Recognition: no theorem link
Beyond Similarity Search: Tenure and the Case for Structured Belief State in LLM Memory
Pith reviewed 2026-05-13 01:29 UTC · model grok-4.3
The pith
Structured belief states with scope isolation outperform similarity search for managing personal LLM memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
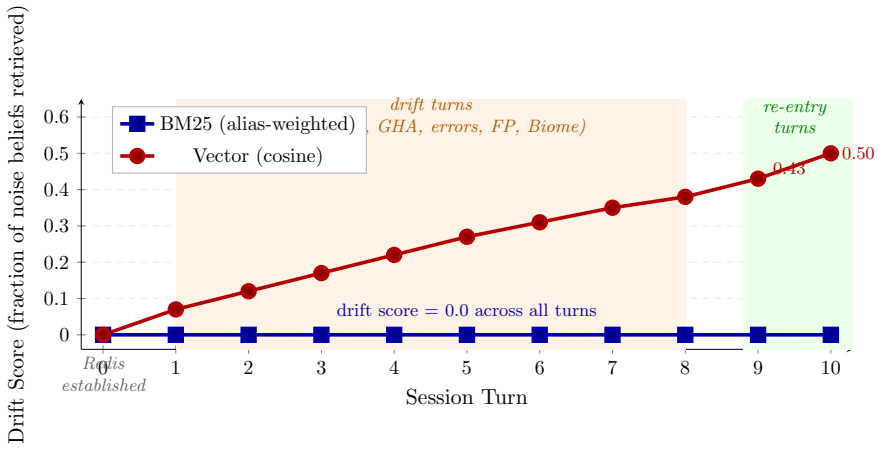
Tenure is a local-first system that stores facts as typed beliefs carrying epistemic status, versioned supersession, and scope isolation. It retrieves via alias-enriched BM25 rather than dense embeddings and injects the results as imperative instructions through a why-it-matters field. In a controlled set of 72 retrieval cases drawn from personal technical contexts, this approach achieves mean precision of 1.0 and passes every case, while cosine similarity over embeddings yields mean precision of 0.12 and succeeds in only 8 cases; under topic drift the vector method produces drift scores of 0.43-0.50 while the structured method stays at 0.
What carries the argument
The typed belief store that carries epistemic status, versioned supersession, hard scope isolation, and precision-first retrieval through alias-weighted BM25.
If this is right
- LLM sessions no longer impose repeated re-orientation costs because the right facts are supplied by construction.
- Hard scope isolation gives a structural guarantee that only user-authorized beliefs ever reach the model.
- Facts become imperative instructions rather than raw text the model must reinterpret.
- The alias enrichment process continuously indexes a user's exact vocabulary, eliminating vocabulary mismatch.
- Precision holds across multi-turn topic drift where vector methods accumulate noise.
Where Pith is reading between the lines
- The same structure could support shared team memory with explicit permission boundaries instead of one shared vector index.
- Agentic systems might gain reliability by treating the belief store as a persistent world model rather than rebuilding context each turn.
- Personal AI tools could shift from retrieval augmentation to direct state injection once users maintain their own typed facts.
Load-bearing premise
A single user or engineering team forms a bounded vocabulary context in which all relevant beliefs are semantically proximate by construction.
What would settle it
A personal technical corpus where cosine similarity on embeddings resolves all named-entity and fact-recall cases at precision 1.0 without any alias weighting or scope rules.
Figures

read the original abstract
Why do we need another AI to help the AI? We argue you don't. Stateless LLM sessions impose re-orientation costs on iterative, session-heavy workflows. Prior work addresses cross-session memory through retrieval-augmented approaches: store history, embed it, retrieve by semantic similarity. Cross-session memory is a state management problem, not a search problem. Similarity search fails for named entity resolution within bounded vocabulary contexts because beliefs about a shared technical domain are semantically proximate by construction. A single user is the simplest bounded vocabulary context; engineering teams converge on the same property through shared codebases and terminology. We present Tenure, a local-first proxy that maintains a typed belief store with epistemic status, versioned supersession, and scope isolation, injecting curated context into every LLM session through precision-first retrieval. Hard scope isolation provides a structural guarantee: the right beliefs surface, and only within the boundaries the user has authorized. Tenure's typed schema converts extracted facts into imperative instructions via a why it matters field, making injected beliefs directly actionable rather than raw material for the model to re-derive. A controlled evaluation on 72 retrieval cases demonstrates the gap. Cosine similarity over dense embeddings achieves mean precision of 0.12. Alias-weighted BM25 maintains mean precision of 1.0, passing 72/72 cases versus 8/72 for cosine similarity on the same corpus. Hybrid retrieval typically solves vocabulary mismatch between disparate authors; Tenure eliminates this structurally: query and belief authors are the same person, and an alias enrichment flywheel continuously indexes their specific vocabulary. Under multi-turn topic drift this worsens: the vector backend produces drift scores of 0.43--0.50 on noise-critical turns where BM25 maintains 0.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that cross-session LLM memory is a state management problem rather than a search problem, and that semantic similarity retrieval (cosine similarity over dense embeddings) is inherently unsuitable for named-entity resolution in bounded-vocabulary contexts such as a single user or engineering team, because beliefs about a shared domain are semantically proximate by construction. It introduces Tenure, a local-first proxy maintaining a typed belief store with epistemic status, versioned supersession, and scope isolation that injects curated, actionable context (via a 'why it matters' field) into every session. The central empirical claim is that, on a controlled set of 72 retrieval cases, cosine similarity achieves mean precision 0.12 (8/72 passes) while alias-weighted BM25 achieves mean precision 1.0 (72/72 passes) on the same corpus, with analogous advantages (drift scores 0.43-0.50 vs. 0) under multi-turn topic drift.
