Recognition: no theorem link
PASA: A Principled Embedding-Space Watermarking Approach for LLM-Generated Text under Semantic-Invariant Attacks
Pith reviewed 2026-05-13 01:09 UTC · model grok-4.3
The pith
PASA embeds watermarks in LLM semantic embedding space to detect generated text after paraphrasing without distorting output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PASA constructs a distributional dependency between token sequences and auxiliary sequences by synchronizing randomness with a secret key and semantic history inside semantic clusters of the latent embedding space. This construction is derived from a theoretical characterization of jointly optimal embedding and detection functions that balance detection accuracy, robustness to semantic-invariant changes, and zero distortion. Experiments on multiple LLMs show the resulting watermark survives strong paraphrasing attacks at higher rates than vocabulary-space baselines while leaving text quality unchanged.
What carries the argument
Semantic clusters in the latent embedding space together with shared-randomness distributional dependency synchronized by secret key and semantic history, which enables joint optimization of embedding and detection.
If this is right
- Detection accuracy stays high after semantic-preserving rewrites that defeat token-level methods.
- Generated text quality remains comparable to unwatermarked output because no token bias is introduced.
- The theoretical trade-off surface among accuracy, robustness, and distortion is achieved by the embedding-detection pair.
- Hyperparameter choices validated by ablation directly support the observed robustness without quality loss.
Where Pith is reading between the lines
- If the synchronization mechanism holds, similar semantic-level dependencies could be applied to other generative models where meaning must survive transformation.
- The approach implies that watermark verification can be performed on rewritten text without needing the original prompt or intermediate tokens.
- Success here would motivate checking whether the same cluster-and-dependency pattern reduces false positives when watermarking is combined with other detection signals.
Load-bearing premise
Semantic clusters can be formed reliably in the embedding space and the synchronized randomness produces a distributional dependency that delivers the stated optimality and robustness without creating detectable artifacts or exploitable weaknesses.
What would settle it
Running the strongest paraphrasing attack described in the paper on PASA-watermarked text and finding detection accuracy no higher than that of a standard vocabulary-space watermark, or finding statistical patterns in the output that reveal the watermark without knowledge of the secret key.
Figures



read the original abstract
Watermarking for large language models (LLMs) is a promising approach for detecting LLM-generated text and enabling responsible deployment. However, existing watermarking methods are often vulnerable to semantic-invariant attacks, such as paraphrasing. We propose PASA, a principled, robust, and distortion-free watermarking algorithm that embeds and detects a watermark at the semantic level. PASA operates on semantic clusters in a latent embedding space and constructs a distributional dependency between token and auxiliary sequences via shared randomness synchronized by a secret key and semantic history. This design is grounded in our theoretical framework that characterizes a jointly optimal embedding-detection pair, achieving the fundamental trade-offs among detection accuracy, robustness, and distortion. Evaluations across multiple LLMs and semantic-invariant attacks demonstrate that PASA remains robust even under strong paraphrasing attacks while preserving high text quality, outperforming standard vocabulary-space baselines. Ablation studies further validate the effectiveness of our hyperparameter choices. Webpage: https://ai-kunkun.github.io/PASA_page/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PASA, a watermarking algorithm for LLM-generated text that embeds and detects watermarks in a latent embedding space using semantic clusters. It constructs distributional dependencies via shared randomness synchronized by a secret key and semantic history, grounded in a theoretical framework characterizing jointly optimal embedding-detection pairs that trade off detection accuracy, robustness, and distortion. Evaluations across LLMs and semantic-invariant attacks (including strong paraphrasing) claim superior robustness and text quality compared to vocabulary-space baselines, with ablations validating hyperparameter choices.
