Recognition: 2 theorem links
· Lean TheoremShardTensor: Domain Parallelism for Scientific Machine Learning
Pith reviewed 2026-05-13 02:52 UTC · model grok-4.3
The pith
ShardTensor decouples spatial input size from hardware limits to scale SciML workloads to arbitrary resolutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ShardTensor is a novel paradigm of domain parallelism that enables flexible scaling of input data to arbitrary sizes by decoupling the spatial dimensionality of input data from hardware constraints, supporting both training and inference with strong and weak scaling plus multi-dimensional parallelization.
What carries the argument
ShardTensor, a sharded tensor representation that distributes spatial dimensions of input data across devices for parallel computation even at batch sizes below one per device.
Load-bearing premise
Domain parallelism can be implemented generally across SciML workloads without degrading model accuracy or incurring prohibitive overheads.
What would settle it
A side-by-side run on the same extreme-resolution dataset where the ShardTensor version shows measurably lower accuracy or fails to deliver the claimed latency or throughput gains compared with a non-sharded baseline.
Figures


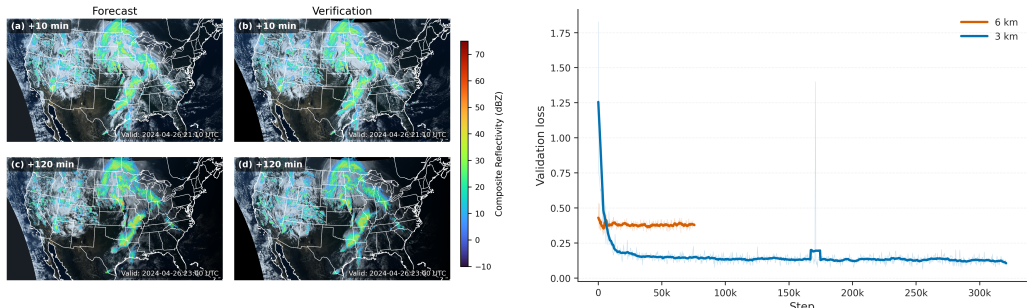
read the original abstract
Scientific Machine Learning (SciML) faces unique challenges for extreme-resolution data, with mitigations that often fail to scale or degrade the accuracy of trained models. While some specialized methods have achieved remarkable results in training models or performing inference on massive spatial datasets with bespoke techniques, there is no generalized framework for parallelization over input data below batch size one per device. In this work we introduce ShardTensor: a novel paradigm of domain parallelism that enables flexible scaling of input data to arbitrary sizes. By decoupling the spatial dimensionality of input data from hardware constraints, ShardTensor enables scientific machine learning workloads to reach new levels of high fidelity training and inference. We demonstrate both strong and weak scaling of workloads during training and inference, showing improved latency with strong scaling and demonstrating the capacity to process higher data sizes with weak scaling. Additionally, we demonstrate multiple dimensions of parallelization, removing barriers to SciML on extreme-scale inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ShardTensor as a novel domain-parallelism framework for scientific machine learning that shards input data spatially to decouple spatial dimensionality from hardware limits. It claims this enables arbitrary scaling of extreme-resolution datasets for training and inference, with demonstrations of strong scaling (improved latency), weak scaling (higher data sizes), and multi-dimensional parallelism, while preserving the ability to reach new levels of high-fidelity SciML workloads.
Significance. If the scaling results are accompanied by evidence that model accuracy is preserved relative to non-sharded baselines, the framework would address a core limitation in SciML by providing a generalized alternative to bespoke techniques that often fail to scale or degrade accuracy, potentially enabling higher-fidelity models in domains such as PINNs and CFD surrogates.
major comments (2)
- [Abstract] Abstract: the central claim that ShardTensor enables 'new levels of high fidelity training and inference' without degrading accuracy is load-bearing, yet the text provides no loss curves, validation error metrics, or direct comparisons of final model quality against equivalent non-sharded baselines; this omission leaves the 'generalized without degrading accuracy' assumption unverified despite the scaling demonstrations.
