Recognition: unknown
Efficient LLM Reasoning via Variational Posterior Guidance with Efficiency Awareness
Pith reviewed 2026-05-13 06:23 UTC · model grok-4.3
The pith
A posterior distribution guided by reference answers achieves higher expected utility than the prior in LLM reasoning, breaking the sampling bottleneck.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors prove that a posterior distribution conditioned on reference answers attains higher expected utility than the prior distribution used in standard reinforcement learning for reasoning compression. They formalize efficient reasoning as a variational inference task and define an efficiency-aware evidence lower bound. The VPG-EA framework realizes this by maintaining a parameter-shared dual-stream network for posterior and prior, applying cross-view filtering to remove inefficient pseudo-paths, and performing unidirectional variational distillation to inject the posterior's efficient patterns into the prior policy that runs at test time.
What carries the argument
parameter-shared dual-stream architecture with cross-view filtering and unidirectional variational distillation under an efficiency-aware evidence lower bound
If this is right
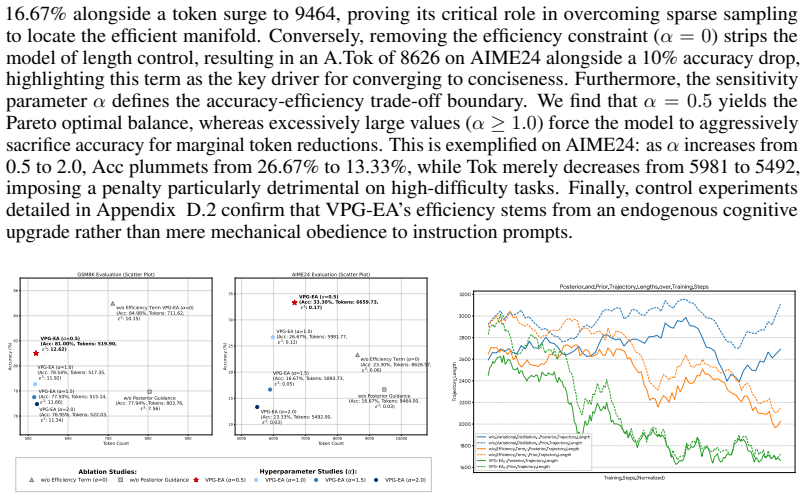
- The method raises the epsilon-cubed efficiency metric by 8.73 percent on the 1.5B model and 12.37 percent on the 7B model compared to strong baselines.
- It reduces the need for complex reward engineering that makes high-quality samples sparse.
- The prior policy at inference time inherits efficient reasoning patterns without direct access to reference answers.
- The approach scales to both 1.5B and 7B parameter models in the DeepSeek-R1-Distill-Qwen family.
Where Pith is reading between the lines
- The variational distillation technique may extend to other sequence generation tasks where a teacher distribution is available only during training.
- Similar posterior guidance could address overthinking in non-language reasoning models such as those for mathematical proofs or planning.
- If the efficiency gains hold, inference costs for complex tasks could drop substantially without sacrificing accuracy.
Load-bearing premise
The dual-stream architecture with cross-view filtering and unidirectional variational distillation can successfully transfer efficient reasoning patterns from the reference-guided posterior to the deployable prior policy.
What would settle it
An experiment measuring the expected utility of samples from the reference-guided posterior versus the prior and finding no advantage for the posterior would falsify the core theoretical claim; alternatively, applying VPG-EA without the distillation step and observing no efficiency improvement would undermine the framework's effectiveness.
