Recognition: 2 theorem links
· Lean TheoremDo Vision-Language-Models show human-like logical problem-solving capability in point and click puzzle games?
Pith reviewed 2026-05-13 01:55 UTC · model grok-4.3
The pith
Vision-language models plan solutions to physics puzzles but cannot execute the precise mouse clicks needed to finish them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Large proprietary vision-language models demonstrate superior planning abilities in the VLATIM benchmark yet struggle with precise visual grounding and continuous mouse interactions required for full puzzle solutions, leading to the conclusion that they do not yet exhibit human-like logical problem-solving capabilities.
What carries the argument
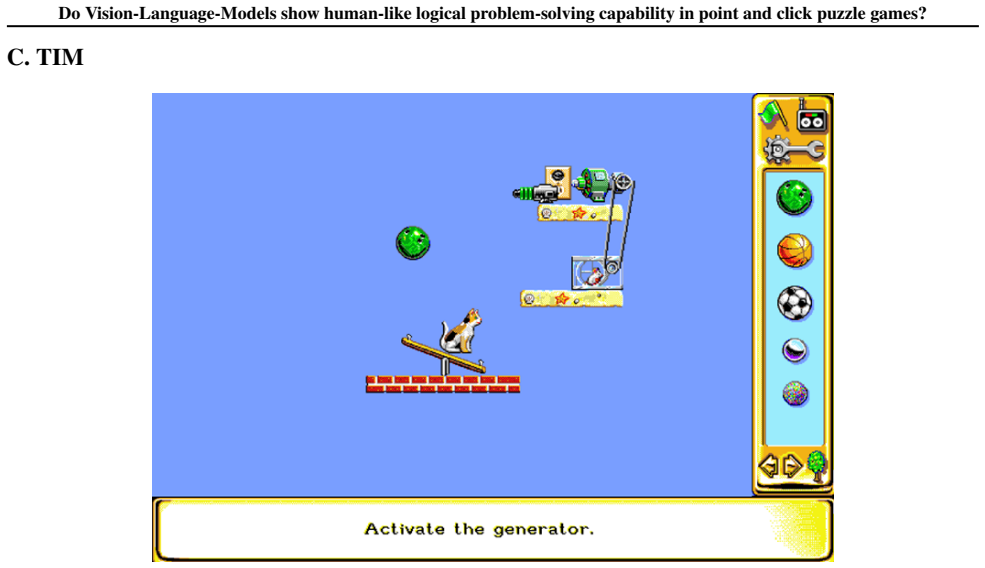
The VLATIM benchmark, a five-part progressive evaluation that measures the gap between high-level logical reasoning and precise execution in point-and-click physics puzzles.
Load-bearing premise
That failure to perform precise mouse interactions in this game benchmark means the models lack human-like logical problem-solving capability overall.
What would settle it
A model that completes the full set of VLATIM puzzles at or above typical human success rates would show the central claim is not correct.
Figures




read the original abstract
Vision-Language(-Action) Models (VLMs) are increasingly applied to interactive environments, yet existing benchmarks often overlook the complex physical reasoning required for point-and-click puzzle games. This paper introduces Vision-Language Against The Incredible Machine (VLATIM), a benchmark designed to evaluate human-like logical problem-solving capabilities within the classic physics puzzle game The Incredible Machine 2 (TIM). Unlike existing benchmarks, VLATIM specifically targets the critical gap between high-level logical reasoning and continuous action spaces requiring precise mouse interactions. This benchmark is structured into five progressive parts, assessing capabilities that range from basic visual grounding and domain understanding to multi-step manipulation and full puzzle solving. Our results reveal a significant disparity between reasoning and execution. While large proprietary models demonstrate superior planning abilities, they struggle with precise visual grounding. Consequently, they do not yet show human-like problem-solving capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the VLATIM benchmark, built on The Incredible Machine 2, to evaluate vision-language models on point-and-click physics puzzles. It structures evaluation into five progressive parts that isolate visual grounding, domain understanding, multi-step planning, and full puzzle solving. Experiments on proprietary and open VLMs show strong high-level planning but weak performance on precise mouse-based grounding and execution, supporting the conclusion that current models lack human-like logical problem-solving in continuous-action settings.
Significance. If the reported planning-execution disparity is robust, the work provides a useful diagnostic benchmark that separates reasoning from low-level control, a distinction often collapsed in existing VLM game benchmarks. The progressive design and focus on precise continuous actions could help prioritize research on grounding and action interfaces, with potential relevance to embodied agents.
major comments (2)
- [Results / §5] The central claim that models 'do not yet show human-like problem-solving capabilities' rests on the observed planning-grounding gap, yet no human performance baselines or inter-rater agreement on the VLATIM tasks are reported. Without these (e.g., in the results section or Table X), it is unclear whether the models' grounding failures exceed typical human variance or simply reflect the benchmark's difficulty.
