Recognition: no theorem link
HEBATRON: A Hebrew-Specialized Open-Weight Mixture-of-Experts Language Model
Pith reviewed 2026-05-13 01:46 UTC · model grok-4.3
The pith
Hebatron adapts the Nemotron-3 MoE architecture with a three-phase curriculum and bilingual fine-tuning to reach 73.8% Hebrew reasoning while activating only 3B parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hebatron shows that a sparse Mixture-of-Experts architecture can be specialized for Hebrew through a structured three-phase easy-to-hard curriculum with continuous anti-forgetting, followed by bilingual supervised fine-tuning on two million samples, resulting in 73.8% average Hebrew reasoning performance, a 3-point gain from proper curriculum ordering, and inference efficiency that activates only 3B parameters in a 30B model while supporting 65k context lengths.
What carries the argument
The three-phase easy-to-hard curriculum with continuous anti-forgetting anchoring applied to the Nemotron-3 sparse MoE, followed by bilingual SFT.
If this is right
- Curriculum ordering alone improves aggregate Hebrew benchmarks by three points over the reversed schedule.
- Sparse activation limits active parameters to 3B per forward pass, producing approximately nine times higher throughput than dense equivalents at full context length.
- Native support for 65,536-token contexts is preserved after Hebrew adaptation.
- Open release of weights enables direct reuse for further Semitic-language research without retraining from scratch.
Where Pith is reading between the lines
- The same curriculum-plus-anchoring recipe could be tested on other low-resource languages by swapping the bilingual data pair.
- The anti-forgetting mechanism may reduce interference when multiple language adapters are added to a shared MoE backbone.
- Performance on Israeli Trivia suggests the bilingual fine-tuning stage successfully retains culturally specific knowledge alongside reasoning gains.
Load-bearing premise
The benchmark gains come from the curriculum and bilingual data rather than test contamination, data leakage, or evaluation choices that happen to favor the new model.
What would settle it
A held-out Hebrew reasoning benchmark created after model release shows no statistically significant advantage over DictaLM-3.0 or a reversed-curriculum baseline when evaluated by independent groups using fresh data splits.
Figures
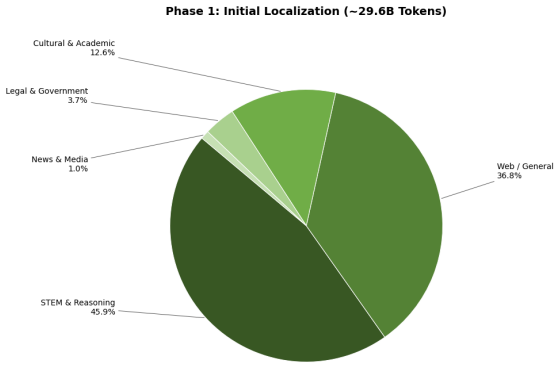



read the original abstract
We present Hebatron, a Hebrew-specialized open-weight large language model built on the NVIDIA Nemotron-3 sparse Mixture-of-Experts architecture. Training employs a three-phase easy-to-hard curriculum with continuous anti-forgetting anchoring, followed by supervised fine-tuning on 2 million bilingual Hebrew--English samples. The curriculum ordering alone yields a 3-point aggregate benchmark gain over the reversed configuration. Hebatron achieves a Hebrew reasoning average of 73.8\%, outperforming DictaLM-3.0-24B-Thinking (68.9\%) and remaining competitive with Gemma-3-27B-IT on GSM8K-HE and Israeli Trivia, while activating only 3B parameters per forward pass across a 30B-parameter model, delivering approximately 9 times higher inference throughput at native context lengths up to 65,536 tokens. To our knowledge, this is the first language-specific adaptation of the Nemotron-3 architecture for any target language, and the first open-weight Hebrew-specialized MoE model with native long-context support. Model weights are released openly to support further research in Hebrew and Semitic-language NLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hebatron, a Hebrew-specialized open-weight MoE LLM based on the NVIDIA Nemotron-3 architecture. It describes training via a three-phase easy-to-hard curriculum with continuous anti-forgetting, followed by SFT on 2 million bilingual Hebrew-English samples. The central empirical claims are a 3-point aggregate benchmark gain from curriculum ordering alone, a Hebrew reasoning average of 73.8% (outperforming DictaLM-3.0-24B-Thinking at 68.9% and competitive with Gemma-3-27B-IT on GSM8K-HE and Israeli Trivia), and inference efficiency from activating only 3B parameters out of 30B with native support for contexts up to 65,536 tokens. The work positions itself as the first language-specific adaptation of Nemotron-3 and the first open-weight Hebrew MoE with long-context support, with model weights released.