Figures





read the original abstract
Although large language models rely on chain-of-thought for complex reasoning, the overthinking phenomenon severely degrades inference efficiency. Existing reinforcement learning methods compress reasoning chains by designing elaborate reward functions, which renders high-quality samples extremely sparse in the exploration space and creates a sampling bottleneck for the prior policy. Inspired by cognitive science, we theoretically prove that a posterior distribution guided by reference answers achieves higher expected utility than the prior distribution, thus capable of breaking through the sampling bottleneck of high-quality samples. However, the posterior distribution is unavailable during inference. To this end, we formalize efficient reasoning as a variational inference problem and introduce an efficiency-aware evidence lower bound as the theoretical foundation. Based on this, we propose the VPG-EA framework. It adopts a parameter-shared dual-stream architecture to instantiate both the posterior distribution and the prior policy; after filtering out pseudo-efficient paths via cross-view evaluation, it unidirectionally transfers the posterior's efficient patterns to the prior policy through variational distillation. Experiments on DeepSeek-R1-Distill-Qwen-1.5B and 7B scales demonstrate that VPG-EA improves the comprehensive efficiency metric epsilon cubed by 8.73% and 12.37% over the strongest baselines on each model size, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
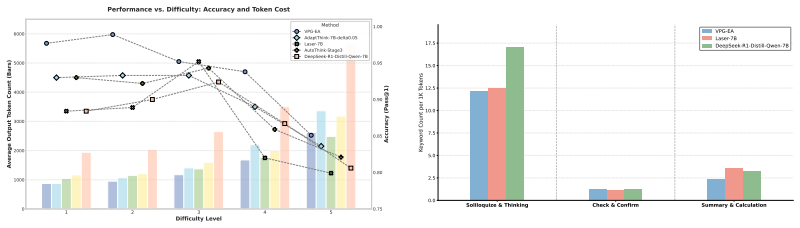
Summary. The paper claims that a reference-guided posterior distribution over reasoning chains has strictly higher expected utility than the prior policy, thereby breaking the sampling bottleneck created by sparse high-quality trajectories in RL-based chain-of-thought compression. It formalizes efficient reasoning as variational inference, introduces an efficiency-aware evidence lower bound, and instantiates the VPG-EA framework via a parameter-shared dual-stream architecture, cross-view filtering of pseudo-efficient paths, and unidirectional variational distillation to transfer posterior patterns to the prior. Experiments on DeepSeek-R1-Distill-Qwen-1.5B and 7B models report 8.73% and 12.37% gains in the composite efficiency metric ε³ over the strongest baselines.
Significance. If the theoretical utility gap holds and the distillation step successfully concentrates the prior on the same high-utility regions, the work would offer a principled variational alternative to reward-engineering approaches for mitigating overthinking in LLMs. The dual-stream design and efficiency-aware ELBO could influence subsequent inference-time optimization methods, provided the transfer mechanism is shown to be robust.
major comments (3)
- [Abstract / Theoretical foundation] Abstract / Theoretical claim: the assertion that the reference-guided posterior achieves strictly higher expected utility than the prior is load-bearing for the entire contribution, yet the manuscript supplies no derivation, explicit utility function, or list of assumptions, preventing verification that the claimed strict improvement survives the variational gap and sampling noise present in actual LLM rollouts.
- [VPG-EA framework] VPG-EA framework description: the unidirectional variational distillation operates only on paths retained after cross-view filtering; it is unclear whether this filtered objective is guaranteed to align the prior’s sampling distribution with the high-utility support of the true posterior, or whether mismatch in the variational gap could leave the prior no better than standard RL baselines.
- [Experiments] Experiments section: the reported 8.73% and 12.37% improvements in ε³ are presented without baseline implementation details, number of random seeds, error bars, or data-exclusion criteria, making it impossible to assess whether the gains are statistically reliable or sensitive to the choice of efficiency metric.
minor comments (2)
- [Abstract] Define the composite efficiency metric ε³ explicitly (including its three constituent factors and normalization) at first use rather than assuming reader familiarity.
- [Method] Clarify whether the efficiency term inside the proposed ELBO is computed from reference answers (unavailable at test time) or from an auxiliary model, to rule out circularity with the training objective.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for clarifying the theoretical foundations and strengthening the experimental reporting. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Theoretical foundation] Abstract / Theoretical claim: the assertion that the reference-guided posterior achieves strictly higher expected utility than the prior is load-bearing for the entire contribution, yet the manuscript supplies no derivation, explicit utility function, or list of assumptions, preventing verification that the claimed strict improvement survives the variational gap and sampling noise present in actual LLM rollouts.
