Recognition: no theorem link
Simpson's Paradox in Behavioral Curves: How Aggregation Distorts Parametric Models of User Dynamics
Pith reviewed 2026-05-13 06:38 UTC · model grok-4.3
The pith
Aggregation distorts behavioral curves so that group peaks occur at three to five times the individual exposure level.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
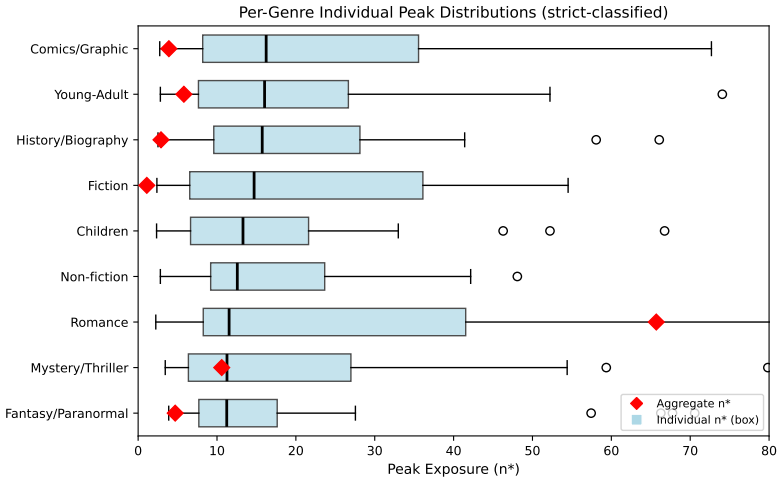
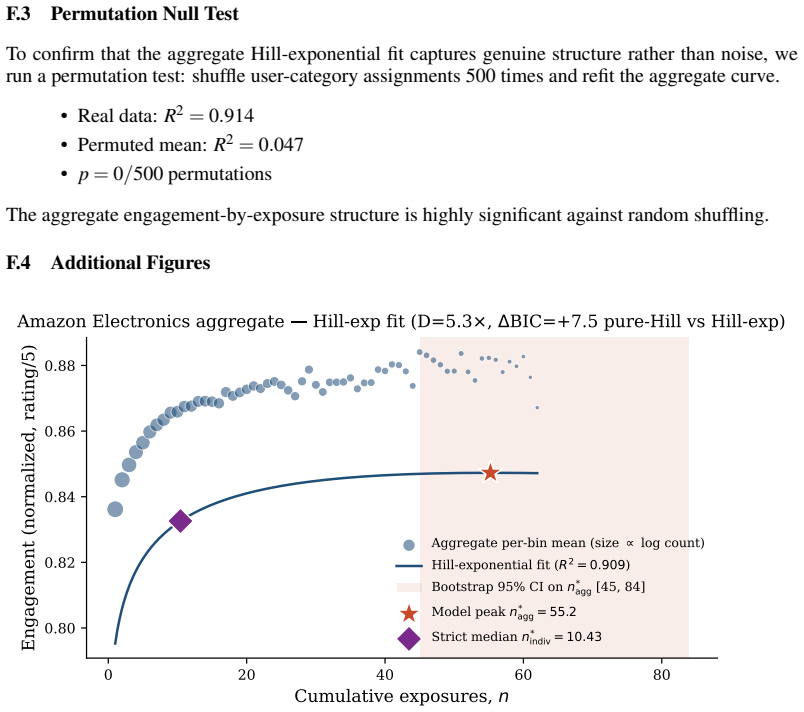
When individual user engagement curves are fitted separately, their peaks cluster around eleven exposures on Goodreads data, yet the single curve fitted to all users together peaks around thirty-four exposures. The same pattern appears at larger scale in Amazon electronics reviews. MovieLens serves as a negative control where the individual and aggregate peaks align, isolating survival bias as the operative mechanism rather than aggregation itself. The distortion persists across different category definitions and engagement measures.
What carries the argument
Simpson's paradox in behavioral curves, produced when survival bias from differential user attrition warps the aggregate parametric fit away from the typical individual peak.
If this is right
- Exposure targets derived from aggregate curves will systematically recommend too many repetitions for the typical user.
- Recommendation and advertising systems that optimize against aggregate behavioral curves will over-expose the median user.
- Clinical dosing schedules fitted to population-level response curves may exceed the point at which most individuals have already responded.
- Per-user or attrition-adjusted modeling is required whenever differential dropout rates are present.
- The introduced Synthetic Null Calibration reduces false positives when classifying which users exhibit a clear peak.
Where Pith is reading between the lines
- Existing studies that tuned exposure levels using only aggregate curves may have set targets substantially higher than needed for most individuals.
- Domains with high user churn, such as social media or mobile apps, are likely to show comparable distortions if examined at the individual level.
- A direct test could compare aggregate versus individual peaks in randomized experiments that control attrition rates.