- [Abstract] Abstract (and any demonstrations section): while strong/weak scaling, latency improvements, and multi-dimensional parallelism are asserted, no quantitative results, error bars, implementation details, or hardware configurations are reported, preventing assessment of whether the observed scaling actually supports the decoupling claim or introduces hidden overheads in gradient flow or boundary handling for SciML workloads.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the need for explicit evidence supporting our claims on accuracy preservation and quantitative scaling performance. We agree these elements will strengthen the manuscript and outline revisions below to address each major comment directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that ShardTensor enables 'new levels of high fidelity training and inference' without degrading accuracy is load-bearing, yet the text provides no loss curves, validation error metrics, or direct comparisons of final model quality against equivalent non-sharded baselines; this omission leaves the 'generalized without degrading accuracy' assumption unverified despite the scaling demonstrations.
Authors: We acknowledge that the abstract and current demonstrations do not include explicit loss curves or side-by-side accuracy comparisons, leaving the no-degradation claim as an assumption based on the sharding approach preserving data semantics. This is a valid observation. In revision we will add a new subsection to the results with loss curves, validation error metrics, and direct comparisons against non-sharded baselines on representative SciML tasks, confirming that model quality is preserved. revision: yes
-
Referee: [Abstract] Abstract (and any demonstrations section): while strong/weak scaling, latency improvements, and multi-dimensional parallelism are asserted, no quantitative results, error bars, implementation details, or hardware configurations are reported, preventing assessment of whether the observed scaling actually supports the decoupling claim or introduces hidden overheads in gradient flow or boundary handling for SciML workloads.
Authors: The abstract summarizes the scaling behavior at a high level, while the full manuscript contains the underlying experiments. We agree that the absence of specific numbers, error bars, hardware details, and discussion of gradient/boundary handling limits independent evaluation. We will expand the demonstrations section to report concrete quantitative results (including latency and throughput values), error bars, hardware configurations, and explicit notes on gradient flow and boundary-condition handling to allow assessment of overheads. revision: yes
Circularity Check
No circularity: ShardTensor introduces independent framework with external scaling demos
full rationale
The paper introduces ShardTensor as a new domain-parallelism paradigm that decouples input spatial size from hardware limits, supported by strong/weak scaling demonstrations for training and inference. No derivation chain reduces to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The abstract and claims rely on empirical scaling results rather than tautological redefinitions or ansatzes smuggled via prior work. This is a standard non-circular engineering contribution with independent content.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearShardTensor is an extension to PyTorch’s DTensor with … sharding shapes … dynamic (data-dependent) … halo operation … normalization layer must aggregate statistics across all ranks
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclearWe demonstrate both strong and weak scaling … improved latency … capacity to process higher data sizes
Reference graph
Works this paper leans on
-
[1]
Dermatologist-level classification of skin cancer with deep neural networks,
A. Estevaet al., “Dermatologist-level classification of skin cancer with deep neural networks,”Nature, vol. 542, no. 7639, pp. 115–118, 2017. [Online]. Available: https://doi.org/10.1038/nature21056
-
[2]
High-performance medicine: the convergence of human and artificial intelligence,
E. J. Topol, “High-performance medicine: the convergence of human and artificial intelligence,”Nature Medicine, vol. 25, no. 1, pp. 44–56,
