Recognition: no theorem link
ReAD: Reinforcement-Guided Capability Distillation for Large Language Models
Pith reviewed 2026-05-13 01:42 UTC · model grok-4.3
The pith
ReAD improves downstream utility under the same token budget by using a reinforcement-guided bandit to adaptively allocate distillation resources based on capability interdependence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By first inferring task-essential capabilities, generating on-the-fly targeted supervision, and using an uncertainty-aware contextual bandit for adaptive budget allocation based on expected utility gains, ReAD explicitly accounts for how capabilities reshape each other during distillation, leading to better preservation of task success under constrained token budgets than methods that treat capabilities independently.
What carries the argument
uncertainty-aware contextual bandit that estimates expected utility gains to adaptively allocate the fixed distillation token budget across interdependent capabilities
Load-bearing premise
Task-essential capabilities can be reliably inferred upfront and the uncertainty-aware contextual bandit can accurately estimate expected utility gains for adaptive budget allocation without introducing new biases or instability.
What would settle it
A controlled experiment in which ReAD's bandit-driven allocations produce equal or lower downstream task scores than uniform or random allocation of the same total tokens on multiple benchmarks would falsify the claimed benefit of adaptive budgeting.
Figures


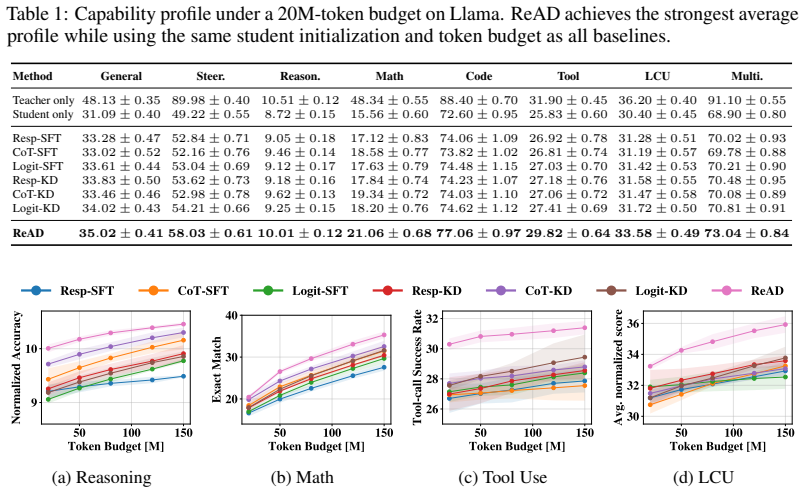

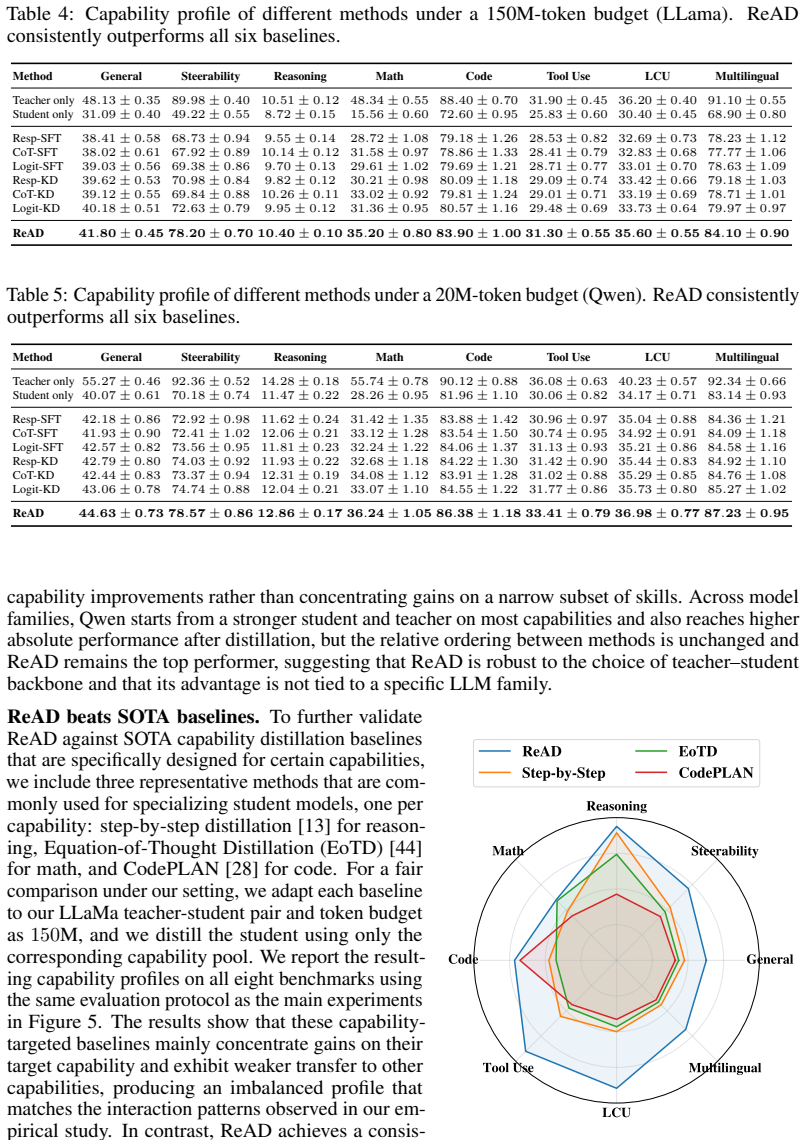
read the original abstract
Capability distillation applies knowledge distillation to selected model capabilities, aiming to compress a large language model (LLM) into a smaller one while preserving the abilities needed for a downstream task. However, most existing methods treat capabilities as independent training targets and overlook how improving one capability can reshape the student's broader capability profile, especially when multiple abilities jointly determine task success. We study capability distillation under a fixed token budget and identify two consistent patterns: distillation induces systematic, budget-dependent cross-capability transfer, and additional budget often brings limited task-relevant gains while sometimes degrading other useful abilities. Building on these insights, we propose ReAD, a Reinforcement-guided cApability Distillation framework that explicitly accounts for capability interdependence. ReAD first infers task-essential capabilities, then generates capability-targeted supervision on the fly, and finally uses an uncertainty-aware contextual bandit to adaptively allocate the distillation budget based on expected utility gains. Extensive experiments show that ReAD improves downstream utility under the same token budget while reducing harmful spillover and wasted distillation effort compared to strong baselines. Our code is publicly available at https://github.com/LabRAI/ReAD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReAD, a framework for capability distillation of LLMs under a fixed token budget. It first identifies two empirical patterns (budget-dependent cross-capability transfer and diminishing task-relevant returns), then infers task-essential capabilities, generates on-the-fly targeted supervision, and employs an uncertainty-aware contextual bandit to adaptively allocate the budget according to expected utility gains. Experiments report improved downstream utility and reduced harmful spillover relative to strong baselines, with public code released.
