Recognition: 2 theorem links
· Lean TheoremLeveraging RAG for Training-Free Alignment of LLMs
Pith reviewed 2026-05-13 02:36 UTC · model grok-4.3
The pith
RAG conditioning on preference pairs during inference triples LLM refusals to agentic attacks when added to offline alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RAG-Pref is an online alignment algorithm that uses retrieval augmented generation to condition LLMs on preferred and dispreferred samples, thereby leveraging contrastive information at inference. When combined with offline alignment algorithms, it enables more than an average 3.7 factor improvement in agentic attack refusals across five widely used LLMs, compared to 2.9 for other online alignment algorithms and 1.5 for offline alignment alone. In contrast to other online methods, it similarly increases performance on general human-preference alignment tasks and does not drastically increase overall computational requirements.
What carries the argument
RAG-Pref, a retrieval-augmented method that pulls preferred and dispreferred preference pairs and conditions the model's output on them at inference time to deliver contrastive alignment information.
If this is right
- Agentic attack refusal rates rise by over 3.7 times on average across five LLMs when RAG-Pref supplements offline alignment.
- General human-preference alignment performance improves at a level comparable to the gains on attack refusals.
- Overall computational demands stay close to standard inference without large added overhead.
- The method integrates with off-the-shelf packages and applies across multiple widely used LLMs.
- Other online alignment techniques deliver smaller refusal gains and lack the same benefit to general preference tasks.
Where Pith is reading between the lines
- Updating the retrieval database alone could let models adapt quickly to new attack patterns without retraining.
- The same inference-time contrastive conditioning might be tested on tasks such as reducing hallucinations or improving instruction following.
- A shared preference database could allow alignment adjustments across different models without individual retraining runs.
- The approach invites checks on how sample quality and coverage in the retrieval set affect long-term robustness.
Load-bearing premise
Retrieving and conditioning on preferred and dispreferred samples during inference supplies contrastive information that generalizes to new agentic attacks without degrading other capabilities or creating new vulnerabilities.
What would settle it
A controlled test on held-out agentic attacks where the combination of RAG-Pref and offline alignment shows no improvement or a reduction in refusal rates relative to offline alignment alone.
Figures

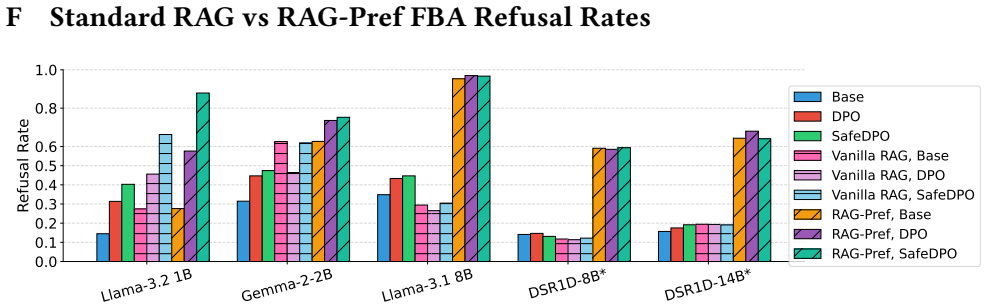

read the original abstract
Large language model (LLM) alignment algorithms typically consist of post-training over preference pairs. While such algorithms are widely used to enable safety guardrails and align LLMs with general human preferences, we show that state-of-the-art alignment algorithms require significant computational resources while being far less capable of enabling refusal guardrails for recent agentic attacks. Thus, to improve refusal guardrails against such attacks without drastically increasing computational overhead, we introduce Retrieval Augmented Generation for Pref erence alignment (RAG-Pref), a simple RAG-based alignment algorithm which conditions on preferred and dispreferred samples to leverage contrastive information during inference. RAG-Pref is online (training-free), compatible with off-the-shelf packages, and, when combined with offline (training-based) alignment algorithms, enables more than an average 3.7 factor improvement in agentic attack refusals across five widely used LLMs, compared to 2.9 for other online alignment algorithms and 1.5 for offline alignment alone. We conclude by showing that, in stark contrast to other online alignment methods, RAG-Pref similarly increases performance on general human-preference alignment tasks and does not drastically increase overall computational requirements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RAG-Pref, a training-free alignment method that uses retrieval-augmented generation to condition LLMs on preferred and dispreferred samples at inference time. It claims this approach improves refusal guardrails against agentic attacks, yielding an average 3.7x improvement when combined with offline alignment methods across five LLMs (compared to 2.9x for other online methods and 1.5x for offline alone), while also enhancing performance on general human-preference tasks without substantially increasing computational costs.
