Recognition: 2 theorem links
· Lean TheoremDynamic Full-body Motion Agent with Object Interaction via Blending Pre-trained Modular Controllers
Pith reviewed 2026-05-13 02:15 UTC · model grok-4.3
The pith
Pretrained dynamic motion and static HOI agents can be blended via a composer network to generate long-term dynamic human-object interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
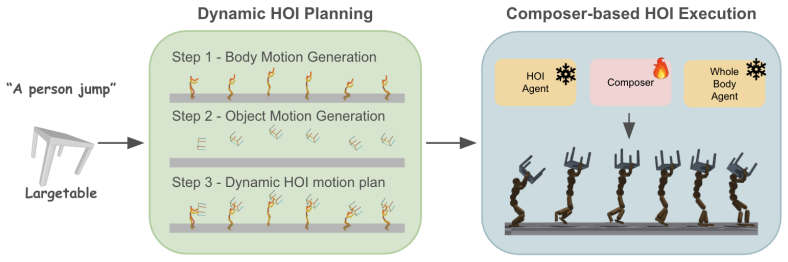
We propose a framework that fulfills dynamic and long-term interaction motions such as running while holding a table, by combining pretrained motion priors and imitation agents in planning and execution stages. In the planning stage, we augment HOI datasets with dynamic priors from a pretrained human motion diffusion model, followed by object trajectory generation. This plans dynamic HOI sequences. In the execution stage, a composer network blends actions of pretrained imitation agents specialized either for dynamic human motions or static HOI motions, enabling spatio-temporal composition of their complementary skills. Our method over relevant prior-arts consistently improves success rates,
What carries the argument
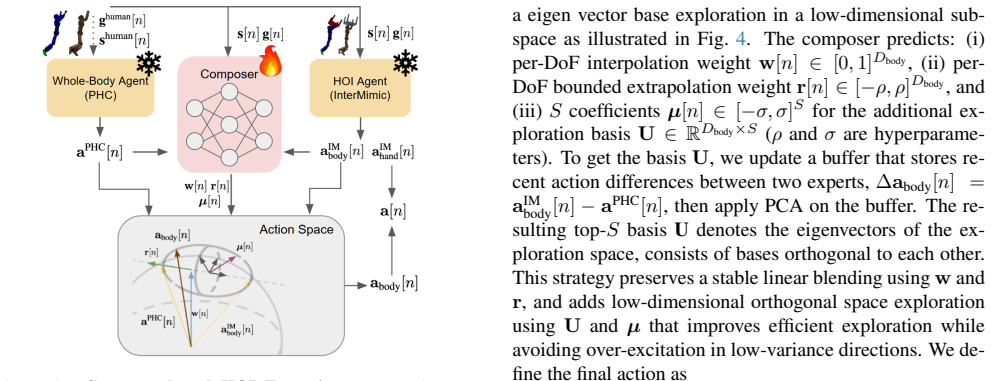
The composer network that blends the actions of two pretrained imitation agents, one specialized for dynamic full-body human motions without objects and the other for static human-object interactions.
Where Pith is reading between the lines
- The modular blending could reduce dependence on large dynamic HOI datasets by reusing separate motion and interaction priors.
- If the composer generalizes across objects and durations, it may support real-time applications in robotics where separate skill modules are common.
- This two-stage planning-plus-execution structure might apply to other motion problems that mix locomotion with manipulation.
Load-bearing premise
The complementary skills of the dynamic human motion agent and the static HOI agent can be spatio-temporally composed by the composer network into stable, physically plausible long-term interactions without artifacts or further adaptation.
What would settle it
Running the composer on extended sequences and observing frequent loss of object contact, visible motion artifacts, or no improvement in success rates over baselines would show the central claim does not hold.
