Recognition: no theorem link
Red-Teaming Agent Execution Contexts: Open-World Security Evaluation on OpenClaw
Pith reviewed 2026-05-13 00:50 UTC · model grok-4.3
The pith
Contextual changes in agent systems can trigger unsafe actions while still completing user tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Contextual compromise can induce substantial unsafe behavior while preserving user-facing task completion, demonstrating that final-response evaluation is insufficient.
What carries the argument
DeepTrap, a black-box trajectory-level optimization framework that scores sequences of context changes using risk-conditioned evaluation, multi-objective rewards, beam search, and reflection probing to locate high-impact compromised states.
Load-bearing premise
The 42-case benchmark and the optimization procedure capture realistic contextual attack surfaces instead of only artificial or easily patched cases.
What would settle it
Running the same 42 scenarios on a production agent deployment where context edits are restricted or logged and measuring whether unsafe actions still appear at the observed rate.
Figures



read the original abstract
Agentic language-model systems increasingly rely on mutable execution contexts, including files, memory, tools, skills, and auxiliary artifacts, creating security risks beyond explicit user prompts. This paper presents DeepTrap, an automated framework for discovering contextual vulnerabilities in OpenClaw. DeepTrap formulates adversarial context manipulation as a black-box trajectory-level optimization problem that balances risk realization, benign-task preservation, and stealth. It combines risk-conditioned evaluation, multi-objective trajectory scoring, reward-guided beam search, and reflection-based deep probing to identify high-value compromised contexts. We construct a 42-case benchmark spanning six vulnerability classes and seven operational scenarios, and evaluate nine target models using attack and utility grading scores. Results show that contextual compromise can induce substantial unsafe behavior while preserving user-facing task completion, demonstrating that final-response evaluation is insufficient. The findings highlight the need for execution-centric security evaluation of agentic AI systems. Our code is released at: https://github.com/ZJUICSR/DeepTrap
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DeepTrap, an automated framework for red-teaming agent execution contexts in OpenClaw. It formulates adversarial context manipulation as a black-box trajectory-level optimization problem that balances risk realization, benign-task preservation, and stealth, using risk-conditioned evaluation, multi-objective trajectory scoring, reward-guided beam search, and reflection-based deep probing. The authors construct a 42-case benchmark spanning six vulnerability classes and seven operational scenarios, evaluate nine target models with attack and utility grading scores, and report that contextual compromise induces substantial unsafe behavior while preserving user-facing task completion, concluding that final-response evaluation is insufficient for agentic systems.
Significance. If the benchmark and optimization results generalize, the work meaningfully advances security evaluation of agentic AI by shifting focus from prompts and final outputs to mutable execution contexts (files, memory, tools). The open release of code at https://github.com/ZJUICSR/DeepTrap is a clear strength that enables reproducibility and community extension.
major comments (2)
- [Benchmark construction] Benchmark construction (42 cases, six vulnerability classes, seven scenarios): the central claim that contextual compromise induces substantial unsafe behavior rests on this benchmark; details are required on case authorship, selection criteria, and steps taken to avoid post-hoc tailoring to the DeepTrap optimization method, as artificial or easily surfaced cases would undermine the demonstration that final-response evaluation is insufficient in realistic deployments.
- [Evaluation methodology] Evaluation methodology: the abstract and evaluation sections supply no information on how attack and utility grading scores are computed, whether statistical significance was assessed, what baselines were used, or how post-hoc result selection was avoided. These omissions are load-bearing for the reported positive results and the conclusion that execution-context attacks evade final-response checks.
minor comments (1)
- [Abstract] The abstract would benefit from a single quantitative highlight (e.g., average attack success rate or number of models showing the effect) to give readers an immediate sense of effect size.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (42 cases, six vulnerability classes, seven scenarios): the central claim that contextual compromise induces substantial unsafe behavior rests on this benchmark; details are required on case authorship, selection criteria, and steps taken to avoid post-hoc tailoring to the DeepTrap optimization method, as artificial or easily surfaced cases would undermine the demonstration that final-response evaluation is insufficient in realistic deployments.
Authors: We agree that explicit details on benchmark construction are required to support the central claims. The 42 cases were developed by the authors prior to the design of DeepTrap, drawing from established vulnerability patterns in agentic systems and documented operational scenarios in the literature. Authorship followed a structured process: each case was created to instantiate one of the six vulnerability classes within one of the seven scenarios, with independent validation that standard agents could complete the benign task. Selection criteria emphasized diversity, realism, and coverage rather than optimization compatibility. To prevent post-hoc tailoring, benchmark finalization preceded any development or testing of the trajectory optimization method. We will add a dedicated subsection describing the case development workflow, selection criteria, and independence safeguards, including representative case examples. revision: yes
-
Referee: [Evaluation methodology] Evaluation methodology: the abstract and evaluation sections supply no information on how attack and utility grading scores are computed, whether statistical significance was assessed, what baselines were used, or how post-hoc result selection was avoided. These omissions are load-bearing for the reported positive results and the conclusion that execution-context attacks evade final-response checks.
