Recognition: 1 theorem link
· Lean TheoremHarmoWAM: Harmonizing Generalizable and Precise Manipulation via Adaptive World Action Models
Pith reviewed 2026-05-12 03:20 UTC · model grok-4.3
The pith
HarmoWAM unifies predictive and reactive control in world action models to deliver both generalization and precision for robot tasks in new settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
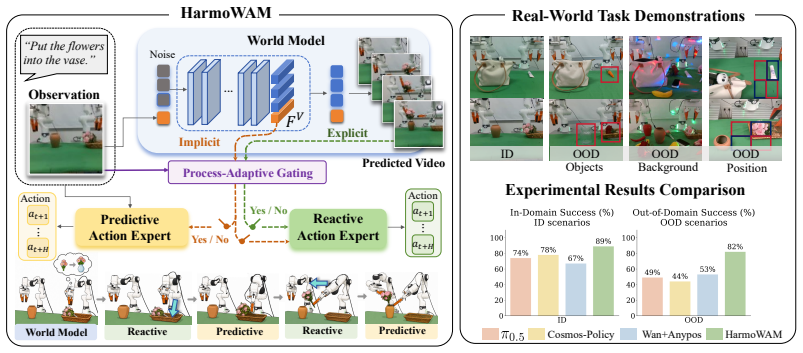
HarmoWAM conditions a predictive expert that iterates actions from latent dynamics and a reactive expert that infers actions from predicted visual evolution, both guided by the world model's spatio-temporal priors, while a Process-Adaptive Gating Mechanism selects the active expert at each moment to support generalizable transit and precise manipulation in one end-to-end model.
What carries the argument
The Process-Adaptive Gating Mechanism, which uses world-model priors to decide the timing and location for switching between the predictive expert and the reactive expert.
If this is right
- The world model expands the reactive expert's exploration space beyond the original training distribution.
- The predictive expert supplies precise control once the task reaches interaction stages.
- Zero-shot performance holds across changes in background, object position, and object semantics on real robots.
- End-to-end training removes the need for separate video-prediction and action modules.
Where Pith is reading between the lines
- The same gating logic could be added to other robot policies that already combine planning and immediate response.
- Longer sequences of tasks would test whether repeated gating decisions preserve coherence without drift.
- Adding explicit physical properties such as mass or friction to the world model priors might sharpen the reactive expert further.
Load-bearing premise
The world model supplies accurate spatio-temporal physical priors and the gating mechanism correctly identifies when and where to switch experts during a task.
What would settle it
A controlled test where the gating mechanism switches at the wrong stage on a precision-critical step in an unseen environment, producing a measurable drop in success rate compared with the reported margins.
Figures










read the original abstract
World Action Models (WAMs) have emerged as a promising paradigm for robot control by modeling physical dynamics. Current WAMs generally follow two paradigms: the "Imagine-then-Execute" approach, which uses video prediction to infer actions via inverse dynamics, and the "Joint Modeling" approach, which jointly models actions and video representations. Based on systematic experiments, we observe a fundamental trade-off between these paradigms: the former explicitly leverages world models for generalizable transit but lacks interaction precision, whereas the latter enables fine-grained, temporally coherent action generation but is constrained by the exploration space of the training distribution. Motivated by these findings, we propose HarmoWAM, an end-to-end WAM that fully leverages a world model to unify predictive and reactive control, enabling both generalizable transit and precise manipulation. Specifically, the world model provides spatio-temporal physical priors that condition two complementary action experts: a predictive expert that leverages latent dynamics for iterative action generation, and a reactive expert that directly infers actions from predicted visual evolution. To enable adaptive coordination, a Process-Adaptive Gating Mechanism is proposed to automatically determine the timing and location of switching between them. This allows the world model to drive the reactive expert to expand the exploration space and the predictive expert to perform precise interactions across different stages of a task. For evaluation, we construct three training-unseen test environments across six real-world robotic tasks, covering variations in background, position, and object semantics. Notably, HarmoWAM achieves strong zero-shot generalization across these scenarios, significantly outperforming prior state-of-the-art VLA models and WAMs by margins of 33% and 29%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing World Action Models exhibit a trade-off between generalizable transit in the 'Imagine-then-Execute' paradigm and precise manipulation in the 'Joint Modeling' paradigm. Motivated by this, HarmoWAM is proposed as an end-to-end WAM that leverages a world model to provide spatio-temporal physical priors conditioning a predictive expert (using latent dynamics for iterative action generation) and a reactive expert (directly inferring actions from predicted visual evolution), with a Process-Adaptive Gating Mechanism to adaptively switch between them. This enables both generalization and precision. On three training-unseen test environments across six real-world robotic tasks, it reports strong zero-shot generalization, outperforming prior SOTA VLA models and WAMs by 33% and 29% respectively.
