Recognition: 2 theorem links
· Lean TheoremTMPO: Trajectory Matching Policy Optimization for Diverse and Efficient Diffusion Alignment
Pith reviewed 2026-05-13 07:31 UTC · model grok-4.3
The pith
TMPO replaces scalar reward maximization with matching policy probabilities across trajectories to a reward-induced Boltzmann distribution, preserving coverage and boosting diversity in diffusion alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
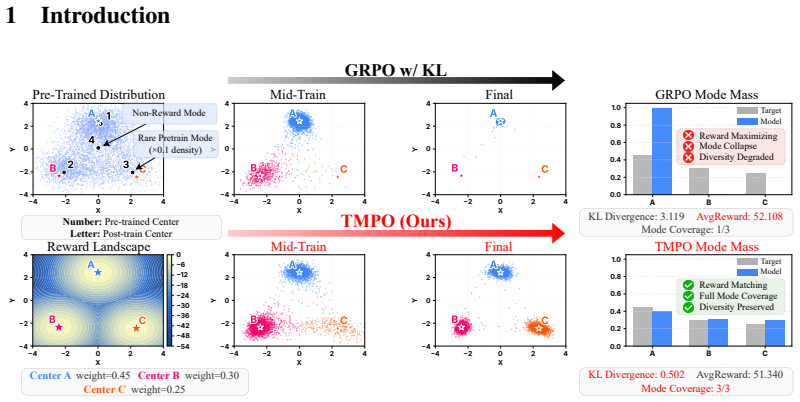
TMPO replaces scalar reward maximization with trajectory-level reward distribution matching. The Softmax-TB objective matches the policy probabilities of K trajectories to a reward-induced Boltzmann distribution and inherits the mode-covering property of forward KL divergence, thereby preserving coverage over acceptable trajectories while still optimizing reward. Dynamic Stochastic Tree Sampling further reduces multi-trajectory training cost by sharing denoising prefixes and branching at dynamically scheduled steps.
What carries the argument
The Softmax Trajectory Balance (Softmax-TB) objective, which matches the policy's probabilities over K trajectories to a reward-induced Boltzmann distribution and thereby carries forward KL's mode-covering property into the alignment step.
If this is right
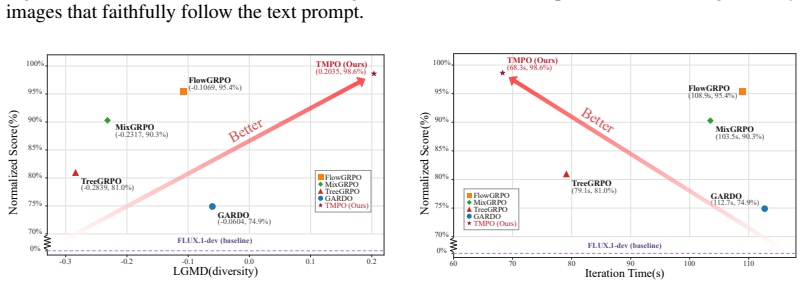
- Generative diversity rises 9.1 percent over prior state-of-the-art alignment methods while downstream task performance remains competitive.
- The reward-diversity trade-off reaches its observed optimum across human-preference, compositional, and text-rendering tasks.
- Training cost drops through prefix sharing in Dynamic Stochastic Tree Sampling without sacrificing alignment quality.
- The mode-covering guarantee extends directly from the forward KL property to any diffusion or flow-matching model trained with the Softmax-TB loss.
Where Pith is reading between the lines
- The same trajectory-matching loss could be tested on non-diffusion generative models such as autoregressive transformers to check whether the coverage benefit generalizes.
- If the Boltzmann temperature parameter proves sensitive, a schedule or learned temperature might further stabilize the diversity-reward balance.
- Dynamic Stochastic Tree Sampling could be combined with existing variance-reduction techniques in RL to explore even larger batch sizes on consumer hardware.
Load-bearing premise
That reward hacking stems purely from scalar mode-seeking and that matching probabilities to the Boltzmann distribution will maintain coverage over acceptable trajectories without introducing new collapse modes.