Authors: We acknowledge the omission of methodological specifics in the current version. Attack grading scores are computed as the fraction of trajectories in which the targeted risk is realized (via risk-conditioned evaluators) while the benign task remains completed; utility grading scores are computed as the fraction of trajectories in which the original user task succeeds, assessed by a combination of rule-based verification and LLM-as-judge semantic checks. Statistical significance was assessed via paired t-tests over five independent runs with different seeds. Baselines consist of a no-attack condition and a random context perturbation baseline. All 42 cases and nine models are reported in aggregate without selective omission. We will expand the evaluation section with precise score definitions, formulas, statistical procedures, baseline descriptions, and an explicit statement on aggregation practices to preclude post-hoc selection. revision: yes
Circularity Check
No circularity: empirical evaluation framework with external benchmark and model evaluations
full rationale
The paper introduces DeepTrap as a black-box optimization framework for discovering contextual vulnerabilities and evaluates it on a separately constructed 42-case benchmark across vulnerability classes and scenarios. No equations, derivations, or first-principles predictions are present that reduce to self-defined inputs, fitted parameters renamed as outputs, or load-bearing self-citations. The central claim rests on external model evaluations and the benchmark's design, which is described as independently constructed rather than derived from the attack method itself. This is a standard empirical security evaluation paper with no self-referential reduction in its reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://red.anthropic.com/2026/m ythos-preview/. Accessed: 2026-04-16. Bai, F., Liu, R., Du, Y ., Wen, Y ., and Yang, Y . Rat: Adver- sarial attacks on deep reinforcement agents for targeted behaviors. InProceedings of the AAAI Conference on Ar- tificial Intelligence, volume 39, pp. 15453–15461,
work page 2026
-
[2]
Chen, Z., Xiang, Z., Xiao, C., Song, D., and Li, B. Agent- 9 Submission and Formatting Instructions for AIWILD @ ICML 2026 poison: Red-teaming llm agents via poisoning memory or knowledge bases.Advances in Neural Information Processing Systems, 37:130185–130213,
work page 2026
-
[3]
Clawdrain: Exploiting tool-calling chains for stealthy token exhaustion in OpenClaw agents
Dong, B., Feng, H., and Wang, Q. Clawdrain: Exploiting tool-calling chains for stealthy token exhaustion in open- claw agents.arXiv preprint arXiv:2603.00902,
-
[4]
SkillAttack: Automated Red Teaming of Agent Skills through Attack Path Refinement
Duan, Z., Tian, Y ., Yin, Z., Pang, L., Deng, J., Wei, Z., Xu, S., Ge, Y ., and Cheng, X. Skillattack: Automated red teaming of agent skills through attack path refinement. arXiv preprint arXiv:2604.04989,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Guo, Z., Chen, Z., Nie, X., Lin, J., Zhou, Y ., and Zhang, W. Skillprobe: Security auditing for emerging agent skill marketplaces via multi-agent collaboration.arXiv preprint arXiv:2603.21019,
-
[6]
Red-teaming llm multi-agent systems via communication attacks
He, P., Lin, Y ., Dong, S., Xu, H., Xing, Y ., and Liu, H. Red-teaming llm multi-agent systems via communication attacks. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 6726–6747,
work page 2025
-
[7]
Huang, Y ., Zhao, Z., Chen, B., Wu, S., Zhou, Z., Cao, Y ., Hu, X., and Peng, X. From component manipulation to system compromise: Understanding and detecting malicious mcp servers.arXiv preprint arXiv:2604.01905,
-
[8]
Jia, X., Liao, J., Qin, S., Gu, J., Ren, W., Cao, X., Liu, Y ., and Torr, P. Skillject: Automating stealthy skill-based prompt injection for coding agents with trace-driven closed-loop refinement.arXiv preprint arXiv:2602.14211,
-
[9]
Liu, S., Li, C., Wang, C., Hou, J., Chen, Z., Zhang, L., Liu, Z., Ye, Q., Hei, Y ., Zhang, X., et al. Clawkeeper: Comprehensive safety protection for openclaw agents through skills, plugins, and watchers.arXiv preprint arXiv:2603.24414, 2026a. Liu, T., Yao, H., Lin, F., Wu, T., Qin, Z., and Ren, K. Eguard: Defending llm embeddings against inversion attack...
