Recognition: no theorem link
An Execution-Verified Multi-Language Benchmark for Code Semantic Reasoning
Pith reviewed 2026-05-13 00:59 UTC · model grok-4.3
The pith
TraceEval supplies execution-verified call graphs from real programs so models can be tested on recovering actual runtime structure from source code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
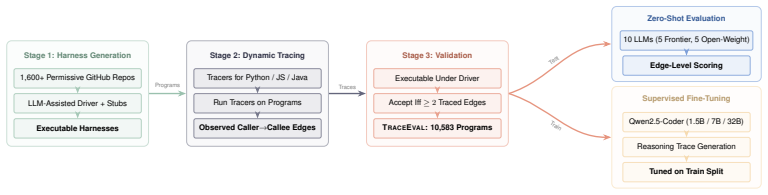
TraceEval is a multi-language collection of 10,583 programs whose runtime call structures have been mechanically witnessed through execution tracing, providing the first large-scale, label-noise-free test of whether language models can recover a program's dynamic call relationships directly from source.
What carries the argument
The execution-verified call-graph recovery task, in which every retained edge must be observed during actual program runs with tracer validation.
If this is right
- Language models can be fine-tuned on the training split to improve recovery of dynamic call structure, closing most of the gap to the strongest zero-shot model.
- Any open-source repository can be turned into additional verified instances using the released pipeline, expanding the benchmark over time.
- Evaluations now isolate semantic understanding of runtime behavior from the separate skill of writing test-passing code.
- Performance on this task becomes a concrete, reproducible signal for comparing models on structural program reasoning.
Where Pith is reading between the lines
- Success here may indicate broader capability to reason about other runtime properties such as data dependencies or exception flows.
- The same verification approach could be applied to measure whether generated code preserves intended call behavior in addition to passing tests.
- Repositories with richer dynamic behavior, such as those using heavy reflection or callbacks, would form natural stress tests for the current construction method.
Load-bearing premise
The LLM-assisted harness generation plus tracer validation captures complete and unbiased runtime call behavior for the chosen programs without missing dynamic paths or creating artifacts.
What would settle it
Executing the benchmark programs under new inputs or environments that activate additional call paths not recorded in the supplied traces would reveal whether the ground-truth labels are incomplete.
Figures
read the original abstract
Evaluating whether large language models (LLMs) can recover execution-relevant program structure, rather than only produce code that passes tests, remains an open problem. Existing code benchmarks emphasize test-passing outputs, from standalone programming tasks (HumanEval, MBPP, LiveCodeBench) to repository repair (SWE-Bench); this is useful, but offers limited diagnostic signal about which program semantics a model can recover from source. We introduce TraceEval, to our knowledge the first execution-verified, multi-language benchmark for code semantic reasoning: recovering a program's runtime call structure from source code. Unlike prior call-graph benchmarks that rely on static-tool output or hand-annotated ground truth, every positive edge in TraceEval is mechanically witnessed by validation execution, eliminating annotator disagreement and label noise for observed behavior. TraceEval consists of (i) 10,583 real-world programs (2,129 test, 8,454 train) extracted from 1,600+ open-source repositories across Python, JavaScript, and Java via an LLM-assisted harness-generation pipeline with tracer validation; and (ii) a reproducible pipeline that converts any open-source repository into new verified benchmark instances. We evaluate 10 LLMs at zero-shot on the held-out test split. The strongest model, Claude-Opus-4.6, reaches an average F1 of 72.9% across the three languages. To demonstrate the train split's utility as a supervision substrate, we fine-tune the Qwen2.5-Coder family on it: lifts of up to +55.6 F1 bring tuned Qwen2.5-Coder-32B to 71.2%, within 1.7 F1 of zero-shot Claude-Opus-4.6. We release the benchmark, pipeline, baselines, and a datasheet at https://github.com/yikun-li/TraceEva
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TraceEval, claimed as the first execution-verified multi-language benchmark for code semantic reasoning: recovering runtime call structure from source code. It extracts 10,583 real-world programs (2,129 test, 8,454 train) from 1,600+ repositories across Python, JavaScript, and Java using an LLM-assisted harness-generation pipeline with tracer validation; every positive call-graph edge is mechanically witnessed by execution. Zero-shot evaluation of 10 LLMs yields up to 72.9% average F1 (Claude-Opus-4.6); fine-tuning Qwen2.5-Coder models on the train split produces lifts up to +55.6 F1, reaching 71.2%. A reproducible pipeline for generating new verified instances from open-source repositories is released along with the benchmark, baselines, and datasheet.