Significance. If the theoretical optimality derivation holds and the reported robustness metrics are reproducible under the described attack strengths, PASA would represent a meaningful advance in LLM watermarking by addressing the vulnerability of prior methods to paraphrasing and other semantic-preserving transformations. The embedding-space approach and explicit focus on joint optimality are strengths that could inform future designs.
major comments (2)
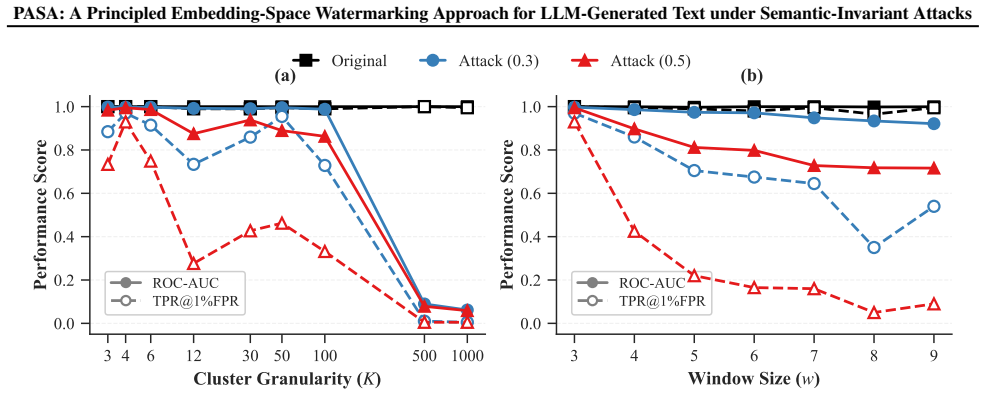
- [§3.1–3.3] §3.1–3.3 (theoretical framework): the characterization of jointly optimal embedding-detection pairs relies on semantic cluster construction and randomness synchronization; the derivation should explicitly show whether optimality is parameter-free or reduces to choices of cluster granularity and history window length, as these appear among the free parameters.
- [§4.3] §4.3 (experimental results on paraphrasing): the claim of remaining robust under strong paraphrasing requires quantitative attack details (e.g., semantic similarity thresholds, paraphrase model, number of rewrites) and effect sizes with error bars; without these, the outperformance over vocabulary baselines cannot be fully assessed as load-bearing evidence.
minor comments (2)
- [Abstract] Abstract: quantitative metrics, specific LLMs tested, and attack strengths are referenced but not summarized; adding one sentence with key numbers would improve clarity.
- [§5] §5 (ablations): ensure all tested hyperparameter ranges and the exact cluster construction algorithm (including any embedding model) are listed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating planned revisions where appropriate to improve clarity and completeness.
read point-by-point responses
-
Referee: [§3.1–3.3] §3.1–3.3 (theoretical framework): the characterization of jointly optimal embedding-detection pairs relies on semantic cluster construction and randomness synchronization; the derivation should explicitly show whether optimality is parameter-free or reduces to choices of cluster granularity and history window length, as these appear among the free parameters.
Authors: We appreciate the referee highlighting this aspect of the theoretical framework. The derivation of jointly optimal embedding-detection pairs is performed conditionally on a fixed semantic cluster granularity and history window length; these are treated as design hyperparameters that control the granularity of the semantic partitioning and the extent of distributional dependence. The optimality result characterizes the fundamental trade-offs for any given choice of these parameters rather than claiming parameter-free optimality. In the revised manuscript we will add an explicit statement in §3 clarifying this conditional nature and include a brief discussion of how varying cluster granularity and window length affect the achievable accuracy-robustness-distortion frontier. revision: yes
-
Referee: [§4.3] §4.3 (experimental results on paraphrasing): the claim of remaining robust under strong paraphrasing requires quantitative attack details (e.g., semantic similarity thresholds, paraphrase model, number of rewrites) and effect sizes with error bars; without these, the outperformance over vocabulary baselines cannot be fully assessed as load-bearing evidence.