Significance. If the central empirical claims hold after clarification of the load-bearing components, the work would provide a concrete mechanism for handling capability interdependence during distillation rather than treating abilities as independent targets. The public code release is a clear strength that supports reproducibility and allows direct inspection of the inference and bandit implementations.
major comments (3)
- [§3.1] §3.1: The procedure for inferring task-essential capabilities is described only at a high level with no algorithm, selection criteria, or validation metric; because this inference is the first step that determines all subsequent supervision and allocation, its reliability directly determines whether the claimed reduction in spillover is achieved or whether misidentified essentials increase wasted effort.
- [§3.3] §3.3, the contextual-bandit formulation: No reward function, uncertainty model, or update rule is supplied for how expected utility gains are computed while accounting for cross-capability transfers; without these equations the claim that the bandit produces accurate, bias-free allocations cannot be verified and remains load-bearing for the headline result of improved utility under the same token budget.
- [Table 2] Table 2 and associated ablation text: The reported gains over baselines are not accompanied by statistical significance tests, error bars, or an ablation that isolates the bandit allocation from the capability-inference step; this prevents confirmation that the adaptive mechanism, rather than other design choices, drives the observed improvements.
minor comments (2)
- [§2] The abstract asserts 'consistent patterns' of cross-capability transfer but §2 does not quantify them with explicit metrics or statistical tests, leaving the empirical foundation for the method somewhat underspecified.
- Notation for 'capability profile' and 'utility gain' is introduced without a compact mathematical definition early in the paper; a single-line formalization would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to improve clarity and rigor in our presentation of the capability inference procedure, bandit formulation, and experimental validation. We address each major comment below and will incorporate the suggested clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: [§3.1] The procedure for inferring task-essential capabilities is described only at a high level with no algorithm, selection criteria, or validation metric; because this inference is the first step that determines all subsequent supervision and allocation, its reliability directly determines whether the claimed reduction in spillover is achieved or whether misidentified essentials increase wasted effort.
Authors: We agree that Section 3.1 presents the inference process at a high level. In the revision we will add a complete algorithm (as pseudocode), explicit selection criteria based on correlation with downstream task performance and cross-capability transfer patterns identified in Section 2, and a validation metric using held-out capability probes. These additions will allow direct assessment of inference reliability and its contribution to reduced spillover. revision: yes
-
Referee: [§3.3] §3.3, the contextual-bandit formulation: No reward function, uncertainty model, or update rule is supplied for how expected utility gains are computed while accounting for cross-capability transfers; without these equations the claim that the bandit produces accurate, bias-free allocations cannot be verified and remains load-bearing for the headline result of improved utility under the same token budget.