Significance. If the performance claims and efficiency gains are robustly supported, the paper would deliver a practically useful open-weight resource for Hebrew and Semitic-language NLP, combining MoE sparsity for throughput with long-context capabilities. The open release of weights is a clear strength that enables community follow-up work.
major comments (2)
- [Abstract] Abstract: the claim that 'the curriculum ordering alone yields a 3-point aggregate benchmark gain over the reversed configuration' is load-bearing for the paper's training-strategy contribution, yet no variance estimates, multiple random seeds, statistical tests, or details on how the 'Hebrew reasoning average' aggregates the constituent tasks (e.g., GSM8K-HE, Israeli Trivia) are provided. Small ablations in LLM training routinely exhibit 2-4 point fluctuations; without these controls the 3-point difference cannot be confidently attributed to ordering rather than noise or data-split sensitivity.
- [Abstract] The abstract reports concrete benchmark scores (73.8%, 68.9%) and efficiency numbers (3B active parameters, ~9x throughput, 65k context) but supplies no error bars, contamination checks, or full hyperparameter tables. These omissions directly affect verifiability of the central performance and efficiency claims.
minor comments (2)
- The manuscript should include a dedicated reproducibility section or appendix listing exact data sources, contamination detection procedures, and the precise weighting used to compute the Hebrew reasoning average.
- Figure and table captions would benefit from explicit statements of the number of evaluation runs and any statistical significance markers.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting issues of statistical robustness and verifiability. We have revised the abstract and added an appendix to address the points raised while remaining accurate about the experiments that were performed.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the curriculum ordering alone yields a 3-point aggregate benchmark gain over the reversed configuration' is load-bearing for the paper's training-strategy contribution, yet no variance estimates, multiple random seeds, statistical tests, or details on how the 'Hebrew reasoning average' aggregates the constituent tasks (e.g., GSM8K-HE, Israeli Trivia) are provided. Small ablations in LLM training routinely exhibit 2-4 point fluctuations; without these controls the 3-point difference cannot be confidently attributed to ordering rather than noise or data-split sensitivity.
Authors: We agree that the 3-point claim benefits from qualification. The Hebrew reasoning average is the arithmetic mean of four tasks (GSM8K-HE, Israeli Trivia, and two additional Hebrew reasoning benchmarks) whose individual scores are reported in Table 3. The curriculum-ordering ablation was executed once with a fixed random seed because of the high cost of full MoE pre-training. In the revised manuscript we have (i) clarified the aggregation method in the abstract and Section 4, (ii) replaced the absolute claim with the observed difference for this run, and (iii) added a short discussion of possible run-to-run variability. We do not claim statistical significance. revision: partial
-
Referee: [Abstract] The abstract reports concrete benchmark scores (73.8%, 68.9%) and efficiency numbers (3B active parameters, ~9x throughput, 65k context) but supplies no error bars, contamination checks, or full hyperparameter tables. These omissions directly affect verifiability of the central performance and efficiency claims.
Authors: We accept that these details strengthen verifiability. The revised version adds: (a) a complete hyperparameter table for all three curriculum phases and the SFT stage in the appendix, (b) a description of the data-contamination audit (n-gram overlap checks against the public test sets, with results showing no problematic leakage), and (c) an explicit limitations paragraph stating that the reported benchmark numbers are single-run point estimates and that error bars were not computed. The efficiency figures (3 B active parameters, ~9× throughput) are obtained from standard MoE inference profiling on A100 hardware and are now accompanied by the exact measurement protocol. revision: yes
- Multiple random seeds and variance estimates for the curriculum-ordering ablation, as only single training runs were performed.