Figures



read the original abstract
Generating physically plausible dynamic motions of human-object interaction (HOI) remains challenging, mainly due to existing HOI datasets limited to static interactions, and pretrained agents capable of either dynamic full-body motions without objects or static HOI motions. Recent works such as InsActor and CLoSD generate HOI motions in planning and execution stages, are yet limited to either static or short-term contacts e.g. striking. In this work, we propose a framework that fulfills dynamic and long-term interaction motions such as running while holding a table, by combining pretrained motion priors and imitation agents in planning and execution stages. In the planning stage, we augment HOI datasets with dynamic priors from a pretrained human motion diffusion model, followed by object trajectory generation. This plans dynamic HOI sequences. In the execution stage, a composer network blends actions of pretrained imitation agents specialized either for dynamic human motions or static HOI motions, enabling spatio-temporal composition of their complementary skills. Our method over relevant prior-arts consistently improves success rates while maintaining interaction for dynamic HOI tasks. Furthermore, blending pretrained experts with our composer achieves competitive performance in significantly reduced training time. Ablation studies validate the effectiveness of our augmentation and composer blending.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for generating dynamic full-body human-object interaction (HOI) motions by combining pre-trained modular controllers in a two-stage process. The planning stage augments existing static HOI datasets with dynamic motion priors from a human motion diffusion model and generates corresponding object trajectories. The execution stage employs a composer network to blend actions from a dynamic full-body motion agent and a static HOI agent, enabling spatio-temporal composition for long-term interactions such as running while holding objects. The authors report that their method achieves consistent improvements in success rates over prior arts while maintaining interactions, delivers competitive performance with significantly reduced training time, and that ablations validate the augmentation and blending components.
Significance. If the claims are substantiated by rigorous experiments, this work has potential significance in the computer vision and robotics fields for HOI motion synthesis. By leveraging pre-trained experts rather than training from scratch, it addresses data scarcity for dynamic interactions and reduces computational costs. The introduction of the composer network for blending complementary skills is a novel contribution that could inspire similar modular approaches in other motion generation tasks. Credit is given for the modular design and the focus on long-term dynamic HOI, which extends beyond short-term or static contacts in prior works like InsActor and CLoSD.
major comments (3)
- [Execution stage] Execution stage (composer network): The central claim that the composer produces artifact-free, contact-stable long-horizon trajectories rests on the untested assumption that blending actions from separately trained dynamic-motion and static-HOI experts yields physically plausible outputs when actions conflict. The manuscript supplies no quantitative long-horizon physical metrics (contact duration, penetration volume, foot-skate distance, or CoM stability) on dynamic-HOI test cases, nor does it state whether the composer received any fine-tuning. This is load-bearing for attributing success-rate gains to the blending mechanism.
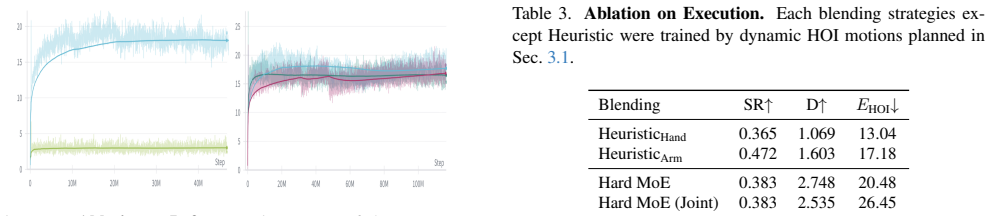
- [Ablation studies] Ablation studies: The claim that ablations 'validate the effectiveness of composer blending' is not supported by comparisons to alternative blending strategies (e.g., action averaging, priority switching) or by reporting whether the composer was trained from scratch versus with frozen experts. Without these controls, the 'significantly reduced training time' advantage cannot be isolated from the pre-training of the experts themselves.
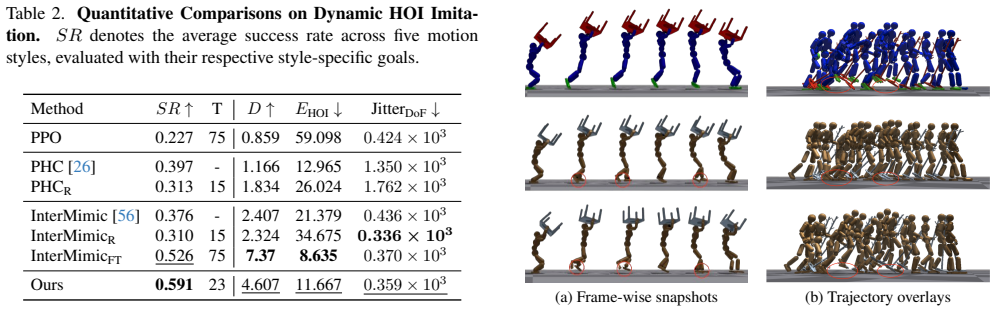
- [Experiments] Experiments section: The headline assertions of 'consistent improvements in success rates' and 'competitive performance in significantly reduced training time' are presented without numerical values, standard deviations, number of trials, environment details, or statistical tests. This prevents assessment of effect size and reproducibility, which is required to evaluate the central claim against prior arts.
minor comments (3)
- [Abstract] Abstract: The phrase 'relevant prior-arts' should explicitly name the key baselines (InsActor, CLoSD) to improve readability.
