Recognition: 2 theorem links
· Lean TheoremGrounded or Guessing? LVLM Confidence Estimation via Blind-Image Contrastive Ranking
Pith reviewed 2026-05-12 03:52 UTC · model grok-4.3
The pith
BICR trains confidence probes for vision-language models by ranking hidden states from real images against blacked-out versions to favor visually grounded predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BICR extracts hidden states from a frozen LVLM twice—once for the real image-question pair and once for the same question with the image blacked out—then trains a small probe on the real-image states under a contrastive ranking loss that enforces lower confidence for the blind-image view, thereby making explicit whether a prediction depends on visual grounding.
What carries the argument
Blind-Image Contrastive Ranking (BICR), a training regularizer that applies a ranking loss between paired hidden states from real and blacked-out images to penalize ungrounded confidence.
If this is right
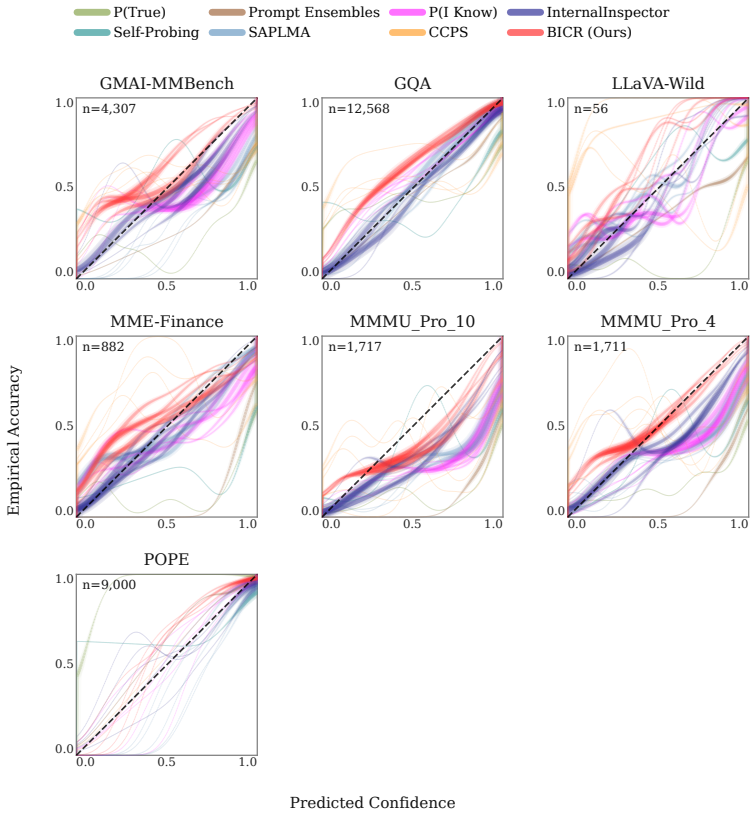
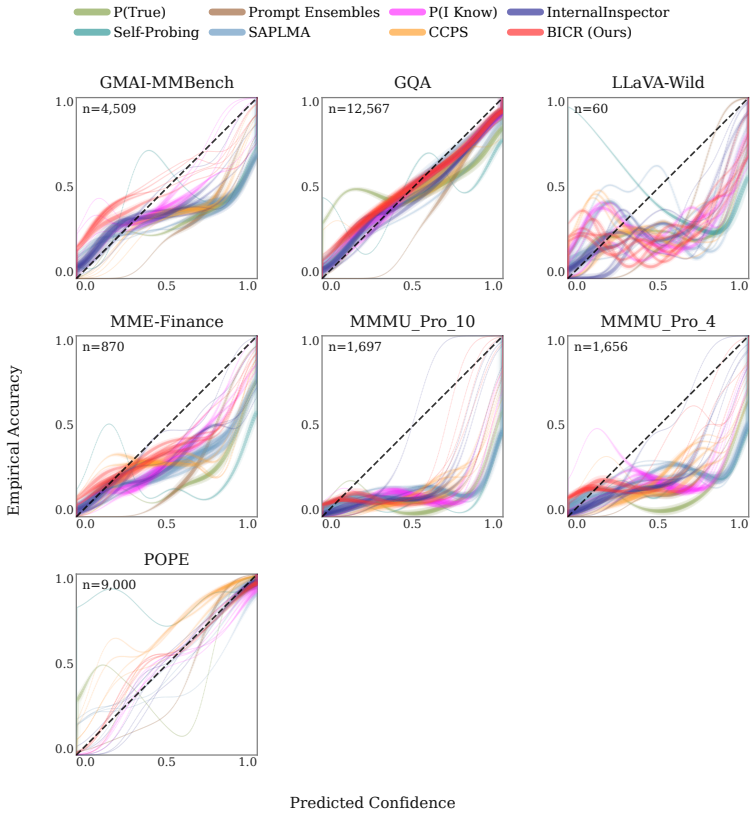
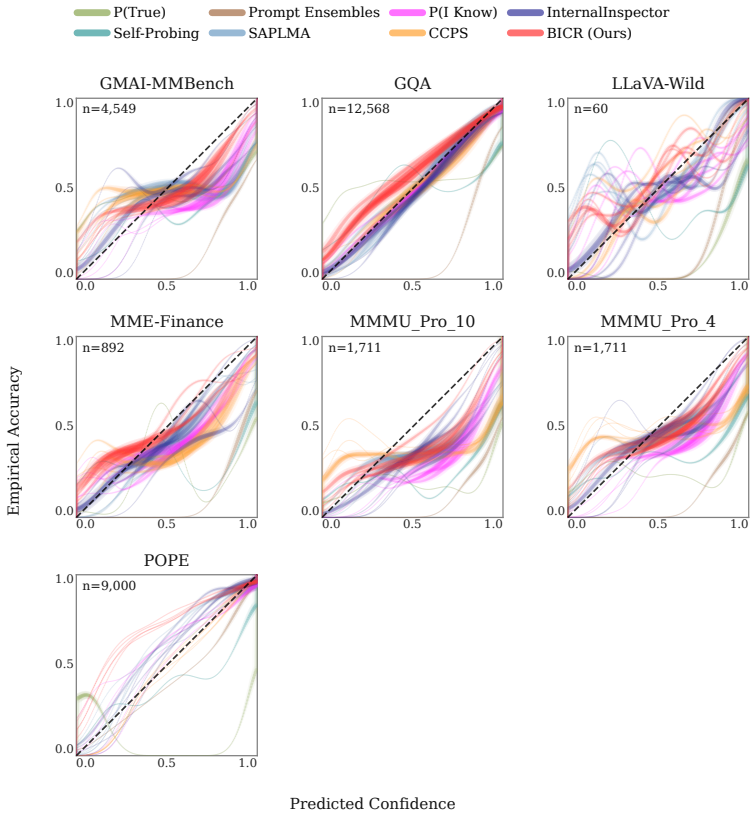
- BICR simultaneously leads in calibration and discrimination metrics averaged across five modern LVLMs.
- Discrimination improvements remain statistically significant even under cluster-aware analysis.
- The probe requires 4-18 times fewer parameters than the strongest existing probing baselines.
- The same framework improves performance on visual question answering, object hallucination detection, medical imaging, and financial document tasks.
Where Pith is reading between the lines
- Similar blind-input contrasts could be applied to other multimodal settings where one modality may be ignored.
- The method shows that explicit negative examples of ungrounded inference can sharpen uncertainty estimates without extra inference cost.
- Deployments that need to know whether an answer truly used the image could adopt this probe as a lightweight filter.
Load-bearing premise
Penalizing higher probe confidence on blacked-out image states will make the probe treat visual grounding as a reliable indicator of prediction correctness instead of latching onto some other correlation in the hidden states.