Significance. If the ground-truth call structures prove complete and representative, TraceEval would be a meaningful contribution by supplying a large-scale, multi-language, execution-verified resource that directly measures semantic recovery rather than test-passing. The open pipeline, train split for supervision, and release of all artifacts would enable reproducible follow-up work and could become a standard diagnostic for code-understanding models.
major comments (1)
- [Dataset construction / harness-generation pipeline] Dataset construction (LLM-assisted harness-generation pipeline with tracer validation): the claim that the resulting traces supply unbiased, complete runtime call structures for real-world programs rests on the unverified assumption that LLM-generated harnesses trigger all relevant entry points, conditionals, and callbacks. No quantitative coverage analysis (e.g., fraction of functions exercised, comparison against project-native test suites, or manual audit of missed dynamic edges) is described; this directly undermines the assertion that the benchmark captures representative runtime behavior rather than only the subset exercised by the generated harnesses.
minor comments (1)
- [Abstract] The final sentence of the abstract contains a truncated repository name ('TraceEva' instead of 'TraceEval').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The concern regarding dataset construction and coverage is well-taken, and we address it directly below. We have revised the paper to incorporate clarifications and additional discussion as described.
read point-by-point responses
-
Referee: Dataset construction (LLM-assisted harness-generation pipeline with tracer validation): the claim that the resulting traces supply unbiased, complete runtime call structures for real-world programs rests on the unverified assumption that LLM-generated harnesses trigger all relevant entry points, conditionals, and callbacks. No quantitative coverage analysis (e.g., fraction of functions exercised, comparison against project-native test suites, or manual audit of missed dynamic edges) is described; this directly undermines the assertion that the benchmark captures representative runtime behavior rather than only the subset exercised by the generated harnesses.
Authors: We appreciate the referee's point and agree that the harness-generation process does not guarantee exhaustive coverage of all possible execution paths. TraceEval does not claim to capture a complete or unbiased enumeration of every conceivable runtime call structure; rather, it supplies a large set of real-world programs for which every positive call-graph edge has been mechanically verified through execution of the generated harness. This design eliminates false-positive labels and annotator disagreement for the observed behaviors, which is the primary contribution relative to static or hand-annotated call-graph resources. The LLM-assisted harness pipeline is intended to produce inputs that exercise core program functionality (with tracer validation to confirm execution), but we acknowledge that coverage is harness-dependent and may miss some dynamic edges. In the revised manuscript we will (1) add an explicit limitations subsection clarifying the scope of the verified traces, (2) report quantitative coverage statistics (e.g., fraction of functions reached by the harnesses on the test split), and (3) note that the released pipeline enables community extensions for improved coverage. We believe these changes preserve the benchmark's utility for evaluating semantic recovery on verified runtime structures while addressing the concern. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper constructs TraceEval by extracting programs from external open-source repositories and applying an LLM-assisted harness-generation pipeline followed by independent tracer validation to produce execution-witnessed call edges. No equations, fitted parameters, or predictions are defined in terms of the target outputs; the benchmark creation, LLM zero-shot evaluation, and fine-tuning experiments operate on externally sourced data with mechanical verification. The central claims rest on the reproducibility of the pipeline against real-world repositories rather than any self-referential reduction or self-citation load-bearing step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dynamic execution traces from instrumented runs accurately capture all relevant runtime call edges for the selected programs.
Reference graph
Works this paper leans on
-
[1]
For each question , list the fu nc ti on calls as a comma - s e p a r a t e d list
-
[2]
Do not include a d d i t i o n a l e x p l a n a t i o n s or c o m m e n t a r y
-
[3]
Include both ex pl ic it and i mp li ci t fu nc tio n calls ( e . g . , __ ini t_ _ when an object is created )
-
[4]
If a fu nc ti on is called through an alias or variable , resolve it to the actual f un ct ion being called
-
[5]
If a passed ar gu men t is not invoked within the function , do not include it
-
[6]
If there are no fu nc ti on calls , leave the answer empty
-
[7]
** I M P O R T A N T **: Always use fully q u a l i f i e d names with the module prefix . For example , use " main . MyClass . func " not " MyClass . func ". The module name is the fil en am e without e x t e n s i o n ( e . g . , " main . py " -> " main ") . ** Format for Answers **: - Provide your answer next to each q ues ti on number . - Do not inclu...
- [8]
-
[9]
module . func3 3. { language - sp ec if ic worked example : Python / J a v a S c r i p t / Java } **{ l an gu ag e } Code P ro vi de d **: { code } ** Q u e s t i o n s **: { one per ground - truth caller } ** Answers **: A.2 Harness-Generation Prompt The corpus-construction stage (Section 2.1) calls GPT-5.4 once per source file with the prompt below. The...
-
[10]
** Pr es er ve the call pa tt ern s **: keep the same fu nc tio n / method call r e l a t i o n s h i p s
-
[11]
** Remove all ex te rn al d e p e n d e n c i e s **: replace imports with stubs or inline i m p l e m e n t a t i o n s
-
[12]
** Make it self - c o n t a i n e d **: the code must run on its own with no ex te rn al p ac ka ges
-
[13]
** Add an entry point **: { e n t r y _ p o i n t _ i n s t r u c t i o n }
-
[14]
** Keep it 15 -40 lines **: s im pli fy if needed , but pr ese rv e the call s t r u c t u r e
-
[15]
No markdown , no e x p l a n a t i o n
** Use r e a l i s t i c names **: don't rename to func1 / func2 , keep m e a n i n g f u l names from the or ig in al ## O ri gi na l code from { repo }: ``` { source } ``` ## Output format : Return ONLY the r e w r i t t e n code . No markdown , no e x p l a n a t i o n . Just the ru nn ab le code . The per-language entry-point instruction is: •Python /...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.