Recognition: 2 theorem links
· Lean TheoremSieve: Dynamic Expert-Aware PIM Acceleration for Evolving Mixture-of-Experts Models
Pith reviewed 2026-05-13 00:50 UTC · model grok-4.3
The pith
Sieve uses runtime monitoring of token-to-expert distributions to dynamically assign experts to GPU or attached PIM, cutting load imbalance in modern MoE models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
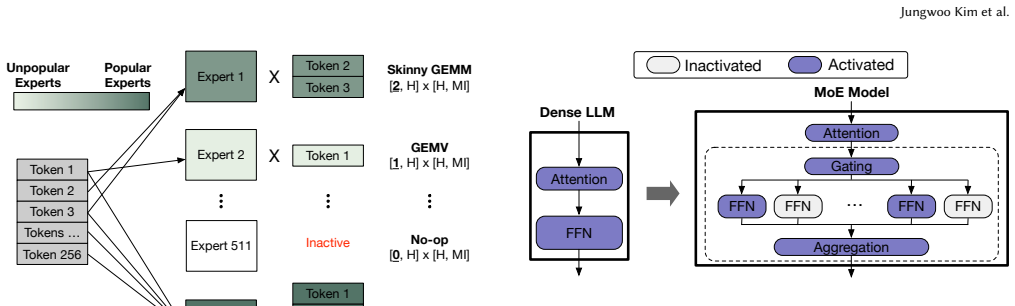
The central claim is that the emerging bimodal token-to-expert distribution in modern MoE models creates a disparity in arithmetic intensity that static PIM rules cannot exploit; a dynamic scheduler that partitions experts between GPU and PIM at runtime, while accounting for interconnect, bandwidth, and device throughputs, restores efficiency and enables overlapping of GPU work, PIM work, and cross-device communication.
What carries the argument
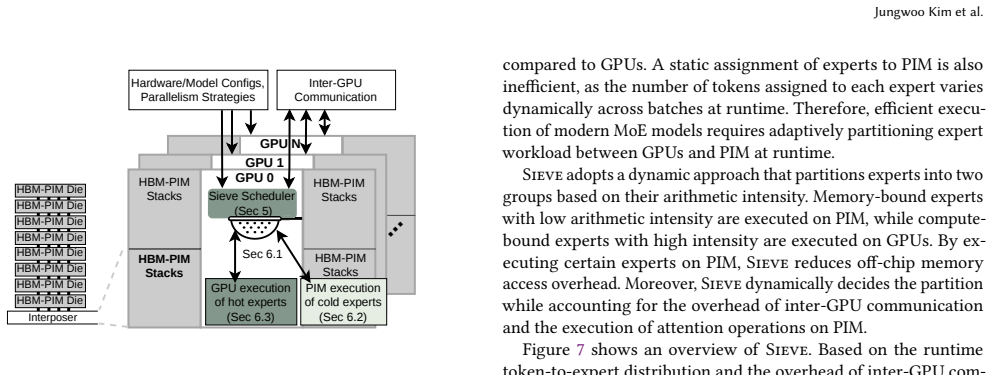
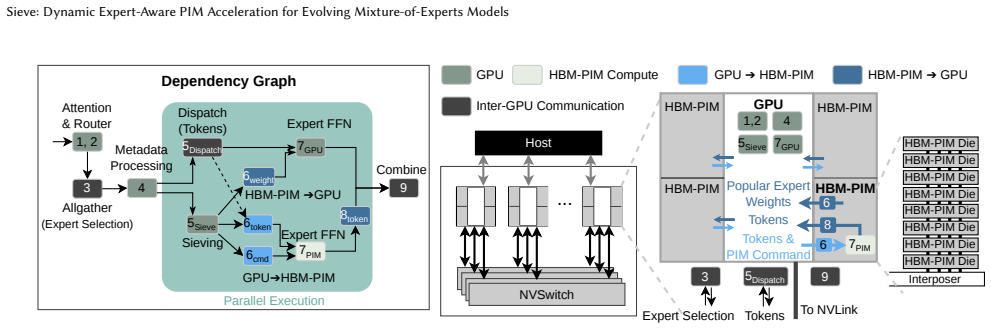
The runtime scheduler that partitions expert execution between GPU and PIM according to observed token-to-expert distributions while jointly considering interconnect overhead, memory bandwidth, GPU throughput, and PIM throughput.