Authors: We acknowledge that the mathematical specification in Section 3.3 is incomplete. The revised manuscript will explicitly define the reward function (expected downstream utility gain net of estimated spillover), the uncertainty model (posterior sampling over capability-value estimates), and the update rule that incorporates empirical cross-capability transfer matrices from our preliminary analysis. These equations will substantiate how the bandit accounts for interdependence and supports the reported utility improvements. revision: yes
-
Referee: [Table 2] Table 2 and associated ablation text: The reported gains over baselines are not accompanied by statistical significance tests, error bars, or an ablation that isolates the bandit allocation from the capability-inference step; this prevents confirmation that the adaptive mechanism, rather than other design choices, drives the observed improvements.
Authors: We will revise the experimental section to include error bars computed over multiple random seeds, paired statistical significance tests for all reported gains in Table 2, and a new ablation that replaces the bandit allocator with a fixed proportional allocation while keeping the inference and supervision components fixed. This will isolate the adaptive allocation's contribution. revision: yes
Circularity Check
No significant circularity; empirical framework with independent validation
full rationale
The paper describes ReAD as an empirical framework that infers task-essential capabilities, generates targeted supervision, and uses an uncertainty-aware contextual bandit for adaptive budget allocation under fixed token constraints. No equations or derivations are presented that reduce the claimed downstream utility gains, reduced spillover, or efficiency improvements to quantities defined by the same fitted parameters, self-citations, or ansatzes used to produce them. The central claims rest on experimental comparisons against baselines with publicly available code, rendering the derivation chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
LongBench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages ...
work page 2024
-
[3]
Zinuo Cai, Rongbo Ma, Yicheng Fu, Weishan Zhang, Ruhui Ma, and Haibing Guan. Llmaas: Serving large language models on trusted serverless computing platforms.IEEE Transactions on Artificial Intelligence, 2024
work page 2024
-
[4]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page 2021
-
[5]
Adapting large language models via reading comprehension
Daixuan Cheng, Shaohan Huang, and Furu Wei. Adapting large language models via reading comprehension. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[6]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023
work page 2023
-
[7]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.ArXiv, abs/1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Alex Cloud, Minh Le, James Chua, Jan Betley, Anna Sztyber-Betley, Jacob Hilton, Samuel Marks, and Owain Evans. Subliminal learning: Language models transmit behavioral traits via hidden signals in data.arXiv preprint arXiv:2507.14805, 2025
-
[9]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christo- pher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
work page 2021
-
[10]
Luyang Fang, Xiaowei Yu, Jiazhang Cai, Yongkai Chen, Shushan Wu, Zhengliang Liu, Zhenyuan Yang, Haoran Lu, Xilin Gong, Yufang Liu, Terry Ma, Wei Ruan, Ali Abbasi, Jing Zhang, Tao Wang, Ehsan Latif, Wei Liu, Wei Zhang, Soheil Kolouri, Xiaoming Zhai, Dajiang Zhu, Wenxuan Zhong, Tianming Liu, and Ping Ma. Knowledge distillation and dataset distillation of la...
-
[11]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021
work page 2021
-
[12]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015. 10
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, and Chen-Yu Lee. Distilling step-by-step! outperforming larger lan- guage models with less training data and smaller model sizes.arXiv preprint arXiv:2305.02301, 2023
-
[14]
Tinybert: Distilling bert for natural language understanding
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language understanding. InFindings of the association for computational linguistics: EMNLP 2020, pages 4163–4174, 2020
work page 2020
-
[15]
Yimin Jing, Renren Jin, Jiahao Hu, Huishi Qiu, Xiaohua Wang, Peng Wang, and Deyi Xiong. Followeval: A multi-dimensional benchmark for assessing the instruction-following capability of large language models.arXiv preprint arXiv:2311.09829, 2023
-
[16]
Dynamic knowledge distillation for pre-trained language models
Lei Li, Yankai Lin, Shuhuai Ren, Peng Li, Jie Zhou, and Xu Sun. Dynamic knowledge distillation for pre-trained language models. 2021
work page 2021
-
[17]
StarCoder: may the source be with you!