Authors: We agree that additional quantitative details are required to make the robustness claims fully reproducible and to allow readers to assess the strength of the reported outperformance. The current manuscript describes the paraphrasing attacks at a high level but does not enumerate the exact paraphrase model, similarity thresholds, number of rewrites, or report error bars. In the revision we will expand §4.3 (and the experimental setup subsection) to specify the paraphrase model, the semantic similarity thresholds employed, the number of rewrites applied, and to present all detection metrics with error bars computed across multiple independent runs. These additions will enable direct evaluation of the evidence. revision: yes
Circularity Check
No significant circularity; theoretical framework presented as independent grounding
full rationale
The abstract grounds the PASA design in a theoretical framework characterizing jointly optimal embedding-detection pairs and trade-offs among accuracy, robustness, and distortion. No equations or self-citations are supplied in the given material that would reduce this framework to a redefinition of the algorithm's own cluster-construction or randomness parameters. Evaluations on multiple LLMs and attacks are described as external validation, with no indication that predictions reduce by construction to fitted inputs or prior self-citations. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- semantic cluster construction parameters
- randomness synchronization threshold or history window
axioms (2)
- domain assumption Semantic clusters in the latent embedding space exist and can be reliably identified across paraphrases
- domain assumption A jointly optimal embedding-detection pair exists and is characterized by the theoretical framework
Reference graph
Works this paper leans on
-
[1]
Watermarking of large language models
Aaronson, S. Watermarking of large language models. https://simons.berkeley.edu/talks/scott-aaronson-ut-austin-openai-2023-08-17, 2023. Accessed: 2023-08
work page 2023
-
[2]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report. https://arxiv.org/abs/2303.08774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Balalle, H. and Pannilage, S. Reassessing academic integrity in the age of ai: A systematic literature review on ai and academic integrity. Social Sciences & Humanities Open, 11: 0 101299, 2025
work page 2025
-
[4]
Gpt-neox-20b: An open-source autoregressive language model
Black, S., Biderman, S., Hallahan, E., Anthony, Q., Gao, L., Golding, L., He, H., Leahy, C., McDonell, K., Phang, J., et al. Gpt-neox-20b: An open-source autoregressive language model. In Proceedings of BigScience Episode\# 5--Workshop on Challenges & Perspectives in Creating Large Language Models, 2022
work page 2022
-
[5]
Towards Better Statistical Understanding of Watermarking LLMs
Cai, Z., Liu, S., Wang, H., Zhong, H., and Li, X. Towards better statistical understanding of watermarking llms. arXiv preprint arXiv:2403.13027, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Scalable watermarking for identifying large language model outputs
Dathathri, S., See, A., Ghaisas, S., Huang, P.-S., McAdam, R., Welbl, J., Bachani, V., Kaskasoli, A., Stanforth, R., Matejovicova, T., et al. Scalable watermarking for identifying large language model outputs. Nature, 2024
work page 2024
-
[7]
Can mllms guide me home? a benchmark study on fine-grained visual reasoning from transit maps
Feng, S., Wang, S., Ouyang, S., Kong, L., Song, Z., Zhu, J., Wang, H., and Wang, X. Can mllms guide me home? a benchmark study on fine-grained visual reasoning from transit maps. arXiv preprint arXiv:2505.18675, 2025
-
[8]
G umbel S oft: Diversified language model watermarking via the G umbel M ax-trick
Fu, J., Zhao, X., Yang, R., Zhang, Y., Chen, J., and Xiao, Y. G umbel S oft: Diversified language model watermarking via the G umbel M ax-trick. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024 a
work page 2024
-
[9]
Fu, Y., Xiong, D., and Dong, Y. Watermarking conditional text generation for ai detection: unveiling challenges and a semantic-aware watermark remedy. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advan...
work page 2024
-
[10]
Giboulot, E. and Furon, T. Watermax: breaking the LLM watermark detectability-robustness-quality trade-off. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[11]
L., Liang, P., and Hashimoto, T
Gu, C., Li, X. L., Liang, P., and Hashimoto, T. On the learnability of watermarks for language models. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[12]
Gumbel, E. J. Statistical theory of extreme values and some practical applications: a series of lectures, volume 33. US Government Printing Office, 1954
work page 1954
-
[13]
Context-aware watermark with semantic balanced green-red lists for large language models
Guo, Y., Tian, Z., Song, Y., Liu, T., Ding, L., and Li, D. Context-aware watermark with semantic balanced green-red lists for large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
work page 2024
-
[14]
Large language models can be used to effectively scale spear phishing campaigns
Hazell, J. Spear phishing with large language models. arXiv preprint arXiv:2305.06972, 2023
-
[15]
Theoretically grounded framework for LLM watermarking: A distribution-adaptive approach
He, H., Liu, Y., Wang, Z., Mao, Y., and Bu, Y. Theoretically grounded framework for LLM watermarking: A distribution-adaptive approach. In The 1st Workshop on GenAI Watermarking, 2025
work page 2025
-
[16]
He, Z., Zhou, B., Hao, H., Liu, A., Wang, X., Tu, Z., Zhang, Z., and Wang, R. Can watermarks survive translation? on the cross-lingual consistency of text watermark for large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024
work page 2024
-
[17]
S em S tamp: A semantic watermark with paraphrastic robustness for text generation
Hou, A., Zhang, J., He, T., Wang, Y., Chuang, Y.-S., Wang, H., Shen, L., Van Durme, B., Khashabi, D., and Tsvetkov, Y. S em S tamp: A semantic watermark with paraphrastic robustness for text generation. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume ...
