Recognition: no theorem link
Kairos: A Scalable Serving System for Physical AI
Pith reviewed 2026-05-13 02:26 UTC · model grok-4.3
The pith
Kairos cuts physical AI task latency by 32 to 66 percent by treating the generate-execute loop as first-class and staying active during robot execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
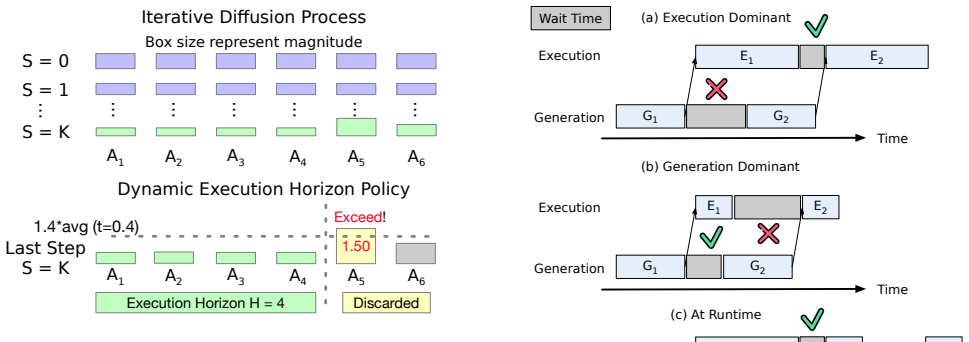
The paper claims that physical AI inference consists of repeated rounds that generate action chunks and run asynchronously with execution, a structure that existing digital serving systems do not handle efficiently. By making the generate-execute loop a first-class citizen and keeping the serving system active during execution, Kairos reduces average end-to-end task latency by 31.8 to 66.5 percent relative to state-of-the-art digital practices, and these gains increase with fleet size.
What carries the argument
The generate-execute loop made first-class with active serving-system involvement during the execution phase, which coordinates multiple inference rounds, chunked actions, and asynchronous interleaving.
If this is right
- Average end-to-end task latency falls by 31.8 to 66.5 percent for physical AI workloads.
- The latency reduction grows larger as the number of robots in the fleet increases.
- The approach works across a range of physical AI models and robot platforms.
- It removes a key obstacle to deploying large models on sizable robot fleets.
Where Pith is reading between the lines
- Serving designs that stay active during physical execution could be applied to other interleaved compute-and-act systems such as autonomous vehicles or industrial control.
- Evaluation benchmarks for AI serving may need new multi-round, chunked-action test cases to reflect physical deployment realities.
- Robot hardware and communication layers might be optimized specifically to reduce overhead in asynchronous interleaving, amplifying the latency gains.
Load-bearing premise
The multi-round inference, chunked actions, and asynchronous interleaving of physical AI are the dominant sources of latency, and keeping the serving system involved during execution reduces them without creating new bottlenecks or correctness problems.
What would settle it
Run the same physical AI task on a fleet of robots using both Kairos and a standard digital AI serving system, then measure whether the end-to-end completion time drops by 31.8 to 66.5 percent and whether the gap widens as the number of robots increases.
Figures












read the original abstract
Physical AI is experiencing rapid growth with frontier foundation models increasing its capabilities across general environments. Physical AI tasks are characterized by inference properties that are markedly different from digital AI. They consist of multiple rounds of inference and action execution, generating a chunk of actions in each inference round, and asynchronously interleaving inference and execution. This makes existing digital AI serving systems unsuited for physical AI; a shortcoming that is critical for enabling their wide adoption, considering their size and the scale of the robot fleets they have to serve. To fill this gap, we design Kairos, the first multi-robot serving system that makes the generate-execute loop a first-class citizen, with active involvement in the execution phase. Across a wide range of physical AI models and robots, Kairos reduces the average end-to-end task latency by 31.8--66.5% over state-of-the-art digital AI serving practices, with gains scaling with the robot fleet size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Kairos, the first multi-robot serving system for physical AI that treats the generate-execute loop as a first-class citizen by actively participating in the execution phase. It identifies key differences in physical AI inference properties (multiple rounds, chunked actions, asynchronous interleaving) that make digital AI serving systems unsuitable, and claims that Kairos reduces average end-to-end task latency by 31.8-66.5% over state-of-the-art digital AI serving practices across a range of models and robots, with gains that scale with robot fleet size.