- [Method] Notation: Define the input features and output blending weights of the composer network more explicitly (e.g., via equations) to support reproducibility.
- Figures: Ensure all comparison plots include error bars, legends, and axis units; clarify whether success-rate curves are averaged over multiple random seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, clarifying aspects of our method and proposing specific revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Execution stage] Execution stage (composer network): The central claim that the composer produces artifact-free, contact-stable long-horizon trajectories rests on the untested assumption that blending actions from separately trained dynamic-motion and static-HOI experts yields physically plausible outputs when actions conflict. The manuscript supplies no quantitative long-horizon physical metrics (contact duration, penetration volume, foot-skate distance, or CoM stability) on dynamic-HOI test cases, nor does it state whether the composer received any fine-tuning. This is load-bearing for attributing success-rate gains to the blending mechanism.
Authors: We appreciate this observation on the need for stronger evidence of physical plausibility. The current manuscript relies on success rates and qualitative visualizations to demonstrate contact stability, but we agree these are insufficient for long-horizon claims. In the revision we will add quantitative long-horizon physical metrics (contact duration, penetration volume, foot-skate distance, and CoM stability) computed on the dynamic-HOI test cases. We will also explicitly state that the composer was trained from scratch with the two pre-trained experts kept frozen (no fine-tuning of the experts), which is the design that enables the reported training-time savings while still producing stable blends. revision: yes
-
Referee: [Ablation studies] Ablation studies: The claim that ablations 'validate the effectiveness of composer blending' is not supported by comparisons to alternative blending strategies (e.g., action averaging, priority switching) or by reporting whether the composer was trained from scratch versus with frozen experts. Without these controls, the 'significantly reduced training time' advantage cannot be isolated from the pre-training of the experts themselves.
Authors: We agree that the ablation section would be more convincing with additional controls. In the revised manuscript we will include direct comparisons against alternative blending strategies (action averaging and priority switching) and will report the exact training protocol: the composer is trained from scratch while the dynamic-motion and static-HOI experts remain frozen. We will also tabulate wall-clock training times for the composer-only stage versus full end-to-end training of a single agent, thereby isolating the computational benefit of the modular approach. revision: yes
-
Referee: [Experiments] Experiments section: The headline assertions of 'consistent improvements in success rates' and 'competitive performance in significantly reduced training time' are presented without numerical values, standard deviations, number of trials, environment details, or statistical tests. This prevents assessment of effect size and reproducibility, which is required to evaluate the central claim against prior arts.
Authors: We apologize for the omission of explicit numerical details in the narrative. The experiments section already references tables containing success rates, but we will expand these tables in the revision to include per-task means and standard deviations (computed over 5 random seeds), the exact number of evaluation trials per task, full environment specifications (including simulator version and physics parameters), and results of statistical significance tests (paired t-tests) against the baselines. These additions will allow readers to assess effect sizes and reproducibility directly. revision: yes
Circularity Check
No circularity; framework combines external pretrained models with a new composer without reducing claims to self-defined inputs.
full rationale
The paper describes a two-stage pipeline: planning augments existing HOI datasets using a pretrained human motion diffusion model plus object trajectory generation, while execution introduces a composer network that blends actions from separately pretrained dynamic-motion and static-HOI imitation agents. No equations, fitted parameters, or predictions are shown to be equivalent to their inputs by construction. The reported success-rate gains and ablation validations rest on the empirical behavior of the newly introduced composer rather than on any self-referential definition or renaming of prior results. The derivation chain therefore remains self-contained against external benchmarks and pretrained components.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained human motion diffusion model and imitation agents for dynamic motions and static HOI are available and performant enough to support augmentation and blending.