- [Benchmark definition] §3.2–3.4: The scoring protocol for 'precise visual grounding' and mouse-click success (pixel tolerance, timeout rules, partial-credit criteria) is not fully specified. This detail is load-bearing because small interface or rendering differences could inflate the reported execution failures independently of model capability.
minor comments (2)
- [Abstract] Abstract: Key quantitative results (e.g., success rates per part, model names, exact deltas between planning and execution) are omitted; adding one or two headline numbers would improve readability.
- [§3] Notation: 'VLATIM' and the five-part naming are introduced without an explicit table or figure summarizing the progression; a compact overview table would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on VLATIM. The comments highlight important areas for strengthening the claims and ensuring reproducibility. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Results / §5] The central claim that models 'do not yet show human-like problem-solving capabilities' rests on the observed planning-grounding gap, yet no human performance baselines or inter-rater agreement on the VLATIM tasks are reported. Without these (e.g., in the results section or Table X), it is unclear whether the models' grounding failures exceed typical human variance or simply reflect the benchmark's difficulty.
Authors: We agree that human performance baselines and inter-rater agreement would provide essential context for interpreting whether the observed grounding failures exceed typical human variance. Our experiments demonstrate a consistent planning-execution disparity across multiple VLMs using the progressive task structure, but without direct human data the 'human-like' claim remains partly inferential. In the revision we will collect and report human baselines on the VLATIM tasks (including inter-rater agreement) and add a new table comparing model versus human performance to support the conclusion more rigorously. revision: yes
-
Referee: [Benchmark definition] §3.2–3.4: The scoring protocol for 'precise visual grounding' and mouse-click success (pixel tolerance, timeout rules, partial-credit criteria) is not fully specified. This detail is load-bearing because small interface or rendering differences could inflate the reported execution failures independently of model capability.
Authors: We apologize for the incomplete specification in the submitted version. The scoring rules are defined in §3 but lack the precise numerical thresholds needed for full reproducibility. We will expand §3.4 with an explicit protocol: click success requires the mouse position to be within a 15-pixel radius of the target center, actions are timed out after 45 seconds, and partial credit is awarded proportionally to proximity (0–100% based on distance) plus correctness of the chosen object. We will also include pseudocode and example screenshots to eliminate ambiguity from rendering or interface variations. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces the VLATIM benchmark with five progressive parts to isolate visual grounding, domain understanding, manipulation, and full puzzle solving in The Incredible Machine 2. It evaluates existing VLMs on this benchmark and reports empirical performance gaps between planning and precise execution. No equations, parameter fitting, self-definitional reductions, or load-bearing self-citations appear in the derivation. The central claim follows directly from benchmark results without renaming known patterns or smuggling ansatzes via prior work. The evaluation is self-contained and externally falsifiable against model outputs on the new tasks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLATIM benchmark tasks measure human-like logical problem-solving capability
invented entities (1)
-
VLATIM benchmark
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VLATIM benchmark structured into five progressive parts... models demonstrate superior planning abilities, they struggle with precise visual grounding.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Action space consists of five actions... click, hover, drag, wait, finished
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2025 , note =. doi:10.48550/arXiv.2509.13347 , author =
-
[3]
2025 , note =. doi:10.48550/arXiv.2505.18134 , author =
-
[4]
doi:10.48550/arXiv.2407.00114 , author =
2024 , note =. doi:10.48550/arXiv.2407.00114 , author =
-
[5]
JARVIS-1: Open- world multi-task agents with memory-augmented multimodal lan- guage models,
2023 , note =. doi:10.48550/arXiv.2311.05997 , author =
-
[6]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager:. 2023 , note =. doi:10.48550/arXiv.2305.16291 , author =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.16291 2023
-
[7]
Describe,. 2024 , note =. doi:10.48550/arXiv.2302.01560 , author =
-
[8]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
2025 , note =. doi:10.48550/arXiv.2506.01844 , author =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.01844 2025
-
[9]
