Recognition: 3 theorem links
· Lean TheoremContext-Gated Associative Retrieval: From Theory to Transformers
Pith reviewed 2026-05-13 01:28 UTC · model grok-4.3
The pith
Context gating in associative memory models exponentially improves retrieval by increasing separation and sparsity, and this mechanism explains in-context learning in transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors propose context-gated associative retrieval, wherein a context-gate subcircuit modifies the energy landscape to increase inter-memory separation and induce sparsity. They prove this yields exponential retrieval improvements and that the overall system admits a unique self-consistent fixed point driven by a direct contextual bias together with a second-order retrieval-gate feedback loop. When instantiated as a first-order approximation inside Llama-3, the same dynamics appear: context localizes a relevant memory subspace, enabling the zero-shot query to discriminate cleanly.
What carries the argument
The context-gate subcircuit, which reshapes the retrieval energy landscape before and during recall to enforce greater separation and sparsity.
If this is right
- Retrieval accuracy scales exponentially with the separation and sparsity induced by the context gate.
- The final retrieval state is uniquely fixed by the joint action of direct contextual bias and the second-order feedback loop.
- In-context learning inside transformers such as Llama-3 operates as context-gated retrieval.
- Context localizes a memory subspace that permits clean zero-shot query discrimination.
Where Pith is reading between the lines
- Explicit context-gating layers could be added to transformer architectures to improve performance on tasks that require precise recall of stored information.
- The same separation-and-sparsity principle may illuminate why attention heads in large models often focus on narrow subspaces during few-shot prompting.
- Testing whether retrieval error rates in modified Hopfield networks follow the predicted exponential scaling would provide a direct experimental check.
- The fixed-point analysis might be extended to study stability in other recurrent or memory-augmented neural architectures.
Load-bearing premise
The context-gate subcircuit can be realized as a practical modification to the energy landscape without destroying the fixed-point guarantees, and the first-order approximation applied to Llama-3 faithfully captures the native dynamics of in-context learning.
What would settle it
A direct numerical simulation of a Hopfield network augmented with the context-gate subcircuit that either confirms or refutes the predicted exponential improvement in retrieval accuracy and the existence of a unique self-consistent fixed point.
Figures








read the original abstract
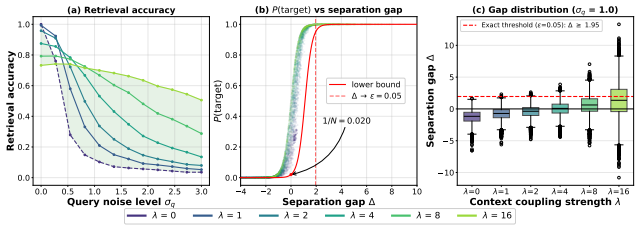
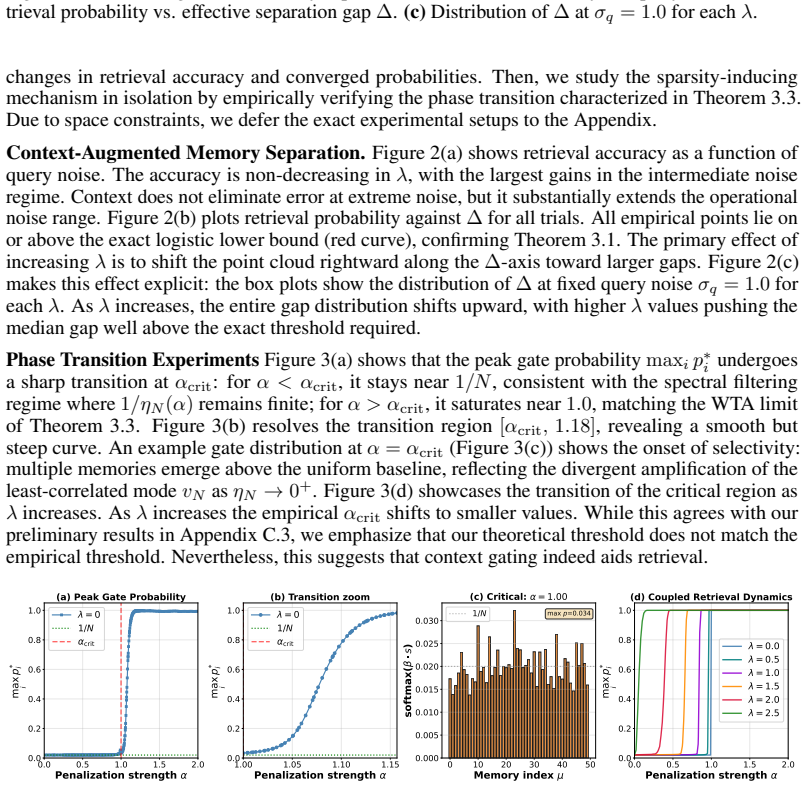