What would settle it
If ablating the ranking loss leaves discrimination performance unchanged or higher on the same benchmark across LVLMs, the contrastive mechanism is not responsible for the reported gains.
Figures







read the original abstract
Large vision-language models suffer from visual ungroundedness: they can produce a fluent, confident, and even correct response driven entirely by language priors, with the image contributing nothing to the prediction. Existing confidence estimation methods cannot detect this, as they observe model behavior under normal inference with no mechanism to determine whether a prediction was shaped by the image or by text alone. We introduce BICR (Blind-Image Contrastive Ranking), a model-agnostic confidence estimation framework that makes this contrast explicit during training by extracting hidden states from a frozen LVLM twice: once with the real image-question pair, and once with the image blacked out while the question is held fixed. A lightweight probe is trained on the real-image hidden state and regularized by a ranking loss that penalizes higher confidence on the blacked-out view, teaching it to treat visual grounding as a signal of reliability at zero additional inference cost. Evaluated across five modern LVLMs and seven baselines on a benchmark covering visual question answering, object hallucination detection, medical imaging, and financial document understanding, BICR achieves the best cross-LVLM average on both calibration and discrimination simultaneously, with statistically significant discrimination gains robust to cluster-aware analysis at 4-18x fewer parameters than the strongest probing baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BICR, a model-agnostic confidence estimation method for LVLMs that extracts hidden states from a frozen model on real image-question pairs and on the same question with the image blacked out, then trains a lightweight probe on the real-image states regularized by a ranking loss that penalizes higher confidence on the blacked-out view. The central claim is that this teaches the probe to treat visual grounding as a reliability signal, yielding the best cross-LVLM average on both calibration and discrimination (with statistically significant discrimination gains robust to cluster-aware analysis) across VQA, hallucination detection, medical imaging, and financial document tasks, at 4-18x fewer parameters than the strongest probing baseline and zero added inference cost.
Significance. If the result holds, the work would be significant for addressing visual ungroundedness in LVLMs: it supplies an explicit contrastive training signal without modifying the base model or incurring inference overhead, and the reported cross-model, multi-domain evaluation with parameter efficiency is a concrete strength. The approach is lightweight and directly targets a known failure mode (language-prior-driven predictions) that standard post-hoc confidence methods cannot detect.
major comments (2)
- [Ranking loss and training procedure (§3)] The ranking loss (described in the abstract and §3) penalizes higher probe confidence on blacked-out hidden states, but the manuscript provides no direct evidence or ablation that the probe learns to use grounding-relevant dimensions of the hidden-state difference rather than incidental ones (global activation shifts, norm changes, or question-specific language patterns that differ across views). This assumption is load-bearing for the claim that BICR solves visual ungroundedness rather than merely fitting a contrastive artifact; without supporting analysis (e.g., probing which dimensions drive the ranking or controlled ablations), the reported gains in calibration and discrimination cannot be confidently attributed to the intended mechanism.
- [Experimental results and tables] Table 3 and the cross-LVLM average results claim statistically significant discrimination gains robust to cluster-aware analysis, yet the manuscript does not detail baseline implementations, exact hyperparameter sweeps, or whether post-hoc analysis choices (e.g., threshold selection or subsetting) influenced the 4-18x parameter advantage. These omissions make it difficult to verify that the superiority is not an artifact of implementation differences.
minor comments (2)
- [Method section] Notation for the two views (real vs. blacked-out) is introduced clearly in the abstract but should be formalized with consistent symbols in the method section to aid reproducibility.