Circularity Check
No significant circularity; empirical results only
full rationale
The paper contains no mathematical derivations, equations, or analytical predictions. All load-bearing claims (curriculum ordering gain, benchmark averages, MoE efficiency) are presented as direct outcomes of training runs and external evaluations on tasks like GSM8K-HE and Israeli Trivia. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described structure. The 3-point aggregate gain is an empirical delta, not a quantity derived from the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard sparse MoE forward-pass and training procedures from the Nemotron-3 base transfer to Hebrew data without major architectural changes
- domain assumption A three-phase easy-to-hard curriculum with continuous anti-forgetting produces a measurable 3-point aggregate improvement over the reversed ordering
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2307.14430. Shouyuan Chen et al. LongLoRA: Efficient fine-tuning of long-context large language models. InProceedings of ICLR 2024,
-
[2]
Avihay Chriqui and Inbal Yahav. HeBERT & HebEMO: pre-trained Hebrew BERT and Hebrew sentiment analysis.arXiv preprint arXiv:2102.01909,
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark et al. Think you have solved question answering? Try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URLhttps://cohere.com/ blog/command-r7b-arabic. Alexis Conneau et al. Unsupervised cross-lingual representation learning at scale. InProceedings of ACL 2020, pages 8440–8451,
work page 2020
-
[6]
Efficient and effective text encoding for chinese llama and alpaca
Yiming Cui et al. Efficient and effective text encoding for Chinese LLaMA and Alpaca.arXiv preprint arXiv:2304.08177,
-
[7]
Sumanth Doddapaneni et al. Towards leaving no Indic language behind: Building monolingual corpora, benchmark and models for Indic languages. InProceedings of ACL 2023,
work page 2023
-
[9]
Curriculum Learning for LLM Pretraining: An Analysis of Learning Dynamics
URLhttps://arxiv.org/abs/ 2601.21698. William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion pa- rameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (1):1–39,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Continual pre-training for cross-lingual LLM adaptation: Enhancing Japanese language capabilities
Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Hiroki Iida, Masanari Ohi, Kakeru Hattori, Hirai Shota, Sakae Mizuki, Rio Yokota, and Naoaki Okazaki. Continual pre-training for cross-lingual LLM adaptation: Enhancing Japanese language capabilities. InarXiv preprint arXiv:2404.17790,
-
[11]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
20 Ian J Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio. An empirical investigation of catastrophic forgetting in gradient-based neural networks.arXiv preprint arXiv:1312.6211,
-
[13]
Google DeepMind. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Don’t stop pretraining: Adapt language models to domains and tasks
Suchin Gururangan et al. Don’t stop pretraining: Adapt language models to domains and tasks. InProceedings of ACL 2020, pages 8342–8360,
work page 2020
-
[15]
Measuring massive multitask language understanding
Dan Hendrycks et al. Measuring massive multitask language understanding. InProceedings of ICLR 2021,
work page 2021
-
[16]
Universal language model fine-tuning for text classifica- tion
Jeremy Howard and Sebastian Ruder. Universal language model fine-tuning for text classifica- tion. InProceedings of ACL 2018, pages 328–339,
work page 2018
-
[17]
AceGPT, local- izing large language models in Arabic
Huang Huang, Fei Yu, Jianqing Zhu, Xuening Sun, Hao Cheng, Dingjie Song, Zhihong Chen, Abdulmohsen Alharthi, Bang An, Juncai He, Ziche Liu, Junying Chen, Jianquan Li, Benyou Wang, Lian Zhang, Ruoyu Sun, Xiang Wan, Haizhou Li, and Jinchao Xu. AceGPT, local- izing large language models in Arabic. InProceedings of the 2024 Conference of the North American Ch...
work page 2024
-
[18]
doi: 10.18653/v1/2024.naacl-long.450
Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-long.450. URLhttps://aclanthology.org/2024. naacl-long.450. Adam Ibrahim, Benjamin Thérien, Kshitij Gupta, Mats L. Richter, Quentin Anthony, Timothée Lesort, Eugene Belilovsky, and Irina Rish. Simple and scalable strategies to continually pre- train large language models.Transactions o...