Hopfield networks and their generalizations have established deep connections among biological associative memories, statistical physics, and transformers. Yet most models treat retrieval as a fixed query-to-memory mapping, ignoring the role of external context in recall. In this work, we propose a two-stage associative memory architecture, wherein a context-gate subcircuit reshapes the retrieval energy landscape before and during recall. We show theoretically that context gating increases inter-memory separation while inducing sparsity, translating into exponential improvements in retrieval. Crucially, we prove that the system admits a unique self-consistent fixed point, revealing that the resulting retrieval state is driven by both a direct contextual bias and a second-order retrieval-gate feedback loop. We then bridge this theory to transformers; specifically, we evaluate a first-order approximation on Llama-3, confirming that in-context learning acts as context-gated retrieval. Native dynamics mirror our theory: context localizes a memory subspace, enabling the zero-shot query to cleanly discriminate. Ultimately, this framework provides a mechanistic link between associative memory theory and LLM phenomenology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a two-stage associative memory model with a context-gate subcircuit that modifies the retrieval energy landscape to increase inter-memory separation and induce sparsity. It claims theoretical results showing exponential retrieval gains from this gating and proves that the system has a unique self-consistent fixed point driven by direct contextual bias plus a second-order retrieval-gate feedback loop. The work then maps the theory to transformers via a first-order approximation evaluated on Llama-3, arguing that in-context learning corresponds to context-gated retrieval where context localizes a memory subspace.
Significance. If the uniqueness of the fixed point is rigorously established after the landscape modification and the Llama-3 approximation is shown to faithfully capture native dynamics, the framework would offer a concrete mechanistic link between Hopfield-style associative memory and LLM in-context learning phenomenology. This could explain how external context shapes retrieval without destroying convergence guarantees, with potential implications for both theoretical neuroscience and practical transformer interpretability.
major comments (2)
- [Theoretical analysis] Theoretical derivation of the fixed point (the section presenting the self-consistent fixed-point proof): no explicit conditions are supplied on how the context-gate term alters the effective field, the Lipschitz constant of the map, or the spectral properties of the Jacobian/Hessian. Without these, it is unclear whether the reshaping preserves global uniqueness or contraction, which is load-bearing for both the exponential improvement claim and the asserted second-order feedback loop.
- [Empirical evaluation] Llama-3 evaluation section: the confirmation that 'native dynamics mirror our theory' is presented at high level with no quantitative metrics (e.g., retrieval accuracy, subspace localization measures), no ablation of the first-order approximation, and no controls comparing against standard in-context learning baselines. This directly affects the validity of the claimed mechanistic bridge to transformers.
minor comments (2)
- [Abstract] Abstract: states the existence of a 'unique self-consistent fixed point' and 'exponential improvements' but provides no scaling relation, error bounds, or derivation outline, forcing the reader to consult the full text for even basic assessment.