invented entities (1)
-
Composer network
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleara composer network blends actions of pretrained imitation agents... per-DoF interpolation weight w[n] ... extrapolation weight r[n] ... S coefficients μ[n] for the additional exploration basis U
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorem unclearspatio-temporal composition of their complementary skills
Reference graph
Works this paper leans on
-
[1]
Adver- sarial imitation learning with trajectorial augmentation and correction
Dafni Antotsiou, Carlo Ciliberto, and Tae-Kyun Kim. Adver- sarial imitation learning with trajectorial augmentation and correction. InICRA, 2021. 2
work page 2021
-
[2]
Mod- ular adaptive policy selection for multi-task imitation learn- ing through task division
Dafni Antotsiou, Carlo Ciliberto, and Tae–Kyun Kim. Mod- ular adaptive policy selection for multi-task imitation learn- ing through task division. InICRA, 2022. 3
work page 2022
-
[3]
Behave: Dataset and method for tracking human object in- teractions
Bharat Lal Bhatnagar, Xianghui Xie, Ilya Petrov, Cristian Sminchisescu, Christian Theobalt, and Gerard Pons-Moll. Behave: Dataset and method for tracking human object in- teractions. InCVPR, 2022. 2
work page 2022
-
[4]
Univla: Learning to act anywhere with task-centric latent ac- tions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent ac- tions. InRSS, 2025. 2, 3
work page 2025
-
[5]
Taming diffusion probabilistic mod- els for character control
Rui Chen, Mingyi Shi, Shaoli Huang, Ping Tan, Taku Ko- mura, and Xuelin Chen. Taming diffusion probabilistic mod- els for character control. InACM SIGGRAPH, 2024. 2, 3
work page 2024
-
[6]
Dense hand-object (ho) graspnet with full grasping taxonomy and dynamics
Woojin Cho, Jihyun Lee, Minjae Yi, Minje Kim, Taeyun Woo, Donghwan Kim, Taewook Ha, Hyokeun Lee, Je-Hwan Ryu, Woontack Woo, and Tae-Kyun Kim. Dense hand-object (ho) graspnet with full grasping taxonomy and dynamics. In ECCV, 2024. 3
work page 2024
-
[7]
Semgeomo: Dynamic contextual human motion generation with semantic and geometric guidance
Peishan Cong, Ziyi Wang, Yuexin Ma, and Xiangyu Yue. Semgeomo: Dynamic contextual human motion generation with semantic and geometric guidance. InCVPR, 2025. 2
work page 2025
-
[8]
Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data
Shengliang Deng et al. Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data. In CoRL, 2025. 2, 3
work page 2025
-
[9]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InNAACL-HLT, 2019. 2
work page 2019
-
[10]
Pengxiang Ding et al. Humanoid-vla: Towards universal humanoid control with visual integration.arXiv preprint arXiv:2502.14795, 2025. 2, 3
-
[11]
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with sim- ple and efficient sparsity.Journal of Machine Learning Re- search, 2022. 3
work page 2022
-
[12]
Helix: A vision-language-action model for generalist humanoid control, 2025
Figure. Helix: A vision-language-action model for generalist humanoid control, 2025. Technical report. 2, 3
work page 2025
-
[13]
Physics-based dexterous manipulations with estimated hand poses and residual reinforcement learning
Guillermo Garcia-Hernando, Edward Johns, and Tae-Kyun Kim. Physics-based dexterous manipulations with estimated hand poses and residual reinforcement learning. InIROS,
-
[14]
Auto-regressive diffusion for generating 3d human- object interactions
Zichen Geng, Zeeshan Hayder, Wei Liu, and Ajmal Saeed Mian. Auto-regressive diffusion for generating 3d human- object interactions. InAAAI, 2025. 2
work page 2025
-
[15]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InCVPR, 2022. 2
work page 2022
-
[16]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion mod- els.arXiv preprint arXiv:2210.02303, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. In ICLR, 2022. 1, 2, 4, 6
work page 2022
-
[18]
Guided motion diffusion for controllable human motion synthesis