- [Abstract] The abstract states 'seven baselines' but does not enumerate them; a short list or reference table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We have revised the manuscript to provide additional mechanistic analysis and experimental details as requested. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Ranking loss and training procedure (§3)] The ranking loss (described in the abstract and §3) penalizes higher probe confidence on blacked-out hidden states, but the manuscript provides no direct evidence or ablation that the probe learns to use grounding-relevant dimensions of the hidden-state difference rather than incidental ones (global activation shifts, norm changes, or question-specific language patterns that differ across views). This assumption is load-bearing for the claim that BICR solves visual ungroundedness rather than merely fitting a contrastive artifact; without supporting analysis (e.g., probing which dimensions drive the ranking or controlled ablations), the reported gains in calibration and discrimination cannot be confidently attributed to the intended mechanism.
Authors: We agree that direct evidence linking the ranking loss to grounding-relevant dimensions would strengthen the attribution of gains to the intended mechanism. In the revised manuscript we have added a new analysis subsection with (i) a linear probe on individual hidden-state dimensions showing that those most predictive of the ranking loss correlate with image presence rather than global activation or norm shifts, and (ii) controlled ablations that selectively mask or perturb grounding-sensitive dimensions versus incidental features, confirming that performance degrades only when visual-grounding signals are disrupted. These additions support that the probe learns to use the visual contrast rather than artifacts. We have also expanded the description of the training procedure in §3 for clarity. revision: yes
-
Referee: [Experimental results and tables] Table 3 and the cross-LVLM average results claim statistically significant discrimination gains robust to cluster-aware analysis, yet the manuscript does not detail baseline implementations, exact hyperparameter sweeps, or whether post-hoc analysis choices (e.g., threshold selection or subsetting) influenced the 4-18x parameter advantage. These omissions make it difficult to verify that the superiority is not an artifact of implementation differences.
Authors: We acknowledge that the original manuscript lacked sufficient implementation detail for full reproducibility. The revised version includes an expanded experimental appendix that specifies all baseline implementations, the exact hyperparameter search ranges and selection criteria, and the precise post-hoc procedures (including threshold selection and any subsetting). We have re-run the comparisons under these documented settings and confirm that the reported discrimination gains and 4-18x parameter advantage remain intact. The code repository has also been updated with the full experimental scripts. revision: yes
Circularity Check
No significant circularity; training signal and evaluation are independent
full rationale
The paper defines BICR explicitly via a contrastive ranking loss between real-image and blacked-out hidden states, then evaluates the resulting probe on external calibration and discrimination metrics computed against ground-truth labels. This does not reduce to a self-definition, fitted parameter renamed as prediction, or self-citation chain. The central claim is an empirical performance result on held-out benchmarks, not a tautology derived from the loss construction itself. No load-bearing uniqueness theorems or ansatzes are imported from prior self-work.
Axiom & Free-Parameter Ledger
free parameters (1)
- ranking loss weight
axioms (1)
- domain assumption Blacking out the image removes all visual information while leaving language priors intact
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniquely minimal at identity) echoesA lightweight probe is trained on real-image hidden states with a ranking loss that penalizes higher confidence on the blacked-out view, teaching it to treat visual grounding as a signal of reliability
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability echoesthe representational difference between real-image and blank-image hidden states (our operational proxy for visual grounding) provides a reliable and discriminative signal of answer correctness
Reference graph
Works this paper leans on
-
[1]
Mitigating hallucination in large vision- language models via modular attribution and intervention
Tianyun Yang, Ziniu Li, Juan Cao, and Chang Xu. Mitigating hallucination in large vision- language models via modular attribution and intervention. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id= Bjq4W7P2Us
work page 2025
-
[2]
Don’t miss the forest for the trees: Attentional vision calibration for large vision language models
Sangmin Woo, Donguk Kim, Jaehyuk Jang, Yubin Choi, and Changick Kim. Don’t miss the forest for the trees: Attentional vision calibration for large vision language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 1927–1951, Vienna, Aust...
work page 2025
-
[3]
Metacognitive Prompting Improves Understanding in Large Language Models
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/ 2025.findings-acl.99. URLhttps://aclanthology.org/2025.findings-acl.99/. 11
-
[4]
Hidden in plain sight: VLMs overlook their visual representations
Stephanie Fu, tyler bonnen, Devin Guillory, and Trevor Darrell. Hidden in plain sight: VLMs overlook their visual representations. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=qQb1JLrwol
work page 2025
-
[5]
Reference- free hallucination detection for large vision-language models
Qing Li, Jiahui Geng, Chenyang Lyu, Derui Zhu, Maxim Panov, and Fakhri Karray. Reference- free hallucination detection for large vision-language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Lin- guistics: EMNLP 2024, pages 4542–4551, Miami, Florida, USA, November 2024. Asso- ciation fo...