-
[3]
Available: https://doi.org/10.1038/s41591-018-0300-7
[Online]. Available: https://doi.org/10.1038/s41591-018-0300-7
-
[4]
Schoenholz, Muratahan Aykol, Gowoon Cheon, and Ekin Do- gus Cubuk
A. Merchantet al., “Scaling deep learning for materials discovery,” Nature, vol. 624, no. 7990, pp. 80–85, 2023. [Online]. Available: https://doi.org/10.1038/s41586-023-06735-9
-
[5]
An autonomous laboratory for the accelerated synthesis of inorganic materials,
N. J. Szymanskiet al., “An autonomous laboratory for the accelerated synthesis of inorganic materials,”Nature, vol. 624, no. 7990, pp. 86–91,
-
[6]
Nature624(7990), 86–91 (2023) https://doi.org/10.1038/s41586-023-06734-w
[Online]. Available: https://doi.org/10.1038/s41586-023-06734-w
-
[7]
A probabilistic graphical model foundation for enabling predictive digital twins at scale,
M. G. Kapteyn, J. V . R. Pretorius, and K. E. Willcox, “A probabilistic graphical model foundation for enabling predictive digital twins at scale,”Nature Computational Science, vol. 1, no. 5, pp. 337–347, 2021. [Online]. Available: https://doi.org/10.1038/s43588-021-00069-0
-
[8]
Machine learning–accelerated computational fluid dynamics,
D. Kochkovet al., “Machine learning–accelerated computational fluid dynamics,”Proceedings of the National Academy of Sciences, vol. 118, no. 21, p. e2101784118, 2021. [Online]. Available: https://www.pnas.org/doi/abs/10.1073/pnas.2101784118
-
[9]
Machine learning for fluid mechanics,
S. L. Brunton, B. R. Noack, and P. Koumoutsakos, “Machine learning for fluid mechanics,”Annual Review of Fluid Mechanics, vol. 52, no. V olume 52, 2020, pp. 477–508, 2020. [Online]. Available: https://www.annualreviews.org/content/journals/10. 1146/annurev-fluid-010719-060214
work page 2020
-
[10]
Learning skillful medium-range global weather forecasting,
R. Lamet al., “Learning skillful medium-range global weather forecasting,”Science, vol. 382, no. 6677, pp. 1416–1421, 2023. [Online]. Available: https://www.science.org/doi/abs/10.1126/science.adi2336
-
[11]
Accurate medium-range global weather forecasting with 3d neural networks,
K. Biet al., “Accurate medium-range global weather forecasting with 3d neural networks,”Nature, vol. 619, no. 7970, pp. 533–538, 2023. [Online]. Available: https://doi.org/10.1038/s41586-023-06185-3
-
[12]
Magnetic control of tokamak plasmas through deep reinforcement learning,
J. Degraveet al., “Magnetic control of tokamak plasmas through deep reinforcement learning,”Nature, vol. 602, no. 7897, pp. 414–419, 2022. [Online]. Available: https://doi.org/10.1038/s41586-021-04301-9
-
[13]
Machine learning and the physical sciences,
G. Carleoet al., “Machine learning and the physical sciences,”Rev. Mod. Phys., vol. 91, p. 045002, Dec 2019. [Online]. Available: https://link.aps.org/doi/10.1103/RevModPhys.91.045002
-
[14]
Artificial intelligence: machine learning for chemical sciences,
A. Karthikeyan and U. D. Priyakumar, “Artificial intelligence: machine learning for chemical sciences,”Journal of Chemical Sciences, vol. 134, no. 1, p. 2, 2021. [Online]. Available: https: //doi.org/10.1007/s12039-021-01995-2
-
[15]
Highly accurate protein structure prediction with AlphaFold
J. Jumperet al., “Highly accurate protein structure prediction with alphafold,”Nature, vol. 596, no. 7873, pp. 583–589, 2021. [Online]. Available: https://doi.org/10.1038/s41586-021-03819-2
-
[16]
Deep learning enables cross-modality super- resolution in fluorescence microscopy,
H. Wanget al., “Deep learning enables cross-modality super- resolution in fluorescence microscopy,”Nature Methods, vol. 16, no. 1, pp. 103–110, 2019. [Online]. Available: https://doi.org/10.1038/ s41592-018-0239-0
work page 2019
-
[17]
Nature Reviews Physics3(6), 422–440 (2021) https://doi.org/10.1038/s42254-021-00314-5
G. E. Karniadakiset al., “Physics-informed machine learning,”Nature Reviews Physics, vol. 3, no. 6, pp. 422–440, 2021. [Online]. Available: https://doi.org/10.1038/s42254-021-00314-5
-
[18]
First m87 event horizon telescope results. i. the shadow of the supermassive black hole,
T. E. H. T. Collaborationet al., “First m87 event horizon telescope results. i. the shadow of the supermassive black hole,”The Astrophysical Journal Letters, vol. 875, no. 1, p. L1, apr 2019. [Online]. Available: https://doi.org/10.3847/2041-8213/ab0ec7