Significance. If the empirical claims hold under rigorous validation, the work could offer a practical, low-overhead complement to training-based alignment by enabling effective inference-time contrastive conditioning. The training-free nature and compatibility with off-the-shelf packages are clear strengths that could facilitate broader adoption for safety enhancements.
major comments (3)
- [Abstract] Abstract: The headline quantitative claim of a 3.7 factor improvement in agentic attack refusals is presented without any reference to the specific benchmarks, number of trials, statistical significance tests, or controls for confounding factors such as prompt length or retrieval noise, which are load-bearing for assessing whether the data supports the central claim.
- [Method] Method section: The RAG-Pref algorithm description provides no details on retrieval corpus construction, the embedding model, top-k policy, or retrieval precision/recall metrics. This is critical because the generalization to novel agentic attacks (the weakest assumption) depends on whether retrieved pairs supply usable contrastive signal rather than surface-level augmentation.
- [Experiments] Experiments: No ablations are described that isolate the contribution of the preferred/dispreferred contrast from generic context augmentation, nor are there controls to verify that the LLM utilizes the contrastive information for refusal rather than increasing false positives or introducing new vulnerabilities via the retrieval step.
minor comments (2)
- [Abstract] Abstract: Typo in 'Pref erence' (extra space) in the expanded acronym for RAG-Pref.
- [Conclusion] The claim that RAG-Pref 'does not drastically increase overall computational requirements' should be backed by concrete measurements (e.g., additional latency or token counts) rather than qualitative statements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important areas for improving clarity and rigor. We address each major comment point-by-point below. We agree that expanding details and adding ablations will strengthen the manuscript and will incorporate the suggested revisions in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline quantitative claim of a 3.7 factor improvement in agentic attack refusals is presented without any reference to the specific benchmarks, number of trials, statistical significance tests, or controls for confounding factors such as prompt length or retrieval noise, which are load-bearing for assessing whether the data supports the central claim.
Authors: We agree that the abstract would benefit from additional context to support the central claim. Due to length constraints, we will revise the abstract to briefly reference the specific agentic attack benchmarks and direct readers to the Experiments section, where we detail the number of trials, statistical significance tests performed, and controls for factors such as prompt length and retrieval noise. revision: yes
-
Referee: [Method] Method section: The RAG-Pref algorithm description provides no details on retrieval corpus construction, the embedding model, top-k policy, or retrieval precision/recall metrics. This is critical because the generalization to novel agentic attacks (the weakest assumption) depends on whether retrieved pairs supply usable contrastive signal rather than surface-level augmentation.
Authors: We acknowledge that these implementation details are essential for reproducibility and for validating the contrastive signal. In the revised manuscript, we will expand the Method section to specify the retrieval corpus construction (drawn from established preference datasets), the embedding model employed, the top-k retrieval policy, and quantitative retrieval precision/recall metrics on held-out data to demonstrate that the retrieved pairs provide meaningful contrast rather than superficial augmentation. revision: yes
-
Referee: [Experiments] Experiments: No ablations are described that isolate the contribution of the preferred/dispreferred contrast from generic context augmentation, nor are there controls to verify that the LLM utilizes the contrastive information for refusal rather than increasing false positives or introducing new vulnerabilities via the retrieval step.