Significance. If the results and method hold under detailed scrutiny, the work could be significant for robot learning by resolving a key trade-off in WAMs through adaptive unification of predictive and reactive control. The gating mechanism offers a potential new tool for task-stage adaptation. However, the provided manuscript supplies no supporting evidence, equations, or validation, so the significance cannot be assessed beyond the high-level motivation.
major comments (1)
- [Abstract] Abstract: The abstract reports performance margins of 33% and 29% on unseen test environments but supplies no experimental details, baselines, error bars, statistical analysis, task descriptions, or implementation specifics; the central claim of superior zero-shot generalization cannot be verified or stress-tested from the given information.
minor comments (1)
- [Abstract] Abstract: New components such as the 'Process-Adaptive Gating Mechanism' and 'spatio-temporal physical priors' are named without definitions, equations, or pseudocode, which reduces immediate clarity.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for clarity in the abstract. We address the single major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports performance margins of 33% and 29% on unseen test environments but supplies no experimental details, baselines, error bars, statistical analysis, task descriptions, or implementation specifics; the central claim of superior zero-shot generalization cannot be verified or stress-tested from the given information.
Authors: We agree that the abstract is intentionally concise and omits granular experimental details, as is conventional to respect length constraints. The full manuscript contains dedicated sections detailing the three training-unseen test environments, the six real-world robotic tasks (with variations in background, position, and object semantics), the baselines (prior SOTA VLA models and WAMs), error bars, statistical analysis, and implementation specifics that underpin the reported 33% and 29% improvements. These elements directly support the zero-shot generalization claims. If the referee recommends, we can revise the abstract to include one additional sentence summarizing the evaluation protocol and task coverage. revision: partial
Circularity Check
No significant circularity identified
full rationale
The abstract presents a high-level motivation from observed trade-offs in prior paradigms, followed by a proposed architecture using world-model priors and a Process-Adaptive Gating Mechanism. No equations, fitted parameters, or derivation steps are provided that reduce to self-definition or construction from inputs. The unification claim and performance results are stated as outcomes rather than tautological predictions. With only the abstract available and no self-citation chains or ansatz smuggling visible, the derivation chain remains self-contained and independent of its own results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption World models can supply useful spatio-temporal physical priors for conditioning action generation.
invented entities (1)
-
Process-Adaptive Gating Mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean; IndisputableMonolith/Foundation/DimensionForcing.lean; IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction; washburn_uniqueness_aczel; alexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the world model provides spatio-temporal physical priors that condition two complementary action experts: a predictive expert that leverages latent dynamics for iterative action generation, and a reactive expert that directly infers actions from predicted visual evolution. ... Process-Adaptive Gating Mechanism
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in Neural Information Processing Systems, 35:23716–23736, 2022
work page 2022
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doer- sch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, and Sean Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation.arXiv preprint arXiv:2409.16283, 2024
-
[4]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, et al. pi0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Rynnvla-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025
Jun Cen, Siteng Huang, Yuqian Yuan, Kehan Li, Hangjie Yuan, Chaohui Yu, Yuming Jiang, Jiayan Guo, Xin Li, Hao Luo, et al. Rynnvla-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025
-
[9]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
work page 2024
-
[12]
Hao Chen, Jiaming Liu, Chenyang Gu, Zhuoyang Liu, Renrui Zhang, Xiaoqi Li, Xiao He, Yandong Guo, Chi-Wing Fu, Shanghang Zhang, et al. Fast-in-slow: A dual-system foundation model unifying fast manipulation within slow reasoning.arXiv preprint arXiv:2506.01953, 2025
-
[13]
arXiv preprint arXiv:2509.22642 , year=
Xiaowei Chi, Peidong Jia, Chun-Kai Fan, Xiaozhu Ju, Weishi Mi, Kevin Zhang, Zhiyuan Qin, Wanxin Tian, Kuangzhi Ge, Hao Li, et al. Wow: Towards a world omniscient world model through embodied interaction.arXiv preprint arXiv:2509.22642, 2025
-
[14]
Lightewm: Light embodied world model, 2026
LightEWM Community. Lightewm: Light embodied world model, 2026
work page 2026
-
[15]
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023. 11
work page 2023
-
[16]
Yao Feng, Hengkai Tan, Xinyi Mao, Chendong Xiang, Guodong Liu, Shuhe Huang, Hang Su, and Jun Zhu. Vidar: Embodied video diffusion model for generalist manipulation.arXiv preprint arXiv:2507.12898, 2025
-
[17]
Chenyang Gu, Jiaming Liu, Hao Chen, Runzhong Huang, Qingpo Wuwu, Zhuoyang Liu, Xiaoqi Li, Ying Li, Renrui Zhang, Peng Jia, et al. Manualvla: A unified vla model for chain-of-thought manual generation and robotic manipulation.arXiv preprint arXiv:2512.02013, 2025
-
[18]
Video prediction policy: A generalist robot policy with predictive visual representations, 2025
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations, 2025
work page 2025
-
[19]
${\pi}_{0.7}$: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, et al. pi0.7: a steerable gen- eralist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
π0.5: a vision-language-action model with open-world generalization, 2025
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, et al. π0.5: a vision-language-action model with open-world generalization, 2025
work page 2025
-
[21]
Dreamgen: Unlocking generalization in robot learning through video world models, 2025
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, Loic Magne, Ajay Mandlekar, Avnish Narayan, You Liang Tan, Guanzhi Wang, Jing Wang, Qi Wang, Yinzhen Xu, Xiaohui Zeng, Kaiyuan Zheng, Ruijie Zheng, Ming-Yu Liu, Luke Zettlemoyer, Dieter Fox, Jan Kautz, Scott Reed, Yuke Zh...
