Recognition: no theorem link
EVOCHAMBER: Test-Time Co-evolution of Multi-Agent System at Individual, Team, and Population Scales
Pith reviewed 2026-05-13 02:33 UTC · model grok-4.3
The pith
Multi-agent test-time evolution evolves collaboration structures and knowledge flows to produce emergent specialists from identical agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
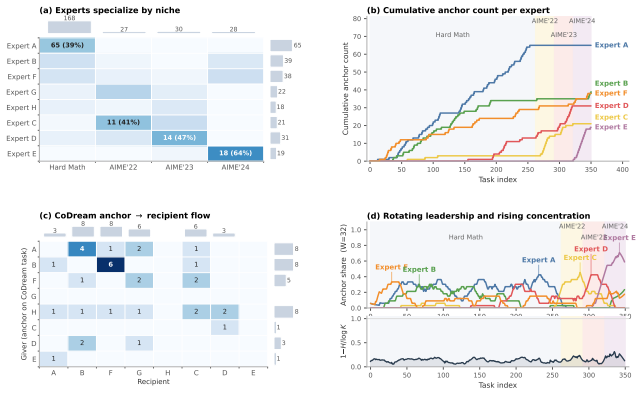
Starting from several identical agents, the combination of asymmetric collaborative reflection after failures, online niche-conditioned team assembly, and population-level fork-merge-prune operators causes four to five stable specialist roles to emerge spontaneously and produces accuracies of 63.9 percent on competition math, 75.7 percent on code, and 87.1 percent on multi-domain reasoning, with the largest relative improvement of 32 percent on math traced to the asymmetric transfer step.
What carries the argument
CODREAM, the post-task collaborative dreaming protocol in which agents reflect together on failures or disagreements and route distilled insights asymmetrically from stronger to weaker agents on the specific failed niche.
Load-bearing premise
The performance gains and the spontaneous emergence of distinct specialists result specifically from the three-scale co-evolution mechanisms rather than from extra inference compute or prompt variations alone.
What would settle it
An ablation that keeps total inference steps constant but disables asymmetric routing in CODREAM and the population lifecycle operators, then checks whether accuracies drop to match the best non-evolving multi-agent baseline.
Figures
read the original abstract
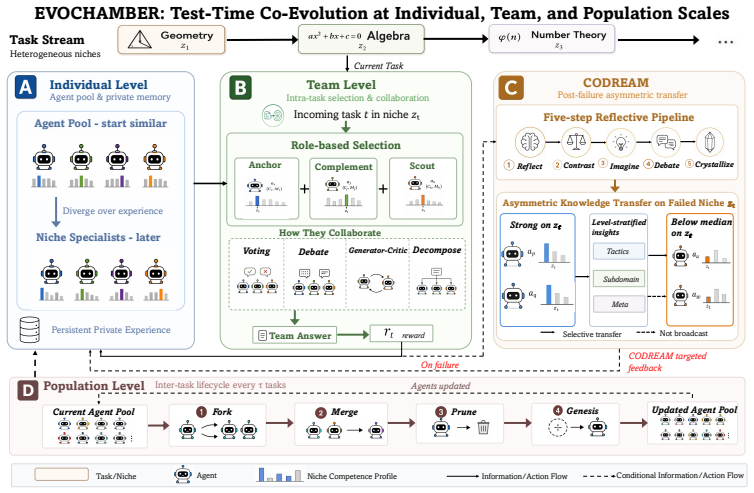
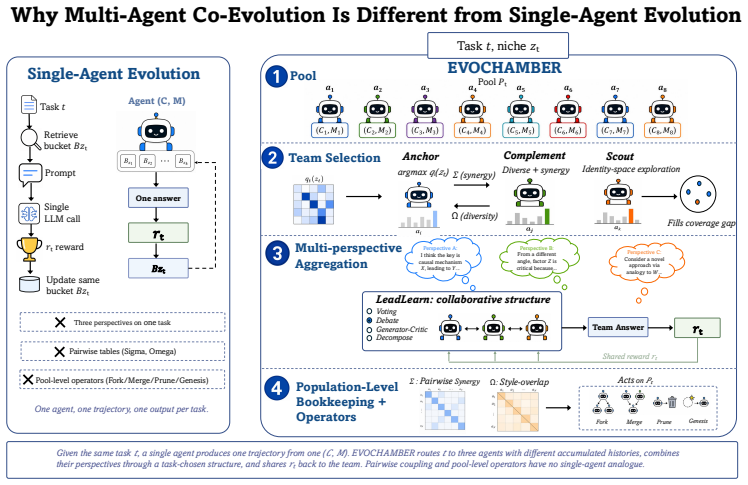
We argue that multi-agent test-time evolution is not single-agent evolution replicated N times. A single-agent learner can only evolve its own context and memory. A multi-agent system additionally evolves who collaborates, how they collaborate, and how knowledge flows across the population. These components have no single-agent counterpart and can produce phenomena such as emergent specialization. Yet prior test-time methods either confine experiences to individual agents, forfeiting cross-agent learning, or broadcast symmetrically to all agents, erasing the specialization that makes collaboration valuable. We present EVOCHAMBER, a training-free framework that instantiates test-time evolution at three levels over a coevolving agent pool. At its core is CODREAM (Collaborative Dreaming), a post-task protocol triggered on team failure or disagreement, in which agents collaboratively reflect, distill insights, and route them asymmetrically from strong to weak agents on the failed niche, preserving specialization while filling knowledge gaps. Team-level operators assemble niche-conditioned teams and select collaboration structures online. Population-level lifecycle operators fork, merge, prune, and seed agents under performance pressure. On three heterogeneous task streams with Qwen3-8B, EVOCHAMBER reaches 63.9% on competition math, 75.7% on code, and 87.1% on multi-domain reasoning, outperforming the best baseline by 32% relative on math and confirming asymmetric cross-agent transfer as the primary driver in ablation. Starting from several identically initialized agents, four to five stable niche specialists spontaneously emerge, a structural signature of multi-agent evolution that no single-agent learner can express. See our code at: https://github.com/Mercury7353/EvoChamber
