Recognition: no theorem link
RETUYT-INCO at BEA 2026 Shared Task 2: Meta-prompting in Rubric-based Scoring for German
Pith reviewed 2026-05-13 01:51 UTC · model grok-4.3
The pith
Meta-prompting lets an LLM generate custom prompts from training examples to score German short student answers using rubrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
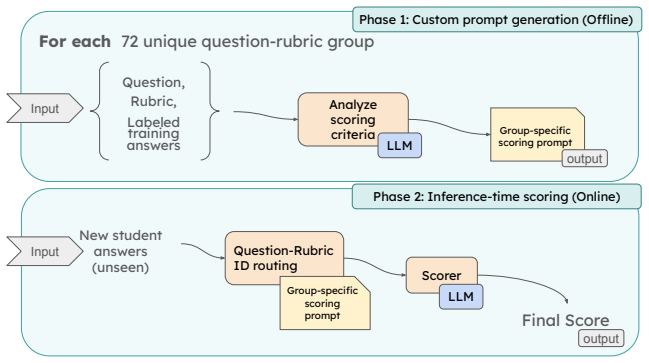
We created a method called Meta-prompting in which an LLM creates a custom prompt based on examples from the Train set, and this prompt is then used to grade new student answers, resulting in QWK scores of 0.729, 0.674, and 0.49 across the three tracks.
What carries the argument
Meta-prompting, a process where an LLM generates a customized grading prompt from a set of training examples for applying rubrics to new answers.
Load-bearing premise
That the large language model can reliably produce effective custom prompts from the available training examples that generalize to new answers and questions.
What would settle it
If applying the meta-generated prompt to a new batch of student answers yields lower agreement with human scores than a carefully hand-crafted fixed prompt does.
Figures
read the original abstract
In this paper, we present the RETUYT-INCO participation at the BEA 2026 shared task "Rubric-based Short Answer Scoring for German". Our team participated in track 1 (Unseen answers three-way), track 3 (Unseen answers two-way) and track 4 (Unseen questions two-way). Since these tracks required scoring short student answers using specific rubrics, we looked for ways to handle the changing nature of the task. We created a method called Meta-prompting. In this approach, an LLM creates a custom prompt based on examples from the Train set. This prompt is then used to grade new student answers. Along with this method, we also describe other approaches we used, such as classic machine learning, fine-tuning open-source LLMs, and different prompting techniques. According to the official results, our team placed 6th out of 8 participants in Track 1 with a QWK of 0.729. In Track 3, we secured 4th place out of 9 with a QWK of 0.674, and we also placed 4th out of 8 in Track 4 with a QWK of 0.49.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports the RETUYT-INCO team's participation in the BEA 2026 shared task on Rubric-based Short Answer Scoring for German. It introduces a meta-prompting method in which an LLM generates custom prompts from training-set examples, which are then applied to score new student answers, and describes additional baselines including classical ML and fine-tuning. Official QWK scores and mid-pack rankings are presented for tracks 1 (0.729, 6/8), 3 (0.674, 4/9), and 4 (0.49, 4/8).
Significance. If the meta-prompting procedure can be shown to generalize reliably, it would provide a practical, low-tuning approach to rubric-based scoring that adapts to unseen answers or questions. The reported results are consistent with other mid-tier shared-task entries but do not yet demonstrate clear advantages over simpler prompting or fine-tuning baselines.
major comments (2)
- [Abstract / Method] Abstract and Method section: the central claim that meta-prompting effectively handles the changing nature of the task rests on the LLM's ability to produce high-quality custom prompts from limited training examples, yet no details are given on the meta-prompt template, number of examples used, or any filtering of generated prompts; without these, the reported QWK scores cannot be attributed specifically to the meta-prompting component.
- [Results] Results section: official QWK scores and rankings are provided, but the manuscript contains no error analysis, per-question breakdown, or ablation comparing meta-prompting against the authors' own classical ML and fine-tuning baselines; this absence leaves the effectiveness claim only partially supported.
minor comments (1)
- [Abstract] The abstract states participation in Track 2 but the results only report Tracks 1, 3, and 4; clarify whether Track 2 was attempted and, if not, why it was omitted.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to provide the requested details and analyses.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and Method section: the central claim that meta-prompting effectively handles the changing nature of the task rests on the LLM's ability to produce high-quality custom prompts from limited training examples, yet no details are given on the meta-prompt template, number of examples used, or any filtering of generated prompts; without these, the reported QWK scores cannot be attributed specifically to the meta-prompting component.