If this is right
- Throughput and interactivity gains scale with the degree of bimodality in token-to-expert distributions.
- Overlapping GPU computation, PIM computation, and intra- and inter-device communication remains feasible while respecting expert-parallelism ordering constraints.
- The same monitoring-plus-joint-cost scheduler can be applied to other heterogeneous memory systems that combine high-bandwidth memory with attached compute.
- Performance remains stable as the number of experts grows and activation sparsity increases.
Where Pith is reading between the lines
- If monitoring latency proves higher on real silicon than in simulation, the framework may need to switch from per-batch to per-layer or per-request monitoring intervals.
- The same cost model could be reused to decide when to migrate experts between devices in a multi-node setting rather than only within a single node.
- Training pipelines could incorporate a lightweight version of the scheduler to produce MoE checkpoints that are already tuned for PIM-augmented inference hardware.
Load-bearing premise
The cycle-accurate simulator captures every relevant overhead of the dynamic scheduler and that the bimodal expert distributions observed in the evaluated models will continue in future MoE deployments.
What would settle it
Running the full Sieve scheduler on physical multi-GPU hardware with HBM-PIM stacks and measuring end-to-end latency against a static PIM baseline on a new MoE model whose expert activations are nearly uniform.
Figures






read the original abstract
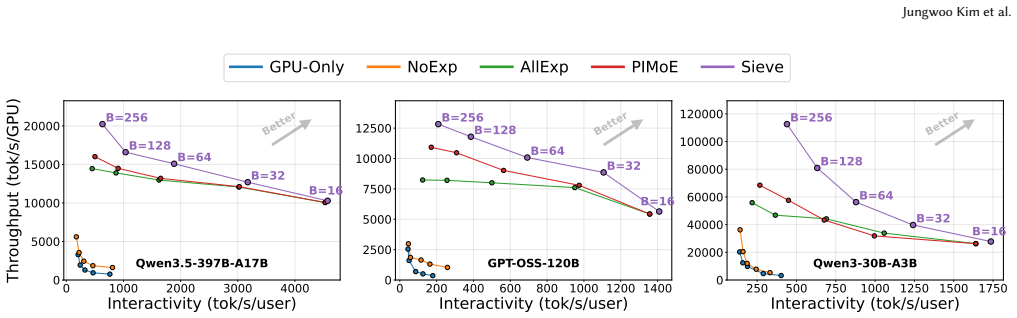
Mixture-of-Experts (MoE) has become a dominant architecture for scaling large language models (LLMs). However, the execution characteristics of MoE inference are changing rapidly and increasingly mismatch the assumptions underlying existing Processing-in-Memory (PIM) systems. Prior PIM systems for LLMs rely on static rules to offload memory-bound operations to PIM, without accounting for the combined effects of load imbalance and inter-GPU communication. Meanwhile, modern MoE models activate fewer experts out of increasingly many, creating a bimodal expert distribution: a small set of experts receives many tokens, while a long tail of experts receives only one or a few. We identify a trend in modern MoE models toward increasingly bimodal token-to-expert distributions, quantify the resulting disparity in arithmetic intensity across experts, and show that this disparity dramatically reduces the efficiency of state-of-the-art PIM systems for LLMs. To address this problem, we propose a scheduler for serving MoE models on multi-GPU systems with attached HBM-PIM stacks. Our scheduler partitions expert execution between GPU and PIM based on runtime token-to-expert distributions, while jointly considering interconnect overhead, memory bandwidth, GPU throughput, and PIM throughput. Moreover, we propose Sieve, a runtime framework that employs the scheduler to coordinate execution across GPUs and their attached HBM-PIM stacks. Sieve overlaps GPU computation, PIM computation, and intra- and inter-device communication while preserving cross-device dependencies induced by expert parallelism. Sieve is evaluated on our cycle-accurate simulator based on Ramulator 2.0. Compared to state-of-the-art PIM systems for MoE, Sieve improves both throughput and interactivity by 1.3x, 1.3x, and 1.6x on Qwen3.5-397B-A17B, GPT-OSS-120B, and Qwen3-30B-A3B, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Sieve, a runtime framework and dynamic scheduler for accelerating inference of evolving Mixture-of-Experts (MoE) large language models on multi-GPU systems equipped with HBM-based Processing-in-Memory (PIM) stacks. The authors observe that modern MoE models exhibit increasingly bimodal token-to-expert activation distributions, leading to varying arithmetic intensities that static PIM offloading strategies fail to handle efficiently due to load imbalance and inter-GPU communication. Sieve's scheduler dynamically partitions expert execution between GPUs and PIM devices based on runtime token counts, while jointly optimizing for interconnect overhead, bandwidth, and throughputs, and overlaps GPU/PIM computation with communications while respecting expert parallelism dependencies. Using a cycle-accurate simulator extending Ramulator 2.0, the paper reports that Sieve improves both throughput and interactivity by 1.3× on Qwen3.5-397B-A17B, 1.3× on GPT-OSS-120B, and 1.6× on Qwen3-30B-A3B compared to prior state-of-the-art PIM systems for MoE.
Significance. If the reported performance improvements prove robust once all runtime overheads are accurately modeled, this work would represent a meaningful advance in PIM acceleration for large-scale MoE inference. It directly targets the emerging mismatch between static PIM designs and the dynamic, bimodal activation patterns of contemporary MoE models, offering a practical scheduling approach that accounts for load imbalance and communication costs. The quantification of the bimodal distribution trend supplies useful empirical grounding for future hardware-software co-design efforts in LLM serving.
major comments (3)
- [§5] §5 (Evaluation and Simulator): The central speedups (1.3–1.6×) are obtained from a cycle-accurate simulator based on Ramulator 2.0, yet the manuscript supplies no description of how runtime token-to-expert distribution monitoring, scheduler decision latency, or the additional cross-device synchronization traffic generated by dynamic partitioning are modeled at cycle granularity. If these costs are omitted or underestimated, the net advantage over static PIM baselines cannot be substantiated.
- [§4] §4 (Scheduler Design): The scheduler is said to partition experts by jointly considering interconnect overhead, memory bandwidth, GPU throughput, and PIM throughput, but the text provides neither pseudocode, decision algorithm, nor cost-model equations. Without these, it is impossible to verify that the partitioning logic itself does not introduce overheads that offset the claimed gains.
- [§3] §3 (Motivation): The bimodal token-to-expert distribution is demonstrated on the three evaluated models, but no analysis or sensitivity study shows whether this distribution persists across future MoE scales or training regimes. The headline claims rest on the assumption that the observed pattern generalizes; absent such evidence, the broader applicability of the dynamic scheduler remains unproven.
minor comments (2)
- [§5] The term 'interactivity' is used in the abstract and results but is never explicitly defined (e.g., as 99th-percentile latency or token generation time); a clear metric definition should be added in §5.
- Figure captions and legends in the evaluation section would benefit from explicit listing of all compared systems and their configurations to improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation and Simulator): The central speedups (1.3–1.6×) are obtained from a cycle-accurate simulator based on Ramulator 2.0, yet the manuscript supplies no description of how runtime token-to-expert distribution monitoring, scheduler decision latency, or the additional cross-device synchronization traffic generated by dynamic partitioning are modeled at cycle granularity. If these costs are omitted or underestimated, the net advantage over static PIM baselines cannot be substantiated.