Authors: We acknowledge that the current presentation of the theoretical claim in the abstract and Section 3 could be more explicit. The manuscript defines the utility function as the expected task reward minus a linear efficiency penalty and proves the strict improvement under the assumption that reference answers provide an oracle upper bound on reward for correct trajectories. The proof proceeds by showing that the posterior concentrates mass on high-utility paths that the prior cannot reach due to sparsity. To address the referee's concern about the variational gap and sampling noise, we will add an expanded derivation in the revised Section 3.1, including the full list of assumptions, a formal statement of the utility gap, and a discussion of how the bound holds in expectation even under approximate sampling. revision: yes
-
Referee: [VPG-EA framework] VPG-EA framework description: the unidirectional variational distillation operates only on paths retained after cross-view filtering; it is unclear whether this filtered objective is guaranteed to align the prior’s sampling distribution with the high-utility support of the true posterior, or whether mismatch in the variational gap could leave the prior no better than standard RL baselines.
Authors: The cross-view filtering step retains only trajectories that receive high efficiency scores from both the posterior and prior streams, and the unidirectional distillation then minimizes the KL divergence from the filtered posterior to the prior under the efficiency-aware ELBO. While this does not provide a strict theoretical guarantee of perfect alignment (due to the inherent variational approximation), the objective is explicitly constructed to reduce the gap on high-utility regions. Our experiments show consistent outperformance over RL baselines, indicating practical alignment. In the revision we will add a dedicated paragraph discussing the conditions under which mismatch could occur and the empirical evidence that the distilled prior concentrates on the same high-utility support. revision: partial
-
Referee: [Experiments] Experiments section: the reported 8.73% and 12.37% improvements in ε³ are presented without baseline implementation details, number of random seeds, error bars, or data-exclusion criteria, making it impossible to assess whether the gains are statistically reliable or sensitive to the choice of efficiency metric.
Authors: We agree that these details are essential for assessing reliability. In the revised manuscript we will expand the Experiments section to include: (i) full implementation details and hyperparameters for all baselines, (ii) results averaged over five random seeds with standard error bars, (iii) explicit statement that no data points were excluded beyond standard length and validity filters, and (iv) a sensitivity analysis showing that the reported gains in ε³ remain stable under reasonable variations of the efficiency metric weights. revision: yes
Circularity Check
Theoretical proof and variational approximation remain independent of fitted inputs
full rationale
The paper first states a theoretical proof that a reference-guided posterior achieves strictly higher expected utility than the prior, breaking the sampling bottleneck. It then formalizes the task as variational inference and introduces an efficiency-aware ELBO as the objective. The VPG-EA implementation (dual-stream architecture, cross-view filtering, unidirectional distillation) is presented as an approximation to this bound rather than a redefinition of it. No equation or step reduces the reported efficiency gains to a fitted parameter renamed as prediction, nor does any self-citation serve as the sole load-bearing justification. The derivation chain therefore contains independent theoretical content and is not circular by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Posterior distribution guided by reference answers achieves higher expected utility than the prior
Reference graph
Works this paper leans on
-
[1]
L1: Controlling how long a reasoning model thinks with reinforcement learning
Pranjal Aggarwal and Sean Welleck. L1: Controlling how long a reasoning model thinks with reinforcement learning. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=4jdIxXBNve
work page 2025
-
[2]
Training language models to reason efficiently
Daman Arora and Andrea Zanette. Training language models to reason efficiently. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https: //openreview.net/forum?id=AiZxn84Wdo
work page 2025
-
[3]
Nudging the boundaries of LLM reasoning
Justin Chen, Xiangyu Peng, Prafulla Kumar Choubey, Kung-Hsiang Huang, Jiaxin Zhang, Mohit Bansal, and Chien-Sheng Wu. Nudging the boundaries of LLM reasoning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https:// openreview.net/forum?id=hfNnQHkTtv
work page 2026