OpenVLA: An Open-Source Vision-Language-Action Model
2024 , note =. doi:10.48550/arXiv.2406.09246 , author =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.09246 2024
-
[10]
2025 , note =. doi:10.48550/arXiv.2503.16365 , author =
-
[11]
doi:10.48550/arXiv.2401.10568 , author =
2024 , note =. doi:10.48550/arXiv.2401.10568 , author =
-
[12]
Puzzle. 2024 , note =. doi:10.48550/arXiv.2402.11291 , author =
-
[13]
doi:10.48550/arXiv.1907.13440 , author =
2019 , note =. doi:10.48550/arXiv.1907.13440 , author =
-
[14]
Wang, Xinyu and Zhuang, Bohan and Wu, Qi , month = oct, year =. Are
-
[15]
doi:10.48550/arXiv.2503.09527 , author =
2025 , note =. doi:10.48550/arXiv.2503.09527 , author =
-
[16]
Vla-0: Building state-of-the-art vlas with zero modification.arXiv preprint arXiv:2510.13054, 2025
2025 , note =. doi:10.48550/arXiv.2510.13054 , author =
-
[17]
Minedojo: Building open-ended embodied agents with internet-scale knowledge, 2022
2022 , note =. doi:10.48550/arXiv.2206.08853 , author =
-
[18]
doi:10.48550/arXiv.2508.03700 , author =
2025 , note =. doi:10.48550/arXiv.2508.03700 , author =
-
[19]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
2025 , note =. doi:10.48550/arXiv.2501.12326 , author =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12326 2025
-
[20]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
2025 , note =. doi:10.48550/arXiv.2509.02544 , author =
work page internal anchor Pith review doi:10.48550/arxiv.2509.02544 2025
-
[21]
doi:10.48550/arXiv.2411.17465 , author =
2024 , note =. doi:10.48550/arXiv.2411.17465 , author =
-
[22]
Wikipedia , month = oct, year =
-
[23]
arXiv preprint arXiv:2411.13543 , year=
2025 , note =. doi:10.48550/arXiv.2411.13543 , author =
-
[24]
2025 , note =. doi:10.48550/arXiv.2502.03214 , author =
-
[25]
Benchmarking. 2025 , note =. doi:10.48550/arXiv.2505.05540 , author =
-
[26]
Gemini 2.5:. 2025 , note =. doi:10.48550/arXiv.2507.06261 , author =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.06261 2025
-
[27]
Qwen3-. 2025 , note =. doi:10.48550/arXiv.2511.21631 , author =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[28]
Ferret-. 2025 , note =. doi:10.48550/arXiv.2410.18967 , author =
-
[29]
2025 , note =. doi:10.48550/arXiv.2503.23064 , author =
-
[30]
Qwen2.5. 2025 , note =. doi:10.48550/arXiv.2412.15115 , author =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2025
-
[31]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Vla-0: Building state-of-the-art vlas with zero modification.arXiv preprint arXiv:2510.13054, 2025
Goyal, A., Hadfield, H., Yang, X., Blukis, V., and Ramos, F. VLA -0: Building State -of-the- Art VLAs with Zero Modification , October 2025. URL http://arxiv.org/abs/2510.13054. arXiv:2510.13054 [cs]
-
[33]
ABot-Claw: A Foundation for Persistent, Cooperative, and Self-Evolving Robotic Agents
Huo, D., Liu, H., Liu, G., Qi, D., Sun, Z., Gao, M., He, J., Yang, Y., Chang, X., Xiong, F., Wei, X., Ma, Z., and Xu, M. ABot-Claw : A Foundation for Persistent , Cooperative , and Self-Evolving Robotic Agents , 2026. URL https://arxiv.org/abs/2604.10096
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Li, M., Wang, Z., He, K., Ma, X., and Liang, Y. JARVIS - VLA : Post - Training Large - Scale Vision Language Models to Play Visual Games with Keyboards and Mouse , September 2025. URL http://arxiv.org/abs/2503.16365. arXiv:2503.16365 [cs]
-
[35]
Mayer, J., Ballout, M., Jassim, S., Nezami, F. N., and Bruni, E. iVISPAR -- An Interactive Visual - Spatial Reasoning Benchmark for VLMs , February 2025. URL http://arxiv.org/abs/2502.03214. arXiv:2502.03214 [cs]
-
[36]
arXiv preprint arXiv:2411.13543 , year=
Paglieri, D., Cupia , B., Coward, S., Piterbarg, U., Wolczyk, M., Khan, A., Pignatelli, E., Kuci \'n ski, ., Pinto, L., Fergus, R., Foerster, J. N., Parker-Holder, J., and Rockt \"a schel, T. BALROG : Benchmarking Agentic LLM and VLM Reasoning On Games , April 2025. URL http://arxiv.org/abs/2411.13543. arXiv:2411.13543 [cs]
-
[37]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Qin, Y., Ye, Y., Fang, J., Wang, H., Liang, S., Tian, S., Zhang, J., Li, J., Li, Y., Huang, S., Zhong, W., Li, K., Yang, J., Miao, Y., Lin, W., Liu, L., Jiang, X., Ma, Q., Li, J., Xiao, X., Cai, K., Li, C., Zheng, Y., Jin, C., Li, C., Zhou, X., Wang, M., Chen, H., Li, Z., Yang, H., Liu, H., Lin, F., Peng, T., Liu, X., and Shi, G. UI - TARS : Pioneering Au...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Qwen, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, Y., Wan, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Ren, Y., Tertikas, K., Maiti, S., Han, J., Zhang, T., S \"u sstrunk, S., and Kokkinos, F. VGRP - Bench : Visual Grid Reasoning Puzzle Benchmark for Large Vision - Language Models , April 2025. URL http://arxiv.org/abs/2503.23064. arXiv:2503.23064 [cs]
-
[40]
Zhang, A. L., Griffiths, T. L., Narasimhan, K. R., and Press, O. VideoGameBench : Can Vision - Language Models complete popular video games?, May 2025. URL http://arxiv.org/abs/2505.18134. arXiv:2505.18134 [cs]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.