Authors: We agree that the modeling of these runtime overheads requires more explicit description for full transparency. The simulator extends Ramulator 2.0 with support for dynamic expert partitioning, where token-to-expert monitoring is implemented via lightweight periodic sampling whose cycle cost is included in the execution trace, scheduler decisions incur a modeled fixed-latency overhead per invocation, and additional synchronization traffic is captured within the existing interconnect model. However, these details are only summarized rather than fully elaborated. We will expand Section 5 with a dedicated subsection on overhead modeling, including the exact cycle costs and assumptions used, to confirm that they do not negate the reported gains. revision: yes
-
Referee: [§4] §4 (Scheduler Design): The scheduler is said to partition experts by jointly considering interconnect overhead, memory bandwidth, GPU throughput, and PIM throughput, but the text provides neither pseudocode, decision algorithm, nor cost-model equations. Without these, it is impossible to verify that the partitioning logic itself does not introduce overheads that offset the claimed gains.
Authors: We concur that the absence of pseudocode and explicit cost-model equations limits verifiability. Section 4 describes the joint optimization criteria and the high-level partitioning heuristic, but does not present the algorithmic steps or equations in a formal manner. We will add pseudocode for the decision procedure and the full set of cost-model equations (including how interconnect, bandwidth, and throughput terms are combined) to the revised manuscript so that readers can independently assess overheads. revision: yes
-
Referee: [§3] §3 (Motivation): The bimodal token-to-expert distribution is demonstrated on the three evaluated models, but no analysis or sensitivity study shows whether this distribution persists across future MoE scales or training regimes. The headline claims rest on the assumption that the observed pattern generalizes; absent such evidence, the broader applicability of the dynamic scheduler remains unproven.
Authors: The manuscript quantifies the bimodal pattern on three contemporary large-scale MoE models that already span a range of sizes and expert counts. We will add a short discussion in Section 3 explaining why the underlying design trends (increasing total experts while keeping per-token activation sparse) make continued bimodality likely. A full sensitivity study on hypothetical future scales or training regimes is not feasible within the current evaluation, as it would require access to models that do not yet exist. revision: partial
Circularity Check
No significant circularity; performance claims are direct empirical measurements from simulator runs
full rationale
The paper proposes a dynamic scheduler for partitioning experts between GPU and PIM based on observed token distributions, then evaluates the resulting Sieve framework via cycle-accurate simulation against static baselines. Reported speedups (1.3–1.6×) are measured outcomes on three concrete models; they do not reduce via any equations to fitted parameters, self-referential definitions, or load-bearing self-citations. The analysis of bimodal distributions is an empirical observation used to motivate the design, not a derivation that presupposes the result. The simulator (Ramulator 2.0) is an external tool, and no uniqueness theorems or ansatzes are imported from prior author work to force the outcome.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Modern MoE models exhibit increasingly bimodal token-to-expert distributions that create large disparities in arithmetic intensity across experts.
- domain assumption A runtime scheduler can accurately weigh interconnect overhead, memory bandwidth, GPU throughput, and PIM throughput to make per-expert placement decisions.
invented entities (1)
-
Sieve runtime framework and scheduler
no independent evidence
Reference graph
Works this paper leans on
-
[1]
[n. d.]. GLM-4.5-FP8 Model Card. https://huggingface.co/zai-org/GLM-4.5-FP8. Accessed: 2025-11-15
work page 2025
-
[2]
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al . 2025. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Artificial Analysis. 2025. Artificial Analysis. https://artificialanalysis.ai. Accessed: 2025-11-03
work page 2025
-
[4]
Daehyeon Baek, Soojin Hwang, and Jaehyuk Huh. 2024. pSyncPIM: Partially Synchronous Execution of Sparse Matrix Operations for All-Bank PIM Archi- tectures. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 354–367. 12 Sieve: Dynamic Expert-Aware PIM Acceleration for Evolving Mixture-of-Experts Models
work page 2024
-
[5]
Baidu-ERNIE-Team. 2025. ERNIE 4.5 Technical Report. https://yiyan.baidu.com/ blog/publication/ERNIE_Technical_Report.pdf
work page 2025
-
[6]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
work page 2020
-
[7]
Hongtao Chen, Weiyu Xie, Boxin Zhang, Jingqi Tang, Jiahao Wang, Jianwei Dong, Shaoyuan Chen, Ziwei Yuan, Chen Lin, Chengyu Qiu, Yuening Zhu, Qingliang Ou, Jiaqi Liao, Xianglin Chen, Zhiyuan Ai, Yongwei Wu, and Mingxing Zhang. 2025. KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models. InProceedings of the ACM SIGOPS 31st...