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Qiguang Chen, Dengyun Peng, Jinhao Liu, Huikang Su, Jiannan Guan, Libo Qin, and Wanxiang Che. Aware first, think less: Dynamic boundary self-awareness drives significant gains in reasoning efficiency in large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 30261–30269, 2026
work page 2026
-
[6]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms.arXiv preprint arXiv:2412.21187, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Verithinker: Learn- ing to verify makes reasoning model efficient
Zigeng Chen, Xinyin Ma, Gongfan Fang, Ruonan Yu, and Xinchao Wang. Verithinker: Learn- ing to verify makes reasoning model efficient. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id= Y1bt0YIS6Y
work page 2025
-
[8]
Incentivizing dual process thinking for efficient large language model reasoning
Xiaoxue Cheng, Junyi Li, Zhenduo Zhang, Xinyu Tang, Xin Zhao, XinYu KONG, and Zhiqiang Zhang. Incentivizing dual process thinking for efficient large language model reasoning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=ezOfR26pGQ
work page 2025
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Chain-of-verification reduces hallucination in large language models
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason E Weston. Chain-of-verification reduces hallucination in large language models. In ICLR 2024 Workshop on Reliable and Responsible Foundation Models, 2024. URL https: //openreview.net/forum?id=ek3GqAs2uO
work page 2024
-
[11]
Thinkless: LLM learns when to think
Gongfan Fang, Xinyin Ma, and Xinchao Wang. Thinkless: LLM learns when to think. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=ariVQf0KZx
work page 2025
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Your models have thought enough: Training large reasoning models to stop overthinking
Jinyi Han, Ying Huang, Ying Liao, Haiquan Zhao, Zishang Jiang, Xinyi Wang, Xikun Lu, Guanghao Zhou, Sihang Jiang, Jiaqing Liang, Weikang Zhou, Zeye Sun, Fei Yu, and Yanghua Xiao. Your models have thought enough: Training large reasoning models to stop overthinking. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps: //op...
work page 2026
-
[14]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021. 10
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Ulrich Hoffrage, Ralph Hertwig, and Gerd Gigerenzer. Hindsight bias: A by-product of knowledge updating?Journal of Experimental Psychology: Learning, Memory, and Cognition, 26(3):566, 2000
work page 2000
-
[16]
Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, and Shiyu Chang. Thinkprune: Pruning long chain-of-thought of LLMs via reinforcement learning.Transactions on Machine Learning Research, 2026. ISSN 2835-8856. URL https://openreview.net/ forum?id=V51gPu1uQD
work page 2026
-
[17]
Mitigating overthinking in large reasoning models via manifold steering
Yao Huang, Huanran Chen, Shouwei Ruan, Yichi Zhang, Xingxing Wei, and Yinpeng Dong. Mitigating overthinking in large reasoning models via manifold steering. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=49Rc51iCso
work page 2025
-
[18]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[19]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=v8L0pN6EOi
work page 2024
-
[20]
Ravr: Reference-answer-guided variational reasoning for large language models
Tianqianjin Lin, Xi Zhao, Xingyao Zhang, Rujiao Long, Yi Xu, Zhuoren Jiang, Wenbo Su, and Bo Zheng. Ravr: Reference-answer-guided variational reasoning for large language models. arXiv preprint arXiv:2510.25206, 2025
-
[21]
Learn to reason efficiently with adaptive length-based reward shaping
Wei Liu, Ruochen Zhou, Yiyun Deng, Yuzhen Huang, Junteng Liu, Yuntian Deng, Yizhe Zhang, and Junxian He. Learn to reason efficiently with adaptive length-based reward shaping. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=hj9eKpqxQl
work page 2026
-
[22]
O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning
Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shiwei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, and Dacheng Tao. O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning. In2nd AI for Math Workshop @ ICML 2025, 2025. URL https://openreview. net/forum?id=ioYybCRcyW
work page 2025
-
[23]
Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl.Notion Blog, 3(5), 2025
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, et al. Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl.Notion Blog, 3(5), 2025
work page 2025
-
[24]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark.CoRR, abs/2311.12022, 2023. URL https://doi.org/10.48550/arXiv.2311. 12022
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311 2023
-
[25]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Dast: Difficulty-adaptive slow-thinking for large reasoning models
Yi Shen, Jian Zhang, Jieyun Huang, Shuming Shi, Wenjing Zhang, Jiangze Yan, Ning Wang, Kai Wang, Zhaoxiang Liu, and Shiguo Lian. Dast: Difficulty-adaptive slow-thinking for large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 2322–2331, 2025
