Recognition: no theorem link
VERDI: Single-Call Confidence Estimation for Verification-Based LLM Judges via Decomposed Inference
Pith reviewed 2026-05-13 01:43 UTC · model grok-4.3
The pith
VERDI estimates how much to trust an LLM judge's verdict from the single structured reasoning trace it already produces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VERDI decomposes each verification-style evaluation into sub-checks and derives three structural signals—Step-Verdict Alignment, Claim-Level Margin, and Evidence Grounding Score—from the reasoning trace. These signals are combined with Platt-scaled logistic regression to produce a confidence estimate for the judge's overall verdict, using only the single inference call that generates the structured output.
What carries the argument
The three structural signals (Step-Verdict Alignment, Claim-Level Margin, Evidence Grounding Score) extracted from a decomposed verification trace and passed through logistic regression for calibration.
Load-bearing premise
The three signals derived from the reasoning trace are sufficiently predictive of whether the judge's verdict is actually correct.
What would settle it
Running VERDI on a fresh set of judge outputs and finding that its scores show no better than random correlation with actual judge errors (AUROC near 0.5) would show the signals are not useful.
Figures




read the original abstract
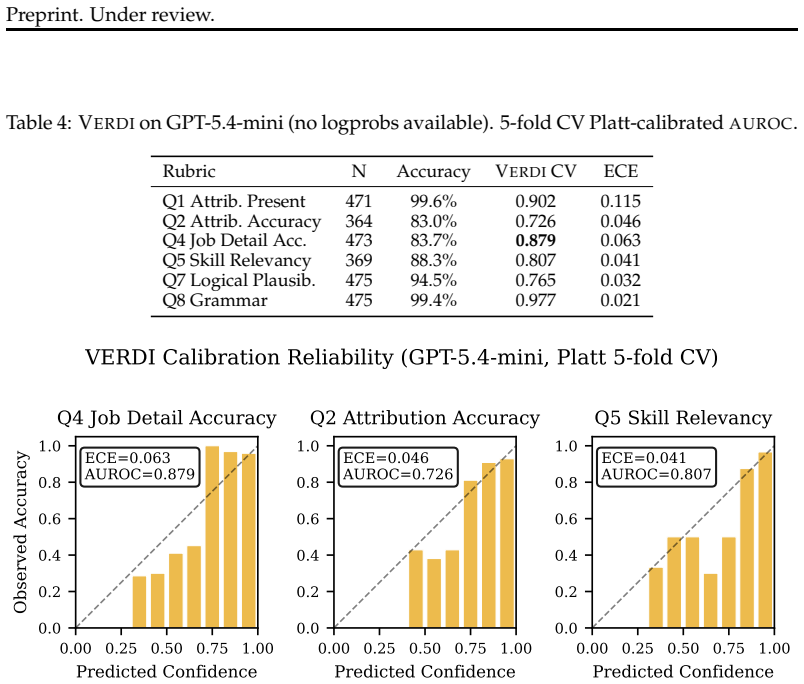
LLM-as-Judge systems are widely deployed for automated evaluation, yet practitioners lack reliable methods to know when a judge's verdict should be trusted. Token log-probabilities, the standard post-hoc confidence signal, are unavailable for many commercial LLMs and, even when accessible, saturate above 0.999 with structured JSON output. We introduce VERDI (VERification-Decomposed Inference), a method that extracts confidence from the reasoning trace a structured judge already produces, with no additional inference calls. VERDI decomposes each verification-style evaluation into sub-checks and derives three structural signals: Step-Verdict Alignment, Claim-Level Margin, and Evidence Grounding Score. We combine them with Platt-scaled logistic regression. On three public benchmarks, VERDI achieves AUROC 0.72-0.91 on GPT-4.1-mini and 0.66-0.80 on GPT-5.4-mini. On Qwen3.5-4B/9B/27B, where answer-token logprobs are anti-calibrated (higher confidence on errors, AUROC 0.32-0.49), VERDI achieves 0.56-0.70. We additionally validate on a production system with eight rubrics (AUROC 0.73-0.88 on factual rubrics), demonstrate cross-model transfer (AUROC 0.66-0.69), and show that a 33M-parameter NLI (Natural Language Inference) model provides a scalable alternative to regex extraction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VERDI extracts reliable confidence scores for verification-based LLM judges from a single inference call by decomposing the judge's reasoning trace into three structural signals (Step-Verdict Alignment, Claim-Level Margin, and Evidence Grounding Score), which are then combined via Platt-scaled logistic regression. It reports AUROC ranges of 0.72-0.91 on GPT-4.1-mini and GPT-5.4-mini, 0.56-0.70 on Qwen models (where log-probabilities are anti-calibrated), plus cross-model transfer and production-system results on factual rubrics.
