Recognition: no theorem link
gym-invmgmt: An Open Benchmarking Framework for Inventory Management Methods
Pith reviewed 2026-05-13 02:52 UTC · model grok-4.3
The pith
gym-invmgmt is a new benchmarking framework that evaluates inventory policies across optimization and learning methods, finding stochastic programming strongest among non-oracle approaches and PPO-Transformer best among learned ones in tested scenarios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Within these released scenarios, informed stochastic programming provides the strongest non-oracle reference, reflecting the value of scenario hedging under forecast access, but at substantially higher online computational cost. Among learned controllers, the Proximal Policy Optimization Transformer variant (PPO-Transformer) achieves the strongest learned-policy quality at fast inference, while Residual Reinforcement Learning (Residual RL) provides competitive hybrid performance.
Load-bearing premise
The assumption that the defined CoreEnv transition dynamics, reward function, action bounds, and KPI definitions create a neutral and representative testbed that does not inadvertently favor certain policy classes over others.
Figures



read the original abstract
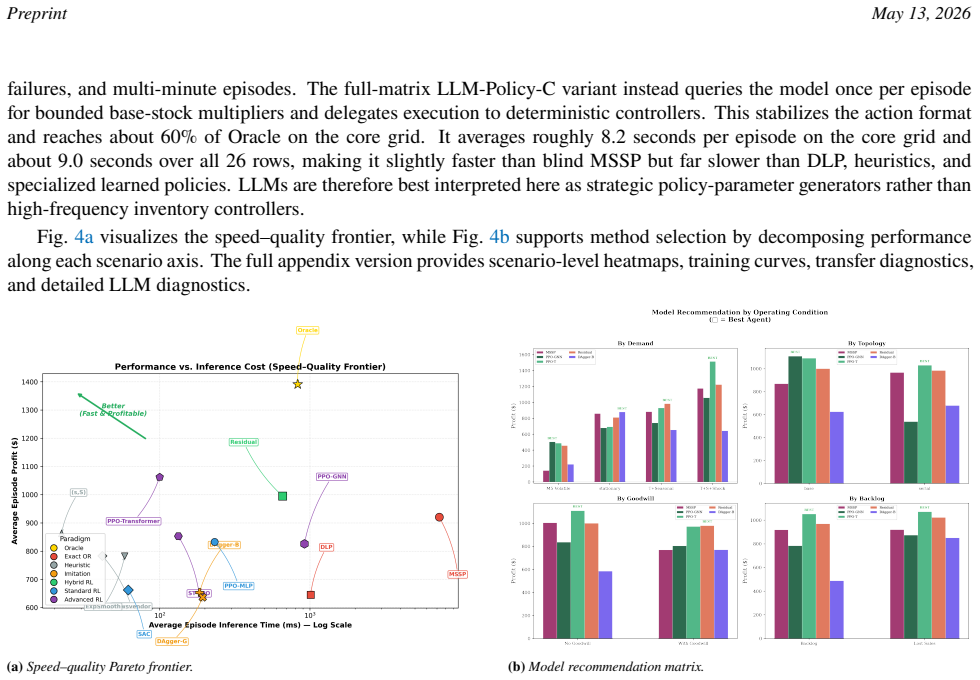
Inventory-policy comparisons are often difficult to interpret because performance depends on the evaluation contract as much as on the policy itself. Differences in topology, demand regime, information access, feasibility constraints, shortage treatment, and Key Performance Indicator (KPI) definitions can change method rankings. We present gym-invmgmt, a Gymnasium-compatible extension of the OR-Gym inventory-management lineage for auditable cross-paradigm evaluation. The benchmark evaluates optimization, heuristic, and learned controllers under a shared CoreEnv transition, reward, action-bound, and KPI contract, while varying stress conditions through a 22-scenario core grid plus four supplemental MARL-mode rows. Within these released scenarios, informed stochastic programming provides the strongest non-oracle reference, reflecting the value of scenario hedging under forecast access, but at substantially higher online computational cost. Among learned controllers, the Proximal Policy Optimization Transformer variant (PPO-Transformer) achieves the strongest learned-policy quality at fast inference, while Residual Reinforcement Learning (Residual RL) provides competitive hybrid performance. The graph neural network variant (PPO-GNN) is highly competitive on the default divergent topology but less robust on the serial topology. Imitation learning performs well in stationary regimes but degrades under demand shift, and the bounded Large Language Model (LLM) policy-parameter baseline is best interpreted as a diagnostic controller rather than an autonomous inventory optimizer. Overall, the benchmark identifies scenario-conditioned leaders while showing that performance depends jointly on information access, demand shift, topology, and policy representation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces gym-invmgmt, a Gymnasium-compatible extension of the OR-Gym inventory-management environment, to enable auditable cross-paradigm comparisons. It defines a shared CoreEnv with fixed transition dynamics, reward function, action bounds, and KPI definitions, then evaluates optimization (informed stochastic programming), heuristics, and learned controllers (PPO-Transformer, PPO-GNN, Residual RL, imitation learning, and a bounded LLM baseline) across a 22-scenario grid that varies topology and demand regime, plus supplemental MARL rows. The central empirical claims are that informed stochastic programming is the strongest non-oracle reference (at high online cost), PPO-Transformer is the strongest learned policy at fast inference, Residual RL is competitive, and performance jointly depends on information access, topology, and demand shift.