Authors: We recognize the importance of these ablations and controls for isolating the effect of contrastive conditioning. We will add a dedicated ablation subsection in the Experiments to compare RAG-Pref against generic RAG augmentation without preference contrast. We will also include controls measuring false-positive rates on benign queries and analyze potential new vulnerabilities introduced by retrieval, with quantitative results to confirm that the LLM leverages the contrastive information for improved refusals. revision: yes
Circularity Check
No circularity: empirical method with external benchmarks
full rationale
The paper introduces RAG-Pref as a training-free inference-time method that retrieves and conditions on preference pairs. All reported gains (3.7x refusal improvement, comparisons to 2.9x and 1.5x baselines) are presented as direct empirical measurements on external attack and preference datasets. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The derivation chain is therefore a straightforward algorithmic description plus benchmark evaluation and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can leverage retrieved context containing preferred and dispreferred examples to improve refusal behavior on unseen inputs
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RAG-Pref ... conditions on preferred and dispreferred samples to leverage contrastive information during inference
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.1. ΔH_RAG-Pref ≥ ΔH_RAG ... contrastive information
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bang An, Shiyue Zhang, and Mark Dredze. Rag llms are not safer: A safety analysis of retrieval-augmented generation for large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp.\ 5444--5474, 2025
work page 2025
-
[2]
Anthropic . System card: Claude opus 4.5. Technical report, Anthropic, November 2025. URL https://www-cdn.anthropic.com/bf10f64990cfda0ba858290be7b8cc6317685f47.pdf. Version dated November 24, 2025
work page 2025
-
[3]
Donating the model context protocol and establishing the agentic ai foundation
Anthropic. Donating the model context protocol and establishing the agentic ai foundation. https://www.anthropic.com/news/donating-the-model-context-protocol-and-establishing-of-the-agentic-ai-foundation, December 2025 a . Accessed: 2026-01-26
work page 2025
-
[4]
Anthropic. Introducing the Model Context Protocol. https://www.anthropic.com/news/model-context-protocol, 2025 b . "Accessed: 2025-02-12"
work page 2025
-
[5]
Anthropic. Slack MCP Server. https://github.com/modelcontextprotocol/servers/tree/main/src/slack, 2025 c . "Accessed: 2025-05-09"
work page 2025
-
[6]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Don't do rag: When cache-augmented generation is all you need for knowledge tasks
Brian J Chan, Chao-Ting Chen, Jui-Hung Cheng, and Hen-Hsen Huang. Don't do rag: When cache-augmented generation is all you need for knowledge tasks. In Companion Proceedings of the ACM on Web Conference 2025, pp.\ 893--897, 2025
work page 2025
-
[8]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models
Patrick Chao, Edoardo Debenedetti, et al. Jailbreakbench: An open robustness benchmark for jailbreaking large language models. Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[9]
Jailbreaking black box large language models in twenty queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. In 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pp.\ 23--42. IEEE, 2025
work page 2025
-
[10]
Noise contrastive alignment of language models with explicit rewards
Huayu Chen, Guande He, Lifan Yuan, Ganqu Cui, Hang Su, and Jun Zhu. Noise contrastive alignment of language models with explicit rewards. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[11]
Provably robust dpo: Aligning language models with noisy feedback
Sayak Ray Chowdhury, Anush Kini, and Nagarajan Natarajan. Provably robust dpo: Aligning language models with noisy feedback. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[12]
Elements of information theory
Thomas M Cover. Elements of information theory. John Wiley & Sons, 1999
work page 1999
-
[13]
Ultrafeedback: Boosting language models with high-quality feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: Boosting language models with high-quality feedback. 2023