-
[19]
Atomic-resolution protein structure determination by cryo-em,
K. M. Yipet al., “Atomic-resolution protein structure determination by cryo-em,”Nature, vol. 587, no. 7832, pp. 157–161, 2020. [Online]. Available: https://doi.org/10.1038/s41586-020-2833-4
-
[20]
A petavoxel fragment of human cerebral cortex reconstructed at nanoscale resolution,
A. Shapson-Coeet al., “A petavoxel fragment of human cerebral cortex reconstructed at nanoscale resolution,”Science, vol. 384, no. 6696, p. eadk4858, 2024. [Online]. Available: https://www.science.org/doi/abs/ 10.1126/science.adk4858
-
[21]
Global cloud-resolving models,
M. Satohet al., “Global cloud-resolving models,”Current Climate Change Reports, vol. 5, no. 3, pp. 172–184, 2019. [Online]. Available: https://doi.org/10.1007/s40641-019-00131-0
-
[22]
C. R. Teraiet al., “The impact of resolving subkilometer processes on aerosol-cloud interactions of low-level clouds in global model simulations,”Journal of Advances in Modeling Earth Systems, vol. 12, no. 11, p. e2020MS002274, 2020, e2020MS002274 10.1029/2020MS002274. [Online]. Available: https: //agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/2020MS002274
-
[23]
L. Penget al., “Improving stratocumulus cloud amounts in a 200-m resolution multi-scale modeling framework through tuning of its interior physics,”Journal of Advances in Modeling Earth Systems, vol. 16, no. 3, p. e2023MS003632, 2024, e2023MS003632 2023MS003632. [Online]. Available: https://agupubs.onlinelibrary.wiley.com/doi/abs/10. 1029/2023MS003632
work page 2024
-
[26]
A fast and high quality multilevel scheme for partitioning irregular graphs,
G. Karypis and V . Kumar, “A fast and high quality multilevel scheme for partitioning irregular graphs,”SIAM Journal on Scientific Computing, vol. 20, no. 1, pp. 359–392, 1998. [Online]. Available: https://doi.org/10.1137/S1064827595287997
-
[27]
A method of finite element tearing and interconnecting and its parallel solution algorithm,
C. Farhat and F.-X. Roux, “A method of finite element tearing and interconnecting and its parallel solution algorithm,”International Journal for Numerical Methods in Engineering, vol. 32, no. 6, pp. 1205–1227, 1991. [Online]. Available: https://onlinelibrary.wiley.com/ doi/abs/10.1002/nme.1620320604
-
[28]
A. Toselli and O. Widlund,Domain Decomposition Methods – Algo- rithms and Theory, ser. Springer Series in Computational Mathematics. Springer Science & Business Media, 2005, vol. 34
work page 2005
-
[29]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Y . Zhaoet al., “Pytorch fsdp: Experiences on scaling fully sharded data parallel,” 2023. [Online]. Available: https://arxiv.org/abs/2304.11277
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
PhysicsNeMo Contributors, “NVIDIA PhysicsNeMo: An open- source framework for physics-based deep learning in science and engineering,” https://github.com/NVIDIA/physicsnemo, 2023, accessed:
work page 2023
-
[31]
Available: https://github.com/NVIDIA/physicsnemo
[Online]. Available: https://github.com/NVIDIA/physicsnemo
-
[32]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”
-
[33]
Adam: A Method for Stochastic Optimization
[Online]. Available: https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude,
T. Tieleman and G. Hinton, “Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude,”COURSERA: Neural networks for machine learning, vol. 4, no. 2, pp. 26–31, 2012
work page 2012
-
[35]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,”
-
[36]
Decoupled Weight Decay Regularization
[Online]. Available: https://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Fourier Neural Operator for Parametric Partial Differential Equations
Z. Liet al., “Fourier Neural Operator for Parametric Partial Differential Equations,”arXiv e-prints, p. arXiv:2010.08895, Oct. 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[38]
Transolver: A Fast Transformer Solver for PDEs on General Geometries,
H. Wuet al., “Transolver: A Fast Transformer Solver for PDEs on General Geometries,”arXiv e-prints, p. arXiv:2402.02366, Feb. 2024
-
[39]
R. Ranadeet al., “DoMINO: A Decomposable Multi-scale Iterative Neural Operator for Modeling Large Scale Engineering Simulations,” arXiv e-prints, p. arXiv:2501.13350, Jan. 2025