Raymond Li, Erik Nijkamp, Swaroop Mishra, et al. Starcoder: May the source be with you! arXiv preprint arXiv:2305.06161, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Less is more: Task-aware layer-wise distillation for language model compression
Chen Liang, Simiao Zuo, Qingru Zhang, Pengcheng He, Weizhu Chen, and Tuo Zhao. Less is more: Task-aware layer-wise distillation for language model compression. InInternational Conference on Machine Learning, pages 20852–20867. PMLR, 2023
work page 2023
-
[19]
Qian Liu, Xiaosen Zheng, Niklas Muennighoff, Guangtao Zeng, Longxu Dou, Tianyu Pang, Jing Jiang, and Min Lin. Regmix: Data mixture as regression for language model pre-training. arXiv preprint arXiv:2407.01492, 2024
-
[20]
Teaching small language models to reason
Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, and Aliaksei Severyn. Teaching small language models to reason. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 2: short papers), pages 1773–1781, 2023
work page 2023
-
[21]
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4.arXiv preprint arXiv:2304.03277, 2023
work page internal anchor Pith review arXiv 2023
-
[22]
Ponti, Goran Glavaš, Olga Majewska, Qianchu Liu, Ivan Vuli´c, and Anna Korhonen
Edoardo M. Ponti, Goran Glavaš, Olga Majewska, Qianchu Liu, Ivan Vuli´c, and Anna Korhonen. XCOPA: A multilingual dataset for causal commonsense reasoning. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020
work page 2020
-
[23]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
work page 2024
-
[24]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Rose Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics, 2024
work page 2024
-
[25]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[26]
Language models are multilingual chain-of-thought reasoners, 2022
Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush V osoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, Dipanjan Das, and Jason Wei. Language models are multilingual chain-of-thought reasoners, 2022
work page 2022
-
[27]
Kumar Shridhar, Alessandro Stolfo, and Mrinmaya Sachan. Distilling reasoning capabilities into smaller language models.Findings of the Association for Computational Linguistics: ACL 2023, pages 7059–7073, 2023
work page 2023
-
[28]
Zhihong Sun, Chen Lyu, Bolun Li, Yao Wan, Hongyu Zhang, Ge Li, and Zhi Jin. Enhancing code generation performance of smaller models by distilling the reasoning ability of llms.arXiv preprint arXiv:2403.13271, 2024. 11
-
[29]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them.arXiv preprint arXiv:2210.09261, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Stanford alpaca: An instruction-following llama model, 2023
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Stanford alpaca: An instruction-following llama model, 2023
work page 2023
-
[31]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. volume 33, pages 5776–5788, 2020
work page 2020
-
[32]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024
work page 2024
-
[33]
WizardLM: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023
work page internal anchor Pith review arXiv 2023
-
[34]
On the tool manipulation capability of open-source large language models, 2023
Qiantong Xu, Fenglu Hong, Bo Li, Changran Hu, Zhengyu Chen, and Jian Zhang. On the tool manipulation capability of open-source large language models, 2023
work page 2023
-
[35]
arXiv preprint arXiv:2402.13116 , year =
Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, and Tianyi Zhou. A survey on knowledge distillation of large language models.arXiv preprint arXiv:2402.13116, 2024
-
[36]
Patil, Ion Stoica, and Joseph E
Fanjia Yan, Huanzhi Mao, Charlie Cheng-Jie Ji, Tianjun Zhang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Berkeley function calling leaderboard.https://gorilla.cs.berkeley. edu/blogs/8_berkeley_function_calling_leaderboard.html, 2024
work page 2024
-
[37]
Chuanpeng Yang, Yao Zhu, Wang Lu, Yidong Wang, Qian Chen, Chenlong Gao, Bingjie Yan, and Yiqiang Chen. Survey on knowledge distillation for large language models: methods, evaluation, and application.ACM Transactions on Intelligent Systems and Technology, 2024
work page 2024
-
[38]
Yuanhao Yue, Chengyu Wang, Jun Huang, and Peng Wang. Distilling instruction-following abilities of large language models with task-aware curriculum planning.arXiv preprint arXiv:2405.13448, 2024
-
[39]
Recommen- dation as instruction following: A large language model empowered recommendation approach
Junjie Zhang, Ruobing Xie, Yupeng Hou, Xin Zhao, Leyu Lin, and Ji-Rong Wen. Recommen- dation as instruction following: A large language model empowered recommendation approach. ACM Transactions on Information Systems, 43(5):1–37, 2025
work page 2025
-
[40]
Knowledgeable preference alignment for llms in domain-specific question answering
Yichi Zhang, Zhuo Chen, Yin Fang, Yanxi Lu, Li Fangming, Wen Zhang, and Huajun Chen. Knowledgeable preference alignment for llms in domain-specific question answering. In Findings of the Association for Computational Linguistics: ACL 2024, pages 891–904, 2024
work page 2024
-
[41]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2), 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Qihuang Zhong, Liang Ding, Li Shen, Juhua Liu, Bo Du, and Dacheng Tao. Revisiting knowledge distillation for autoregressive language models.arXiv preprint arXiv:2402.11890, 2024
-
[43]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. Distilling mathematical reasoning capabilities into small language models.Neural Networks, 179:106594, 2024. 12 Technical Appendices and Supplementary Material A Benchmark Datasets Table 3 summarizes the benchmark suite used to evaluate each capability. For capabilities associated with multiple bench...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.