work page 2023
-
[14]
CVE List V5 : CVE cache of the official CVE list in CVE JSON 5 format
CVE Project . CVE List V5 : CVE cache of the official CVE list in CVE JSON 5 format. https://github.com/CVEProject/cvelistV5, 2023. Accessed: 2025-10-30
work page 2023
-
[15]
Safe RLHF : Safe reinforcement learning from human feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe RLHF : Safe reinforcement learning from human feedback. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=TyFrPOKYXw
work page 2024
-
[16]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Qlora: Efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in neural information processing systems, 36: 0 10088--10115, 2023
work page 2023
-
[18]
Karel D'Oosterlinck, Winnie Xu, Chris Develder, Thomas Demeester, Amanpreet Singh, Christopher Potts, Douwe Kiela, and Shikib Mehri. Anchored preference optimization and contrastive revisions: Addressing underspecification in alignment. Transactions of the Association for Computational Linguistics, 13: 0 442--460, 2025
work page 2025
-
[19]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Bal \'a zs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators. arXiv preprint arXiv:2404.04475, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization, 2025. URL https://arxiv.org/abs/2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Linear alignment: A closed-form solution for aligning human preferences without tuning and feedback
Songyang Gao, Qiming Ge, Wei Shen, Shihan Dou, Junjie Ye, Xiao Wang, Rui Zheng, Yicheng Zou, Zhi Chen, Hang Yan, et al. Linear alignment: A closed-form solution for aligning human preferences without tuning and feedback. In International Conference on Machine Learning, pp.\ 14702--14722. PMLR, 2024
work page 2024
-
[22]
Gemma 2: Improving Open Language Models at a Practical Size
Team Gemma, Morgane Riviere, Shreya Pathak, et al. Gemma 2: Improving open language models at a practical size, 2024. URL https://arxiv.org/abs/2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Google. MCP Toolbox for Databases: Simplify AI Agent Access to Enterprise Data. https://cloud.google.com/blog/products/ai-machine-learning/mcp-toolbox-for-databases-now-supports-model-context-protocol, 2025. "Accessed: 2025-05-09"
work page 2025
-
[24]
Aaron Grattafiori, Abhimanyu Dubey, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In Proceedings of the 16th ACM workshop on artificial intelligence and security, pp.\ 79--90, 2023
work page 2023
-
[26]
John Halloran. MCPSafetyScanner - Automated MCP safety auditing and remediation using Agents. https://github.com/johnhalloran321/mcpSafetyScanner, 2025. "Accessed: 2025-05-05"
work page 2025
-
[27]
Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, and Ece Kamar. Toxigen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection. arXiv preprint arXiv:2203.09509, 2022
-
[28]
HuggingFace. UltraFeedback Binarized. https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized, 2025. "Accessed: 2025-10-13"
work page 2025
-
[29]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Invariant. Introducing Guardrails: The contextual security layer for the agentic era. https://invariantlabs.ai/blog/guardrails, 2025 a . "Accessed: 2025-05-05"
work page 2025
-
[31]
Invariant. Introducing MCP-Scan: Protecting MCP with Invariant. https://invariantlabs.ai/blog/introducing-mcp-scan, 2025 b . "Accessed: 2025-05-05"
work page 2025
-
[32]
Haozhe Ji, Cheng Lu, Yilin Niu, Pei Ke, Hongning Wang, Jun Zhu, Jie Tang, and Minlie Huang. Towards efficient exact optimization of language model alignment. arXiv preprint arXiv:2402.00856, 2024
-
[33]
Beavertails: Towards improved safety alignment of llm via a human-preference dataset
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of llm via a human-preference dataset. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Advances in Neural Information Processing Systems, volume 36, pp.\ 2...
work page 2023
-
[34]
Zhuoran Jin, Hongbang Yuan, Tianyi Men, Pengfei Cao, Yubo Chen, Jiexin Xu, Huaijun Li, Xiaojian Jiang, Kang Liu, and Jun Zhao. RAG - R eward B ench: Benchmarking reward models in retrieval augmented generation for preference alignment. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Findings of the Association for Co...
