Recognition: unknown
Instinct vs. Reflection: Unifying Token and Verbalized Confidence in Multimodal Large Models
Pith reviewed 2026-05-10 06:28 UTC · model grok-4.3
The pith
Multimodal models' token probabilities and verbal self-assessments often conflict, but a monotone fusion rule plus mean alignment produces better-calibrated confidence scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
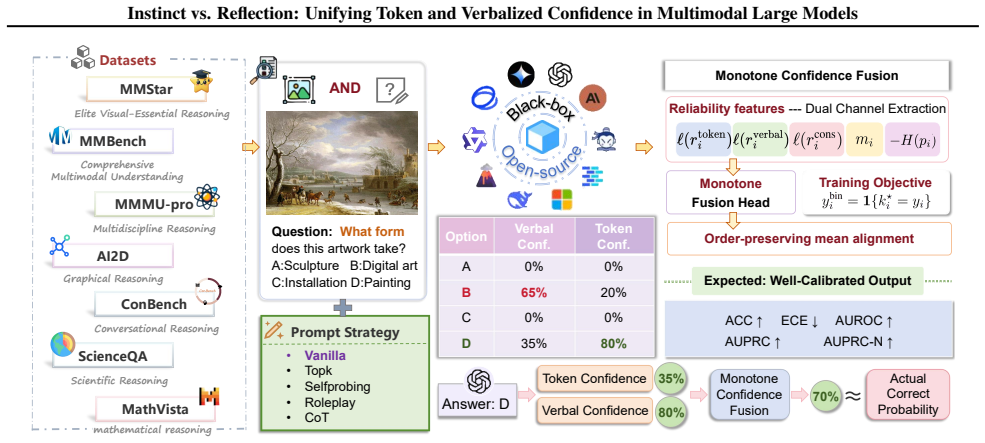
Multimodal LLMs exhibit instinct-reflection misalignment between implicit token-level support and verbalized self-assessment. A monotone confidence fusion framework merges these dual-channel signals by leveraging cross-channel consistency to estimate correctness. An order-preserving mean alignment step then corrects global bias, improving calibration while preserving the risk-coverage trade-off for selective prediction.
What carries the argument
Monotone confidence fusion framework that merges token probabilities and verbalized confidence using cross-channel consistency, followed by an order-preserving mean alignment to correct bias.
If this is right
- The fused scores give more reliable confidence estimates on diverse open-source and closed-source MLLMs.
- Calibration error decreases while the risk-coverage curve for selective prediction stays intact.
- Failure prediction improves because the combined signal better tracks actual correctness.
- The method avoids expensive self-consistency sampling by using only the existing token and verbal outputs.
Where Pith is reading between the lines
- The same fusion idea could be tested on text-only LLMs where token and verbal confidence also diverge.
- If the misalignment pattern proves consistent, a single learned fusion function might replace hand-crafted monotone rules.
- Task-specific alignment steps could further reduce residual bias on domains where global mean correction falls short.
Load-bearing premise
The observed instinct-reflection misalignment stays stable enough across tasks and models to be fixed by one monotone fusion rule and a single global mean alignment step without creating new errors.
What would settle it
On a held-out collection of MLLMs and tasks, applying the fusion and alignment fails to raise calibration metrics or worsens failure prediction performance compared with using either signal alone.