work page 2025
-
[22]
Video2act: A dual-system video diffusion policy with robotic spatio-motional modeling, 2026
Yueru Jia, Jiaming Liu, Shengbang Liu, Rui Zhou, Wanhe Yu, Yuyang Yan, Xiaowei Chi, Yandong Guo, Boxin Shi, and Shanghang Zhang. Video2act: A dual-system video diffusion policy with robotic spatio-motional modeling, 2026
work page 2026
-
[23]
Prismatic vlms: Investigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[24]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
work page internal anchor Pith review arXiv 2026
-
[27]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review arXiv 2026
-
[29]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page Pith review arXiv 2024
-
[30]
Unified video action model, 2025
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model, 2025. 12
work page 2025
-
[31]
Manipllm: Embodied multimodal large language model for object-centric robotic manipulation
Xiaoqi Li, Mingxu Zhang, Yiran Geng, Haoran Geng, Yuxing Long, Yan Shen, Renrui Zhang, Jiaming Liu, and Hao Dong. Manipllm: Embodied multimodal large language model for object-centric robotic manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18061–18070, 2024
work page 2024
-
[32]
Video generators are robot policies, 2025
Junbang Liang, Pavel Tokmakov, Ruoshi Liu, Sruthi Sudhakar, Paarth Shah, Rares Ambrus, and Carl V ondrick. Video generators are robot policies, 2025
work page 2025
-
[33]
Genie envisioner: A unified world foundation platform for robotic manipulation, 2025
Yue Liao, Pengfei Zhou, Siyuan Huang, Donglin Yang, Shengcong Chen, Yuxin Jiang, Yue Hu, Jingbin Cai, Si Liu, Jianlan Luo, Liliang Chen, Shuicheng Yan, Maoqing Yao, and Guanghui Ren. Genie envisioner: A unified world foundation platform for robotic manipulation, 2025
work page 2025
-
[34]
Onetwovla: A unified vision-language-action model with adaptive reasoning
Fanqi Lin, Ruiqian Nai, Yingdong Hu, Jiacheng You, Junming Zhao, and Yang Gao. Onet- wovla: A unified vision-language-action model with adaptive reasoning.arXiv preprint arXiv:2505.11917, 2025
-
[35]
Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model.arXiv preprint arXiv:2503.10631, 2025
-
[36]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Zhuoyang Liu, Jiaming Liu, Hao Chen, Jiale Yu, Ziyu Guo, Chengkai Hou, Chenyang Gu, Xiangju Mi, Renrui Zhang, Kun Wu, et al. Last _{0}: Latent spatio-temporal chain-of-thought for robotic vision-language-action model.arXiv preprint arXiv:2601.05248, 2026
-
[38]
Weishi Mi, Yong Bao, Xiaowei Chi, Xiaozhu Ju, Zhiyuan Qin, Kuangzhi Ge, Kai Tang, Peidong Jia, Shanghang Zhang, and Jian Tang. Tc-idm: Grounding video generation for executable zero-shot robot motion.arXiv preprint arXiv:2601.18323, 2026
-
[39]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Jonas Pai, Liam Achenbach, Victoriano Montesinos, Benedek Forrai, Oier Mees, and Elvis Nava. mimic-video: Video-action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692, 2025
-
[42]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[44]
Perceiver-actor: A multi-task transformer for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
work page 2023
-
[45]
AnyPos: Automated Task-Agnostic Actions for Bimanual Manipulation
Hengkai Tan, Yao Feng, Xinyi Mao, Shuhe Huang, Guodong Liu, Zhongkai Hao, Hang Su, and Jun Zhu. Anypos: Automated task-agnostic actions for bimanual manipulation.arXiv preprint arXiv:2507.12768, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
arXiv preprint arXiv:2412.03293 , year=
Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chaomin Shen, et al. Diffusion-vla: Scaling robot foundation models via unified diffusion and autoregression.arXiv preprint arXiv:2412.03293, 2024
-
[49]
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
work page 2025
-
[50]
Dual-stream diffusion for world-model augmented vision-language-action model, 2025
John Won, Kyungmin Lee, Huiwon Jang, Dongyoung Kim, and Jinwoo Shin. Dual- stream diffusion for world-model augmented vision-language-action model.arXiv preprint arXiv:2510.27607, 2025
-
[51]
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation.arXiv preprint arXiv:2312.13139, 2023
work page internal anchor Pith review arXiv 2023
-
[52]
Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation,
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, et al. Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation.arXiv preprint arXiv:2412.13877, 2024
-
[53]
Gigaworld-policy: An efficient action- centered world–action model, 2026
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, et al. Gigaworld-policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026
-
[54]
World action models are zero-shot policies, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, Jimmy Wu, Qi ...