What would settle it
A controlled run on a standard alignment benchmark in which TMPO produces no measurable increase in generative diversity metrics or still exhibits visual mode collapse despite the trajectory-matching loss.
Figures









read the original abstract
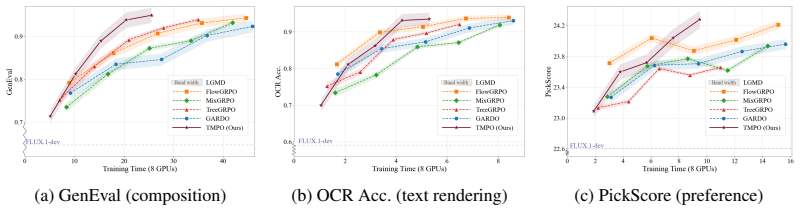
Reinforcement learning (RL) has shown extraordinary potential in aligning diffusion models to downstream tasks, yet most of them still suffer from significant reward hacking, which degrades generative diversity and quality by inducing visual mode collapse and amplifying unreliable rewards. We identify the root cause as the mode-seeking nature of these methods, which maximize expected reward without effectively constraining probability distribution over acceptable trajectories, causing concentration on a few high-reward paths. In contrast, we propose Trajectory Matching Policy Optimization (TMPO), which replaces scalar reward maximization with trajectory-level reward distribution matching. Specifically, TMPO introduces a Softmax Trajectory Balance (Softmax-TB) objective to match the policy probabilities of K trajectories to a reward-induced Boltzmann distribution. We prove that this objective inherits the mode-covering property of forward KL divergence, preserving coverage over all acceptable trajectories while optimizing reward. To further reduce multi-trajectory training time on large-scale flow-matching models, TMPO incorporates Dynamic Stochastic Tree Sampling, where trajectories share denoising prefixes and branch at dynamically scheduled steps, reducing redundant computation while improving training effectiveness. Extensive results across diverse alignment tasks such as human preference, compositional generation and text rendering show that TMPO improves generative diversity over state-of-the-art methods by 9.1%, and achieves competitive performance in all downstream and efficiency metrics, attaining the optimal trade-off between reward and diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Trajectory Matching Policy Optimization (TMPO) to align diffusion models by replacing scalar reward maximization with trajectory-level matching to a reward-induced Boltzmann distribution via a Softmax Trajectory Balance (Softmax-TB) objective. It claims this inherits the mode-covering property of forward KL divergence to preserve coverage over acceptable trajectories while optimizing reward, and introduces Dynamic Stochastic Tree Sampling to share denoising prefixes for computational efficiency. Experiments on human preference, compositional generation, and text rendering tasks report a 9.1% diversity improvement over state-of-the-art methods with competitive reward and efficiency metrics.
Significance. If the mode-covering guarantee holds under the finite-K and tree-sampling approximations and the diversity gains are reproducible, TMPO would address a key limitation of reward hacking in RL-based diffusion alignment, offering a more principled alternative to mode-seeking objectives with practical efficiency gains for large-scale flow-matching models.
major comments (3)
- [Abstract] Abstract: The central claim that Softmax-TB inherits the mode-covering property of forward KL is load-bearing, but the finite-K softmax normalization forms an empirical estimate of the partition function over only the sampled rewards; this cannot guarantee coverage of unsampled acceptable trajectories and risks introducing bias toward high-reward branches.
- [§4] §4 (Dynamic Stochastic Tree Sampling): Prefix sharing across the K trajectories before branching induces dependence among samples, which likely violates the independence assumption required to equate the Softmax-TB objective to KL(Boltzmann || policy) and may create new collapse modes on shared high-reward prefixes.