Significance. If the empirical results hold under scrutiny, this work addresses a timely and practically important gap in systems support for physical AI deployments. The focus on execution-phase involvement and fleet-size scaling provides a concrete path toward efficient operation of large foundation models on robot fleets, which could accelerate real-world adoption. The empirical nature of the central claim (latency measurements rather than derivations) is appropriately matched to the problem.
major comments (2)
- [§5] §5 (Evaluation): the latency reduction numbers (31.8-66.5%) are presented without an accompanying table or figure that breaks down the contribution of each Kairos mechanism (e.g., async interleaving vs. chunked action handling) versus baseline overheads; this makes it difficult to confirm that the gains are attributable to the claimed design rather than unstated experimental choices.
- [§4] §4 (System Design): the description of active execution-phase involvement does not quantify the additional communication or synchronization overhead introduced by Kairos itself; without this, it is unclear whether the net latency improvement remains positive under higher robot counts or network variability.
minor comments (2)
- The abstract would benefit from a one-sentence summary of the experimental scope (number of models/robots, fleet sizes tested) to give readers immediate context for the reported percentages.
- Figure captions and axis labels in the scaling plots should explicitly state whether error bars represent standard deviation across runs or across robot instances.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of Kairos and for the constructive major comments. We address each point below and have revised the manuscript to incorporate additional analysis and clarifications as suggested.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): the latency reduction numbers (31.8-66.5%) are presented without an accompanying table or figure that breaks down the contribution of each Kairos mechanism (e.g., async interleaving vs. chunked action handling) versus baseline overheads; this makes it difficult to confirm that the gains are attributable to the claimed design rather than unstated experimental choices.
Authors: We appreciate the referee's request for greater attribution of the reported gains. While the original evaluation focused on end-to-end results across models and robots, we agree that an explicit breakdown strengthens the claims. In the revised manuscript, we have added a new table and accompanying figure in §5 that decomposes the latency reductions into contributions from async interleaving, chunked action handling, and other mechanisms, while isolating baseline overheads from digital AI serving systems. The breakdown shows that async interleaving and active execution-phase participation account for the majority of the improvement (typically 45-60% of the total reduction), with the remainder from chunked handling; this confirms the gains are attributable to Kairos's design rather than experimental artifacts. We have also expanded the experimental setup description for clarity. revision: yes
-
Referee: [§4] §4 (System Design): the description of active execution-phase involvement does not quantify the additional communication or synchronization overhead introduced by Kairos itself; without this, it is unclear whether the net latency improvement remains positive under higher robot counts or network variability.
Authors: We thank the referee for noting this omission. To address it directly, the revised §4 now includes a dedicated overhead analysis subsection with empirical measurements of the communication and synchronization costs introduced by Kairos's active execution-phase involvement. These overheads were quantified under varying fleet sizes (up to 64 robots) and network conditions (including simulated variability). The results demonstrate that the added overhead remains low (typically 3-7% of end-to-end latency) and scales sublinearly, preserving net latency reductions of 28-62% even at higher robot counts and with 15-25% network jitter. This supports the scalability of the design. revision: yes
Circularity Check
No significant circularity in empirical systems evaluation
full rationale
The paper describes a serving system for physical AI and supports its latency-reduction claims through direct experimental measurements across multiple models, robots, and fleet sizes. No equations, derivations, fitted parameters, or predictions are presented that could reduce to inputs by construction. The argument relies on empirical results rather than self-citations, uniqueness theorems, or ansatzes, making the evaluation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Physical AI tasks consist of multiple rounds of inference and action execution that asynchronously interleave inference and execution.
Reference graph
Works this paper leans on
-
[1]
1X Technologies.https://www.1x.tech, 2024
work page 2024
-
[2]
Figure AI.https://www.figure.ai, 2024
work page 2024
-
[3]
Unitree Robotics.https://www.unitree.com, 2024
work page 2024
-
[4]
Fourier gr-1.https://www.fftai.com/products-gr1, 2026
work page 2026
-
[5]
Nvidia isaac lab.https://developer.nvidia.com/isaac/lab, 2026
work page 2026
-
[6]
Nvidia isaac sim.https://developer.nvidia.com/isaac/sim, 2026
work page 2026
-
[7]
So-101.https://huggingface.co/docs/lerobot/en/so101, 2026
work page 2026
-
[8]
R. Abhyankar, Z. He, V. Srivatsa, H. Zhang, and Y. Zhang. Infercept: Efficient intercept support for augmented large language model infer- ence, 2024
work page 2024
-
[9]
Amazon. Amazon robotics.https://www.aboutamazon.com/news/ operations/amazon-robotics-robots-fulfillment-center, 2024
work page 2024
-
[10]
The Claude 3 model family: Opus, Sonnet, Haiku
Anthropic. The Claude 3 model family: Opus, Sonnet, Haiku. Technical report, 2024.https : / / www - cdn . anthropic . com / de8ba9b01c9ab7cbabf5c33b80b7bbc618857627 / Model _ Card _ Claude_3.pdf
work page 2024
- [11]
-
[12]
A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, X. Chen, K. Choroman- ski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y. Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y. Lu, H. Michalewski, I. Mordatch, K. Per...