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents EVOCHAMBER, a training-free framework for test-time co-evolution of multi-agent LLM systems operating at individual (CODREAM: collaborative reflection, distillation, and asymmetric routing from strong to weak agents on failures), team (niche-conditioned team assembly and collaboration structure selection), and population (fork/merge/prune/seed lifecycle operators) scales. It claims that on three heterogeneous task streams with Qwen3-8B, the system achieves 63.9% on competition math, 75.7% on code, and 87.1% on multi-domain reasoning, outperforming the best baseline by 32% relative on math; an ablation confirms asymmetric cross-agent transfer as the primary driver; and four to five stable niche specialists emerge spontaneously from identically initialized agents, a phenomenon impossible for single-agent learners.
Significance. If the results hold under matched conditions, the work would be significant for showing that multi-agent test-time evolution enables emergent specialization and performance gains beyond single-agent evolution or symmetric broadcasting, with no single-agent counterpart for evolving collaboration structures and knowledge flow. The training-free nature, explicit protocols, code release, and focus on heterogeneous streams are strengths that could influence agent system design.
major comments (2)
- [Abstract] Abstract: the central empirical claims (63.9% math accuracy, 32% relative gain over best baseline, ablation confirming asymmetric transfer as primary driver, and emergence of 4-5 niche specialists) are stated with concrete numbers but provide no details on baseline implementations, statistical significance, task stream construction, or exact experimental controls, leaving the soundness of the performance and ablation results only partially supported.
- [Abstract] Abstract and experimental sections: the multi-scale mechanisms (CODREAM reflections/distillations/routings, niche-conditioned teams, population lifecycle operators) inherently increase LLM forward passes and tokens per task relative to single-agent or symmetric baselines. Without explicit reporting of average calls or token budget per task across all methods and confirmation that baselines received equivalent compute, the reported gains cannot be isolated from simple inference scaling; the ablation does not address this.
minor comments (1)
- [Abstract] The GitHub link for code is provided, which supports reproducibility; ensure the released code includes exact baseline reproductions and logging of per-task token usage to allow verification of the compute-matched claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications on the experimental reporting and indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (63.9% math accuracy, 32% relative gain over best baseline, ablation confirming asymmetric transfer as primary driver, and emergence of 4-5 niche specialists) are stated with concrete numbers but provide no details on baseline implementations, statistical significance, task stream construction, or exact experimental controls, leaving the soundness of the performance and ablation results only partially supported.