work page 2024
-
[18]
k- S em S tamp: A clustering-based semantic watermark for detection of machine-generated text
Hou, A., Zhang, J., Wang, Y., Khashabi, D., and He, T. k- S em S tamp: A clustering-based semantic watermark for detection of machine-generated text. In Findings of the Association for Computational Linguistics: ACL 2024, 2024 b
work page 2024
-
[19]
Huang, B., Zhu, B., Zhu, H., Lee, J. D., Jiao, J., and Jordan, M. I. Towards optimal statistical watermarking. arXiv preprint arXiv:2312.07930, 2023
-
[20]
Jiang, D., Liu, Y., Liu, S., Zhao, J., Zhang, H., Gao, Z., Zhang, X., Li, J., and Xiong, H. From clip to dino: Visual encoders shout in multi-modal large language models. arXiv preprint arXiv:2310.08825, 2023
-
[21]
Mergemix: A unified augmentation paradigm for visual and multi-modal understanding
Jin, X., Li, S., Jian, S., Yu, K., and Wang, H. Mergemix: A unified augmentation paradigm for visual and multi-modal understanding. arXiv preprint arXiv:2510.23479, 2025
-
[22]
A watermark for large language models
Kirchenbauer, J., Geiping, J., Wen, Y., Katz, J., Miers, I., and Goldstein, T. A watermark for large language models. In Proceedings of the 40th International Conference on Machine Learning, 2023
work page 2023
-
[23]
On the reliability of watermarks for large language models
Kirchenbauer, J., Geiping, J., Wen, Y., Shu, M., Saifullah, K., Kong, K., Fernando, K., Saha, A., Goldblum, M., and Goldstein, T. On the reliability of watermarks for large language models. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[24]
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense
Krishna, K., Song, Y., Karpinska, M., Wieting, J., and Iyyer, M. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense. Advances in Neural Information Processing Systems, 36, 2023
work page 2023
-
[25]
Robust distortion-free watermarks for language models
Kuditipudi, R., Thickstun, J., Hashimoto, T., and Liang, P. Robust distortion-free watermarks for language models. Transactions on Machine Learning Research, 2024
work page 2024
-
[26]
Li, X., Ruan, F., Wang, H., Long, Q., and Su, W. J. A statistical framework of watermarks for large language models: Pivot, detection efficiency and optimal rules. The Annals of Statistics, 53 0 (1): 0 322--351, 2025
work page 2025
-
[27]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Li, Z., Zhang, X., Zhang, Y., Long, D., Xie, P., and Zhang, M. Towards general text embeddings with multi-stage contrastive learning. arXiv preprint arXiv:2308.03281, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
A semantic invariant robust watermark for large language models
Liu, A., Pan, L., Hu, X., Meng, S., and Wen, L. A semantic invariant robust watermark for large language models. In The Twelfth International Conference on Learning Representations, 2024 a
work page 2024
-
[29]
A semantic invariant robust watermark for large language models
Liu, A., Pan, L., Hu, X., Meng, S., and Wen, L. A semantic invariant robust watermark for large language models. In International Conference on Learning Representations, 2024 b
work page 2024
-
[30]
A survey of text watermarking in the era of large language models
Liu, A., Pan, L., Lu, Y., Li, J., Hu, X., Zhang, X., Wen, L., King, I., Xiong, H., and Yu, P. A survey of text watermarking in the era of large language models. ACM Comput. Surv., 57 0 (2), 2024 c
work page 2024
-
[31]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Y. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
- [32]
-
[33]
Least squares quantization in pcm
Lloyd, S. Least squares quantization in pcm. IEEE transactions on information theory, 28 0 (2): 0 129--137, 1982
work page 1982
-
[34]
The threat of offensive ai to organizations
Mirsky, Y., Demontis, A., Kotak, J., Shankar, R., Gelei, D., Yang, L., Zhang, X., Pintor, M., Lee, W., Elovici, Y., et al. The threat of offensive ai to organizations. Computers & Security, 124: 0 103006, 2023
work page 2023
-
[35]
Language models are unsupervised multitask learners