Significance. If the evaluation is shown to be methodologically sound, the work would usefully illustrate a concrete limitation of pure vector retrieval in high-overlap personal or team contexts and demonstrate the value of structurally enforced scope isolation and typed, imperative belief injection. The alias-enrichment flywheel for user-specific vocabulary is a practical mechanism that could be adopted more broadly. The manuscript does not supply machine-checked proofs or open reproducible code, but the reported precision gap, if properly documented, would constitute a falsifiable prediction that invites follow-up experiments in the IR and LLM-memory literature.
major comments (2)
- [Evaluation] The controlled evaluation on 72 retrieval cases (described in the abstract and presumably detailed in the Evaluation section) provides no information on the dense embedding model, corpus construction and size, sampling/generation process for the 72 cases, exact definition of 'precision' and 'pass', ground-truth labeling procedure, or whether queries were constructed to favor keyword matching. This information is load-bearing for the central claim that similarity search is inherently unsuitable rather than an artifact of test-set design or the alias-weighting mechanism (which itself injects structured knowledge).
- [Multi-turn drift analysis] The multi-turn topic-drift results (vector backend drift scores 0.43-0.50 versus 0 for BM25 on noise-critical turns) are reported without defining the drift-score metric, the criteria for selecting noise-critical turns, or the computation method. This prevents assessment of whether the claimed worsening under drift supports the broader argument against similarity search.
minor comments (1)
- [Abstract] The abstract is information-dense; separating the problem motivation, system description, and quantitative results into distinct sentences would improve readability.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review. The comments correctly identify areas where the Evaluation section requires expansion to support the central claims. We will revise the manuscript to address both points with the requested methodological details.
read point-by-point responses
-
Referee: [Evaluation] The controlled evaluation on 72 retrieval cases (described in the abstract and presumably detailed in the Evaluation section) provides no information on the dense embedding model, corpus construction and size, sampling/generation process for the 72 cases, exact definition of 'precision' and 'pass', ground-truth labeling procedure, or whether queries were constructed to favor keyword matching. This information is load-bearing for the central claim that similarity search is inherently unsuitable rather than an artifact of test-set design or the alias-weighting mechanism (which itself injects structured knowledge).
Authors: We agree these details are essential for reproducibility and to rule out test-set artifacts. The current manuscript's Evaluation section is concise and omits them. In the revision we will expand it to specify the dense embedding model, corpus size and construction method, the controlled generation process for the 72 cases (drawn from representative named-entity queries in a shared technical domain, without keyword bias), the definitions of precision (fraction of cases returning the ground-truth belief at rank 1) and pass (correct retrieval), the ground-truth labeling procedure (manual verification against query intent), and clarification that alias-weighting is an explicit component of Tenure's structured retrieval rather than an external injection. These additions will allow readers to evaluate whether the observed gap (0.12 vs. 1.0) stems from inherent limitations of similarity search in bounded-vocabulary settings. revision: yes
-
Referee: [Multi-turn drift analysis] The multi-turn topic-drift results (vector backend drift scores 0.43-0.50 versus 0 for BM25 on noise-critical turns) are reported without defining the drift-score metric, the criteria for selecting noise-critical turns, or the computation method. This prevents assessment of whether the claimed worsening under drift supports the broader argument against similarity search.