Figures




















read the original abstract
Multimodal Large Language Models (MLLMs) have demonstrated exceptional capabilities in various perception and reasoning tasks. Despite this success, ensuring their reliability in practical deployment necessitates robust confidence estimation. Prior works have predominantly focused on text-only LLMs, often relying on computationally expensive self-consistency sampling. In this paper, we extend this to multimodal settings and conduct a comprehensive evaluation of MLLMs' response confidence estimation. Our analysis reveals a significant instinct-reflection misalignment: the model's implicit token-level support frequently diverges from its verbal self-assessment confidence. To address this misalignment, we propose a monotone confidence fusion framework to merge dual-channel signals and cross-channel consistency to estimate correctness. Subsequently, an order-preserving mean alignment step is applied to correct global bias, which improves calibration while preserving the risk-coverage trade-off for selective prediction. Experiments on diverse open-source and closed-source MLLMs show that our method consistently yields more reliable confidence estimates and improves both calibration and failure prediction. Code will be available at https://github.com/Yunkaidang/Instinct-vs.-Reflection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that MLLMs exhibit a significant instinct-reflection misalignment between implicit token-level confidence and verbalized self-assessment. It proposes a monotone confidence fusion framework to merge these dual-channel signals via cross-channel consistency for correctness estimation, followed by an order-preserving mean alignment step to correct global bias. This is asserted to improve calibration and failure prediction while preserving risk-coverage trade-offs. Experiments across diverse open- and closed-source MLLMs are reported to yield consistently more reliable confidence estimates.
Significance. If the central claims hold, the work provides a lightweight, sampling-free approach to unifying dual confidence signals in multimodal settings, which could meaningfully advance reliable deployment of MLLMs. Strengths include evaluation on both open-source and closed-source models and the planned code release, which aids reproducibility. The focus on preserving selective-prediction properties is a positive design choice.
major comments (3)
- [§3] §3 (Method): The monotone confidence fusion framework and subsequent order-preserving mean alignment are described at a high level but without explicit equations, pseudocode, or implementation details for how token probabilities are mapped and fused with verbalized confidence (including determination of any fusion weights or thresholds). This is load-bearing for the central claim, as the reported improvements depend on these steps producing better-calibrated estimates without introducing new errors or violating monotonicity.
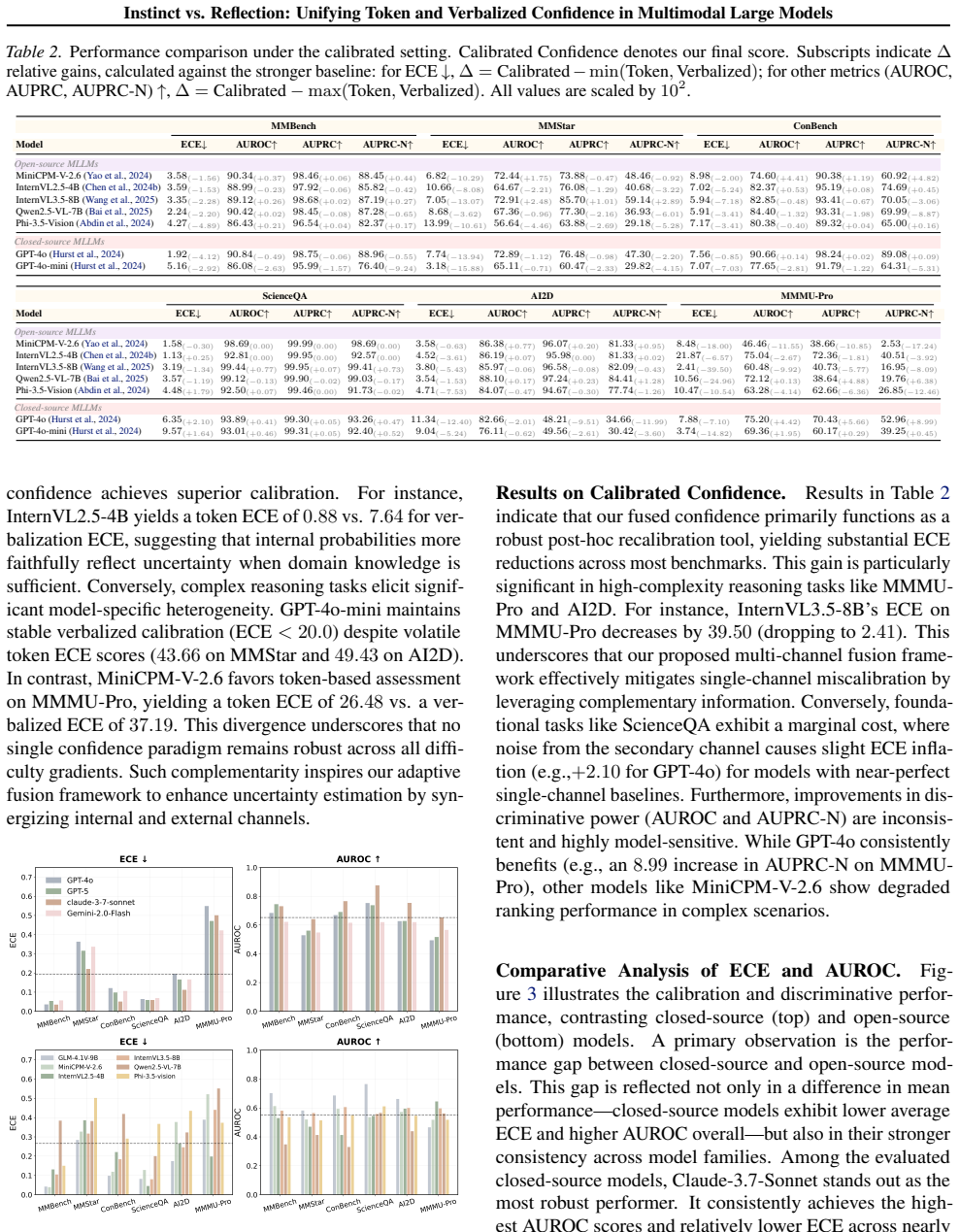