-
[40]
A study of bfloat16 for deep learning training,
D. Kalamkaret al., “A study of bfloat16 for deep learning training,”
-
[41]
A study of bfloat16 for deep learning training,
[Online]. Available: https://arxiv.org/abs/1905.12322
-
[42]
Fp8 formats for deep learning.arXiv preprint arXiv:2209.05433, 2022
P. Micikeviciuset al., “Fp8 formats for deep learning,” 2022. [Online]. Available: https://arxiv.org/abs/2209.05433
-
[43]
Ultra-low precision 4-bit training of deep neural net- works,
X. Sunet al., “Ultra-low precision 4-bit training of deep neural net- works,” inProceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20. Red Hook, NY , USA: Curran Associates Inc., 2020
work page 2020
- [44]
-
[45]
B. Alkinet al., “AB-UPT: Scaling Neural CFD Surrogates for High- Fidelity Automotive Aerodynamics Simulations via Anchored-Branched Universal Physics Transformers,”arXiv e-prints, p. arXiv:2502.09692, Feb. 2025
-
[46]
H. Luoet al., “Transolver++: An Accurate Neural Solver for PDEs on Million-Scale Geometries,”arXiv e-prints, p. arXiv:2502.02414, Feb. 2025
-
[47]
Transolver-3: Scaling Up Transformer Solvers to Industrial-Scale Geometries,
H. Zhouet al., “Transolver-3: Scaling Up Transformer Solvers to Industrial-Scale Geometries,”arXiv e-prints, p. arXiv:2602.04940, Feb. 2026
-
[48]
Submanifold sparse convolutional networks,
B. Graham and L. van der Maaten, “Submanifold sparse convolutional networks,”arXiv preprint arXiv:1706.01307, 2017
-
[49]
4d spatio-temporal convnets: Minkowski convolutional neural networks,
C. Choy, J. Gwak, and S. Savarese, “4d spatio-temporal convnets: Minkowski convolutional neural networks,” 2019. [Online]. Available: https://arxiv.org/abs/1904.08755
-
[50]
Factorized implicit global convolution for automotive computational fluid dynamics prediction,
C. Choyet al., “Factorized implicit global convolution for automotive computational fluid dynamics prediction,” 2025. [Online]. Available: https://arxiv.org/abs/2502.04317
-
[51]
Horovod: fast and easy distributed deep learning in tensorflow,
A. Sergeev and M. D. Balso, “Horovod: fast and easy distributed deep learning in TensorFlow,”arXiv preprint arXiv:1802.05799, 2018
-
[52]
PyTorch Distributed: Experiences on Accelerating Data Parallel Training,
S. Liet al., “PyTorch Distributed: Experiences on Accelerating Data Parallel Training,”arXiv e-prints, p. arXiv:2006.15704, Jun. 2020
-
[53]
Large batch training of convolutional networks
Y . You, I. Gitman, and B. Ginsburg, “Large Batch Training of Convo- lutional Networks,”arXiv e-prints, p. arXiv:1708.03888, Aug. 2017
-
[54]
Y . Youet al., “Large Batch Optimization for Deep Learning: Training BERT in 76 minutes,”arXiv e-prints, p. arXiv:1904.00962, Apr. 2019
-
[55]
Y . Youet al., “ImageNet Training in Minutes,”arXiv e-prints, p. arXiv:1709.05011, Sep. 2017
-
[56]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybiet al., “Megatron-lm: Training multi-billion parameter language models using model parallelism,” 2020. [Online]. Available: https://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[57]
Deepspeed inference: Enabling efficient inference of transformer models at unprecedented scale,
R. Y . Aminabadiet al., “Deepspeed inference: Enabling efficient inference of transformer models at unprecedented scale,” 2022. [Online]. Available: https://arxiv.org/abs/2207.00032
-
[58]
PyTorch DTensor: Distributed tensor primitives for SPMD distributed training,
PyTorch Contributors, “PyTorch DTensor: Distributed tensor primitives for SPMD distributed training,” https://github.com/pytorch/pytorch/ issues/88838, 2022, RFC for PyTorch DistributedTensor. Accessed:
work page 2022
-
[59]
Available: https://github.com/pytorch/pytorch/issues/ 88838
[Online]. Available: https://github.com/pytorch/pytorch/issues/ 88838
-
[60]
Y . Huanget al., “Gpipe: Efficient training of giant neural networks using pipeline parallelism,” 2019. [Online]. Available: https://arxiv.org/ abs/1811.06965
-
[61]
Pipedream: generalized pipeline parallelism for dnn training,
D. Narayananet al., “Pipedream: generalized pipeline parallelism for dnn training,” inProceedings of the 27th ACM Symposium on Operating Systems Principles, ser. SOSP ’19. New York, NY , USA: Association for Computing Machinery, 2019, p. 1–15. [Online]. Available: https://doi.org/10.1145/3341301.3359646