work page 2025
-
[8]
Yunji Chen, Tao Luo, Shaoli Liu, Shijin Zhang, Liqiang He, Jia Wang, Ling Li, Tianshi Chen, Zhiwei Xu, Ninghui Sun, et al . 2014. Dadiannao: A machine- learning supercomputer. In2014 47th Annual IEEE/ACM International Symposium on Microarchitecture. IEEE, 609–622
work page 2014
-
[9]
Yu-Hsin Chen, Joel Emer, and Vivienne Sze. 2016. Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks.ACM SIGARCH computer architecture news44, 3 (2016), 367–379
work page 2016
-
[10]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y. K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. 2024. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. arXiv:2401.06066 [cs.CL] https://arxiv.org/abs/2401.06066
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Bill Dally. 2023. Hardware for deep learning. In2023 IEEE Hot Chips 35 Symposium (HCS). IEEE Computer Society, 1–58
work page 2023
-
[13]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
work page 2019
-
[14]
Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, et al
-
[15]
In International conference on machine learning
Glam: Efficient scaling of language models with mixture-of-experts. In International conference on machine learning. PMLR, 5547–5569
-
[16]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
work page 2022
-
[17]
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, Andy Jones, Sam Bowman, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Nelson Elhage, Sheer El-Showk, Stanislav Fort, Zac Hatfield-Dodds, Tom Henighan, Danny Hernandez, Tristan Hume, Josh Jacobson, Scott Joh...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Amir Gholami, Zhewei Yao, Sehoon Kim, Coleman Hooper, Michael W Mahoney, and Kurt Keutzer. 2024. Ai and memory wall.IEEE Micro44, 3 (2024), 33–39
work page 2024
-
[19]
Yufeng Gu, Alireza Khadem, Sumanth Umesh, Ning Liang, Xavier Servot, Onur Mutlu, Ravi Iyer, and Reetuparna Das. 2025. PIM is all you need: A CXL-enabled GPU-free system for large language model inference. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Lan- guages and Operating Systems, Volume 2. 862–881
work page 2025
-
[20]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Mingxuan He, Choungki Song, Ilkon Kim, Chunseok Jeong, Seho Kim, Il Park, Mithuna Thottethodi, and TN Vijaykumar. 2020. Newton: A DRAM-maker’s accelerator-in-memory (AiM) architecture for machine learning. In2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 372–385
work page 2020
-
[22]
Yintao He, Haiyu Mao, Christina Giannoula, Mohammad Sadrosadati, Juan Gómez-Luna, Huawei Li, Xiaowei Li, Ying Wang, and Onur Mutlu. 2025. Papi: Ex- ploiting dynamic parallelism in large language model decoding with a processing- in-memory-enabled computing system. InProceedings of the 30th ACM Inter- national Conference on Architectural Support for Progra...