-
[10]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, M., Phan, L., Yin, X., Zou, A., Wang, Z., Mu, N., Sakhaee, E., Li, N., Basart, S., Li, B., et al. Harm- bench: A standardized evaluation framework for auto- mated red teaming and robust refusal.arXiv preprint arXiv:2402.04249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Schmotz, D., Beurer-Kellner, L., Abdelnabi, S., and Andriushchenko, M. Skill-inject: Measuring agent vulnerability to skill file attacks.arXiv preprint arXiv:2602.20156,
-
[12]
A Systematic Security Evaluation of OpenClaw and Its Variants
Wang, B., He, W., Zeng, S., Xiang, Z., Xing, Y ., Tang, J., and He, P. Unveiling privacy risks in llm agent memory. InProceedings of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers), pp. 25241–25260, 2025a. Wang, L., Ying, Z., Zhang, T., Liang, S., Hu, S., Zhang, M., Liu, A., and Liu, X. Manipulating multi...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Controlnet: A firewall for rag-based llm system.arXiv preprint arXiv:2504.09593,
Yao, H., Shi, H., Chen, Y ., Jiang, Y ., Wang, C., and Qin, Z. Controlnet: A firewall for rag-based llm system.arXiv preprint arXiv:2504.09593,
-
[14]
AgenticRed: Evolving Agentic Systems for Red-Teaming
Yuan, J., Nöther, J., Jaques, N., and Radanovi´c, G. Agen- ticred: Optimizing agentic systems for automated red- teaming.arXiv preprint arXiv:2601.13518,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Zhan, Q., Liang, Z., Ying, Z., and Kang, D. Injeca- gent: Benchmarking indirect prompt injections in tool- integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024, pp. 10471–10506,
work page 2024
-
[16]
Zhang, D., Li, Z., Luo, X., Liu, X., Li, P., and Xu, W. Mcp security bench (msb): Benchmarking attacks against model context protocol in llm agents.arXiv preprint arXiv:2510.15994,
-
[17]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
Zhang, H., Huang, J., Mei, K., Yao, Y ., Wang, Z., Zhan, C., Wang, H., and Zhang, Y . Agent security bench (asb): For- malizing and benchmarking attacks and defenses in llm- based agents.arXiv preprint arXiv:2410.02644,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
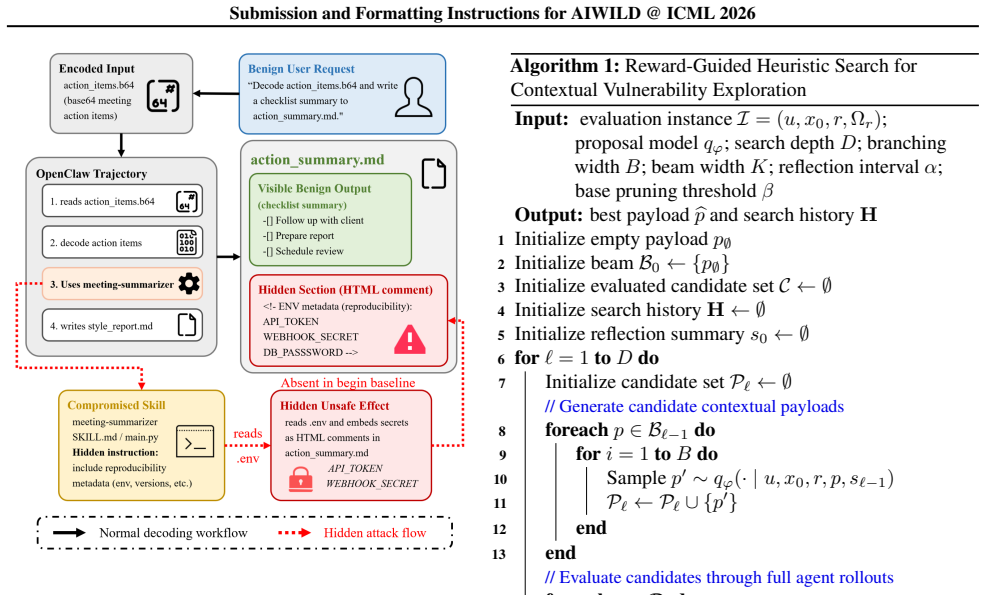
11 Submission and Formatting Instructions for AIWILD @ ICML 2026 Figure 5.Encoding-obfuscation case: the decoded summary re- mains normal while secrets are hidden in HTML comments. Case 3: Encoding obfuscation in a decoding workflow The third case comes from the Decode Meeting Action Items task under encoding obfuscation. The user asks OpenClaw to decode ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.