work page 2026
-
[55]
Fast-wam: Do world action models need test-time future imagination?, 2026
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?, 2026
work page 2026
-
[56]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
work page 2023
-
[57]
Flare: Robot learning with implicit world modeling, 2025
Ruijie Zheng, Jing Wang, Scott Reed, Johan Bjorck, Yu Fang, Fengyuan Hu, Joel Jang, Kaushil Kundalia, Zongyu Lin, Loic Magne, et al. Flare: Robot learning with implicit world modeling. arXiv preprint arXiv:2505.15659, 2025
-
[58]
Act2goal: From world model to general goal-conditioned policy, 2025
Pengfei Zhou, Liliang Chen, Shengcong Chen, Di Chen, Wenzhi Zhao, Rongjun Jin, Guanghui Ren, and Jianlan Luo. Act2goal: From world model to general goal-conditioned policy.arXiv preprint arXiv:2512.23541, 2025
-
[59]
Siyuan Zhou, Yilun Du, Jiaben Chen, Yandong Li, Dit-Yan Yeung, and Chuang Gan. Ro- bodreamer: Learning compositional world models for robot imagination.arXiv preprint arXiv:2404.12377, 2024
-
[60]
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets, 2025
work page 2025
-
[61]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In7th Annual Conference on Robot Learning, 2023. 14 Appendix A Real-World Set-up Single-Arm Configuration.As shown in Figure 6, our single-arm plat...
work page 2023
-
[62]
S1: grasp and place banana; S2: grasp and place carrot
Pick Fruit to Plate.The robot sequentially picks up a banana and a carrot and places them onto a plate. S1: grasp and place banana; S2: grasp and place carrot. The average length is approximately 280 steps and is sequentially evaluated. A stage is considered successful if the robot successfully grasps the corresponding object and places it stably on the p...
-
[63]
S1: place the second can beside the first; S2: place the third can on top
Stack Coke Cans.The robot stacks three cans one by one, demanding highly precise spatial alignment. S1: place the second can beside the first; S2: place the third can on top. The average length is approximately 290 steps and is sequentially evaluated. S1 is considered successful if the robot places the second can beside the first can with stable contact a...
-
[64]
S1: grasp bottle; S2: pour into beaker
Pour Coke into Beaker.The robot grasps a bottle and pours its contents into a beaker, testing fine- grained rotational control. S1: grasp bottle; S2: pour into beaker. The average length is approximately 310 steps and is sequentially evaluated. S1 is considered successful if the robot securely grasps and 15 lifts the bottle, and S2 is considered successfu...
-
[65]
Yes”.The robot picks up a marker and writes “Y
Write “Yes”.The robot picks up a marker and writes “Y”, “e”, “s” on a whiteboard in sequence. S1: write “Y”; S2: write “e”; S3: write “s”. The average length is approximately 310 steps and is sequentially evaluated. A stage is considered successful if the robot writes the corresponding character legibly on the whiteboard. Dual-Arm Tasks
-
[66]
S1: pick flower; S2: bimanual handover; S3: insert into vase
Put Flowers in Vase.The left arm picks a flower and hands it to the right arm, which inserts it into a vase, requiring precise bimanual coordination and tight-tolerance insertion. S1: pick flower; S2: bimanual handover; S3: insert into vase. The average length is approximately 280 steps and is sequentially evaluated. S1 is considered successful if the lef...
-
[67]
Put Items to Bag and Zip.Both arms collaborate to place items into a bag and zip it closed, which is the longest-horizon task. S1 →S 2: pick up item and place into bag; S3 →S 4 →S 5: one arm grips the bag to hold it steady, the other grips and pulls the zipper to close. The average length is approximately 400 steps and is sequentially evaluated. S1 is con...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.