-
[6]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InProceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, page 1321–1330. JMLR.org, 2017
work page 2017
-
[7]
Instinct vs. Reflection: Unifying Token and Verbalized Confidence in Multimodal Large Models
Yunkai Dang, Yifan Jiang, Yizhu Jiang, Anqi Chen, Wenbin Li, and Yang Gao. Instinct vs. reflection: Unifying token and verbalized confidence in multimodal large models, 2026. URL https://arxiv.org/abs/2604.17274
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Zijun Chen, Wenbo Hu, Guande He, Zhijie Deng, Zheng Zhang, and Richang Hong. Unveiling uncertainty: A deep dive into calibration and performance of multimodal large language models. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Comput...
work page 2025
-
[9]
InternalInspector i2: Robust confidence estimation in LLMs through internal states
Mohammad Beigi, Ying Shen, Runing Yang, Zihao Lin, Qifan Wang, Ankith Mohan, Jianfeng He, Ming Jin, Chang-Tien Lu, and Lifu Huang. InternalInspector i2: Robust confidence estimation in LLMs through internal states. In Yaser Al-Onaizan, Mohit Bansal, and Yun- Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 12...
-
[10]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms, 2024. URL https://arxiv.org/abs/2306.13063
work page internal anchor Pith review arXiv 2024
-
[11]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empiri...
-
[12]
Qingcheng Zeng, Weihao Xuan, Leyang Cui, and Rob V oigt. Thinking out loud: Do reasoning models know when they’re right? In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1394–1407, Suzhou, China, November 2025. Associatio...
-
[13]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models, 2023. URLhttps://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Hademif: Hallucination detection and mitigation in large language models
Xiaoling Zhou, Mingjie Zhang, Zhemg Lee, Wei Ye, and Shikun Zhang. Hademif: Hallucination detection and mitigation in large language models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=VwOYxPScxB. 12
work page 2025
-
[15]
Zhengbao Jiang, Jun Araki, Haibo Ding, and Graham Neubig. How can we know when language models know? on the calibration of language models for question answering.Transactions of the Association for Computational Linguistics, 9:962–977, 2021. doi: 10.1162/tacl_a_00407. URLhttps://aclanthology.org/2021.tacl-1.57/
-
[16]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Varun Chandola, Arindam Banerjee, and Vipin Kumar
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying, 2023. URL https://arxiv.org/abs/2304.13734
-
[18]
Reza Khanmohammadi, Erfan Miahi, Mehrsa Mardikoraem, Simerjot Kaur, Ivan Brugere, Charese Smiley, Kundan S Thind, and Mohammad M. Ghassemi. Calibrating LLM confi- dence by probing perturbed representation stability. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Me...
-
[19]
Same answer, different representations: Hidden instability in vlms, 2026
Farooq Ahmad Wani, Alessandro Suglia, Rohit Saxena, Aryo Pradipta Gema, Wai-Chung Kwan, Fazl Barez, Maria Sofia Bucarelli, Fabrizio Silvestri, and Pasquale Minervini. Same answer, different representations: Hidden instability in vlms, 2026. URL https://arxiv.org/abs/ 2602.06652
-
[20]
Weihao Xuan, Qingcheng Zeng, Heli Qi, Junjue Wang, and Naoto Yokoya. Seeing is believ- ing, but how much? a comprehensive analysis of verbalized calibration in vision-language models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Proces...