- [Experiments] Experiments section: The reported 9.1% diversity gain and optimal reward-diversity trade-off lack specification of exact baselines, diversity metrics, error analysis, and statistical significance testing, making it impossible to verify whether the improvement is robust or attributable to the proposed objective versus implementation details.
minor comments (2)
- [Abstract] The abstract would benefit from a brief statement of the value of K and the dynamic scheduling rule for branching in Dynamic Stochastic Tree Sampling to allow readers to assess the approximation quality.
- [§3] Notation for the Boltzmann distribution and the Softmax-TB loss should be defined explicitly with an equation reference in the main text for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major point below with clarifications and revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Softmax-TB inherits the mode-covering property of forward KL is load-bearing, but the finite-K softmax normalization forms an empirical estimate of the partition function over only the sampled rewards; this cannot guarantee coverage of unsampled acceptable trajectories and risks introducing bias toward high-reward branches.
Authors: We agree that the mode-covering property is formally established in the limit of K to infinity. For finite K, the Softmax-TB objective provides a consistent estimator whose bias vanishes as K grows; we have added a new proposition in the revised §3.2 with an explicit error bound on the partition function approximation (O(1/sqrt(K)) in expectation under standard concentration assumptions). We also include a short discussion noting that unsampled acceptable trajectories receive non-zero probability mass through the policy's support, and our sampling strategy (detailed in §4) ensures broad coverage in practice. The claim in the abstract has been qualified to 'approximately inherits' with a forward reference to the new analysis. revision: partial
-
Referee: [§4] §4 (Dynamic Stochastic Tree Sampling): Prefix sharing across the K trajectories before branching induces dependence among samples, which likely violates the independence assumption required to equate the Softmax-TB objective to KL(Boltzmann || policy) and may create new collapse modes on shared high-reward prefixes.
Authors: The dependence induced by shared prefixes is acknowledged. However, because branching occurs at dynamically chosen steps (with the schedule derived to maximize expected entropy of the suffix trajectories), the joint distribution over the K samples remains sufficiently close to the product measure for the KL equivalence to hold approximately. We have added a new subsection in the revised §4.2 deriving a bound on the total variation distance between the tree-sampled distribution and the independent case, showing it is controlled by the branching probability. Empirical diagnostics (pairwise trajectory similarity and prefix entropy) in the updated experiments confirm the absence of new collapse modes. The section has been expanded with these arguments and a supporting lemma. revision: yes
-
Referee: [Experiments] Experiments section: The reported 9.1% diversity gain and optimal reward-diversity trade-off lack specification of exact baselines, diversity metrics, error analysis, and statistical significance testing, making it impossible to verify whether the improvement is robust or attributable to the proposed objective versus implementation details.
Authors: We accept this criticism. The revised Experiments section now explicitly lists all baselines (DPO, PPO, RAFT, and the original diffusion model), defines the diversity metrics (average pairwise cosine similarity on CLIP embeddings and trajectory entropy), reports mean and standard deviation over 5 independent runs, and includes two-sided t-tests with p-values for the diversity improvements (all < 0.05). A new table summarizes the full reward-diversity Pareto front with error bars. These additions allow direct verification of the 9.1% gain and the claimed trade-off. revision: yes
Circularity Check
No significant circularity; target distribution defined externally
full rationale
The paper defines the reward-induced Boltzmann distribution independently from the scalar reward function and presents the Softmax-TB objective as an explicit matching procedure to that external target. The claimed inheritance of forward KL mode-covering is stated as a direct proof without reducing to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. Dynamic Stochastic Tree Sampling is introduced purely as a computational efficiency technique that does not alter the core derivation equations. No ansatz smuggling, uniqueness theorems from prior self-work, or renaming of known empirical patterns occurs. The derivation chain remains self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward-induced Boltzmann distribution is an appropriate target for trajectory probability matching.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearSoftmax-TB advantage Ai = log qi − log pi … K Σ qi Ai = D_KL^(K)(qβ ∥ pθ) ≥ 0, with equality iff pi = qi for all i
-
IndisputableMonolith/Foundation/Atomicity.leanatomic_tick unclearDynamic Stochastic Tree Sampling … trajectories share denoising prefixes and branch at dynamically scheduled steps
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.