Significance. If the central results hold after addressing the noted gaps, the work is significant for practical LLM-as-judge deployments: it offers a zero-extra-call alternative to token log-probabilities, works on closed models, and shows utility on anti-calibrated open models plus a real production system. The single-call and cross-model transfer aspects are particularly valuable strengths.
major comments (2)
- [§4] §4 (Experimental Results) and associated tables: No ablation studies are presented that isolate the contribution of each of the three structural signals (e.g., full model vs. models using only Step-Verdict Alignment or only Claim-Level Margin). This is load-bearing for the central claim that the decomposed signals drive the reported AUROCs rather than format artifacts or the logistic regression itself; without ablations or feature-importance coefficients on the same data splits, the predictiveness of the signals remains unverified.
- [§4.3] §4.3 (Production and Transfer Experiments): The manuscript reports AUROC 0.73-0.88 on the production system with eight rubrics but provides no details on rubric definitions, data splits, or statistical significance testing of the AUROC differences versus baselines. This weakens the claim of practical utility and cross-model transfer (AUROC 0.66-0.69).
minor comments (2)
- [§3.1] §3.1: The exact regex or parsing procedure for extracting the three signals from the judge trace is described at a high level; a small pseudocode listing or example trace would improve reproducibility.
- [Abstract] Abstract and §4: The reported AUROC ranges are given without confidence intervals or mention of the number of evaluation instances per benchmark, which is standard for calibration results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening our experimental validation. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Results) and associated tables: No ablation studies are presented that isolate the contribution of each of the three structural signals (e.g., full model vs. models using only Step-Verdict Alignment or only Claim-Level Margin). This is load-bearing for the central claim that the decomposed signals drive the reported AUROCs rather than format artifacts or the logistic regression itself; without ablations or feature-importance coefficients on the same data splits, the predictiveness of the signals remains unverified.
Authors: We agree that ablation studies are necessary to isolate the contribution of each structural signal and confirm they drive the reported AUROCs rather than format artifacts or the logistic regression. In the revised manuscript, we will add ablation experiments on the same data splits, reporting AUROC for the full combined model, each individual signal (Step-Verdict Alignment, Claim-Level Margin, Evidence Grounding Score), and all pairwise combinations. We will also report the learned coefficients from the Platt-scaled logistic regression to quantify feature importance. These additions will directly verify the predictiveness of the decomposed signals. revision: yes
-
Referee: [§4.3] §4.3 (Production and Transfer Experiments): The manuscript reports AUROC 0.73-0.88 on the production system with eight rubrics but provides no details on rubric definitions, data splits, or statistical significance testing of the AUROC differences versus baselines. This weakens the claim of practical utility and cross-model transfer (AUROC 0.66-0.69).