Authors: We agree that additional methodological details are required for proper attribution. In the revised manuscript we will expand the Method section to include the complete meta-prompt template, the exact number of training examples supplied to the LLM for custom prompt generation, and any filtering or selection steps applied to the generated prompts. These additions will allow readers to evaluate the contribution of the meta-prompting component more precisely. revision: yes
-
Referee: [Results] Results section: official QWK scores and rankings are provided, but the manuscript contains no error analysis, per-question breakdown, or ablation comparing meta-prompting against the authors' own classical ML and fine-tuning baselines; this absence leaves the effectiveness claim only partially supported.
Authors: We acknowledge the absence of error analysis and ablations in the submitted version. Although classical ML and fine-tuning baselines were implemented, a systematic comparison was not reported. In the revision we will add an error analysis section with representative mis-scored examples and include a development-set ablation table comparing meta-prompting QWK scores against our other approaches. Because official results are test-set only, we will clearly distinguish development-set comparisons and note any limitations in generalizability. revision: partial
Circularity Check
No significant circularity; purely empirical shared-task report
full rationale
The paper describes participation in a BEA 2026 shared task on rubric-based short answer scoring. It introduces a meta-prompting procedure (LLM-generated custom prompts from training examples) alongside baselines like fine-tuning and classic ML, then reports official QWK scores and mid-pack rankings on held-out test sets for tracks 1, 3, and 4. No derivations, equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear. All performance claims are externally validated by the shared-task organizers' evaluation, making the work self-contained against independent benchmarks with no load-bearing steps that reduce to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Luis Chiruzzo, Laura Musto, Santiago Gongora, Brian Carpenter, Juan Filevich, and Aiala Rosa
The Eras and Trends of Automatic Short An- swer Grading.International Journal of Artificial Intelligence in Education, 25(1):60–117. Luis Chiruzzo, Laura Musto, Santiago Gongora, Brian Carpenter, Juan Filevich, and Aiala Rosa. 2022. Us- ing NLP to support English teaching in rural schools. InProceedings of the Second Workshop on NLP for Positive Impact (N...
work page 2022
-
[2]
SemEval-2013 task 7: The joint student re- sponse analysis and 8th recognizing textual entail- ment challenge. InSecond Joint Conference on Lexi- cal and Computational Semantics (*SEM), Volume 2: Proceedings of the Seventh International Work- shop on Semantic Evaluation (SemEval 2013), pages 263–274, Atlanta, Georgia, USA. Association for Computational Li...
work page 2013
-
[3]
Report on the bea 2026 shared task on rubric- based short answer scoring for german. InProceed- ings of the 21st Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2026). Association for Computational Linguistics. Santiago Góngora, Ignacio Sastre, Santiago Robaina, Ignacio Remersaro, Luis Chiruzzo, and Aiala Rosá
work page 2026
-
[4]
RETUYT-INCO at BEA 2025 shared task: How far can lightweight models go in AI-powered tu- tor evaluation? InProceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025), pages 1135–1144, Vienna, Austria. Association for Computational Linguistics. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pande...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Read the question, the student answer, and all rubric levels.,→
-
[6]
Identify the full set of meaning requirements for the rubric label "Correct". ,→ ,→
-
[7]
Use the question only as context to interpret the student's wording.,→
-
[8]
Do not use outside knowledge to add content that is not stated or clearly implied by the student's answer. ,→ ,→
- [9]
-
[10]
Output "Correct" only if all requirements for a fully correct answer are present and unambiguous. ,→ ,→
- [11]
-
[12]
If the rubric allows multiple alternative ways to be fully correct, any one complete valid alternative is sufficient. ,→ ,→
-
[13]
Ignore spelling and grammar errors unless they make the meaning unclear.,→
-
[14]
Ignore extra details unless they contradict the required content or make the answer incompatible with the rubric. ,→ ,→
-
[15]
For multi-part requirements, all required parts must be present unless the rubric explicitly states otherwise. ,→ ,→
-
[16]
The question, answer, and rubric may be in German
Do not output any explanation. The question, answer, and rubric may be in German. Score based on meaning, not language quality. ,→ ,→ Input: <Question> {question} </Question> <StudentAnswer> {answer_to_classify} </StudentAnswer> <Rubric> <Incorrect> {rubric_incorrect} </Incorrect> <PartiallyCorrect> {rubric_partially_correct} </PartiallyCorrect> <Correct>...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.