Significance. If the CoreEnv contract proves neutral, the work supplies a reproducible, open benchmarking resource that directly addresses the field's problem of incomparable evaluations caused by differing topologies, shortage treatments, and KPI definitions. The release of scenarios and code, together with the explicit separation of oracle vs. non-oracle and learned vs. optimization baselines, is a concrete strength that could accelerate progress in inventory control research.
major comments (1)
- [Abstract and §4] Abstract and §4 (results): The ranking claims (informed stochastic programming strongest non-oracle; PPO-Transformer strongest learned policy) are load-bearing for the paper's contribution yet rest on the untested assumption that the CoreEnv transition dynamics, reward (holding/shortage cost ratios), action bounds, and KPI definitions create a neutral testbed. No sensitivity analysis, alternative reward formulations, or ablation under modified dynamics (e.g., different lead-time models or variance penalties) is presented to rule out systematic bias toward scenario-hedging optimizers or sequence-model policies.
minor comments (3)
- [§3.2] §3.2 (CoreEnv specification): A compact table listing the exact parameter values (lead times, cost coefficients, demand distributions) for each of the 22 scenarios would improve reproducibility and allow readers to assess the stress conditions at a glance.
- [Figure 3] Figure 3 and associated text: The computational-cost comparison for stochastic programming vs. learned policies should report both mean and worst-case online solve times, together with the hardware used, to substantiate the claim of 'substantially higher' cost.
- [§5] §5 (limitations): The discussion of generalizability could be strengthened by explicitly stating which classes of inventory problems (e.g., multi-echelon with capacity constraints or non-stationary lead times) fall outside the current CoreEnv scope.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for acknowledging the benchmark's potential to address incomparable evaluations in inventory control research. We respond to the major comment below and outline targeted revisions that strengthen the manuscript without altering its core contribution as an open, auditable framework.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results): The ranking claims (informed stochastic programming strongest non-oracle; PPO-Transformer strongest learned policy) are load-bearing for the paper's contribution yet rest on the untested assumption that the CoreEnv transition dynamics, reward (holding/shortage cost ratios), action bounds, and KPI definitions create a neutral testbed. No sensitivity analysis, alternative reward formulations, or ablation under modified dynamics (e.g., different lead-time models or variance penalties) is presented to rule out systematic bias toward scenario-hedging optimizers or sequence-model policies.
Authors: We agree that the absence of explicit sensitivity analysis leaves the neutrality assumption untested and that this merits attention given the load-bearing nature of the rankings. The manuscript frames the CoreEnv as a fixed, literature-derived contract (extending OR-Gym with standard holding/shortage ratios, action bounds, and KPIs) rather than claiming universal neutrality; results are explicitly conditioned on the released 22-scenario grid. To address the concern, we will revise the abstract, §4, and add a new limitations subsection that (i) justifies parameter choices with references to established inventory literature, (ii) discusses how the varied topologies and demand regimes already provide partial robustness probing, and (iii) acknowledges that alternative contracts could shift rankings. We will also include a limited sensitivity check on the holding/shortage cost ratio in one representative scenario. Full ablations across arbitrary lead-time models or variance penalties exceed the scope of this benchmark-establishment paper and are positioned as future uses of the open framework. This revision clarifies the conditional nature of the claims without overstating generality. revision: partial
- Exhaustive sensitivity analyses and ablations under all suggested alternative dynamics and reward formulations cannot be performed within the current revision due to computational cost and scope constraints.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Optimalinventorypolicy.Econometrica,19(3):250–272,1951
KennethJ.Arrow,TheodoreHarris,andJacobMarschak. Optimalinventorypolicy.Econometrica,19(3):250–272,1951. Bharathan Balaji, Jordan Bell-Masterson, Enes Bilgin, Andreas Damianou, Pablo Moreno Garcia, Arpit Jain, et al. ORL: Reinforcement learning benchmarks for online stochastic optimization problems.arXiv preprint arXiv:1911.10641,
-
[2]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. OpenAI Gym.arXiv preprint arXiv:1606.01540,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Jen-Ming Chen and Tsung-Hui Chen
doi: 10.1016/j.cor.2024.106778. Jen-Ming Chen and Tsung-Hui Chen. The multi-item replenishment problem in a two-echelon supply chain: the effect of centralization versus decentralization.Computers & Operations Research, 32:3191–3207,
-
[4]
doi: 10.1016/j.cor. 2004.05.007. Andrew J. Clark and Herbert Scarf. Optimal policies for a multi-echelon inventory problem.Management Science, 6(4): 475–490,
-
[5]
Florian Felten, Lucas N. Alegre, Ann Nowé, Ana L. C. Bazzan, El Ghazali Talbi, Grégoire Danoy, and Bruno C. da Silva. A toolkit for reliable benchmarking and research in multi-objective reinforcement learning. InAdvances in Neural In- formationProcessingSystems,volume36,2023. URLhttps://proceedings.neurips.cc/paper_files/paper/ 2023/hash/4aa8891583f07ae20...