work page 2023
- [13]
-
[14]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y. Liu, Z. Li, Q. Liang, X. Lin, Y. Ge, Z. Gu, W. Deng, Y. Guo, T. Nian, X. Xie, Q. Chen, K. Su, T. Xu, G. Liu, M. Hu, H. ang Gao, K. Wang, Z. Liang, Y. Qin, X. Yang, P. Luo, and Y. Mu. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation, 2025
work page 2025
-
[15]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y. Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion, 2024
work page 2024
-
[16]
N. Corporation. Tensorrt-llm: An open-source library to accelerate inference of large language models on nvidia gpus.https://github. com/NVIDIA/TensorRT-LLM, 2023. Library: TensorRT-LLM
work page 2023
-
[17]
H. Fang, Y. Liu, Y. Du, L. Du, and H. Yang. Sqap-vla: A synergistic quantization-aware pruning framework for high-performance vision- language-action models, 2025
work page 2025
-
[18]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Google. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
I. Gim, S. seob Lee, and L. Zhong. Asynchronous llm function calling, 2024
work page 2024
-
[20]
J. Gu, M. Chowdhury, K. G. Shin, Y. Zhu, M. Jeon, J. Qian, H. Liu, and C. Guo. Tiresias: a gpu cluster manager for distributed deep learning. InProceedings of the 16th USENIX Conference on Networked Systems Design and Implementation, NSDI’19, page 485–500, USA, 2019. USENIX Association
work page 2019
-
[21]
P. B. Hansen.Operating system principles. Prentice-Hall, Inc., USA, 1973
work page 1973
-
[22]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y. Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vu...
work page 2025
- [23]
- [24]
-
[25]
M. J. Kim, Y. Gao, T.-Y. Lin, Y.-C. Lin, Y. Ge, G. Lam, P. Liang, S. Song, M.-Y. Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning, 2026
work page 2026
-
[26]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burch- fiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model, 2024
work page 2024
-
[27]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[28]
S.-W. Lee, X. Kang, and Y.-L. Kuo. Diff-dagger: Uncertainty estimation with diffusion policy for robotic manipulation, 2025
work page 2025
-
[29]
H. Li, Q. Mang, R. He, Q. Zhang, H. Mao, X. Chen, H. Zhou, A. Cheung, J. Gonzalez, and I. Stoica. Continuum: Efficient and robust multi-turn llm agent scheduling with kv cache time-to-live, 2026
work page 2026
-
[30]
P. Li, Y. Zhou, D. Muhtar, L. Yin, S. Yan, L. Shen, S. Vosoughi, and S. Liu. Diffusion language models know the answer before decoding, 2026
work page 2026
-
[31]
S. Li, Y. Gao, D. Sadigh, and S. Song. Unified video action model, 2025
work page 2025
-
[32]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kirmani, S. Levine, J. Wu, C. Finn, H. Su, Q. Vuong, and T. Xiao. Evaluating real-world robot manipulation policies in simulation, 2024
work page 2024
- [33]
-
[34]
B. Liu, Y. Zhu, C. Gao, Y. Feng, Q. Liu, Y. Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023
work page 2023
- [35]
-
[36]
Z. Liu, Y. Chen, H. Cai, T. Lin, S. Yang, Z. Liu, and B. Zhao. Vla- pruner: Temporal-aware dual-level visual token pruning for efficient vision-language-action inference, 2026
work page 2026
-
[37]
M. Luo, X. Shi, C. Cai, T. Zhang, J. Wong, Y. Wang, C. Wang, Y. Huang, Z. Chen, J. E. Gonzalez, and I. Stoica. Autellix: An efficient serving engine for llm agents as general programs, 2025
work page 2025
-
[38]
T. Ma, J. Zheng, Z. Wang, C. Jiang, A. Cui, J. Liang, and S. Yang. Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control, 2026
work page 2026
-
[39]
M. Nuyens and A. Wierman. The foreground–background queue: A survey.Performance Evaluation, 65(3):286–307, 2008
work page 2008
-
[40]
NVIDIA, :, J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y. Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y. L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y. Xie, Y. Xu, Z. Xu, S. Ye, Z. Yu, ...