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. Language models are unsupervised multitask learners. OpenAI blog, 1 0 (8): 0 9, 2019
work page 2019
-
[36]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21 0 (1), 2020
work page 2020
-
[37]
Enhancing LLM watermark resilience against both scrubbing and spoofing attacks
Shen, H., Huang, B., and Wan, X. Enhancing LLM watermark resilience against both scrubbing and spoofing attacks. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[38]
Necessary and sufficient watermark for large language models
Takezawa, Y., Sato, R., Bao, H., Niwa, K., and Yamada, M. Necessary and sufficient watermark for large language models. arXiv preprint arXiv:2310.00833, 2023
-
[39]
Lvomnibench: Pioneering long audio-video understanding evaluation for omnimodal llms
Tao, K., Zheng, Y., Xu, J., Du, W., Shao, K., Wang, H., Chen, X., Jin, X., Zhu, J., Yu, B., et al. Lvomnibench: Pioneering long audio-video understanding evaluation for omnimodal llms. arXiv preprint arXiv:2603.19217, 2026
-
[40]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M., Lacroix, T., Rozi \` e re, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lample, G. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Disinformation capabilities of large language models
Vykopal, I., Pikuliak, M., Srba, I., Moro, R., Macko, D., and Bielikova, M. Disinformation capabilities of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 14830--14847, 2024
work page 2024
-
[42]
Optimizing watermarks for large language models
Wouters, B. Optimizing watermarks for large language models. In International Conference on Machine Learning, pp.\ 53251--53269. PMLR, 2024
work page 2024
-
[43]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. https://arxiv.org/abs/2505.09388, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Watermarking for large language models: A survey
Yang, Z., Zhao, G., and Wu, H. Watermarking for large language models: A survey. Mathematics, 13 0 (9), 2025 b
work page 2025
-
[45]
Cohemark: A novel sentence-level watermark for enhanced text quality
Zhang, J., Liu, S., Liu, A., Gao, Y., Li, J., Gu, X., and Hu, X. Cohemark: A novel sentence-level watermark for enhanced text quality. In The 1st Workshop on GenAI Watermarking, 2025 a
work page 2025
-
[46]
Poison as cure: Visual noise for mitigating object hallucinations in lvms
Zhang, K., Tao, K., Tang, J., and Wang, H. Poison as cure: Visual noise for mitigating object hallucinations in lvms. In NeurIPS, 2025 b
work page 2025
-
[47]
TinyLlama: An Open-Source Small Language Model
Zhang, P., Zeng, G., Wang, T., and Lu, W. Tinyllama: An open-source small language model. arXiv preprint arXiv:2401.02385, 2024 a
work page internal anchor Pith review arXiv 2024
-
[48]
S., Neekhara, P., and Koushanfar, F
Zhang, R., Hussain, S. S., Neekhara, P., and Koushanfar, F. REMARK-LLM : A robust and efficient watermarking framework for generative large language models. In 33rd USENIX Security Symposium (USENIX Security 24), 2024 b
work page 2024
-
[49]
V., Mihaylov, T., Ott, M., Shleifer, S., Shuster, K., Simig, D., Koura, P
Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X. V., Mihaylov, T., Ott, M., Shleifer, S., Shuster, K., Simig, D., Koura, P. S., Sridhar, A., Wang, T., and Zettlemoyer, L. Opt: Open pre-trained transformer language models, 2022
work page 2022
-
[50]
Zhao, X., Ananth, P. V., Li, L., and Wang, Y.-X. Provable robust watermarking for AI -generated text. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[51]
Obs-diff: Accurate pruning for diffusion models in one-shot
Zhu, J., Wang, H., Su, M., Wang, Z., and Wang, H. Obs-diff: Accurate pruning for diffusion models in one-shot. arXiv preprint arXiv:2510.06751, 2025 a
-
[52]
Revisiting Image Manipulation Localization under Realistic Manipulation Scenarios
Zhu, X., Zhou, J.-Z., Feng, K., Qu, C., Wang, Y., Zhou, L., and Liu, J. Does the manipulation process matter? rita: Reasoning composite image manipulations via reversely-ordered incremental-transition autoregression. arXiv preprint arXiv:2509.20006, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.