Korrawe Karunratanakul, Konpat Preechakul, Supasorn Suwajanakorn, and Siyu Tang. Guided motion diffusion for controllable human motion synthesis. InICCV, 2023. 5
work page 2023
-
[19]
Op- timizing diffusion noise can serve as universal motion priors
Korrawe Karunratanakul, Konpat Preechakul, Emre Aksan, Thabo Beeler, Supasorn Suwajanakorn, and Siyu Tang. Op- timizing diffusion noise can serve as universal motion priors. InCVPR, 2024. 2
work page 2024
-
[20]
David: Modeling dynamic affordance of 3d objects using pre- trained video diffusion models
Hyeonwoo Kim, Sangwon Baik, and Hanbyul Joo. David: Modeling dynamic affordance of 3d objects using pre- trained video diffusion models. InICCV, 2025. 1, 2, 6, 8
work page 2025
-
[21]
Jeonghwan Kim, Jisoo Kim, Jeonghyeon Na, and Hanbyul Joo. Parahome: Parameterizing everyday home activities to- wards 3d generative modeling of human-object interactions. InCVPR, 2025. 5
work page 2025
-
[22]
Object motion guided human motion synthesis
Jiaman Li, Jiajun Wu, and C Karen Liu. Object motion guided human motion synthesis. InACM TOG, 2023. 2, 4, 5, 6
work page 2023
- [23]
-
[24]
Yuhang Lin, Yijia Xie, Jiahong Xie, Yuehao Huang, Ruoyu Wang, Jiajun Lv, Yukai Ma, and Xingxing Zuo. Simgenhoi: Physically realistic whole-body humanoid-object interaction via generative modeling and reinforcement learning.arXiv preprint arXiv:2508.14120, 2025. 3
-
[25]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. SMPL: A skinned multi- person linear model. InACM TOG, 2015. 4, 1
work page 2015
-
[26]
Winkler, Kris Ki- tani, and Weipeng Xu
Zhengyi Luo, Jinkun Cao, Alexander W. Winkler, Kris Ki- tani, and Weipeng Xu. Perpetual humanoid control for real- time simulated avatars. InICCV, 2023. 2, 3, 5, 7, 1
work page 2023
-
[27]
Omnigrasp: Grasping di- verse objects with simulated humanoids
Zhengyi Luo, Jinkun Cao, Sammy Christen, Alexander Win- kler, Kris Kitani, and Weipeng Xu. Omnigrasp: Grasping di- verse objects with simulated humanoids. InNeurIPS, 2024. 3, 5
work page 2024
-
[28]
Zhengyi Luo, Jinkun Cao, Josh Merel, Alexander Winkler, Jing Huang, Kris M. Kitani, and Weipeng Xu. Universal humanoid motion representations for physics-based control. InICLR, 2024. 3 9
work page 2024
-
[29]
Himo: A new benchmark for full-body human interacting with multiple objects
Xintao Lv, Liang Xu, Yichao Yan, Xin Jin, Congsheng Xu, Shuwen Wu, Yifan Liu, Lincheng Li, Mengxiao Bi, Wenjun Zeng, and Xiaokang Yang. Himo: A new benchmark for full-body human interacting with multiple objects. InECCV,
-
[30]
Troje, Ger- ard Pons-Moll, and Michael J
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Ger- ard Pons-Moll, and Michael J. Black. Amass: Archive of motion capture as surface shapes. InICCV, 2019. 2, 4, 6, 7
work page 2019
-
[31]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021. 5, 1
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
To- kenhsi: Unified synthesis of physical human-scene interac- tions through task tokenization
Liang Pan, Zeshi Yang, Zhiyang Dou, Wenjia Wang, Buzhen Huang, Bo Dai, Taku Komura, and Jingbo Wang. To- kenhsi: Unified synthesis of physical human-scene interac- tions through task tokenization. InCVPR, 2025. 5
work page 2025
-
[33]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3D hands, face, and body from a single image. InCVPR, 2019. 5
work page 2019
-
[34]
Hoi-diff: Text-driven synthe- sis of 3d human-object interactions using diffusion models
Xiaogang Peng, Yiming Xie, Zizhao Wu, Varun Jampani, Deqing Sun, and Huaizu Jiang. Hoi-diff: Text-driven synthe- sis of 3d human-object interactions using diffusion models. InCVPR Workshop on Human Motion Generation (HuMo- Gen), 2025. 2, 6
work page 2025
-
[35]
Deepmimic: Example-guided deep reinforce- ment learning of physics-based character skills
Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel Van de Panne. Deepmimic: Example-guided deep reinforce- ment learning of physics-based character skills. InACM TOG, 2018. 2, 3