work page 2025
-
[23]
Guseul Heo, Sangyeop Lee, Jaehong Cho, Hyunmin Choi, Sanghyeon Lee, Hyungkyu Ham, Gwangsun Kim, Divya Mahajan, and Jongse Park. 2024. Ne- upims: Npu-pim heterogeneous acceleration for batched llm inferencing. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. 722–737
work page 2024
-
[24]
Yang Hong, Junlong Yang, Bo Peng, and Jianguo Yao. 2026. REPA: Re configurable P IM for the Joint A cceleration of KV Cache Offloading and Processing. In Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 1622–1639
work page 2026
-
[25]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Norman P Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, et al. 2017. In-datacenter performance analysis of a tensor processing unit. InProceedings of the 44th annual international symposium on computer architecture. 1–12
work page 2017
-
[27]
Jin Hyun Kim, Shin-Haeng Kang, Sukhan Lee, Hyeonsu Kim, Yuhwan Ro, Seung- won Lee, David Wang, Jihyun Choi, Jinin So, YeonGon Cho, et al. 2022. Aquabolt- XL HBM2-PIM, LPDDR5-PIM with in-memory processing, and AXDIMM with acceleration buffer.IEEE Micro42, 3 (2022), 20–30
work page 2022
-
[28]
Jin Hyun Kim, Yuhwan Ro, Jinin So, Sukhan Lee, Shin-haeng Kang, YeonGon Cho, Hyeonsu Kim, Byeongho Kim, Kyungsoo Kim, Sangsoo Park, et al. 2023. Samsung pim/pnm for transfmer based ai: Energy efficiency on pim/pnm cluster. In2023 IEEE Hot Chips 35 Symposium (HCS). IEEE Computer Society, 1–31
work page 2023
-
[29]
Wonung Kim, Yubin Lee, Yoonsung Kim, Jinwoo Hwang, Seongryong Oh, Jiyong Jung, Aziz Huseynov, Woong Gyu Park, Chang Hyun Park, Divya Mahajan, et al
- [30]
-
[31]
Hyucksung Kwon, Kyungmo Koo, Janghyeon Kim, Woongkyu Lee, Minjae Lee, Gyeonggeun Jung, Hyungdeok Lee, Yousub Jung, Jaehan Park, Yosub Song, et al
-
[32]
In2026 IEEE International Symposium on High Performance Computer Architecture (HPCA)
PIMphony: Overcoming Bandwidth and Capacity Inefficiency in PIM-Based Long-Context LLM Inference System. In2026 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 1–21
-
[33]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAtten- tion. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
work page 2023
-
[34]
Yongkee Kwon, Kornijcuk Vladimir, Nahsung Kim, Woojae Shin, Jongsoon Won, Minkyu Lee, Hyunha Joo, Haerang Choi, Guhyun Kim, Byeongju An, et al. 2022. System architecture and software stack for GDDR6-AiM. In2022 IEEE Hot Chips 34 Symposium (HCS). IEEE, 1–25
work page 2022
-
[35]
Hyojung Lee, Daehyeon Baek, Jimyoung Son, Jieun Choi, Kihyo Moon, and Minsung Jang. 2025. PAISE: PIM-Accelerated Inference Scheduling Engine for Transformer-based LLM. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 1707–1719
work page 2025
-
[36]
Sukhan Lee, Shin-haeng Kang, Jaehoon Lee, Hyeonsu Kim, Eojin Lee, Seungwoo Seo, Hosang Yoon, Seungwon Lee, Kyounghwan Lim, Hyunsung Shin, et al. 2021. Hardware architecture and software stack for PIM based on commercial DRAM technology: Industrial product. In2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 43–56
work page 2021
-
[37]
Seongju Lee, Kyuyoung Kim, Sanghoon Oh, Joonhong Park, Gimoon Hong, Dongyoon Ka, Kyudong Hwang, Jeongje Park, Kyeongpil Kang, Jungyeon Kim, et al. 2022. A 1ynm 1.25 V 8Gb, 16Gb/s/pin GDDR6-based accelerator-in-memory supporting 1TFLOPS MAC operation and various activation functions for deep- learning applications. In2022 IEEE International Solid-State Cir...