- [Model definition] Notation and definitions: the precise functional form of the context-gate subcircuit and how it is added to the original Hopfield energy (additive term, multiplicative modulation, etc.) should be stated explicitly in the first theoretical section to make the landscape-reshaping claim reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. The feedback identifies important opportunities to strengthen both the theoretical rigor and the empirical validation of our claims. We address each major comment below and commit to revisions that will clarify the fixed-point analysis and provide quantitative support for the transformer mapping.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical derivation of the fixed point (the section presenting the self-consistent fixed-point proof): no explicit conditions are supplied on how the context-gate term alters the effective field, the Lipschitz constant of the map, or the spectral properties of the Jacobian/Hessian. Without these, it is unclear whether the reshaping preserves global uniqueness or contraction, which is load-bearing for both the exponential improvement claim and the asserted second-order feedback loop.
Authors: We agree that the fixed-point section would benefit from explicit conditions. The existing proof treats the context-gate as a bounded, Lipschitz-continuous perturbation of the base associative dynamics and shows that the composite map remains contractive for sufficiently small gate strength. In the revised manuscript we will add a dedicated subsection deriving the precise bounds: (i) an upper limit on the Lipschitz constant of the gate function that keeps the overall map's Lipschitz constant below 1, (ii) the resulting spectral-radius condition on the Jacobian, and (iii) a Hessian-based argument confirming local uniqueness of the fixed point. These additions will make the contraction-mapping argument fully rigorous while preserving the claimed exponential retrieval gains and the second-order feedback interpretation. revision: yes
-
Referee: [Empirical evaluation] Llama-3 evaluation section: the confirmation that 'native dynamics mirror our theory' is presented at high level with no quantitative metrics (e.g., retrieval accuracy, subspace localization measures), no ablation of the first-order approximation, and no controls comparing against standard in-context learning baselines. This directly affects the validity of the claimed mechanistic bridge to transformers.
Authors: We concur that the Llama-3 results require quantitative grounding. In the revision we will augment the evaluation section with: (i) retrieval accuracy on a held-out query set, (ii) subspace-localization metrics (e.g., average cosine similarity between the context-induced attention subspace and the retrieved key subspace), (iii) an ablation comparing the first-order approximation against the full second-order dynamics, and (iv) direct comparisons against standard in-context learning baselines (vanilla few-shot prompting and random-context controls). These metrics will be reported with statistical significance and will directly test whether context gating improves separation and sparsity in the model's native activations. revision: yes
Circularity Check
No significant circularity; derivation chain remains self-contained
full rationale
The abstract presents a two-stage architecture with a claimed theoretical proof of a unique self-consistent fixed point arising from direct contextual bias plus second-order feedback. This is asserted as derived from the energy-landscape reshaping rather than fitted or self-defined. The transformer connection is an empirical first-order approximation evaluated on Llama-3, not a reduction of the fixed-point result to its own inputs. No load-bearing self-citations, ansatz smuggling, or renaming of known results appear in the provided text, and the uniqueness claim is not shown to collapse by construction to the gate definition itself.
Axiom & Free-Parameter Ledger
invented entities (1)
-
context-gate subcircuit
no independent evidence
Lean theorems connected to this paper
-
Cost/FunctionalEquationwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Theorem 3.4 (Self-consistent Retrieval): ... if βλ²/(2η_min(α)) < 1, the subsystem has a unique fixed point. ... p* = Φ_α,λ(p*) ... contraction mapping
-
Foundation/AlphaCoordinateFixationJ_uniquely_calibrated_via_higher_derivative echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
context gating increases the effective separation gap between memories ... Δ = Δ_raw + λ Δ_gate ... exponential improvements in retrieval
-
Foundation/ArithmeticFromLogicembed_add echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the resulting retrieval state is driven by both a direct contextual bias and a second-order retrieval-gate feedback loop
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Simone Betteti, Giacomo Baggio, Francesco Bullo, and Sandro Zampieri. Input-driven dynamics for robust memory retrieval in Hopfield networks.Science Advances, 11(17):eadu6991, 2025
work page 2025
-
[2]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
work page 2020
-
[3]
Thomas F Burns, Tomoki Fukai, and Christopher J Earls. Associative memory inspires im- provements for in-context learning using a novel attention residual stream architecture, 2025
work page 2025
-
[4]
Moulik Choraria, Xinbo Wu, Akhil Bhimaraju, Nitesh Sekhar, Yue Wu, Xu Zhang, Prateek Singhal, and Lav R. Varshney. DeepInsert: Early layer bypass for efficient and performant multi- modal understanding. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors,Proceedings of the 19th Conference of the European Chapter of the Association for Computational ...