-
[21]
Yunpu Zhao, Rui Zhang, Junbin Xiao, Ruibo Hou, Jiaming Guo, Zihao Zhang, Yifan Hao, and Yunji Chen. Object-level verbalized confidence calibration in vision-language models via semantic perturbation, 2025. URLhttps://arxiv.org/abs/2504.14848
-
[22]
Confidence calibration for multimodal LLMs: An empirical study through medical VQA
Yuetian Du, Yucheng Wang, Ming Kong, Tian Liang, Qiang Long, Bingdi Chen, and Qiang Zhu. Confidence calibration for multimodal LLMs: An empirical study through medical VQA. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2025: 28th International Conference, Daejeon, South Korea, September 23–27, 2025, Proceedings, Part VI, page 89–99...
-
[23]
VL-Calibration: Decoupled Confidence Calibration for Large Vision-Language Models Reasoning
Wenyi Xiao, Xinchi Xu, and Leilei Gan. Vl-calibration: Decoupled confidence calibration for large vision-language models reasoning, 2026. URLhttps://arxiv.org/abs/2604.09529
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
T-VSL: text-guided visual sound source localization in mixtures
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13872–13882, 2024. doi: 10.1109/CVPR52733.2024.01316
-
[25]
Ruiyang Zhang, Hu Zhang, and Zhedong Zheng. Vl-uncertainty: Detecting hallucination in large vision-language model via uncertainty estimation, 2024. URL https://arxiv.org/abs/ 2411.11919. 13
-
[26]
Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang. Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens, 2025. URLhttps://arxiv.org/abs/2411.16724
-
[27]
Understanding the language prior of LVLMs by contrasting chain-of-embedding
Lin Long, Changdae Oh, Seongheon Park, and Sharon Li. Understanding language prior of lvlms by contrasting chain-of-embedding, 2026. URL https://arxiv.org/abs/2509.23050
-
[28]
Confidence calibration in vision-language-action models,
Thomas P Zollo and Richard Zemel. Confidence calibration in vision-language-action models,
- [29]
-
[30]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019
work page 2019
-
[31]
doi: 10.18653/v1/2023.emnlp-main.20
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 292–305, Singapore, December 2023. Association for Computational Lin- gui...
-
[32]
GMAI-MMBench: A comprehensive multimodal evaluation benchmark towards general medical AI
Pengcheng Chen, Jin Ye, Guoan Wang, Yanjun Li, Zhongying Deng, Wei Li, Tianbin Li, Haodong Duan, Ziyan Huang, Yanzhou Su, Benyou Wang, Shaoting Zhang, Bin Fu, Jianfei Cai, Bohan Zhuang, Eric J Seibel, Yu Qiao, and Junjun He. GMAI-MMBench: A comprehensive multimodal evaluation benchmark towards general medical AI. InProceedings of the 38th International Co...
work page 2024
-
[33]
Mme-finance: A multimodal finance benchmark for expert-level understanding and reasoning
Ziliang Gan, Dong Zhang, Haohan Li, Yang Wu, Xueyuan Lin, Ji Liu, Haipang Wu, Chaoyou Fu, Zenglin Xu, Rongjunchen Zhang, and Yong Dai. Mme-finance: A multimodal finance benchmark for expert-level understanding and reasoning. InProceedings of the 33rd ACM International Conference on Multimedia, MM ’25, page 12867–12874, New York, NY , USA,
-
[34]
Association for Computing Machinery. ISBN 9798400720352. doi: 10.1145/3746027. 3758230. URLhttps://doi.org/10.1145/3746027.3758230
-
[35]
MMMU -Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neubig. MMMU- pro: A more robust multi-discipline multimodal understanding benchmark. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Mee...