- The same aggregation bias may affect other parametric summaries of user behavior beyond simple exposure-response curves.
Load-bearing premise
The gap between individual and aggregate peaks is caused primarily by survival bias rather than by artifacts of how the curves are fitted, how engagement is measured, or by other unmeasured factors.
What would settle it
Construct a synthetic dataset in which every user has identical probability of continuing after each exposure and then check whether the aggregate peak still deviates from the individual peaks; if the deviation disappears, the survival-bias account is supported.
Figures



read the original abstract
Behavioral curve modeling -- fitting parametric functions to engagement-versus-exposure data -- is standard practice in recommendation, advertising, and clinical dosing. We show that aggregation introduces a systematic distortion: Simpson's paradox in behavioral curves. On Goodreads (3.3M users, 9 genres), individual users peak at n* approximately 11 exposures while the aggregate peaks at n* approximately 34 -- a 3x gap driven by survival bias. Amazon Electronics (18M reviews) shows a 5.3x distortion. MovieLens-25M (D approximately 1) serves as a negative control, confirming that survival bias -- not aggregation per se -- is the operative mechanism. The distortion is robust to category granularity, engagement operationalization, and classifier calibration. We develop Synthetic Null Calibration to address a 32% false positive rate in per-user classification. Our findings apply wherever individual behavioral parameters are estimated from aggregate curves under differential attrition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that aggregation of user engagement-versus-exposure data induces Simpson's paradox in parametric behavioral curves: individual-level fits yield lower peak exposures (n* ≈ 11 on Goodreads) than aggregate fits (n* ≈ 34), a 3x distortion attributed to survival bias rather than aggregation per se. Evidence comes from Goodreads (3.3M users, 9 genres), Amazon Electronics (18M reviews, 5.3x distortion), and MovieLens-25M as negative control (D ≈ 1), with robustness to granularity, operationalization, and classifier calibration. The authors introduce Synthetic Null Calibration to correct a 32% false-positive rate in per-user peak classification and argue the findings apply to any setting estimating individual parameters from aggregates under differential attrition.
Significance. If the central empirical discrepancy is shown to arise specifically from survival bias and not from fitting instability or misspecification, the result would be significant for recommender systems, advertising, and clinical modeling, where aggregate curves are routinely used to infer optimal exposure levels. The multi-dataset design with negative control and robustness checks provides a solid empirical foundation; the introduction of Synthetic Null Calibration is a constructive methodological contribution that could be adopted more broadly.
major comments (3)
- [Synthetic Null Calibration] The Synthetic Null Calibration section addresses only the false-positive rate (32%) for classifying users as having a peak; it does not validate recovery of the continuous peak location n* or quantify bias/variance in per-user estimates under sparse data. Because the headline 3x gap rests on the distribution of these individual n* values, explicit simulation results showing that the chosen parametric family recovers known peaks when data are sparse (as in the Goodreads per-user regime) are required.
- [Methods / per-user fitting procedure] The manuscript provides insufficient detail on the exact parametric families fitted to individual users, the optimization procedure (MLE, least-squares, regularization), and how n* is extracted from each fit. Without these, it is impossible to rule out that the reported individual-aggregate discrepancy is partly an artifact of functional-form misspecification or unstable estimation for low-exposure users, rather than survival bias alone.
- [Empirical results and robustness checks] While MovieLens serves as a negative control, the paper does not report quantitative checks (e.g., per-user goodness-of-fit statistics or cross-validation error) demonstrating that the chosen parametric form is adequate for individual trajectories on the main datasets. Such diagnostics are necessary to isolate survival bias from model mismatch.
minor comments (2)
- [Data description] Clarify the precise definition of 'exposure' and 'engagement' used in each dataset, including any preprocessing steps that could interact with attrition.
- [Robustness analysis] The abstract states 'robust to category granularity' but the main text should include a table or figure showing the range of granularities tested and the resulting n* values.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each of the major comments below, and we will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Synthetic Null Calibration] The Synthetic Null Calibration section addresses only the false-positive rate (32%) for classifying users as having a peak; it does not validate recovery of the continuous peak location n* or quantify bias/variance in per-user estimates under sparse data. Because the headline 3x gap rests on the distribution of these individual n* values, explicit simulation results showing that the chosen parametric family recovers known peaks when data are sparse (as in the Goodreads per-user regime) are required.