work page 2018
-
[36]
Mcp: Learning composable hierarchi- cal control with multiplicative compositional policies
Xue Bin Peng, Michael Chang, Grace Zhang, Pieter Abbeel, and Sergey Levine. Mcp: Learning composable hierarchi- cal control with multiplicative compositional policies. In NeurIPS, 2019. 2, 3
work page 2019
-
[37]
Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters
Xue Bin Peng, Yunrong Guo, Lina Halper, Sergey Levine, and Sanja Fidler. Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters. InACM TOG, 2022. 3
work page 2022
-
[38]
The KIT motion-language dataset.Big Data, 2016
Matthias Plappert, Christian Mandery, and Tamim Asfour. The KIT motion-language dataset.Big Data, 2016. 2
work page 2016
-
[39]
Punnakkal, Arjun Chandrasekaran, Nikos Athanasiou, Alejandra Quiros-Ramirez, and Michael J
Abhinanda R. Punnakkal, Arjun Chandrasekaran, Nikos Athanasiou, Alejandra Quiros-Ramirez, and Michael J. Black. BABEL: Bodies, action and behavior with english labels. InCVPR, 2021. 2
work page 2021
-
[40]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 2
work page 2021
-
[41]
Diffmimic: Efficient motion mimicking with differentiable physics
Jiawei Ren, Cunjun Yu, Siwei Chen, Xiao Ma, Liang Pan, and Ziwei Liu. Diffmimic: Efficient motion mimicking with differentiable physics. InICLR, 2023. 2, 3
work page 2023
-
[42]
Insactor: Instruction-driven physics- based characters
Jiawei Ren, Mingyuan Zhang, Cunjun Yu, Xiao Ma, Liang Pan, and Ziwei Liu. Insactor: Instruction-driven physics- based characters. InNeurIPS, 2023. 2, 3
work page 2023
-
[43]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, 2022. 2, 5
work page 2022
-
[44]
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Raz- van Pascanu, and Raia Hadsell. Progressive neural networks. arXiv preprint arXiv:1606.04671, 2016. 3
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[45]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 7
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Outra- geously large neural networks: The sparsely-gated mixture- of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outra- geously large neural networks: The sparsely-gated mixture- of-experts layer. InICLR, 2017. 3
work page 2017
-
[47]
Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
Tom Silver, Kelsey Allen, Josh Tenenbaum, and Leslie Kaelbling. Residual policy learning.arXiv preprint arXiv:1812.06298, 2018. 3
-
[48]
Black, and Dim- itrios Tzionas
Omid Taheri, Nima Ghorbani, Michael J. Black, and Dim- itrios Tzionas. GRAB: A dataset of whole-body human grasping of objects. InECCV, 2020. 2
work page 2020
-
[49]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-or, and Amit Haim Bermano. Human motion diffusion model. InICLR, 2023. 1, 2, 4, 6
work page 2023
-
[50]
CLoSD: Closing the loop between simulation and diffusion for multi-task character control
Guy Tevet, Sigal Raab, Setareh Cohan, Daniele Reda, Zhengyi Luo, Xue Bin Peng, Amit Haim Bermano, and Michiel van de Panne. CLoSD: Closing the loop between simulation and diffusion for multi-task character control. In ICLR, 2025. 2, 3, 5
work page 2025
-
[51]
Skillmimic: Learning basketball interaction skills from demonstrations
Yinhuai Wang, Qihan Zhao, Runyi Yu, Hok Wai Tsui, Ail- ing Zeng, Jing Lin, Zhengyi Luo, Jiwen Yu, Xiu Li, Qifeng Chen, Jian Zhang, Lei Zhang, and Ping Tan. Skillmimic: Learning basketball interaction skills from demonstrations. InCVPR, 2025. 3
work page 2025
-
[52]
Hoi-dyn: Learn- ing interaction dynamics for human-object motion diffusion
Lin Wu, Zhixiang Chen, and Jianglin Lan. Hoi-dyn: Learn- ing interaction dynamics for human-object motion diffusion. arXiv preprint arXiv:2507.01737, 2025. 2
-
[53]
Qianyang Wu, Ye Shi, Xiaoshui Huang, Jingyi Yu, Lan Xu, and Jingya Wang. Thor: Text to human-object inter- action diffusion via relation intervention.arXiv preprint arXiv:2403.11208, 2024