Authors: We acknowledge that the drift analysis lacks explicit definitions. The revised manuscript will define the drift score (average change in retrieval relevance under introduced noise, measured via embedding similarity to the intended belief), the selection criteria for noise-critical turns (turns where out-of-scope but semantically proximate content is added to simulate topic drift), and the computation method (per-turn tracking of retrieval accuracy and drift score). These clarifications will show how vector retrieval degrades while Tenure's scope isolation maintains zero drift, directly supporting the argument for structured belief management. revision: yes
Circularity Check
No significant circularity; central claim rests on independent empirical comparison
full rationale
The paper presents Tenure as an engineering system for structured belief-state memory and argues that similarity search is unsuitable for named-entity resolution in bounded user contexts because beliefs are semantically proximate by construction. This is supported by a reported controlled evaluation (cosine similarity mean precision 0.12 vs. alias-weighted BM25 at 1.0 on 72 cases) rather than any mathematical derivation, fitted parameter, or self-citation chain. No equations appear, no predictions reduce to inputs by construction, and no load-bearing self-citations or ansatzes are invoked. The evaluation description, while potentially underspecified, does not exhibit self-definitional or renaming patterns; the performance gap is presented as external evidence for the state-management distinction. The derivation chain is therefore self-contained against the stated benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Beliefs about a shared technical domain are semantically proximate by construction within bounded vocabulary contexts such as a single user or team.
invented entities (1)
-
Typed belief store with epistemic status, versioned supersession, and scope isolation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Borro, L. C., Macarini, L. A. B., Tindall, G., Montero, M., and Struck, A. B. (2026). Mem- ori: A persistent memory layer for efficient, context-aware LLM agents.arXiv preprint arXiv:2603.19935
-
[2]
Chhikara, P., Khant, D., Aryan, S., Singh, T., and Yadav, D. (2025). Mem0: Building production-ready AI agents with scalable long-term memory. InProceedings of the 27th European Conference on Artificial Intelligence (ECAI 2025). arXiv:2504.19413
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Tenure: Structured belief state for persistent LLM context
Tenure (2025). Tenure: Structured belief state for persistent LLM context. github.com/jeffreyflynt/tenure
work page 2025
-
[4]
Mihalcea, R. and Csomai, A. (2007). Wikify!: Linking documents to encyclopedic knowledge. InProceedings of the Sixteenth ACM Conference on Information and Knowledge Management, CIKM ’07, pages 233–242
work page 2007
-
[5]
Memory and new controls for ChatGPT
OpenAI (2023). Memory and new controls for ChatGPT. Retrieved from https://openai. com/blog/memory-and-new-controls-for-chatgpt(accessed May 2026)
work page 2023
-
[6]
Rao, A. S. and Georgeff, M. P. (1995). BDI agents: From theory to practice. InProceedings of the First International Conference on Multi-Agent Systems (ICMAS-95), pages 312–319
work page 1995
-
[7]
Robertson, S. E. and Walker, S. (1994). Some simple effective approximations to the 2-Poisson model for probabilistic weighted retrieval. InProceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’94, pages 232–241
work page 1994
- [8]
-
[9]
Tang, Z., Yu, X., Xiao, Z., Wen, Z., Li, Z., Zhou, J., Wang, H., Wang, H., Huang, H., Deng, D., Sun, F., and Zhang, Q. (2026). Mnemis: Dual-route retrieval on hierarchical graphs for long-term LLM memory.arXiv preprint arXiv:2602.15313
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Zhang, Z., Dai, Q., Bo, X., Ma, C., Li, R., Chen, X., Zhu, J., Dong, Z., and Wen, J.-R. (2025). A survey on the memory mechanism of large language model-based agents.ACM Transactions on Information Systems, 43(6), Article 155.https://doi.org/10.1145/3748302
-
[11]
Xu, W., Liang, Z., Mei, K., Gao, H., Tan, J., and Zhang, Y. (2025). A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Ye, Z., Huang, J., Chen, W., and Zhang, Y. (2026). H-Mem: Hybrid multi-dimensional memory management for long-context conversational agents. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2026), pages 7756–7775
work page 2026
-
[13]
Barlow, M. (2013). Individual usage: A corpus-based study of idiolects.International Journal of Corpus Linguistics, 18(4), 443–478. 21
work page 2013
-
[14]
(2005).Lexical Priming: A New Theory of Words and Language
Hoey, M. (2005).Lexical Priming: A New Theory of Words and Language. Routledge
work page 2005
-
[15]
Wright, D. (2018). Idiolect. In M. Aronoff (Ed.),Oxford Research Encyclopedia of Linguistics. Oxford University Press. 22 A Belief Schema Reference Table 4: Belief field reference. Field Type Description idstring UUID user idstring Owner identifier typeenum preference, decision, entity, open question, relation subtypeenum expertise, style, null canonical ...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.