work page 2022
-
[38]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[39]
Cong Li, Zhe Zhou, Size Zheng, Jiaxi Zhang, Yun Liang, and Guangyu Sun
-
[40]
Specpim: Accelerating speculative inference on pim-enabled system via architecture-dataflow co-exploration. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. 950–965
-
[41]
Sixu Li, Yuzhou Chen, Chaojian Li, Yonggan Fu, Zheng Wang, Zhongzhi Yu, Hao- ran You, Zhifan Ye, Wei Zhou, Yongan Zhang, et al. 2025. ORCHES: Orchestrated Test-Time-Compute-based LLM Reasoning on Collaborative GPU-PIM HEtero- geneous System. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture. 476–489
work page 2025
-
[42]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations
work page 2023
-
[43]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024). 13 Jungwoo Kim et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Nisa Bostancı, Ataberk Olgun, A
Haocong Luo, Yahya Can Tuğrul, F. Nisa Bostancı, Ataberk Olgun, A. Giray Yağlıkçı, , and Onur Mutlu. 2023. Ramulator 2.0: A Modern, Modular, and Extensible DRAM Simulator
work page 2023
-
[45]
Meta AI. 2025. The Llama 4 Herd: The Beginning of a New Era of Natively Multimodal Models. https://ai.meta.com/blog/llama-4-multimodal-intelligence/
work page 2025
-
[46]
NVIDIA. 2025. NVIDIA DGX B200 Datasheet. https://resources.nvidia.com/en- us-dgx-systems/dgx-b200-datasheet
work page 2025
-
[47]
Yue Pan, Zihan Xia, Po-Kai Hsu, Lanxiang Hu, Hyungyo Kim, Janak Sharda, Minxuan Zhou, Nam Sung Kim, Shimeng Yu, Tajana Rosing, et al. 2025. Stratum: System-Hardware Co-Design with Tiered Monolithic 3D-Stackable DRAM for Efficient MoE Serving.arXiv preprint arXiv:2510.05245(2025)
-
[48]
Jaehyun Park, Jaewan Choi, Kwanhee Kyung, Michael Jaemin Kim, Yongsuk Kwon, Nam Sung Kim, and Jung Ho Ahn. 2024. Attacc! unleashing the power of pim for batched transformer-based generative model inference. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 103–119
work page 2024
-
[49]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
work page 2024
-
[50]
Derrick Quinn, E Ezgi Yücel, Jinkwon Kim, José F Martínez, and Mohammad Alian. 2025. LongSight: Compute-Enabled Memory to Accelerate Large-Context LLMs via Sparse Attention. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture. 34–48
work page 2025
-
[51]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
GLM-4.5 Team. 2025. GLM-4.5: Agentic, Reasoning, and Coding (ARC) Founda- tion Models. https://arxiv.org/abs/2508.06471
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al . 2025. Kimi K2: Open Agentic Intelligence.arXiv preprint arXiv:2507.20534(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement De- langue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. 2019. Huggingface’s transformers: State-of-the-art natural language pro- cessing.arXiv preprint arXiv:1910.03771(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[55]
Lizhou Wu, Haozhe Zhu, Siqi He, Xuanda Lin, Xiaoyang Zeng, and Chixiao Chen. 2025. PIMoE: Towards efficient MoE transformer deployment on NPU- PIM system through throttle-aware task offloading. In2025 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, 1–7
work page 2025
-
[56]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Sungmin Yun, Kwanhee Kyung, Juhwan Cho, Jaewan Choi, Jongmin Kim, Byeongho Kim, Sukhan Lee, Kyomin Sohn, and Jung Ho Ahn. 2024. Duplex: A device for large language models with mixture of experts, grouped query atten- tion, and continuous batching. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 1429–1443
work page 2024
-
[58]
Shulai Zhang, Ningxin Zheng, Haibin Lin, Ziheng Jiang, Wenlei Bao, Chengquan Jiang, Qi Hou, Weihao Cui, Size Zheng, Li-Wen Chang, et al . 2025. Comet: Fine-grained computation-communication overlapping for mixture-of-experts. Proceedings of Machine Learning and Systems7 (2025)
work page 2025
-
[59]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. Sglang: Efficient execution of structured language model programs. Advances in neural information processing systems37 (2024), 62557–62583
work page 2024
-
[60]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: disaggregating prefill and decoding for goodput-optimized large language model serving. InProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation(Santa Clara, CA, USA)(OSDI’24). USENIX Association, USA, Article...
work page 2024
- [61]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.