-
[54]
Interdiff: Generating 3d human-object interactions with physics-informed diffusion
Sirui Xu, Zhengyuan Li, Yu-Xiong Wang, and Liang-Yan Gui. Interdiff: Generating 3d human-object interactions with physics-informed diffusion. InICCV, 2023. 2
work page 2023
-
[55]
InterAct: Advancing large-scale versatile 3d human-object interaction generation
Sirui Xu, Dongting Li, Yucheng Zhang, Xiyan Xu, Qi Long, Ziyin Wang, Yunzhi Lu, Shuchang Dong, Hezi Jiang, Ak- shat Gupta, Yu-Xiong Wang, and Liang-Yan Gui. InterAct: Advancing large-scale versatile 3d human-object interaction generation. InCVPR, 2025. 2
work page 2025
-
[56]
Intermimic: Towards universal whole-body control for physics-based human-object interactions
Sirui Xu, Hung Yu Ling, Yu-Xiong Wang, and Liang-Yan Gui. Intermimic: Towards universal whole-body control for physics-based human-object interactions. InCVPR, 2025. 2, 3, 5, 7, 1
work page 2025
-
[57]
Humanvla: Towards vision-language directed object re- arrangement by physical humanoid
Xinyu Xu, Yizheng Zhang, Yong-Lu Li, Lei Han, and Cewu Lu. Humanvla: Towards vision-language directed object re- arrangement by physical humanoid. InNeurIPS, 2024. 2, 3
work page 2024
-
[58]
Runyi Yu, Yinhuai Wang, Qihan Zhao, Hok Wai Tsui, Jingbo Wang, Ping Tan, and Qifeng Chen. Skillmimic-v2: Learning robust and generalizable interaction skills from sparse and noisy demonstrations. InACM SIGGRAPH, 2025. 3 10
work page 2025
-
[59]
Physdiff: Physics-guided human motion diffusion model
Ye Yuan, Jiaming Song, Umar Iqbal, Arash Vahdat, and Jan Kautz. Physdiff: Physics-guided human motion diffusion model. InICCV, 2023. 2, 6
work page 2023
-
[60]
Adaptive skill selection for effective exploration of action space
Haoke Zhang, Yiyong Huang, Wei Han, Dan Xiong, Chuanfu Zhang, and Yanjie Yang. Adaptive skill selection for effective exploration of action space. InIJCNN, 2024. 3
work page 2024
-
[61]
Neural- dome: A neural modeling pipeline on multi-view human- object interactions
Juze Zhang, Haimin Luo, Hongdi Yang, Xinru Xu, Qianyang Wu, Ye Shi, Jingyi Yu, Lan Xu, and Jingya Wang. Neural- dome: A neural modeling pipeline on multi-view human- object interactions. InCVPR, 2023. 2
work page 2023
-
[62]
arXiv preprint arXiv:2208.15001 (2022) 1, 3, 10, 12
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Motiondif- fuse: Text-driven human motion generation with diffusion model.arXiv preprint arXiv:2208.15001, 2022. 2
-
[63]
Zhuangzhuang Zhang, Yizhao Wang, Zhinan Zhang, Lihui Wang, Huang Huang, and Qixin Cao. A residual reinforce- ment learning method for robotic assembly using visual and force information.Journal of Manufacturing Systems, 2024. 3
work page 2024
-
[64]
I’m hoi: Inertia-aware monocular capture of 3d human-object inter- actions
Chengfeng Zhao, Juze Zhang, Jiashen Du, Ziwei Shan, Junye Wang, Jingyi Yu, Jingya Wang, and Lan Xu. I’m hoi: Inertia-aware monocular capture of 3d human-object inter- actions. InCVPR, 2024. 2
work page 2024
-
[65]
DartControl: A diffusion-based autoregressive motion model for real-time text-driven motion control
Kaifeng Zhao, Gen Li, and Siyu Tang. DartControl: A diffusion-based autoregressive motion model for real-time text-driven motion control. InICLR, 2025. 2
work page 2025
-
[66]
Rt-2: Vision-language-action mod- els transfer web knowledge to robotic control
Brianna Zitkovich et al. Rt-2: Vision-language-action mod- els transfer web knowledge to robotic control. InCoRL,
-
[67]
2, 3 11 Dynamic Full-body Motion Agent with Object Interaction via Blending Pre-trained Modular Controllers Supplementary Material A. Supplementary Video The submitted video qualitatively illustrates how our frame- work generates dynamic and physically valid HOI motions, comparing its planning and execution with multiple base- lines. •Prior-Blending for H...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.