Authors: We acknowledge that additional details are needed to support the practical utility and cross-model transfer claims. In the revision, we will expand §4.3 to include: summarized definitions of the eight rubrics, explicit descriptions of the data splits (including how production data was partitioned), and statistical significance testing such as bootstrap confidence intervals for AUROCs and p-values or tests for differences versus baselines. We will also clarify the cross-model transfer experimental setup. These changes will strengthen the evidence for real-world applicability. revision: yes
Circularity Check
No significant circularity in VERDI's signal derivation or combination
full rationale
The paper defines Step-Verdict Alignment, Claim-Level Margin, and Evidence Grounding Score directly from the structure of the judge's existing reasoning trace, independent of any correctness labels. These signals are then fed to a standard Platt-scaled logistic regression whose parameters are fit on labeled data to produce a confidence score; AUROC is reported on benchmark splits as a measure of ranking performance. This is a conventional supervised calibration pipeline with no reduction of the output to the inputs by construction, no self-citation load-bearing steps, and no imported uniqueness claims. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Platt scaling logistic regression coefficients
axioms (1)
- domain assumption Structural signals can be reliably extracted from LLM reasoning traces using regex or a small NLI model.
Reference graph
Works this paper leans on
-
[1]
Atla Selene Mini: A general purpose evaluation model.arXiv preprint arXiv:2501.17195,
Andrei Alexandru, Antonia Calvi, Henry Broomfield, Jackson Golden, Kyle Dai, Mathias Leys, Maurice Burger, Max Bartolo, Roman Engeler, Sashank Pisupati, Toby Drane, and Young Sun Park. Atla Selene Mini: A general purpose evaluation model.arXiv preprint arXiv:2501.17195,
-
[2]
Zhenyu Bi, Gaurav Srivastava, Yang Li, Meng Lu, Swastik Roy, Morteza Ziyadi, and Xuan Wang
As of March 2026, Claude models do not expose token log- probabilities. Zhenyu Bi, Gaurav Srivastava, Yang Li, Meng Lu, Swastik Roy, Morteza Ziyadi, and Xuan Wang. JudgeBoard: Benchmarking and enhancing small language models for reasoning evaluation.arXiv preprint arXiv:2511.15958,
-
[3]
Trace length is a simple uncertainty signal in reasoning models
Siddartha Devic, Charlotte Peale, Arwen Bradley, Sinead Williamson, Preetum Nakkiran, and Aravind Gollakota. Trace length is a simple uncertainty signal in reasoning models. arXiv preprint arXiv:2510.10409,
-
[4]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Lan- guage models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
G- Eval: NLG evaluation using GPT-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G- Eval: NLG evaluation using GPT-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 2511–2522,
work page 2023
-
[6]
FActScore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mo- hit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 12076–12100,
work page 2023
-
[7]
10 Preprint. Under review. Bhaktipriya Radharapu, Eshika Saxena, Kenneth Li, Chenxi Whitehouse, Adina Williams, and Nicola Cancedda. Calibrating LLM judges: Linear probes for fast and reliable un- certainty estimation.arXiv preprint arXiv:2512.22245,
-
[8]
BaseCal: Unsupervised Confidence Calibration via Base Model Signals
Hexiang Tan, Wanli Yang, Junwei Zhang, Xin Chen, Rui Tang, Du Su, Jingang Wang, Yuanzhuo Wang, Fei Sun, and Xueqi Cheng. BaseCal: Unsupervised confidence cali- bration via base model signals.arXiv preprint arXiv:2601.03042,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
FEVER: a large-scale dataset for fact extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: a large-scale dataset for fact extraction and VERification. InProceedings of the 2018 Confer- ence of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 809–819,
work page 2018
-
[10]
Zailong Tian, Zhuoheng Han, Yanzhe Chen, Haozhe Xu, Xi Yang, Richeng Xuan, Houfeng Wang, and Lizi Liao. Overconfidence in LLM-as-a-judge: Diagnosis and confidence- driven solution.arXiv preprint arXiv:2508.06225,
-
[11]
Fact or fiction: Verifying scientific claims
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. Fact or fiction: Verifying scientific claims. InProceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 7534–7550,
work page 2020
-
[12]
A Example Sub-Check Prompt Below is an abbreviated version of the Q2 (attribution accuracy) sub-check prompt used in our experiments. The prompt instructs the judge to extract, verify, and label each claim individually, producing the structured trace that VERDIanalyzes. You are evaluating whether attributed claims in the generated text are accurate. Step ...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.