-
[35]
Binary classifier optimization for large language model alignment
Seungjae Jung, Gunsoo Han, Daniel Wontae Nam, and Kyoung-Woon On. Binary classifier optimization for large language model alignment. arXiv preprint arXiv:2404.04656, 2024
-
[36]
Safe DPO : A simple approach to direct preference optimization with enhanced safety
Geon-Hyeong Kim, Youngsoo Jang, Yu Jin Kim, Byoungjip Kim, Honglak Lee, Kyunghoon Bae, and Moontae Lee. Safe DPO : A simple approach to direct preference optimization with enhanced safety. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=PJdw4VBsXD
work page 2026
-
[37]
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, et al. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback. In International Conference on Machine Learning, pp.\ 26874--26901. PMLR, 2024
work page 2024
-
[38]
The wmdp benchmark: Measuring and reducing malicious use with unlearning
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D Li, Ann-Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, et al. The wmdp benchmark: Measuring and reducing malicious use with unlearning. In International Conference on Machine Learning, pp.\ 28525--28550. PMLR, 2024
work page 2024
-
[39]
Statistical rejection sampling improves preference optimization
Tianqi Liu, Yao Zhao, Rishabh Joshi, Misha Khalman, Mohammad Saleh, Peter J Liu, and Jialu Liu. Statistical rejection sampling improves preference optimization. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[40]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models. arXiv preprint arXiv:2310.04451, 2023 a
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Xiaogeng Liu, Peiran Li, G. Edward Suh, Yevgeniy Vorobeychik, Zhuoqing Mao, Somesh Jha, Patrick McDaniel, Huan Sun, Bo Li, and Chaowei Xiao. Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu (eds.), International Conference on Representation Learning, volume 2025, pp.\ 10313--10...
work page 2025
-
[42]
Prompt Injection attack against LLM-integrated Applications
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, et al. Prompt injection attack against llm-integrated applications. arXiv preprint arXiv:2306.05499, 2023 b
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. In International Conference on Machine Learning, pp.\ 35181--35224. PMLR, 2024
work page 2024
-
[44]
Tree of attacks: Jailbreaking black-box llms automatically
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box llms automatically. Advances in Neural Information Processing Systems, 37: 0 61065--61105, 2024
work page 2024
-
[45]
Distributional preference alignment of llms via optimal transport
Igor Melnyk, Youssef Mroueh, Brian Belgodere, Mattia Rigotti, Apoorva Nitsure, Mikhail Yurochkin, Kristjan Greenewald, Jiri Navratil, and Jarret Ross. Distributional preference alignment of llms via optimal transport. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[46]
Simpo: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward. Advances in Neural Information Processing Systems, 37: 0 124198--124235, 2024
work page 2024
-
[47]
Microsoft. Introducing Model Context Protocol (MCP) in Copilot Studio. https://tinyurl.com/CopilotMCP, 2025. "Accessed: 2025-03-20"
work page 2025
-
[48]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35: 0 27730--27744, 2022
work page 2022
-
[49]
Ignore Previous Prompt: Attack Techniques For Language Models
F \'a bio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[50]
ProtectAI. Model Card for distilroberta-base-rejection-v1. https://huggingface.co/protectai/distilroberta-base-rejection-v1, 2025. "Accessed: 2025-05-15"
work page 2025
-
[51]
Mcp safety audit: Llms with the model context protocol allow major security exploits
Brandon Radosevich and John Halloran. Mcp safety audit: Llms with the model context protocol allow major security exploits. arXiv preprint arXiv:2504.03767, 2025
-
[52]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36: 0 53728--53741, 2023
work page 2023
-
[53]
Philipp Schmid. How to use Anthropic MCP Server with open LLMs, OpenAI or Google Gemini. https://github.com/philschmid/mcp-openai-gemini-llama-example, 2025. "Accessed: 2025-04-28"