work page 2025
-
[41]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
J. Pai, L. Achenbach, V. Montesinos, B. Forrai, O. Mees, and E. Nava. mimic-video: Video-action models for generalizable robot control be- yond vlas, 2025
work page 2025
-
[43]
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez. Gorilla: Large language model connected with massive apis, 2023
work page 2023
-
[44]
S. Pohland, X. Foukas, G. Ananthanarayanan, A. Kolobov, S. Mehro- tra, B. Radunovic, and A. Verma. Offload or overload: A platform measurement study of mobile robotic manipulation workloads, 2026
work page 2026
- [45]
-
[46]
Sawyer robot.https://robotsguide.com/robots/sawyer, 2026
Robots Guide. Sawyer robot.https://robotsguide.com/robots/sawyer, 2026
work page 2026
-
[47]
H. Shi, B. Xie, Y. Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang. Memoryvla: Perceptual-cognitive memory in vision- language-action models for robotic manipulation, 2026
work page 2026
- [48]
-
[49]
J. Tang, Y. Sun, Y. Zhao, S. Yang, Y. Lin, Z. Zhang, J. Hou, Y. Lu, Z. Liu, and S. Han. Vlash: Real-time vlas via future-state-aware asynchronous inference, 2025
work page 2025
-
[50]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakrishna, R. Baruch, M. Bauza, M. Blokzijl, S. Bo- hez, K. Bousmalis, A. Brohan, T. Buschmann, A. Byravan, S. Cabi, K. Caluwaerts, F. Casarini, O. Chang, J. E. Chen, X. Chen, H.-T. L. Chi- ang, K. Choromanski, D. D’Ambrosio, S. Dasari, T. Davchev, C. Devin, N. D. Palo, ...
work page 2025
-
[51]
Tesla optimus.https://www.tesla.com/optimus, 2024
Tesla. Tesla optimus.https://www.tesla.com/optimus, 2024
work page 2024
-
[52]
Z. Wang, Z. Li, A. Mandlekar, Z. Xu, J. Fan, Y. Narang, L. Fan, Y. Zhu, Y. Balaji, M. Zhou, M.-Y. Liu, and Y. Zeng. One-step diffusion policy: Fast visuomotor policies via diffusion distillation, 2024
work page 2024
-
[53]
Y. Xu, X. Kong, T. Chen, and D. Zhuo. Conveyor: Efficient tool-aware llm serving with tool partial execution, 2024
work page 2024
-
[54]
Y. Xu, Y. Yang, Z. Fan, Y. Liu, Y. Li, B. Li, and Z. Zhang. Qvla: Not all channels are equal in vision-language-action model’s quantization, 2026
work page 2026
-
[55]
H. Yan, Z. Zhong, J. Zhu, J. He, W. Yuan, W. Song, X. Gong, Y. Cai, G. Zhao, X. Yan, B. Liu, Y.-C. Chen, and H. Li. S-vam: Shortcut video- action model by self-distilling geometric and semantic foresight, 2026
work page 2026
-
[56]
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. R. Narasimhan, and O. Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InNeurIPS, 2024
work page 2024
-
[57]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao. React: Synergizing reasoning and acting in language models, 2023
work page 2023
-
[58]
A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, H. Li, J. Li, J. Lv, J. Liu, M. Cao, P. Li, Q. Deng, W. Mei, X. Wang, X. Chen, X. Zhou, Y. Wang, Y. Chang, Y. Li, Y. Zhou, Y. Ye, Z. Liu, and Z. Zhu. Gigaworld-policy: An efficient action-centered world–action model, 2026
work page 2026
-
[59]
H. Ye, J. Yuan, R. Xia, X. Yan, T. Chen, J. Yan, B. Shi, and B. Zhang. Training-free adaptive diffusion with bounded difference approxima- tion strategy, 2024
work page 2024
-
[60]
S. Ye, Y. Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y. L. Tan, C. Zhu, J. Xiang, A. Malik, K. Lee, W. Liang, N. Ranawaka, J. Gu, Y. Xu, G. Wang, F. Hu, A. Narayan, J. Bjorck, J. Wang, G. Kim, D. Niu, R. Zheng, Y. Xie, J. Wu, Q. Wang, R. Julian, D. Xu, Y. Du, Y. Chebotar, S. Reed, J. Kautz, Y. Zhu, L. J. Fan, and J. Jang. World action models are...
work page 2026
-
[61]
T. Yu, D. Quillen, Z. He, R. Julian, A. Narayan, H. Shively, A. Bellathur, K. Hausman, C. Finn, and S. Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning, 2021
work page 2021
-
[62]
T. Yuan, Z. Dong, Y. Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?, 2026
work page 2026
- [63]
-
[64]
T. Z. Zhao, V. Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware, 2023
work page 2023
- [65]
- [66]
-
[67]
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y. Bisk, D. Fried, U. Alon, and G. Neubig. WebArena: A realistic web environment for building autonomous agents. InICLR, 2024. 14
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.