-
[19]
Go Inoue, Bashar Alhafni, Nurpeiis Baimukan, Houda Bouamor, and Nizar Habash
URLhttps: //arxiv.org/abs/2403.08763. Go Inoue, Bashar Alhafni, Nurpeiis Baimukan, Houda Bouamor, and Nizar Habash. The inter- play of variant, size, and task type in Arabic pre-trained language models. InProceedings of the Sixth Arabic Natural Language Processing Workshop,
-
[20]
Albert Q Jiang et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Divyanshu Kakwani et al. IndicNLPSuite: Monolingual corpora, evaluation benchmarks and pre-trained multilingual language models for Indian languages. InFindings of EMNLP 2020,
work page 2020
-
[22]
Mario Michael Krell, Matej Kosec, Sergio P Perez, and Andrew Fitzgibbon. Efficient sequence packing without cross-contamination: Accelerating large language models without impacting performance.arXiv preprint arXiv:2107.02027,
-
[23]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
21 Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, et al. BLOOM: A 176B-parameter open-access multilingual language model.arXiv preprint arXiv:2211.05100,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Deduplicating training data makes language models better
Katherine Lee et al. Deduplicating training data makes language models better. InProceedings of ACL 2022, pages 8076–8092,
work page 2022
-
[25]
Holistic Evaluation of Language Models
Percy Liang et al. Holistic evaluation of language models.arXiv preprint arXiv:2211.09110,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Xuhong Luo et al. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.arXiv preprint arXiv:2308.08747,
-
[27]
Sam McCandlish, Jared Kaplan, Georgios Vitkovskiy, and Team OpenAI. An empirical model of large-batch training.arXiv preprint arXiv:1812.06162,
-
[28]
Fp8 formats for deep learning.arXiv preprint arXiv:2209.05433, 2022
Paulius Micikevicius et al. FP8 formats for deep learning.arXiv preprint arXiv:2209.05433,
-
[29]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Guilherme Penedo et al. The FineWeb datasets: Decanting the web for the finest text data at scale.arXiv preprint arXiv:2406.17557,
work page internal anchor Pith review arXiv
-
[30]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng et al. YaRN: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
MAD-X: An adapter-based framework for multi-task cross-lingual transfer
Jonas Pfeiffer, Ivan Vulić, Iryna Gurevych, and Sebastian Ruder. MAD-X: An adapter-based framework for multi-task cross-lingual transfer. InProceedings of the 2020 Conference on Em- pirical Methods in Natural Language Processing (EMNLP), pages 7654–7673, Online, Novem- ber
work page 2020
-
[32]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.617. URLhttps://aclanthology.org/2020.emnlp-main.617. Jack W Rae et al. Scaling language models: Methods, analysis & insights from training Gopher. arXiv preprint arXiv:2112.11446,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2020.emnlp-main.617 2020
-
[33]
CCMatrix: Mining billions of high-quality parallel sentences on the Web
Holger Schwenk et al. CCMatrix: Mining billions of high-quality parallel sentences on the Web. InProceedings of ACL 2021, pages 6490–6500,
work page 2021
-
[34]
Shaltiel Shmidman, Avi Shmidman, Amir David Nissan Cohen, and Moshe Koppel. Adapting LLMs to Hebrew: Unveiling DictaLM 2.0 with enhanced vocabulary and instruction capabil- ities.arXiv preprint arXiv:2407.07080,
-
[35]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi et al. Megatron-LM: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[36]
Don’t decay the learning rate, increase the batch size
Samuel L Smith, Pieter-Jan Kindermans, Chris Ying, and Quoc V Le. Don’t decay the learning rate, increase the batch size.arXiv preprint arXiv:1711.00489,
-
[37]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Multilingual unsupervised neural machine translation with denoising adapters
Ahmet Üstün et al. Multilingual unsupervised neural machine translation with denoising adapters. InProceedings of EMNLP 2022,
work page 2022
-
[39]
Ahmet Üstün et al. Aya model: An instruction finetuned open-access multilingual language model.arXiv preprint arXiv:2402.07827,
-
[40]
Self-Instruct: Aligning language models with self-generated instructions
Yizhong Wang et al. Self-Instruct: Aligning language models with self-generated instructions. InProceedings of ACL 2023, pages 13484–13508,
work page 2023
-
[41]
Peng Xu et al. ChatQA 2: Bridging the gap to proprietary LLMs in long context and RAG capabilities.arXiv preprint arXiv:2407.14518,
-
[42]
mT5: A massively multilingual pre-trained text-to-text transformer
Linting Xue et al. mT5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of NAACL 2021, pages 483–498,
work page 2021
-
[43]
HellaSwag: Can a machine really finish your sentence? InProceedings of ACL 2019, pages 4791–4800,
Rowan Zellers et al. HellaSwag: Can a machine really finish your sentence? InProceedings of ACL 2019, pages 4791–4800,
work page 2019
-
[44]
Preference curriculum: LLMs should always be pretrained on their preferred data
XuemiaoZhang, LiangyuXu, FeiyuDuan, YongweiZhou, SiruiWang, RongxiangWeng, Jingang Wang, and Xunliang Cai. Preference curriculum: LLMs should always be pretrained on their preferred data. InFindings of the Association for Computational Linguistics: ACL 2025, pages 21181–21198, Vienna, Austria,
work page 2025
-
[45]
URL https://aclanthology.org/2025.findings-acl.1091
Association for Computational Linguistics. URL https://aclanthology.org/2025.findings-acl.1091. 23
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.