Authors: We concur that additional validation of the per-user peak recovery is necessary to substantiate the reliability of the individual n* estimates. In the revised manuscript, we will include a dedicated simulation experiment. We will generate synthetic user trajectories with known ground-truth peak locations n* drawn from a distribution similar to our empirical findings, under sparsity levels matching the Goodreads dataset (i.e., varying numbers of observations per user). We will then apply the same fitting procedure and report metrics such as mean absolute error, bias, and variance in the estimated n* values. This will demonstrate that the parametric model can accurately recover peaks even with sparse data, thereby supporting that the observed 3x distortion arises from survival bias rather than estimation artifacts. revision: yes
-
Referee: [Methods / per-user fitting procedure] The manuscript provides insufficient detail on the exact parametric families fitted to individual users, the optimization procedure (MLE, least-squares, regularization), and how n* is extracted from each fit. Without these, it is impossible to rule out that the reported individual-aggregate discrepancy is partly an artifact of functional-form misspecification or unstable estimation for low-exposure users, rather than survival bias alone.
Authors: We agree that the current description of the per-user fitting procedure is insufficiently detailed. In the revision, we will substantially expand the Methods section to include: (1) the specific parametric family employed for the behavioral curves (including the mathematical form and any assumptions), (2) the optimization algorithm used (maximum likelihood estimation via gradient descent or similar), including any regularization terms or constraints, and (3) the precise method for deriving n* from the fitted parameters (e.g., by solving for the mode or maximum of the fitted function). We will also provide supplementary code or pseudocode to ensure reproducibility. revision: yes
-
Referee: [Empirical results and robustness checks] While MovieLens serves as a negative control, the paper does not report quantitative checks (e.g., per-user goodness-of-fit statistics or cross-validation error) demonstrating that the chosen parametric form is adequate for individual trajectories on the main datasets. Such diagnostics are necessary to isolate survival bias from model mismatch.
Authors: We acknowledge the value of reporting quantitative model fit diagnostics to rule out misspecification as a confounding factor. In the revised manuscript, we will add a new subsection or table summarizing per-user goodness-of-fit metrics for the Goodreads and Amazon datasets. This will include, for example, the distribution of R^2 values, mean squared errors, or log-likelihoods across users, as well as results from a cross-validation procedure (e.g., 5-fold CV error averaged over users). These diagnostics will be compared to those on the MovieLens negative control to further isolate the role of survival bias. revision: yes
Circularity Check
No significant circularity; central result is direct empirical comparison of fitted peaks
full rationale
The paper reports direct maximum-likelihood or least-squares fits of a parametric family to per-user engagement curves and to the aggregate curve on external datasets (Goodreads, Amazon Electronics, MovieLens-25M). The headline discrepancy (individual n* ≈11 vs aggregate n* ≈34) is the observed difference between those two independent fits; it does not reduce to a fitted parameter being renamed as a prediction, nor to any self-citation chain that supplies the uniqueness or functional form. The Synthetic Null Calibration is an auxiliary procedure that only calibrates false-positive classification rate and is not used to adjust the reported peak locations. No equation or derivation step equates a claimed prediction to its own input by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of per-user parametric functions
axioms (2)
- domain assumption Engagement versus exposure can be accurately modeled by parametric functions at the individual user level
- domain assumption Differential attrition produces survival bias that systematically shifts aggregate curve peaks
Reference graph
Works this paper leans on
- [1]
-
[2]
Psychological Bulletin , volume=
The Psychology of Curiosity: A Review and Reinterpretation , author=. Psychological Bulletin , volume=. 1994 , publisher=
work page 1994
-
[3]
International Conference on Machine Learning (ICML) , pages=
Curiosity-Driven Exploration by Self-Supervised Prediction , author=. International Conference on Machine Learning (ICML) , pages=
-
[4]
Proceedings of the 19th International Conference on World Wide Web (WWW) , pages=
A Contextual-Bandit Approach to Personalized News Article Recommendation , author=. Proceedings of the 19th International Conference on World Wide Web (WWW) , pages=
-
[5]
Curiosity-Driven Recommendation Strategy , author=. The Web Conference , pages=
-
[6]
Proceedings of the 15th ACM Conference on Recommender Systems (RecSys) , pages=
Values of User Exploration in Recommender Systems , author=. Proceedings of the 15th ACM Conference on Recommender Systems (RecSys) , pages=
-
[7]