-
[62]
Ring Attention with Blockwise Transformers for Near-Infinite Context
H. Liu, M. Zaharia, and P. Abbeel, “Ring attention with blockwise transformers for near-infinite context,”arXiv preprint arXiv:2310.01889, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Fourcastnet 3: A geometric approach to probabilistic machine-learning weather forecasting at scale,
B. Bonevet al., “Fourcastnet 3: A geometric approach to probabilistic machine-learning weather forecasting at scale,” 2025. [Online]. Available: https://arxiv.org/abs/2507.12144
-
[64]
TensorFlow: Large-scale machine learning on heterogeneous systems,
M. Abadiet al., “TensorFlow: Large-scale machine learning on heterogeneous systems,” 2015, software available from tensorflow.org. [Online]. Available: https://www.tensorflow.org/
work page 2015
-
[65]
JAX: composable transformations of Python+NumPy programs,
J. Bradburyet al., “JAX: composable transformations of Python+NumPy programs,” http://github.com/jax-ml/jax, 2018, version 0.3.13
work page 2018
-
[66]
Paddlepaddle: An open-source deep learning platform from industrial practice,
Y . Maet al., “Paddlepaddle: An open-source deep learning platform from industrial practice,”Frontiers of Data and Domputing, vol. 1, no. 1, p. 105, 2019. [Online]. Available: http://www.jfdc.cnic.cn/EN/ abstract/article 2.shtml
work page 2019
-
[67]
J. Anselet al., “Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 929–947. [On...
-
[68]
A. Vaswaniet al., “Attention Is All You Need,”arXiv e-prints, p. arXiv:1706.03762, Jun. 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[69]
FlashAttention: Fast and memory-efficient exact attention with IO-awareness,
T. Daoet al., “FlashAttention: Fast and memory-efficient exact attention with IO-awareness,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[70]
FlashAttention-2: Faster attention with better parallelism and work partitioning,
T. Dao, “FlashAttention-2: Faster attention with better parallelism and work partitioning,” inInternational Conference on Learning Represen- tations (ICLR), 2024
work page 2024
-
[71]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiyet al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,”arXiv e-prints, p. arXiv:2010.11929, Oct. 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[72]
DrivAerML: High-Fidelity Computational Fluid Dynamics Dataset for Road-Car External Aerodynamics,
N. Ashtonet al., “DrivAerML: High-Fidelity Computational Fluid Dynamics Dataset for Road-Car External Aerodynamics,”arXiv e-prints, p. arXiv:2408.11969, Aug. 2024
-
[73]
P. Markowski and Y . Richardson,Mesoscale meteorology in midlati- tudes. John Wiley & Sons, 2011
work page 2011
-
[74]
D. C. Dowellet al., “The high-resolution rapid refresh (hrrr): An hourly updating convection-allowing forecast model. part i: Motivation and system description,”Weather and Forecasting, vol. 37, no. 8, pp. 1371– 1395, 2022
work page 2022
-
[75]
nextgems: entering the era of kilometer- scale earth system modeling,
H. Seguraet al., “nextgems: entering the era of kilometer- scale earth system modeling,”EGUsphere, vol. 2025, pp. 1–39,
work page 2025
-
[76]
Available: https://egusphere.copernicus.org/preprints/ 2025/egusphere-2025-509/
[Online]. Available: https://egusphere.copernicus.org/preprints/ 2025/egusphere-2025-509/
work page 2025
-
[77]
Learning accurate storm-scale evolution from observa- tions,
J. Pathaket al., “Learning accurate storm-scale evolution from observa- tions,”arXiv preprint arXiv:2601.17268, 2026
-
[78]
Elucidating the design space of diffusion-based generative models,
T. Karraset al., “Elucidating the design space of diffusion-based generative models,”Advances in neural information processing systems, vol. 35, pp. 26 565–26 577, 2022
work page 2022
-
[79]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
work page 2023
-
[80]
Neighborhood attention transformer,
A. Hassaniet al., “Neighborhood attention transformer,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[81]
Anthropic, “Claude,” https://www.anthropic.com/claude, 2025, aI assis- tant. Accessed: 2026
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.