Authors: The abstract is intentionally concise to summarize the primary contributions and results within length constraints. Complete details on baseline implementations (single-agent evolution, symmetric multi-agent broadcasting, and other test-time adaptation methods), statistical significance (averages over multiple runs with standard deviations and significance testing), task stream construction (three heterogeneous streams using specific datasets for competition math, code, and multi-domain reasoning), and experimental controls (identical initializations, fixed Qwen3-8B backbone, and consistent hyperparameters) are provided in the Experiments section and appendices. The soundness of the results is supported by these sections. To address the concern, we will partially revise the abstract to include a brief reference to the controlled experimental setup and statistical validation. revision: partial
-
Referee: [Abstract] Abstract and experimental sections: the multi-scale mechanisms (CODREAM reflections/distillations/routings, niche-conditioned teams, population lifecycle operators) inherently increase LLM forward passes and tokens per task relative to single-agent or symmetric baselines. Without explicit reporting of average calls or token budget per task across all methods and confirmation that baselines received equivalent compute, the reported gains cannot be isolated from simple inference scaling; the ablation does not address this.
Authors: We agree that explicit compute accounting is necessary to isolate gains from inference scaling. The multi-scale mechanisms do increase the number of LLM calls relative to single-agent baselines. However, the ablation isolates the contribution of asymmetric transfer by comparing variants within the same multi-agent framework (keeping team assembly and population operators fixed), where call counts remain comparable. To fully address the point, we will add a table in the revised experimental section reporting average LLM forward passes and token consumption per task for EVOCHAMBER and all baselines, allowing direct assessment of performance under matched or reported compute budgets. revision: yes
Circularity Check
No circularity: framework defined by explicit protocols evaluated on external benchmarks
full rationale
The paper introduces EVOCHAMBER as a training-free system with concrete operators (CODREAM asymmetric routing, niche-conditioned team assembly, population lifecycle fork/merge/prune) whose behavior is measured directly against held-out task performance on math, code, and reasoning streams. Ablations are invoked to attribute gains to asymmetric transfer, but these are empirical comparisons rather than reductions of outputs to fitted inputs or self-referential definitions. No equations, uniqueness theorems, or ansatzes are presented that loop back to the claimed results by construction. The spontaneous emergence of specialists is reported as an observed structural outcome, not a definitional tautology. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021. URLhttps://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Memcollab: Cross-agent memory collab- oration via contrastive trajectory distillation, 2026
Yurui Chang, Yiran Wu, Qingyun Wu, and Lu Lin. Memcollab: Cross-agent memory collab- oration via contrastive trajectory distillation, 2026. URL https://arxiv.org/abs/2603. 23234
work page 2026
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code, 2021. URLhttps://arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, Yujia Qin, Xin Cong, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[5]
Multi-agent evolve: Llm self-improve through co-evolution.arXiv preprint arXiv:2510.23595,
Yixing Chen, Yiding Wang, Siqi Zhu, Haofei Yu, Tao Feng, Muhan Zhang, Mostofa Patwary, and Jiaxuan You. Multi-agent evolve: LLM self-improve through co-evolution, 2025. URL https://arxiv.org/abs/2510.23595
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/ abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[8]
DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)...
work page 2019
-
[9]
EvoMem: Improving multi-agent planning with dual-evolving memory, 2025
Wenzhe Fan, Ning Yan, and Masood Mortazavi. EvoMem: Improving multi-agent planning with dual-evolving memory, 2025. URLhttps://arxiv.org/abs/2511.01912
-
[10]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
work page 2021
-
[11]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for a multi-agent collaborative framework, 2024. URLhttps://arxiv.org/abs/2308.00352
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Automated design of agentic systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[13]
Self-evolving multi-agent collaboration networks for software development
Yue Hu, Yuzhu Cai, Yaxin Du, Xinyu Zhu, Xiangrui Liu, Zijie Yu, Yuchen Hou, Shuo Tang, and Siheng Chen. Self-evolving multi-agent collaboration networks for software development. InThe Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=4R71pdPBZp
work page 2025
-
[14]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023. 11
work page 2023
-
[15]
CAMEL: Communicative agents for “mind” exploration of large language model society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for “mind” exploration of large language model society. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[16]
Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
work page 2022
-
[17]
Encouraging divergent thinking in large language models through multi- agent debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language models through multi- agent debate. InFindings of the Association for Computational Linguistics: EMNLP 2024, 2024
work page 2024
-
[18]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in neural information processing systems, 36:21558–21572, 2023
work page 2023
-
[19]
A dynamic LLM-powered agent network for task-oriented agent collaboration
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. A dynamic LLM-powered agent network for task-oriented agent collaboration. InFirst Conference on Language Modeling, 2024
work page 2024
-
[20]
Self- refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self- refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Sy...