work page 2026
-
[5]
Mete Demircigil, Judith Heusel, Matthias Löwe, Sven Upgang, and Franck Vermet. On a model of associative memory with huge storage capacity.Journal of Statistical Physics, 168(2):288– 299, May 2017
work page 2017
-
[6]
Understanding task vectors in in-context learning: Emergence, functionality, and limitations, 2025
Yuxin Dong, Jiachen Jiang, Zhihui Zhu, and Xia Ning. Understanding task vectors in in-context learning: Emergence, functionality, and limitations, 2025
work page 2025
-
[7]
Guttenplan, Isa Maxwell, Erin Santos, Luke A
Kevin A. Guttenplan, Isa Maxwell, Erin Santos, Luke A. Borchardt, Ernesto Manzo, Leire Abalde-Atristain, Rachel D. Kim, and Marc R. Freeman. Gpcr signaling gates astrocyte responsiveness to neurotransmitters and control of neuronal activity.Science, 388(6748):763– 768, 2025
work page 2025
-
[8]
In-context learning creates task vectors, 2023
Roee Hendel, Mor Geva, and Amir Globerson. In-context learning creates task vectors, 2023
work page 2023
-
[9]
J J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558, 1982
work page 1982
-
[10]
J J Hopfield. Neurons with graded response have collective computational properties like those of two-state neurons.Proceedings of the National Academy of Sciences, 81(10):3088–3092, 1984
work page 1984
-
[11]
On sparse modern hopfield model
Jerry Yao-Chieh Hu, Donglin Yang, Dennis Wu, Chenwei Xu, Bo-Yu Chen, and Han Liu. On sparse modern hopfield model. InThirty-seventh Conference on Neural Information Processing Systems, 2023. 10
work page 2023
-
[12]
Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang. Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens. InProc. Comput. Vis. Pattern Recog. (CVPR), pages 25004– 25014, 2025
work page 2025
-
[13]
Mohadeseh Shafiei Kafraj, Dmitry Krotov, and Peter E. Latham. A biologically plausible dense associative memory with exponential capacity. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[14]
Noise-enhanced associative memories
Amin Karbasi, Amir Hesam Salavati, Amin Shokrollahi, and Lav Varshney. Noise-enhanced associative memories. In C.J. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Weinberger, editors,Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc., 2013
work page 2013
-
[15]
Hierarchical associative memory, 2021
Dmitry Krotov. Hierarchical associative memory, 2021
work page 2021
-
[16]
Modern methods in associative memory, 2025
Dmitry Krotov, Benjamin Hoover, Parikshit Ram, and Bao Pham. Modern methods in associative memory, 2025
work page 2025
- [17]
-
[18]
Lefton, Yifan Wu, Yanchao Dai, Takao Okuda, Yufen Zhang, Allen Yen, Gareth M
Katheryn B. Lefton, Yifan Wu, Yanchao Dai, Takao Okuda, Yufen Zhang, Allen Yen, Gareth M. Rurak, Sarah Walsh, Rachel Manno, Bat-Erdene Myagmar, Joseph D. Dougherty, Vijay K. Samineni, Paul C. Simpson, and Thomas Papouin. Norepinephrine signals through astrocytes to modulate synapses.Science, 388(6748):776–783, 2025
work page 2025
-
[19]
Xin Li and Dan Roth. Learning question classifiers. InProceedings of the 19th International Conference on Computational Linguistics - Volume 1, COLING ’02, page 1–7, USA, 2002. Association for Computational Linguistics
work page 2002
-
[20]
Sheng Liu, Haotian Ye, Lei Xing, and James Zou. In-context vectors: Making in context learning more effective and controllable through latent space steering, 2024
work page 2024
-
[21]
Interpreting key mechanisms of factual recall in transformer-based language models
Ang Lv, Yuhan Chen, Kaiyi Zhang, Yulong Wang, Lifeng Liu, Ji-Rong Wen, Jian Xie, and Rui Yan. Interpreting key mechanisms of factual recall in transformer-based language models. arXiv 2403.19521 [cs.CL], 2024
-
[22]