Finite-Time Analysis of the Multiarmed Bandit Problem , author=. Machine Learning , volume=. 2002 , publisher=
work page 2002
-
[8]
On the Likelihood that One Unknown Probability Exceeds Another in View of the Evidence of Two Samples , author=. Biometrika , volume=
-
[9]
Chapelle, Olivier and Li, Lihong , booktitle=. An Empirical Evaluation of
-
[10]
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
work page 2018
- [11]
-
[12]
Proceedings of the ACM Conference on Recommender Systems (RecSys) , year=
Stable Exploration in Reinforcement Learning for Recommendation , author=. Proceedings of the ACM Conference on Recommender Systems (RecSys) , year=
-
[13]
and Gillenwater, Jennifer , booktitle=
Wilhelm, Mark and Ramanathan, Ajith and Bonomo, Alexander and Jain, Sagar and Chi, Ed H. and Gillenwater, Jennifer , booktitle=. Practical Diversified Recommendations on
-
[14]
International Conference on Learning Representations (ICLR) , year=
Exploration by Random Network Distillation , author=. International Conference on Learning Representations (ICLR) , year=
-
[15]
Psychological Science , volume=
The Wick in the Candle of Learning: Epistemic Curiosity Activates Reward Circuitry and Enhances Memory , author=. Psychological Science , volume=
-
[16]
States of Curiosity Modulate Hippocampus-Dependent Learning via the Dopaminergic Circuit , author=. Neuron , volume=
-
[17]
Developmental Psychology , volume=
The Impact of Curiosity on Information Seeking and Learning in Adolescents , author=. Developmental Psychology , volume=
-
[18]
Wang, Xiang and He, Xiangnan and Cao, Yixin and Liu, Meng and Chua, Tat-Seng , booktitle=
-
[19]
Wang, Hongwei and Zhang, Fuzheng and Xie, Xing and Guo, Minyi , booktitle=
-
[20]
A Survey on Knowledge-Enhanced Recommendation , author=. ACM Computing Surveys , year=
-
[21]
International Conference on Machine Learning (ICML) , pages=
Taming the Monster: A Fast and Simple Algorithm for Contextual Bandits , author=. International Conference on Machine Learning (ICML) , pages=
-
[22]
and Nikolic, Isidor and De Bona, Fabio and Krause, Andreas , booktitle=
Vanchinathan, Hastagiri P. and Nikolic, Isidor and De Bona, Fabio and Krause, Andreas , booktitle=. Explore-Exploit in Top-
-
[23]
Chen, Minmin and Beutel, Alex and Covington, Paul and Jain, Sagar and Belletti, Francois and Chi, Ed H. , booktitle=. Top-
-
[24]
Self-Supervised Reinforcement Learning for Recommender Systems , author=. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
- [25]
-
[26]
Proceedings of the 12th ACM Conference on Recommender Systems (RecSys) , pages=
Recsys Challenge 2018: Automatic Music Playlist Continuation , author=. Proceedings of the 12th ACM Conference on Recommender Systems (RecSys) , pages=
work page 2018
-
[27]
Bennett, James and Lanning, Stan , booktitle=. The
-
[28]
Proceedings of the 12th ACM Conference on Recommender Systems (RecSys) , pages=
Item Recommendation on Monotonic Behavior Chains , author=. Proceedings of the 12th ACM Conference on Recommender Systems (RecSys) , pages=
-
[29]
and Vu, Trung and Heldt, Lukasz and Hong, Lichan and Tay, Yi and Tran, Vinh Q
Rajput, Shashank and Mehta, Nikhil and Singh, Anima and Keshavan, Raghunandan H. and Vu, Trung and Heldt, Lukasz and Hong, Lichan and Tay, Yi and Tran, Vinh Q. and Saber, Jonah and others , booktitle=
-
[30]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Transformer Memory as a Differentiable Search Index , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[31]
Distilling the Knowledge in a Neural Network
Distilling the Knowledge in a Neural Network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Gu, Yuxian and Dong, Li and Wei, Furu and Huang, Minlie , booktitle=. Mini
-
[33]
Journal of the Royal Statistical Society, Series B , volume=
The Interpretation of Interaction in Contingency Tables , author=. Journal of the Royal Statistical Society, Series B , volume=
- [34]
- [35]
-
[36]
American Sociological Review , volume=
Ecological Correlations and the Behavior of Individuals , author=. American Sociological Review , volume=
-
[37]
and Lerman, Kristina , booktitle=
Alipourfard, Nazanin and Fennell, Peter G. and Lerman, Kristina , booktitle=. Using
-
[38]
Robins, James M. and Finkelstein, Dianne M. , journal=. Correcting for Non-Compliance and Dependent Censoring in an
-
[39]
Kievit, Rogier A. and Frankenhuis, Willem E. and Waldorp, Lourens J. and Borsboom, Denny , journal=
- [40]
-
[41]
A Solution to the Ecological Inference Problem: Reconstructing Individual Behavior from Aggregate Data , author=. 1997 , publisher=
work page 1997
- [42]
-
[43]
Prior Distributions for Variance Parameters in Hierarchical Models , author=. Bayesian Analysis , volume=
- [44]
-
[45]
Springer Series in Statistics , year=
Permutation, Parametric, and Bootstrap Tests of Hypotheses , author=. Springer Series in Statistics , year=
-
[46]
Findings of the Association for Computational Linguistics: NAACL 2024 , year=
Bridging Language and Items for Retrieval and Recommendation , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , year=
work page 2024
- [47]
-
[48]
Statistical Analysis with Missing Data , author=. 2019 , publisher=
work page 2019
-
[49]
Sample Selection Bias as a Specification Error , author=. Econometrica , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.