work page 2025
-
[28]
Invariance in policy optimisation and partial identifiability in reward learning
Joar Max Viktor Skalse, Matthew Farrugia-Roberts, Stuart Russell, Alessandro Abate, and Adam Gleave. Invariance in policy optimisation and partial identifiability in reward learning. In International Conference on Machine Learning, pages 32033–32058. PMLR, 2023. 11
work page 2023
-
[29]
Stop overthinking: A survey on efficient reasoning for large language models.Trans
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, Hanjie Chen, and Xia Hu. Stop overthinking: A survey on efficient reasoning for large language models.Trans. Mach. Learn. Res., 2025, 2025. URLhttps://openreview.net/forum?id=HvoG8SxggZ
work page 2025
-
[30]
Learning when to think: Shaping adaptive reasoning in r1-style models via multi-stage RL
Songjun Tu, Jiahao Lin, Qichao Zhang, Xiangyu Tian, Linjing Li, Xiangyuan Lan, and Dongbin Zhao. Learning when to think: Shaping adaptive reasoning in r1-style models via multi-stage RL. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=Hs3FrjwyVZ
work page 2025
-
[31]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
work page 2024
-
[32]
Jiaxin Wen, Ruiqi Zhong, Akbir Khan, Ethan Perez, Jacob Steinhardt, Minlie Huang, Samuel R. Bowman, He He, and Shi Feng. Language models learn to mislead humans via RLHF. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=xJljiPE6dg
work page 2025
-
[33]
Large language models are better reasoners with self-verification
Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, and Jun Zhao. Large language models are better reasoners with self-verification. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 2550–2575, 2023
work page 2023
-
[34]
Demystifying long chain-of-thought reasoning in LLMs
Edward Yeo, Yuxuan Tong, Xinyao Niu, Graham Neubig, and Xiang Yue. Demystifying long chain-of-thought reasoning in LLMs. InICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models, 2025. URLhttps://openreview.net/forum?id= AgtQlhMQ0V
work page 2025
-
[35]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
work page 2025
-
[36]
Star: Self-taught reasoner bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D Goodman. Star: Self-taught reasoner bootstrapping reasoning with reasoning. InProc. the 36th International Conference on Neural Information Processing Systems, volume 1126, pages 0–55, 2024
work page 2024
-
[37]
From system 1 to system 2: A survey of reasoning large language models.IEEE Trans
Duzhen Zhang, Zhong-Zhi Li, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhijiang Guo, Le Song, and Cheng-Lin Liu. From system 1 to system 2: A survey of reasoning large language models.IEEE Trans. Pattern Anal. Mach. Intell., 48(3):3335–3354, March 2026. URL https://d...
-
[38]
Adaptthink: Reasoning models can learn when to think
Jiajie Zhang, Nianyi Lin, Lei Hou, Ling Feng, and Juanzi Li. Adaptthink: Reasoning models can learn when to think. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3716–3730, 2025
work page 2025
-
[39]
ExPO: Unlocking hard reasoning with self-explanation-guided reinforcement learning
Ruiyang Zhou, Shuozhe Li, Amy Zhang, and Liu Leqi. ExPO: Unlocking hard reasoning with self-explanation-guided reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id= D1PeGJtVEu
work page 2025
-
[40]
Variational reasoning for language models
Xiangxin Zhou, Zichen Liu, Haonan Wang, Chao Du, Min Lin, Chongxuan Li, Liang Wang, and Tianyu Pang. Variational reasoning for language models. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=fGGcovg6oW. 12 A Detailed Mathematical Derivation and Theoretical Boundary Discussion of Propositio...
work page 2026
-
[41]
Maintain the tone of a focused individual thinking to themself. Avoid meta-commentary like "for the first time," and any phrasing that reveals simulation
-
[42]
Do not mention, imply, or hint at prior access to the Reference Answer in the monologue. Avoid phrases like "according to the answer..." or "to get to that answer...", and any euphemism that signals foreknowledge
-
[43]
Do not merely restate the final answer in the monologue; articulate the reasoning pathway with sufficient intermediate steps, rationale, decision points, verification, and any necessary error-correction or backtracking.<|im_end|> <|im_start|>assistant 17 D.2 Exploration of the Endogenous Attribution of Efficiency after Removing Instruction Bias Student Pr...
-
[44]
This method introduces explicit system-aware tokens (e.g., <fast_think>) for SFT cold start, and subsequently integrates an online token length budget mechanism and a composite reward function within the GRPO framework, enabling the model to achieve dynamic switching between fast and slow thinking modes and adaptive allocation of cognitive resources based...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.