A mechanism for solving relational tasks in transformer language models, 2024
Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. A mechanism for solving relational tasks in transformer language models, 2024
work page 2024
-
[23]
The Waluigi effect (mega-post)
Cleo Nardo. The Waluigi effect (mega-post). AI Alignment Forum, March 2023. Accessed: 2026-02-07
work page 2023
-
[24]
Eshaan Nichani, Jason D. Lee, and Alberto Bietti. Understanding factual recall in transformers via associative memories, 2024
work page 2024
-
[25]
The linear representation hypothesis and the geometry of large language models, 2024
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models, 2024
work page 2024
-
[26]
Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, and Sebastian Riedel. Language models as knowledge bases?, 2019
work page 2019
-
[27]
Zaki, Luca Ambrogioni, and Dmitry Krotov
Bao Pham, Gabriel Raya, Matteo Negri, Mohammed J. Zaki, Luca Ambrogioni, and Dmitry Krotov. Memorization to generalization: Emergence of diffusion models from associative memory, 2025
work page 2025
-
[28]
William F. Podlaski, Everton J. Agnes, and Tim P. V ogels. High capacity and dynamic accessi- bility in associative memory networks with context-dependent neuronal and synaptic gating. Phys. Rev. X, 15:011057, Mar 2025
work page 2025
-
[29]
Hopfield networks is all you need.arXiv preprint arXiv:2008.02217, 2020
Hubert Ramsauer, Bernhard Schäfl, Johannes Lehner, Philipp Seidl, Michael Widrich, Thomas Adler, Lukas Gruber, Markus Holzleitner, Milena Pavlovi´c, Geir Kjetil Sandve, et al. Hopfield networks is all you need.arXiv preprint arXiv:2008.02217, 2020. 11
-
[30]
Saul Santos, Vlad Niculae, Daniel McNamee, and Andre F.T. Martins. Hopfield-fenchel-young networks: A unified framework for associative memory retrieval.Journal of Machine Learning Research, 26(265):1–51, 2025
work page 2025
-
[31]
S. M. Smith and E. Vela. Environmental context-dependent memory: A review and meta- analysis.Psychonomic Bulletin&Review, 8(2):203–220, 2001
work page 2001
-
[32]
Manning, Andrew Ng, and Christopher Potts
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In David Yarowsky, Timothy Baldwin, Anna Korhonen, Karen Livescu, and Steven Bethard, editors,Proceedings of the 2013 Conference on Empirical Methods in Natural Lang...
work page 2013
-
[33]
Function vectors in large language models
Eric Todd, Millicent Li, Arnab Sen Sharma, Aaron Mueller, Byron C Wallace, and David Bau. Function vectors in large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[34]
Silvana Valtcheva and Laurent Venance. Astrocytes gate hebbian synaptic plasticity in the striatum.Nature Communications, 7(1):13845, Dec 2016
work page 2016
-
[35]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[36]
In-context learning as conditioned associative memory retrieval
Weimin Wu, Teng-Yun Hsiao, Jerry Yao-Chieh Hu, Wenxin Zhang, and Han Liu. In-context learning as conditioned associative memory retrieval. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[37]
Unifying attention heads and task vectors via hidden state geometry in in-context learning
Haolin Yang, Hakaze Cho, Yiqiao Zhong, and Naoya Inoue. Unifying attention heads and task vectors via hidden state geometry in in-context learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[38]
Character-level convolutional networks for text classification, 2016
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification, 2016. 12 A Primer: General Dense Associative Memories A.1 Modular Energy Framework Here, we provide a brief introduction on the generalized abstraction of Energy-based AMs (HAMUX), introduced by [16]. At a high level, dense associative memories (DAMs) ...