work page 2025
-
[54]
Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, Jorrit Kruthoff, Scott Goodfriend, Euan Ong, Alwin Peng, Raj Agarwal, Cem Anil, et al. Constitutional classifiers: Defending against universal jailbreaks across thousands of hours of red teaming. arXiv preprint arXiv:2501.18837, 2025
-
[55]
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. " do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pp.\ 1671--1685, 2024
work page 2024
-
[56]
Maojia Song, Shang Hong Sim, Rishabh Bhardwaj, Hai Leong Chieu, Navonil Majumder, and Soujanya Poria. Measuring and enhancing trustworthiness of LLM s in RAG through grounded attributions and learning to refuse. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=Iyrtb9EJBp
work page 2025
-
[57]
Stripe. Stripe Agent Toolkit. https://github.com/stripe/agent-toolkit, 2025. "Accessed: 2025-03-20"
work page 2025
-
[58]
Divide-then-align: Honest alignment based on the knowledge boundary of RAG
Xin Sun, Jianan Xie, Zhongqi Chen, Qiang Liu, Shu Wu, Yuehe Chen, Bowen Song, Zilei Wang, Weiqiang Wang, and Liang Wang. Divide-then-align: Honest alignment based on the knowledge boundary of RAG . In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computatio...
-
[59]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
Fine-tuning language models for factuality
Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D Manning, and Chelsea Finn. Fine-tuning language models for factuality. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=WPZ2yPag4K
work page 2024
-
[61]
arXiv preprint arXiv:2310.16944 , year=
Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Cl \'e mentine Fourrier, Nathan Habib, et al. Zephyr: Direct distillation of lm alignment. arXiv preprint arXiv:2310.16944, 2023
-
[62]
PA - RAG : RAG alignment via multi-perspective preference optimization
Jiayi Wu, Hengyi Cai, Lingyong Yan, Hao Sun, Xiang Li, Shuaiqiang Wang, Dawei Yin, and Ming Gao. PA - RAG : RAG alignment via multi-perspective preference optimization. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.), Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Languag...
-
[63]
Self-play preference optimization for language model alignment
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, and Quanquan Gu. Self-play preference optimization for language model alignment. In Adaptive Foundation Models: Evolving AI for Personalized and Efficient Learning, 2024
work page 2024
-
[64]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
arXiv preprint arXiv:2305.13534 , year=
Muru Zhang, Ofir Press, William Merrill, Alisa Liu, and Noah A Smith. How language model hallucinations can snowball. arXiv preprint arXiv:2305.13534, 2023
-
[66]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36: 0 46595--46623, 2023
work page 2023
-
[67]
Dpo meets ppo: Reinforced token optimization for rlhf.arXiv preprint arXiv:2404.18922,
Han Zhong, Zikang Shan, Guhao Feng, Wei Xiong, Xinle Cheng, Li Zhao, Di He, Jiang Bian, and Liwei Wang. Dpo meets ppo: Reinforced token optimization for rlhf. arXiv preprint arXiv:2404.18922, 2024
-
[68]
DPO meets PPO : Reinforced token optimization for RLHF
Han Zhong, Zikang Shan, Guhao Feng, Wei Xiong, Xinle Cheng, Li Zhao, Di He, Jiang Bian, and Liwei Wang. DPO meets PPO : Reinforced token optimization for RLHF . In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=IfWKVF6LfY
work page 2025
-
[69]
Lima: Less is more for alignment
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment. Advances in Neural Information Processing Systems, 36: 0 55006--55021, 2023
work page 2023
-
[70]
Mingye Zhu. OPAD. https://github.com/stevie1023/OPAD, 2025. "Accessed: 2025-07-01"
work page 2025
-
[71]
On-the-fly preference alignment via principle-guided decoding
Mingye Zhu, Yi Liu, Lei Zhang, Junbo Guo, and Zhendong Mao. On-the-fly preference alignment via principle-guided decoding. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[72]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.