work page 2023
-
[6]
doi: 10.1287/educ.1053.0020. Yanran Gao and Shuning Chen. Deep reinforcement learning for multi-echelon supply chain management under demand uncertainty.arXiv preprint arXiv:2003.11485,
-
[7]
14 Preprint May 13, 2026 Stephen C. Graves and Sean P. Willems. Optimizing strategic safety stock placement in supply chains.Manufacturing & Service Operations Management, 2(1):68–83,
work page 2026
-
[8]
Christian D. Hubbs, Hector D. Perez, Owais Sarwar, Nikolaos V. Sahinidis, Ignacio E. Grossmann, and John M. Wassick. OR-Gym: A reinforcement learning library for operations research problems.arXiv preprint arXiv:2008.06319,
-
[9]
Dhruv Madeka, Kari Torkkola, Carson Eisenach, Anna Luo, Dean P
arXiv:2308.01649. Dhruv Madeka, Kari Torkkola, Carson Eisenach, Anna Luo, Dean P. Foster, and Sham M. Kakade. Deep inventory management.arXiv preprint arXiv:2210.03137v3,
-
[10]
Stuart Mitchell, Michael O’Sullivan, and Iain Dunning
doi: 10.1007/s00521-021-06129-w. Stuart Mitchell, Michael O’Sullivan, and Iain Dunning. PuLP: A linear programming toolkit for Python,
-
[11]
Afshin Oroojlooyjadid, MohammadReza Nazari, Lawrence V
doi: 10.1287/mnsc.1080.0889. Afshin Oroojlooyjadid, MohammadReza Nazari, Lawrence V. Snyder, and Martin Takáč. A deep Q-network for the beer game: Deep reinforcement learning for inventory optimization.Manufacturing & Service Operations Management, 24 (1):285–304,
-
[12]
YinzhuQuanandZefangLiu. InvAgent: Alargelanguagemodelbasedmulti-agentinventorymanagementsystem.arXiv preprint arXiv:2407.11384v1,
-
[13]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
doi: 10.48550/arXiv.2412.15115. 15 Preprint May 13, 2026 AntoninRaffin,AshleyHill,AdamGleave,AnssiKanervisto,MaximilianErnestus,andNoahDormann.Stable-Baselines3: Reliable reinforcement learning implementations.Journal of Machine Learning Research, 22(268):1–8,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2026
-
[15]
Proximal Policy Optimization Algorithms
JohnSchulman,FilipWolski,PrafullaDhariwal,AlecRadford,andOlegKlimov. Proximalpolicyoptimizationalgorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Tom Silver, Kelsey Allen, Josh Tenenbaum, and Leslie Kaelbling
doi: 10.1287/mnsc.12.12.B538. Tom Silver, Kelsey Allen, Josh Tenenbaum, and Leslie Kaelbling. Residual policy learning. InRobotics: Science and Systems XIV,
-
[17]
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U
doi: 10.1016/j.matpr.2021.05.314. Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U. Balis, Gianluca De Cola, Tristan Deleu, et al. Gymnasium: A standard interface for reinforcement learning environments. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track,
-
[18]
Reinforcementlearningforsparepartsinventorymanagementwithadeepq-network
JiangjiangWangandYunFongLin. Reinforcementlearningforsparepartsinventorymanagementwithadeepq-network. arXiv preprint arXiv:2103.14110,
-
[19]
Xianliang Yang, Zhihao Liu, Wei Jiang, Chuheng Zhang, Li Zhao, Lei Song, and Jiang Bian. A versatile multi-agent reinforcement learning benchmark for inventory management.arXiv preprint arXiv:2306.07542,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.