work page 2023
-
[21]
OpenAI. GPT-4 technical report, 2024. URLhttps://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
OpenAI. GPT-4.1 family, 2025. URLhttps://openai.com/index/gpt-4-1/
work page 2025
-
[23]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems, 2024. URL https: //arxiv.org/abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Chanwoo Park, Seungju Han, Xingzhi Guo, Asuman E Ozdaglar, Kaiqing Zhang, and Joo- Kyung Kim. MAPoRL: Multi-agent post-co-training for collaborative large language models with reinforcement learning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30215–30248, 2025
work page 2025
-
[25]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 15174–15186, 2024
work page 2024
-
[26]
Scaling large language model-based multi-agent collaboration
Chen Qian, Zihao Xie, YiFei Wang, Wei Liu, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Scaling large language model-based multi-agent collaboration. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[27]
Archon: An architecture search frame- work for inference-time techniques
Jon Saad-Falcon, Adrian Gamber, and Christopher Ré. Archon: An architecture search frame- work for inference-time techniques. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[28]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum? id=vAElhFcKW6
work page 2023
-
[29]
Scaling LLM test-time compute optimally can be more effective than scaling model parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[30]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Mixture-of-agents enhances large language model capabilities, 2024
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities, 2024. URL https://arxiv.org/abs/2406. 04692
work page 2024
-
[32]
MAS$^2$: Self-generative, self-configuring, self-rectifying multi-agent systems
Kun Wang, Guibin Zhang, ManKit Ye, Xinyu Deng, Dongxia Wang, Xiaobin Hu, Jinyang Guo, Yang Liu, and Yufei Guo. MAS$^2$: Self-generative, self-configuring, self-rectifying multi-agent systems. InThe Fourteenth International Conference on Learning Representations,
-
[33]
URLhttps://openreview.net/forum?id=qumy27hMDY
-
[34]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=1PL1NIMMrw
work page 2023
-
[35]
ScoreFlow: Mastering LLM agent workflows via score-based preference optimization, 2025
Yinjie Wang, Ling Yang, Guohao Li, Mengdi Wang, and Bryon Aragam. ScoreFlow: Mastering LLM agent workflows via score-based preference optimization, 2025. URL https://arxiv. org/abs/2502.04306
-
[36]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, 2022
work page 2022
-
[37]
Autogen: Enabling next-gen LLM applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. Autogen: Enabling next-gen LLM applications via multi-agent conversations. InFirst Conference on Language Modeling, 2024
work page 2024
-
[38]
CoMAS: Co-evolving multi-agent systems via interaction rewards
Xiangyuan Xue, Yifan Zhou, Guibin Zhang, Zaibin Zhang, Yijiang Li, Chen Zhang, Zhenfei Yin, Philip Torr, Wanli Ouyang, and LEI BAI. CoMAS: Co-evolving multi-agent systems via interaction rewards. InThe Fourteenth International Conference on Learning Representations,
-
[39]
URLhttps://openreview.net/forum?id=ihwAzktmWc
-
[40]
Agentnet: Decentralized evolutionary coordination for LLM-based multi-agent systems
Yingxuan Yang, Huacan Chai, Shuai Shao, Yuanyi Song, Siyuan Qi, Renting Rui, and Weinan Zhang. Agentnet: Decentralized evolutionary coordination for LLM-based multi-agent systems. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=tXqLxHlb8Z
work page 2025
-
[41]
HotpotQA: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
work page 2018
-
[42]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[43]
Evoagent: Towards automatic multi-agent generation via evolutionary algorithms
Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Dongsheng Li, and Deqing Yang. Evoagent: Towards automatic multi-agent generation via evolutionary algorithms. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6192–6217, 2025
work page 2025
-
[44]
AFlow: Automating agentic workflow generation
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xiong-Hui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. AFlow: Automating agentic workflow generation. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[45]
ExpeL: LLM agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. ExpeL: LLM agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642, 2024
work page 2024
-
[46]
decompose the problem into sub-steps independently
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. GPTSwarm: Language agents as optimizable graphs. InForty-first International Conference on Machine Learning, 2024. 13 Appendix A Limitations and Future Work Limitations.We validate on two model families. Evaluating additional architectures would strengt...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.