evaluation of Creative NLG Systems: An Interdisciplinary Survey on Recent Papers. Proceedings of the First Workshop on Natural Language Generation, Evaluation, and Metrics (GEM). 2021. doi:10.18653/v1/2021.gem-1.9
-
[35]
C hat GPT is fun, but it is not funny! Humor is still challenging Large Language Models
Jentzsch, Sophie and Kersting, Kristian. C hat GPT is fun, but it is not funny! Humor is still challenging Large Language Models. Proceedings of the 13th Workshop on Computational Approaches to Subjectivity, Sentiment, & Social Media Analysis. 2023. doi:10.18653/v1/2023.wassa-1.29
- [36]
-
[37]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2020 , eprint=
work page 2020
-
[38]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction , author=. 2020 , eprint=
work page 2020
-
[39]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure , author=. 2022 , eprint=
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.