work page 2016
-
[39]
Choose convex LagrangianL x(x)for each neuron layer (defines activation function)
-
[40]
Design hypersynapse energiesE synapse s encoding desired relationships
-
[41]
Total energy: sum of all neuron and hypersynapse energies
-
[42]
Dynamics: minimize energy via local gradient descent (Eq. 2)
-
[43]
Guaranteed convergence with bounded activations 14 B Modern Hopfield Networks To keep this work self-contained, we provide a brief introduction to Modern Hopfield Networks (MHN) ([29]). MHNs are a form of DAM with an energy function of the form E=−lse(β, X T ξ) + 1 2 ξT ξ+β −1 logN+ 1 2 M2 (16) where lse(β,·) is the LogSumExp function with temperature par...
-
[44]
Of particular interest in this paper are Theorems 4 and 5
provide theorems to guarantee convergence for this form of Associative Memory and further establishes an exponential storage capacity (see Theorems 1, 2, and 3 in their paper). Of particular interest in this paper are Theorems 4 and 5. Theorem B.1(Theorem 4 in [ 29]).With query ξ, pattern xi, fixed point x∗ i , and separation of xi to other memories ∆i, a...
-
[45]
byW V whereW K ∈R dy×dk,W Q ∈R dr×dk,W V ∈R dk×dv. If we combine everything into matrix operations as is commonly done for attention, we arrive at the following. Let Y= (y 1, . . . , yN)T , R= (r 1, . . . , rN)T . Define X T =K=Y W K, ΞT =Q=RW Q, and V=Y W KWV =X T WV . Let the temperature parameter in MHN β= 1√dk and let the output of softmax be a row-ve...
-
[46]
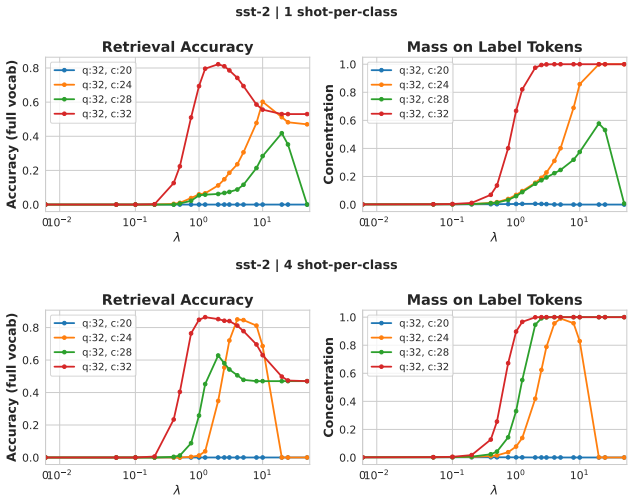
on the AG-News dataset. 010 2 10 1 100 101 0.0 0.1 0.2 0.3Accuracy (full vocab) Retrieval Accuracy q:32, c:20 q:32, c:24 q:32, c:28 q:32, c:32 010 2 10 1 100 101 0.0 0.2 0.4 0.6 0.8 1.0Concentration Mass on Label Tokens q:32, c:20 q:32, c:24 q:32, c:28 q:32, c:32 trec | 1 shot-per-class 010 2 10 1 100 101 0.0 0.1 0.2 0.3 0.4Accuracy (full vocab) Retrieval...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.