- [§4] §4 (Experiments): The abstract and summary state that the method 'consistently yields more reliable confidence estimates' and improves calibration/failure prediction, yet no quantitative results (e.g., ECE, Brier score, or AUROC values), ablation studies isolating fusion versus alignment, or details on parameter selection are supplied. This prevents verification that the improvements are not artifacts of the specific benchmarks or that the approach generalizes when misalignment varies across perception versus reasoning tasks.
- [§3.2] §3.2: The order-preserving mean alignment step assumes a stable, globally correctable bias between channels. If the misalignment pattern is non-monotonic or task-dependent (as could occur in vision-language settings), the single global shift risks degrading calibration on unseen data; no sensitivity analysis or task-stratified results are provided to support the assumption.
minor comments (2)
- [Abstract] The abstract would benefit from including one or two key quantitative metrics to substantiate the 'consistent improvements' claim.
- [§1] Define notation for 'instinct' (token-level) and 'reflection' (verbalized) signals explicitly in the introduction or §2 for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that greater methodological transparency, explicit quantitative results, and additional robustness checks will strengthen the paper. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [§3] §3 (Method): The monotone confidence fusion framework and subsequent order-preserving mean alignment are described at a high level but without explicit equations, pseudocode, or implementation details for how token probabilities are mapped and fused with verbalized confidence (including determination of any fusion weights or thresholds). This is load-bearing for the central claim, as the reported improvements depend on these steps producing better-calibrated estimates without introducing new errors or violating monotonicity.
Authors: We appreciate the referee's emphasis on reproducibility. The current description in §3 is indeed high-level. In the revised manuscript we will add the explicit equations for token-to-confidence mapping (normalized answer-token probability), the cross-channel consistency measure used for fusion, the weighted fusion formula, and the order-preserving mean alignment shift. We will also include pseudocode for the full pipeline and specify how fusion weights are derived from consistency and how any thresholds are selected on a validation split. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and summary state that the method 'consistently yields more reliable confidence estimates' and improves calibration/failure prediction, yet no quantitative results (e.g., ECE, Brier score, or AUROC values), ablation studies isolating fusion versus alignment, or details on parameter selection are supplied. This prevents verification that the improvements are not artifacts of the specific benchmarks or that the approach generalizes when misalignment varies across perception versus reasoning tasks.