-
[36]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
work page 2023
-
[37]
Calibration-tuning: Teaching large language models to know what they don’t know
Sanyam Kapoor, Nate Gruver, Manley Roberts, Arka Pal, Samuel Dooley, Micah Goldblum, and Andrew Wilson. Calibration-tuning: Teaching large language models to know what they don’t know. In Raúl Vázquez, Hande Celikkanat, Dennis Ulmer, Jörg Tiedemann, Swabha Swayamdipta, Wilker Aziz, Barbara Plank, Joris Baan, and Marie-Catherine de Marneffe, editors,Procee...
work page 2024
-
[38]
Reza Khanmohammadi, Erfan Miahi, Simerjot Kaur, Charese Smiley, Ivan Brugere, Kundan S Thind, and Mohammad M. Ghassemi. How reliable are confidence estimators for large reasoning models? a systematic benchmark on high-stakes domains. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors,Proceedings of the 19th Conference of the European Chapter of the...
-
[39]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Improved baselines with visual instruction tuning, 2023
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2023
work page 2023
-
[41]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean-Bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, Zhenda Xie, Yu Wu, Kai Hu, Jiawei Wang, Yaofeng Sun, Yukun Li, Yishi Piao, Kang Guan, Aixin Liu, Xin Xie, Yuxiang You, Kai Dong, Xingkai Yu, Haowei Zhang, Liang Zhao, Yisong Wang, and Chong Ruan. Deepseek-vl2: Mixture-of-experts visio...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating 15 Systems Principles, SOSP ’23, page 611–626, New York, NY , USA, 2023. Association for Computing Mac...
-
[45]
Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C
Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision, 2014
work page 2014
-
[46]
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Reasoning models know when they’re right: Probing hidden states for self-verification, 2025. URL https://arxiv.org/abs/2504.05419
-
[47]
Arslan Chaudhry, Sridhar Thiagarajan, and Dilan Gorur. Finetuning language models to emit linguistic expressions of uncertainty, 2024. URLhttps://arxiv.org/abs/2409.12180
-
[48]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation, 2023. URL https://arxiv.org/ abs/2302.09664
work page internal anchor Pith review arXiv 2023
-
[49]
Uncertainty estimation in autoregressive structured prediction,
Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction,
- [50]
-
[51]
Op- tuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Op- tuna: A next-generation hyperparameter optimization framework. InThe 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2623–2631, 2019
work page 2019
-
[52]
Is there a {object} in the image?
Preetum Nakkiran, Arwen Bradley, Adam Goli´nski, Eugene Ndiaye, Michael Kirchhof, and Sinead Williamson. Trained on tokens, calibrated on concepts: The emergence of semantic calibration in llms, 2025. URLhttps://arxiv.org/abs/2511.04869. 16 Appendix Table of Contents A Large Vision-Language Model Backbones 18 B VLCB Benchmark Construction 20 B.1 Data Cura...
-
[53]
Read the question carefully
-
[54]
Compare the student’s answer to the ground truth answer
-
[55]
Consider semantic equivalence — answers that mean the same thing should be considered correct even if worded differently
-
[56]
yes” if the answer is correct, or “no
Return ONLY “yes” if the answer is correct, or “no” if it is incorrect
-
[57]
Be lenient with minor variations in wording, capitalization, or punctuation. Response Grading — User Prompt Question: {question} Ground Truth Answer: {ground_truth_answer} Student Answer: {generated_response} Is the student’s answer correct? (yes/no): 25 Multimodal input format.The image is passed to the judge as a separate multimodal input alongside the ...
-
[58]
Rephraseonlythe question stem (the text asking the question)
-
[59]
Append the EXACT same optionsin theEXACT same orderto the end of your rephrased question
-
[60]
Donotshuffle, reword, or modify the options in any way. • Allowed Changes:You may vary word order, sentence structure, and use strict synonyms for the question text. •Prohibited Changes:Donotadd new constraints, remove location details, or introduce ambiguity. Output Format: Each rephrased question should be wrapped in numbered tags like this: [question_1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.