Authors: We acknowledge that the experimental section would benefit from more granular reporting. While the manuscript already demonstrates consistent gains across open- and closed-source models, the revision will add explicit tables with ECE, Brier score, and AUROC numbers, plus risk-coverage curves. We will further include ablations that isolate the fusion step from the alignment step and report parameter-selection details together with separate results for perception versus reasoning tasks. revision: yes
-
Referee: [§3.2] §3.2: The order-preserving mean alignment step assumes a stable, globally correctable bias between channels. If the misalignment pattern is non-monotonic or task-dependent (as could occur in vision-language settings), the single global shift risks degrading calibration on unseen data; no sensitivity analysis or task-stratified results are provided to support the assumption.
Authors: The referee correctly identifies a key assumption. Our empirical observations across the evaluated models and tasks indicated that the channel bias is largely monotonic and globally correctable. To address potential task dependence, the revised version will add sensitivity analysis on the alignment shift parameter and task-stratified results (perception vs. reasoning). These additions will either corroborate the assumption or clearly delineate its limitations. revision: partial
Circularity Check
No circularity: empirical method proposed without self-referential reduction
full rationale
The paper reports an observed instinct-reflection misalignment in MLLMs, then introduces a monotone fusion framework plus order-preserving mean alignment as a corrective procedure. No equations, derivations, or self-citations are exhibited that would make the claimed calibration gains equivalent to a fitted parameter or input quantity defined from the same data by construction. The central claim rests on empirical evaluation across models rather than a closed logical loop, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- fusion weights or thresholds
- mean alignment offset
axioms (2)
- domain assumption Token probabilities constitute an implicit confidence signal distinct from verbalized self-assessment.
- domain assumption Cross-channel consistency is a reliable indicator of correctness.
invented entities (1)
-
monotone confidence fusion framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Grounded or Guessing? LVLM Confidence Estimation via Blind-Image Contrastive Ranking
BICR uses blind-image contrastive ranking on frozen LVLM hidden states to train a lightweight probe that penalizes confidence on blacked-out inputs, yielding top calibration and discrimination across five models and m...
Reference graph
Works this paper leans on
-
[1]
Letk ⋆ i = arg maxk pik andr token i = maxk pik
Token confidence channel (instinct).Compute option log-probabilities {zik}K k=1 at the answer position and form pi = softmax(zi)as in (2). Letk ⋆ i = arg maxk pik andr token i = maxk pik
-
[2]
A"..."D" or
Verbalized confidence channel (reflection).Prompt the MLLM to output per-option confidence (Appendix B.2); parse into si ∈[0,1] K and setr verbal i =s i,k⋆ i . 3.Cross-channel consistency.Computeκ ik by (4) and setr cons i =κ i,k⋆ i . 4.Features.Formϕ i by (9) usingℓ(·)in (10), margin (11), and entropy (12). Fitting:Standardize features using calibration-...
2025
-
[3]
confidence
"confidence" must be an integer in the range 0 to 100 (no extra symbols or text)
-
[4]
chosen_answer
"chosen_answer" must be one of "A", "B", "C", or "D"
-
[5]
Do not include any explanation or text outside of the JSON object
-
[6]
Here is your answer:
Do not wrap your JSON inside code fences or add any prefixes like "Here is your answer:"
-
[7]
Only the exact structure shown above
No additional keys are allowed. Only the exact structure shown above
-
[8]
confidence
Please ensure that the "confidence" values are output in the exact order corresponding to the options provided in the question. For example, if the question has N options (such as A, B, C, etc.), then the first "confidence" value must correspond to the first option, the second to the second option, and so on. Do not change or shuffle this order
-
[9]
confidence
When you assign the "confidence" value for each option, carefully consider: • The difficulty or complexity of the question, • The availability (or lack) of relevant knowledge, • Any ambiguity in the prompt or the attached image, • Other potential sources of uncertainty (e.g., incomplete reasoning). Your "confidence" should reflect how likely you believe t...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.